一、Junit 是什么?
Junit 是 Java 中用于单元测试的框架。使用 Junit 能让我们快速高效的完成单元测试。
- 自动化测试:JUnit提供了自动化测试的能力,开发人员可以编写一次测试用例,然后通过简单的命令或集成到持续集成工具中进行反复运行,大大减少了重复性的测试工作量。
- 注解和断言:JUnit使用注解对测试方法进行标记,使用断言进行结果验证,让测试用例编写更为简洁、直观,同时减少了手动编写测试代码的出错概率。
传统模式下,我们写完代码想要测试这段代码的正确性,那么必须新建一个类,然后创建一个 main() 方法,然后编写测试代码。如果需要测试的代码很多呢?那么要么就会建很多main() 方法来测试,要么将其全部写在一个 main() 方法里面。这也会大大的增加测试的复杂度,降低程序员的测试积极性。而 Junit 能很好的解决这个问题,简化单元测试,写一点测一点,在编写以后的代码中如果发现问题可以较快的追踪到问题的原因,减小回归错误的纠错难度。
二、配置 Junit 环境
配置 Junit 只需要在单元测试中导入相关依赖即可,我们这里使用的是 Junit5。maven 地址:https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-api/5.8.2
<!-- https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-api -->
<dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-api</artifactId><version>5.8.2</version><scope>test</scope>
</dependency>
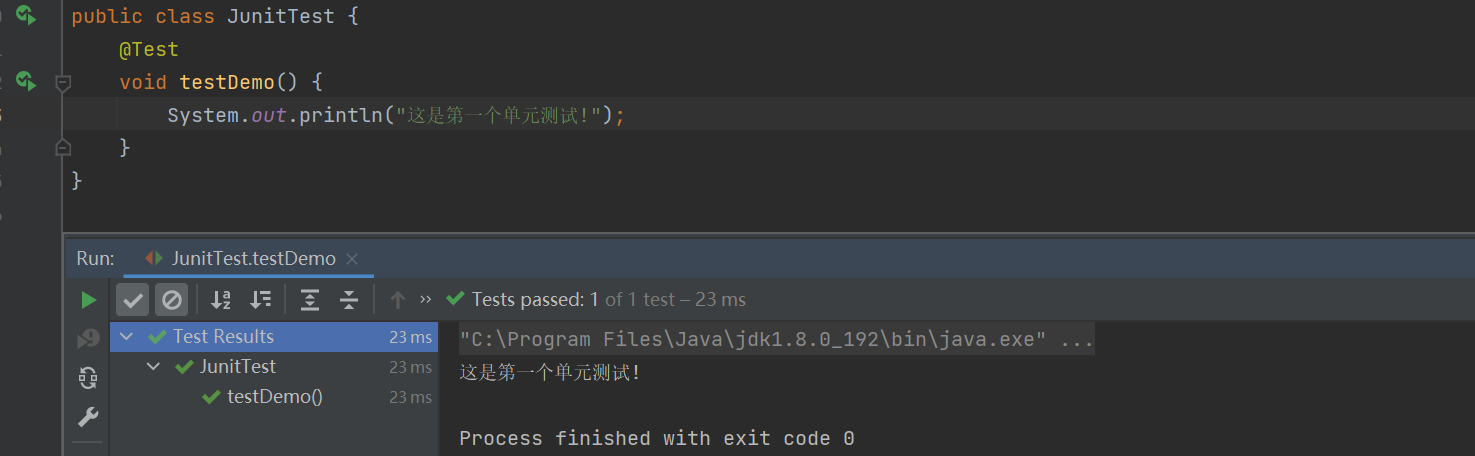
下面我们写个demo测试一下是否导入成功:
import org.junit.jupiter.api.Test;
public class JunitTest {@Testvoid testDemo() {System.out.println("这是第一个单元测试!");}
}
1、常用注解
-
@Test注解用于标记测试方法。JUnit 将会执行所有被 @Test 注解标记的方法作为测试用例。 -
@Disabled注解用于标记测试方法并禁用它,这在你暂时不想执行某个测试方法时非常有用。 -
@BeforeAll注解用于标记在所有测试方法执行之前只需执行一次的方法。且被该注解修饰的方法必须为静态方法。通常用于初始化静态资源。 -
@AfterAll注解用于标记在所有测试方法执行之后只需执行一次的方法。且被该注解修饰的方法必须为静态方法。通常用于释放静态资源。 -
@BeforeEach注解用于标记在每个测试方法之前需要执行的方法。通常用于初始化测试环境。 -
@AfterEach注解用于标记在每个测试方法之后需要执行的方法。通常用于清理测试环境。
public class JunitTest {@BeforeAllstatic void setUp() {System.out.println("所有测试方法执行之前执行BeforeAll");}@AfterAllstatic void tearDown() {System.out.println("所有测试方法执行结束后执行AfterAll");}@BeforeEachvoid setUpEach() {System.out.println("在每个测试方法执行前执行BeforeEach");}@AfterEachvoid tearDownEach() {System.out.println("在每个测试方法执行之后执行AfterEach");}@Testvoid testDemo1() {System.out.println("testDemo1()");}@Testvoid testDemo2() {System.out.println("testDemo2()");}@Disabledvoid testDemo3() {System.out.println("testDemo3()");}
}

