前言
对于分析型数据库产品,通过增加服务节点实现集群水平扩容,并提升集群性能和容量,是运维的必要手段。
但是对于熟悉 ClickHouse 的工程师而言,听到“扩容”二字一定会头疼不已。开源 ClickHouse 的 MPP 架构导致扩容成本高,已是 ClickHouse 运维的核心痛点。
主要体现在:
-
流程全手动,无数据可靠性保证。
-
扩容期间性能开销大,通常需要暂停服务。
基于字节跳动内广泛的使用场景,ByteHouse 企业版基于开源社区 ClickHouse 进行了诸多优化,现已正式公测“水平扩容”功能。
如果将“ClickHouse”比作一辆汽车,那么此次ByteHouse升级则实现了扩容“手动挡”变“自动挡”,同时“自动档"过程中还能省油加速,使得扩容整体操作更顺滑流畅。
开源社区的实现方案
在 开源社区文档 中,社区工程师通常推荐使用“数据重分布”思路来解决扩容问题,但存在以下问题:
-
新增节点后,手动提升新节点的导入权重,或暂时停止旧节点的数据导入,直至数据均衡。这种配置要求 Distributed 表的分片键(Sharding-key)设置为 random,对于设定了指定的 sharding-key 的表,无法采用这种模式。此外,如果存量数据很大,通过该方式实现均衡非常缓慢,可能花费数天乃至数个月才能追平。
-
手动在节点之间移动分区,使节点间均衡。该方式需要大表均已设置比较合理的分区键(Partition Key),并且分片键也只能为 Random,并且需要手动计算分区的移动目标节点。
-
使用 ClickHouse Copier或 Insert Into Select 方式,将现存表全部重新插入实现均衡。该方式开销非常高,将占用大量的 CPU / 存储 IO / 网络 IO 资源。
此外,不管是哪种方式,都需要用户手动在新节点复制元数据、校验数据,拼装各环节流程,因此被称为“手动挡”。
ByteHouse 的优化方案
在字节跳动内部,业务的快速增长带来集群规划性能不足、亟需扩容的问题。ByteHouse 对内主要支撑数据看板、用户行为分析性等业务模块,因此对服务持续在线、性能迅速提升要求高,并且用户表的表结构也异常丰富。因此,社区提供的方案均不能满足字节内部业务诉求。
基于以上背景,ByteHouse 自研集群扩容能力,解决自动化流程的问题,也为用户提供了性能开销更低的扩容方式。
具体我们通过数据库引擎优化和操作界面优化两方面来实现。
数据库引擎优化
ByteHouse 的数据库引擎自研 Alter Table...Resharding命令,将一张表以分区的粒度进行重分布到另一张表。该命令支持两种方式:
-
重分布到其他集群的另一张表
-
重分布到本集群的另一张表
命令格式如下:
alter table <db>.<table> resharding partition <partition_expr> with <sharding_expr> to shard [shard_list]
通过该命令,可以实现提交从源表扩容到目标表的任务,该任务将实现 Split - Fetch,在原表拆分 Part,目标表拉取 Part,实现扩容。
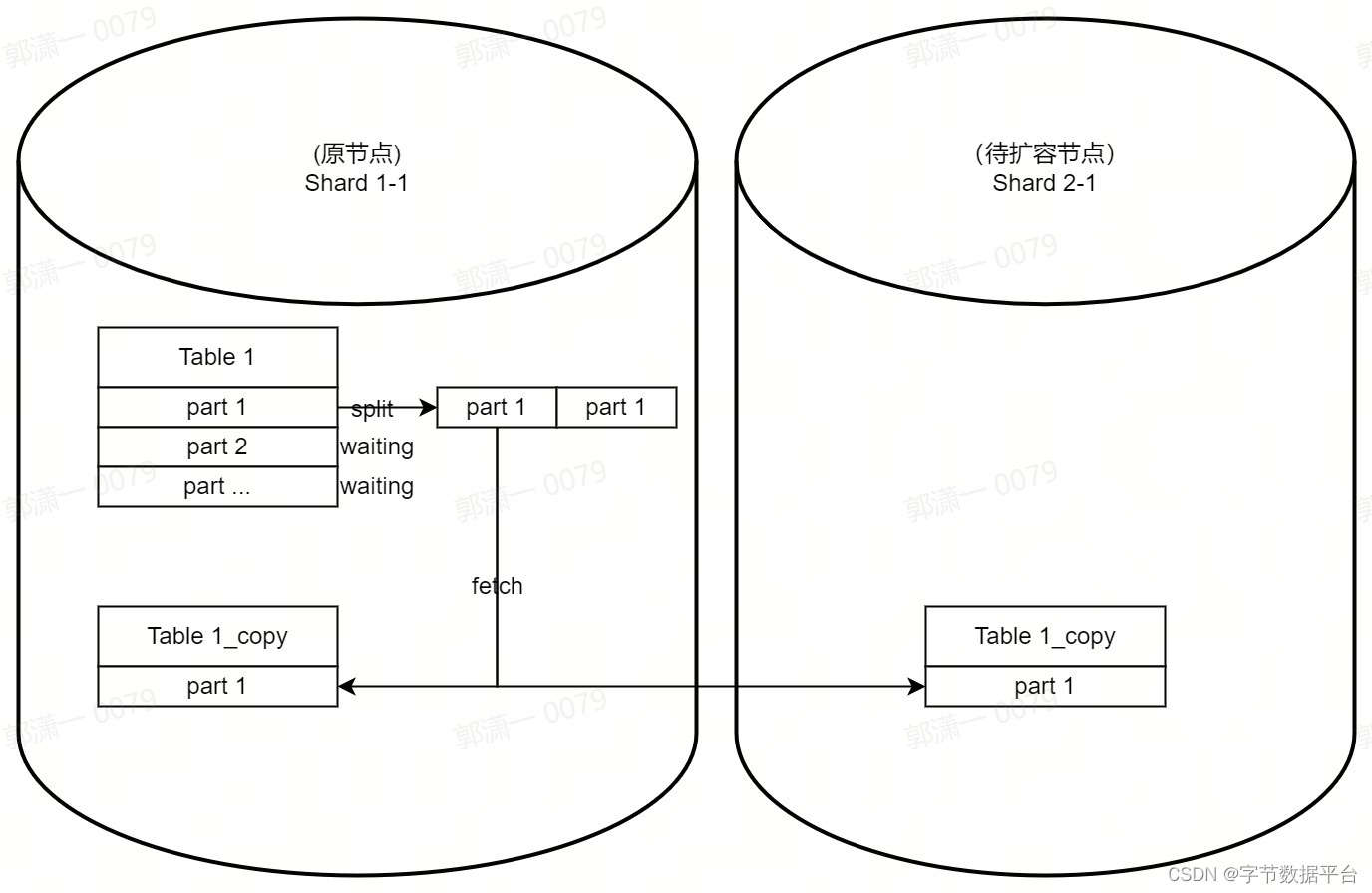
具体操作步骤如下:
-
对于要扩容的表 table,新建目标表,如 table1_new;
-
提交
Alter Table table1 Resharding Partition <partition_expr> with <sharding_expr> to table [table1_new_list];提交的任务会被存储到 ZooKeeper 上,后台线程负责调度执行; -
