目录
1. 部门工资前三高的所有员工(185)
题解一(dense_rank()窗口函数)
题解二(自定义函数)
2.删除重复的电子邮箱(196)
题解一
题解二(官方解析)
3.上升的温度(197)
解法一(DATEDIFF())
解法二(TIMESTAMPDIFF())
解法三(ADDDATE()力扣)
1. 部门工资前三高的所有员工(185)
表: Employee
+--------------+---------+ | Column Name | Type | +--------------+---------+ | id | int | | name | varchar | | salary | int | | departmentId | int | +--------------+---------+ Id是该表的主键列。 departmentId是Department表中ID的外键。 该表的每一行都表示员工的ID、姓名和工资。它还包含了他们部门的ID。
表: Department
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | +-------------+---------+ Id是该表的主键列。 该表的每一行表示部门ID和部门名。
公司的主管们感兴趣的是公司每个部门中谁赚的钱最多。一个部门的 高收入者 是指一个员工的工资在该部门的 不同 工资中 排名前三 。
编写一个SQL查询,找出每个部门中 收入高的员工 。
以 任意顺序 返回结果表。
题解一(dense_rank()窗口函数)
dense_rank() 排序规则 1 2 3 3 4
rank() 1 2 3 3 5
partition by 根据某字段分区
# Write your MySQL query statement below
select Department, Employee, Salary
from (select d.name Department,e.name Employee,e.salary Salary ,dense_rank() over(partition by d.name order by e.salary desc) no from employee e join department d
on e.departmentId=d.id) temp
where temp.no<=3
题解二(自定义函数)
到现在,我对这个自定义函数的用法才稍微熟练了一点,这自定义函数的出现,可以让sql变的更加灵活。
CASE
WHEN @pre = DepartmentId THEN @rank:= @rank + 1
WHEN @pre := DepartmentId THEN @rank:= 1
END AS 'RANK'
这个意思是,如果@pre等于当前的DepartmentId则@rank加一,否则更新@pre的值且@rank=1。
这个@rank的值命名为RANK字段。用这个进行排序的关键就是from 的表需要有序。
SELECT dep.Name Department, emp.Name Employee, emp.Salary
FROM (## 自定义变量RANK, 查找出 每个部门工资前三的排名SELECT te.DepartmentId, te.Salary,CASE WHEN @pre = DepartmentId THEN @rank:= @rank + 1WHEN @pre := DepartmentId THEN @rank:= 1END AS 'RANK'FROM (SELECT @pre:=null, @rank:=0)tt,(## (部门,薪水)去重,根据 部门(升),薪水(降) 排序SELECT DepartmentId,SalaryFROM EmployeeGROUP BY DepartmentId,SalaryORDER BY DepartmentId,Salary DESC)te)t
INNER JOIN Department dep ON t.DepartmentId = dep.Id
INNER JOIN Employee emp ON t.DepartmentId = emp.DepartmentId and t.Salary = emp.Salary and t.RANK <= 3
ORDER BY t.DepartmentId, t.Salary DESC ## t 结果集已有序,根据该集合排序2.删除重复的电子邮箱(196)
表: Person
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | email | varchar | +-------------+---------+ id是该表的主键列。 该表的每一行包含一封电子邮件。电子邮件将不包含大写字母。
编写一个 SQL 删除语句来 删除 所有重复的电子邮件,只保留一个id最小的唯一电子邮件。
以 任意顺序 返回结果表。 (注意: 仅需要写删除语句,将自动对剩余结果进行查询)
题解一
首先反向思维,找出不满足的,根据分组可以很简单找到
DELETE from Person
WHERE id NOT IN #不在满足条件内的肯定就是不满足的,直接删除
(SELECT ID #先把满足条件的找出来From(SELECT MIN(id) as IDFrom PersonGroup by Email)t
)题解二(官方解析)
# Write your MySQL query statement below
DELETE p1 FROM Person p1,Person p2
WHEREp1.Email = p2.Email AND p1.Id > p2.Id3.上升的温度(197)
表: Weather
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | recordDate | date | | temperature | int | +---------------+---------+ id 是这个表的主键 该表包含特定日期的温度信息
编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 不要求顺序 。
示例 1:
输入:
Weather 表:
+----+------------+-------------+
| id | recordDate | Temperature |
+----+------------+-------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+----+------------+-------------+
输出:
+----+
| id |
+----+
| 2 |
| 4 |
+----+
解释:
2015-01-02 的温度比前一天高(10 -> 25)
2015-01-04 的温度比前一天高(20 -> 30)解法一(DATEDIFF())
DATEDIFF 函数,可以计算两者的日期差
DATEDIFF('2007-12-31','2007-12-30'); # 1
DATEDIFF('2010-12-30','2010-12-31'); # -1
# Write your MySQL query statement below select a.ID
from weather as a cross join weather as b on datediff(a.recordDate, b.recordDate) = 1
where a.temperature > b.temperature;解法二(TIMESTAMPDIFF())
TIMESTAMPDIFF能干什么,可以计算相差天数、小时、分钟和秒,相比于datediff函数要灵活很多。格式是时间小的前,时间大的放在后面。 计算相差天数
select a.ID
from weather as a cross join weather as b on timestampdiff(day,a.recordDate, b.recordDate) = -1
where a.temperature > b.temperature;解法三(ADDDATE()力扣)
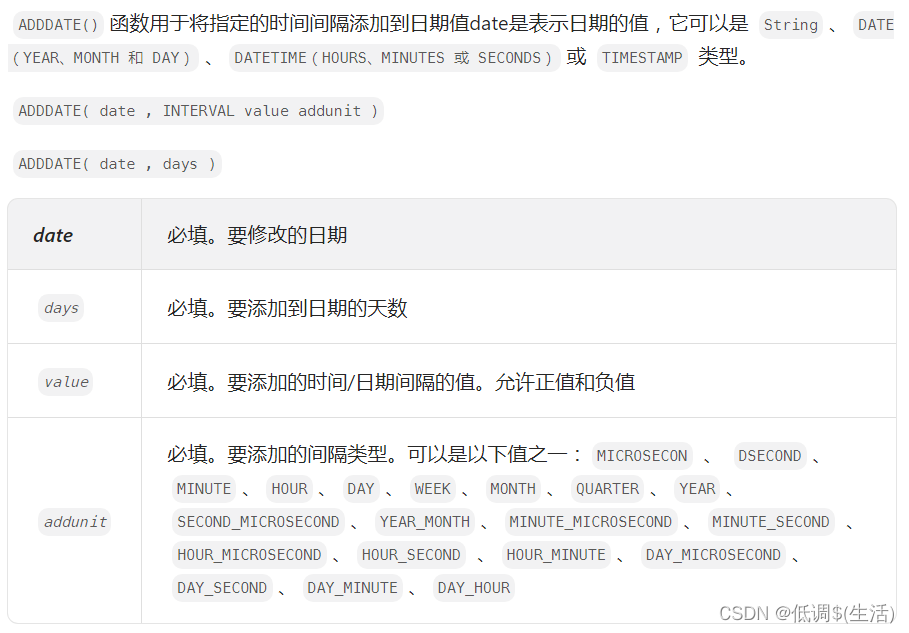
select a.id from weather a join weather b on (a.recorddate = adddate(b.recorddate,INTERVAL 1 day))
where a.temperature > b.temperature