2、断言
在 JUnit 中,断言是用于验证测试结果是否符合预期的工具,以下是一些常用的 JUnit 断言方法:
assertEquals(expected, actual):验证两个值是否相等。适用于比较基本数据类型或对象。assertNotEquals(unexpected, actual):验证两个值是否不相等。assertTrue(condition):验证条件是否为 true。assertFalse(condition):验证条件是否为 false。assertNull(object):验证对象是否为 null。assertNotNull(object):验证对象是否不为 null。assertArrayEquals(expectedArray, resultArray):验证两个数组是否相等。assertSame(expected, actual):验证两个引用是否指向同一个对象。assertNotSame(unexpected, actual):验证两个引用是否指向不同的对象。assertThrows(expectedException, executable):验证方法是否抛出了预期的异常。
下面写一个简单的使用示例:
public class JunitTest {@Testvoid testDemo1() {Assertions.assertEquals("aaa","aaa");Assertions.assertTrue(true);}@Testvoid testDemo2() {Assertions.assertTrue(false);}
}

3、参数化
参数化用例可以帮我们更好的管理测试用例,将测试数据与测试用例分离,实现测试用例的重用。JUnit 5 提供了 @ParameterizedTest 注解来支持参数化测试,使用前需要先导入相关依赖。maven仓库地址:https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-params/5.8.2
@ParameterizedTest 需要搭配数据源用于为参数化测试提供测试数据,以下是一些常用的数据源及其用法:
(1)@ValueSource 注解:用于提供基本类型的单一值作为参数,例如整型、字符串、布尔等。
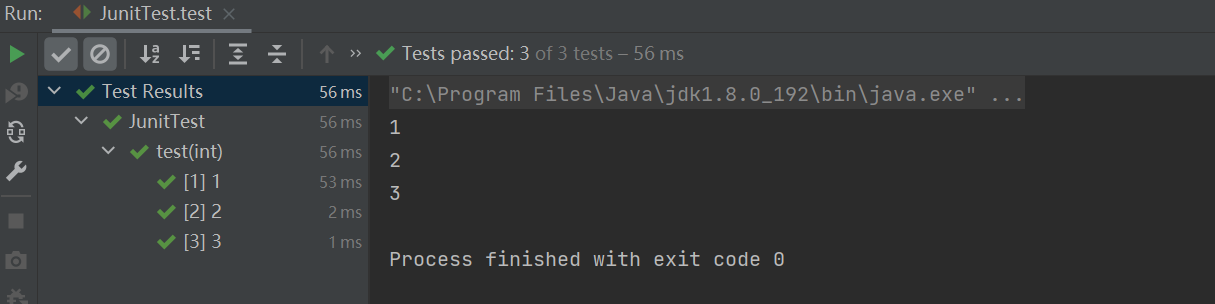
@ParameterizedTest@ValueSource(ints = {1,2,3})void test(int num) {System.out.println(num);}
(2)@EnumSource 注解:用于提供枚举类型作为参数,可以指定包含的枚举类型。
// 定义一个枚举enum Season {a,b,c}@ParameterizedTest@EnumSource(Season.class)void test2(Season season) {System.out.println(season);}