所有提交的任务逐个开始执行。每个任务首先执行 Part 拆分,将一个 Part 根据 Sharding-key 拆分为 N 份(N 为扩容后的分片数);
-
Part 拆分结束后,将 Part 信息发布到对应的分片上,对应不同分片上的目标表 table1_new 会进入 FETCHING 状态,开始拉取 Part;
-
等待这些 Part 被拉取完成,然后开始执行下一个任务,直至一张表的所有 Part 都被重分布完成
在一张表完成后,可以进行校验数据,删除旧表(table1),重命名新表(table1_new -> table1)。实现了一张表的扩容。
扩容全程可以通过系统表 system.reshard_partition追踪进度,取得状态。
这种扩容方式相比社区推荐的方式,有以下优势:
-
扩容的适应性好,对于是否设置分片键、分区键,均无硬性要求,都可以进行扩容。
-
性能损耗小。整个重分布过程为一个旁路计算任务,开销远低于
insert into select全局数据重新插入的方式。 -
执行过程中,数据保持可查询,下游数据看板、数据分析等服务不用暂停。目前在扩容过程中,ByteHouse暂时不支持写入。但就原理而言,扩容进度90%前都可写入,只需要最后阶段一次性 Resharding 在扩容任务执行过程中新写入的 Part 即可。因此,ByteHouse未来功能也有继续提升的空间。
操作界面优化
ByteHouse 数据库实现了 SQL 的底层能力进行数据重分布,实现了开销更低、适应性更强的重分布能力,但对于普通用户而言仍有使用门槛。
因此 ByteHouse 在控制台也支持水平扩容功能,组装底层能力,实现产品化。
通过 ByteHouse 控制台,可通过以下步骤完成集群的水平扩容:
1.在集群列表/详情页选择“更改配置”,选择“水平更配”。
2.用户选择集群更配后节点数,支持增加节点(水平扩容),也支持减少节点(水平缩容);
3.可在扩容前勾选“完成后自动重分布”,也可不勾选,在扩容后再手动重分布;如果勾选“自动重分布”,则需要选择需要在扩容后立即重分布的表。
4.界面会给出预估扩容时间。用户可以根据实际情况,对下游业务发出扩容公告
5.提交扩容任务,集群进入“运维任务中”状态。后台执行两阶段任务:
a.阶段1,新增节点。实际在进行新节点的初始化,并在新节点上新建元数据;
b.阶段2,集群节点完成增加后,则开始重分布,可以查看每张表的重分布进度。
6.上述步骤完成,集群恢复“运行中”状态。
通过界面化操作,ByteHouse 给用户的扩容流程带来了全新的便利:
-
全流程自动化,不再需要自行编写脚本。
-
也开放一小部分手动空间。例如,在扩容前可选立即重分布的表,对于剩余的表,可在扩容后再选择时间重分布任务,适应一些希望在业务低峰时扩容大表,进一步降低大表只读带来的影响。
-
包含容错处理,自动校验数据,流程便利可靠。
总结
ByteHouse 团队通过自研“水平扩容”能力,实现了数据库底层与界面支持数据重分布。相比于开源社区的方式,ByteHouse 的数据重分布有以下优势:
-
低 CPU / IO 开销,数据重分布期间可读;
-
全程自动化,界面化;
-
不依赖其他外置工具,在 ByteHouse 产品内闭环;
目前,水平扩容功能现已在 ByteHouse 企业版公测上线,同时支持私有化部署与火山引擎版本,欢迎体验。
点击跳转 【云原生数据仓库ByteHouse】 了解更多






![Go []uint8和string的爱恨情仇](https://img-blog.csdnimg.cn/76e0cc7413d9439eb73fd48634dfc7bf.jpeg)