(3)@CsvSource 注解:允许你直接内联定义CSV格式的数据,作为参数传递给测试方法。
@ParameterizedTest@CsvSource({"apple, 1","banana, 2","orange, 3"})void testWithCsvSource(String fruit, int count) {// 测试代码System.out.println("fruit = "+fruit+", count = "+count);}

(4)@CsvFileSource 注解:允许你从外部CSV文件中读取数据作为参数传递给测试方法。
@ParameterizedTest@CsvFileSource(resources = "test-data.csv", numLinesToSkip = 1)void testWithCsvFileSource(String name, String gender ,int age) {// 测试代码System.out.println("name = "+name+", gender = "+gender+", age = "+age);}

注:通常情况下,CSV文件的第一行会包含列标题或者字段名,描述了每一列数据的含义。当使用@CsvFileSource进行参数化测试时,使用 numLinesToSkip = 1 跳过第一行可以避免将列标题作为测试数据传递给测试方法。
(5)@MethodSource 注解:用于指定一个方法作为数据源,该方法必须返回一个Stream、Iterable、Iterator或者数组。
public static Stream<Arguments> generateData() {return Stream.of(Arguments.arguments("张三",18,"男"),Arguments.arguments("张三",19,"女"),Arguments.arguments("李四",20,"女"));}@ParameterizedTest@MethodSource("generateData")void testWithSimpleMethodSource(String name,int age,String gender) {// 测试代码System.out.println("name = "+name+", age = "+age+", gender = "+gender);}

4、测试用例的执行顺序
在 JUnit 中,测试方法的执行顺序本身是不保证的,并不像我们想的一样是从上至下依次执行的,为例反证这一点,我们可以写个Demo演示一下:

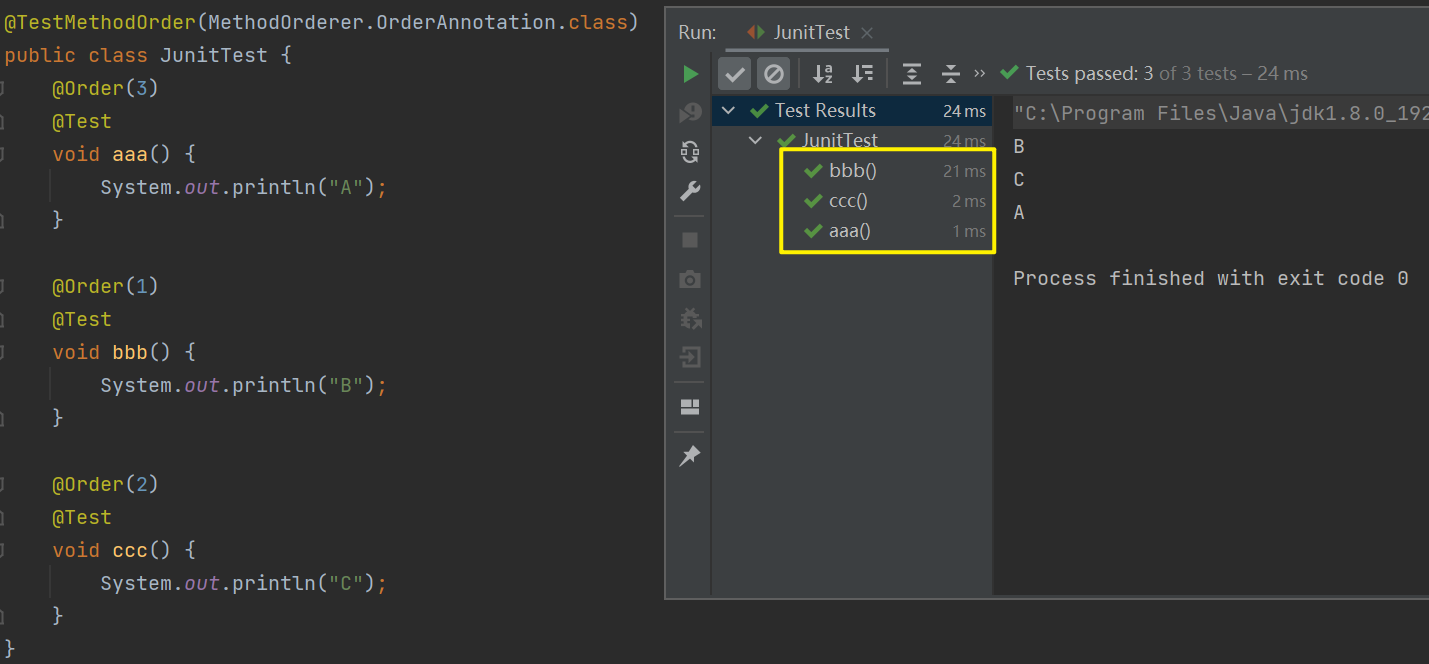
但是在实际测试中,我们需要完成连贯的多个步骤的测试,是需要规定测试用例执行的顺序的。JUnit 5 中的 @TestMethodOrder 注解可用于指定测试方法的执行顺序。
@TestMethodOrder 注解可以与实现了 MethodOrderer 接口的自定义顺序器一起使用,以便根据特定的排序策略执行测试方法。JUnit 5提供的主要测试方法排序器:
MethodNameOrderer:按照方法名的字典顺序执行测试方法。Random:随机执行测试方法。OrderAnnotation:根据@Order注解中指定的顺序执行测试方法。
MethodNameOrderer 测试

Random测试

OrderAnnotation 测试
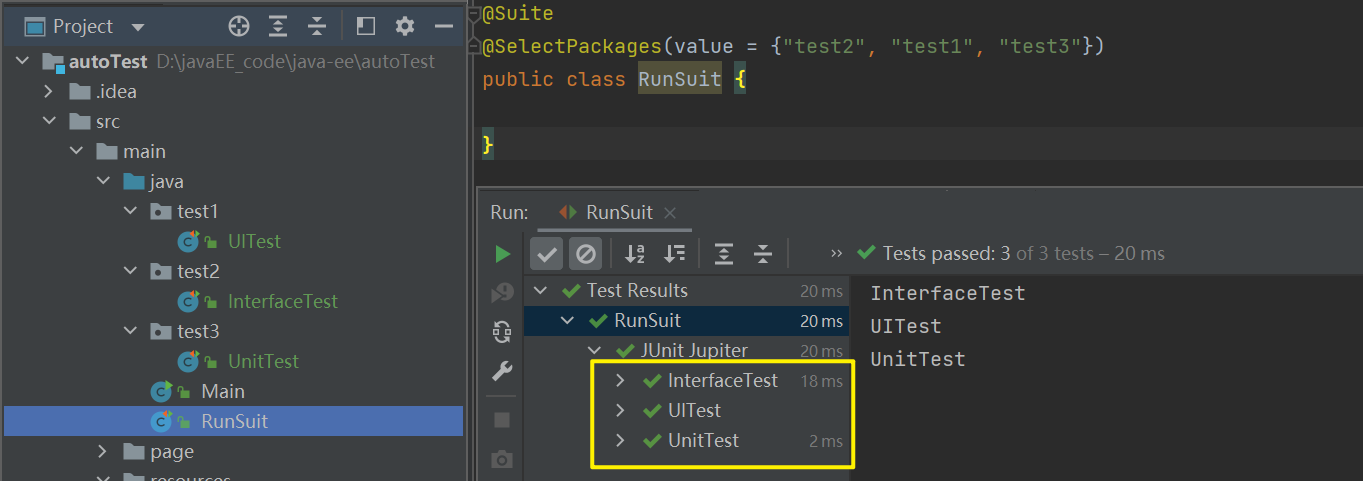
5、测试套件
当我们一个类中有多个测试用例时,我们不可能挨个去运行,那样将会很耗费时间,这时我们就需要 测试套件 来指定类或者指定包名来运行类下或者包下的所有测试用例。在Junit中可以使用@Suite标记测试套件,使用时需要导入依赖。maven 地址:https://mvnrepository.com/artifact/org.junit.platform/junit-platform-suite/1.9.1
另外使用 suite 需要引入 引擎engine 依赖。maven 地址:https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-engine/5.8.2
(1)指定 Class 执行测试用例
使用注解:@SelectClasses({指定类, 指定类, 指定类})

(2)指定包执行测试用例
使用注解:@SelectPackages(value = {"包1", "包2","..."})
PS:如果使用包名来指定运行的范围,那么该包下的所有的测试类的命名需要以 Test 或者 Tests结尾(T必须大写);