D-VRNN模型和DD-VRNN模型
总体架构
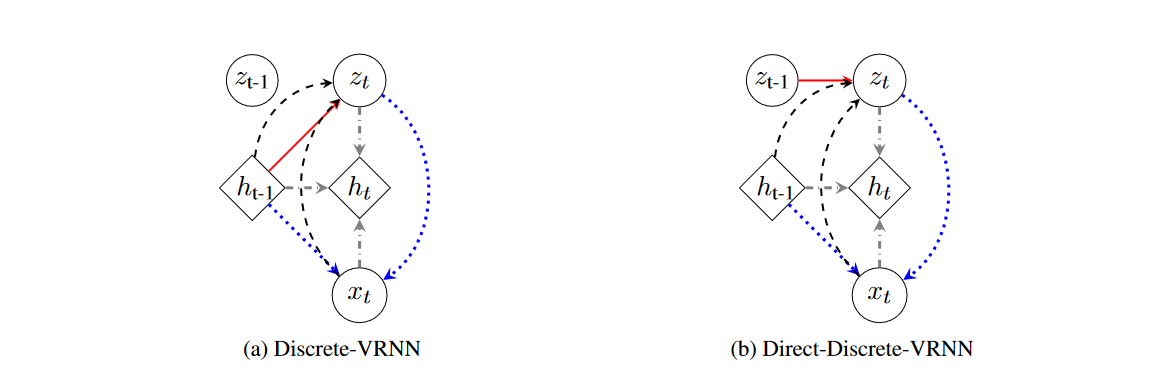
离散-可变循环变分自编码器(D-VRNN)和直接-离散-可变循环变分自编码器(DD-VRNN)概述。D-VRNN和DD-VRNN使用不同的先验分布来建模 z t z_t zt之间的转换,如红色实线所示。 x t x_t xt的再生成用蓝色虚线表示。状态级别的循环神经网络的循环关系以灰色虚线点划线表示。 z t z_t zt的推断过程以黑色虚线表示。
方法
原则上,变分递归神经网络(VRNN)在每个时间步都包含一个变分自编码器(VAE),这些VAE通过一个状态级的递归神经网络(RNN)相连。在这个RNN中,隐藏状态变量 h t − 1 h_{t-1} ht−1 编码了直到时间 t t t 的对话上下文。这种连接帮助VRNN模拟对话的时间结构(Chung等人,2015年)。模型的观测输入 x t x_t xt 是构建的话语嵌入。 z t z_t zt 是时间 t t t 时VRNN中的潜在向量。与Chung等人(2015年)的工作不同,我们模型中的 z t z_t zt 是一个离散的独热向量,其维度为 N N N,其中 N N N 是潜在状态的总数。
D-VRNN与DD-VRNN之间的主要区别在于 z t z_t zt 的先验设定。在D-VRNN中,我们假设 z t z_t zt 依赖于整个对话上下文 h t − 1 h_{t-1} ht−1,如图(a)中红色部分所示,这与Chung等人(2015年)的设定相同;而在DD-VRNN中,我们假设在先验中, z t z_t zt 直接依赖于 z t − 1 z_{t-1} zt−1,以模拟不同潜在状态之间的直接转换,如图(b)中红色部分所示。我们使用 z t z_t zt 和 h t − 1 h_{t-1} ht−1 来重新生成当前话语 x t x_t xt,而不是生成下一个话语 x t + 1 x_{t+1} xt+1,如图1中蓝色虚线所示。重生成的思想有助于恢复对话结构。接下来,递归神经网络利用 h t − 1 h_{t-1} ht−1, x t x_t xt 和 z t z_t zt 更新自身,并允许上下文随着对话的进行而传递,如图1中灰色点划线所示。最后,在推断中,我们用上下文 h t − 1 h_{t-1} ht−1 和 x t x_t xt 构建 z t z_t zt 的后验,并通过从后验中抽样来推断 z t z_t zt,如图1中黑色虚线所示。每个操作的数学细节在下文中描述。φ(·)τ 是高度灵活的特征提取函数,如神经网络。 φ τ x φ_{τ}^x φτx , φ z τ φzτ φzτ , φ τ p r i o r φ^{prior}_τ φτprior , φ τ e n c φ^{enc}_τ φτenc , φ τ d e c φ^{dec}_τ φτdec 是分别用于输入 x x x,潜在向量 z z z,先验,编码器和解码器的特征提取网络。
句子嵌入
用户话语 u t = [ w 1 , t , w 2 , t , … , w n w , t ] u_t = [w_{1,t}, w_{2,t}, \ldots, w_{n_w,t}] ut=[w1,t,w2,t,…,wnw,t] 和系统话语 s t = [ v 1 , t , v 2 , t , … , v n v , t ] s_t = [v_{1,t}, v_{2,t}, \ldots, v_{n_v,t}] st=[v1,t,v2,t,…,vnv,t] 是在时间 t t t 的用户话语和系统话语,其中 w i , j w_{i,j} wi,j 和 v i , j v_{i,j} vi,j 是单独的词语。两方话语的连接, x t = [ u t , s t ] x_t = [u_t, s_t] xt=[ut,st],是VAE中的观测变量。我们使用Mikolov等人(2013年)的方法来进行词嵌入,并对 u t u_t ut 和 s t s_t st 的词嵌入向量进行平均,得到 u ~ t \tilde{u}_t u~t 和 s ~ t \tilde{s}_t s~t。 u ~ t \tilde{u}_t u~t 和 s ~ t \tilde{s}_t s~t 的连接被用作 x t x_t xt 的特征提取,即 ϕ τ x ( x t ) = [ u ~ t , s ~ t ] \phi^x_\tau (x_t) = [\tilde{u}_t, \tilde{s}_t] ϕτx(xt)=[u~t,s~t]。 ϕ τ x ( x t ) \phi^x_\tau (x_t) ϕτx(xt) 是模型的输入。
Prior in D-VRNN
在D-VRNN中,先验是我们在观察数据之前对 z t z_t zt 的假设。在D-VRNN中,假设 z t z_t zt 的先验依赖于上下文 h t − 1 h_{t-1} ht−1,并遵循公式(1)中显示的分布是合理的,因为对话上下文是影响对话转换的关键因素。由于 z t z_t zt 是离散的,我们使用softmax函数来获取分布。
z t ∼ softmax ( ϕ τ prior ( h t − 1 ) ) (1) z_t \sim \text{softmax}(\phi^{\text{prior}}_\tau (h_{t-1}))\tag{1} zt∼softmax(ϕτprior(ht−1))(1)
Prior in DD-VRNN
DD-VRNN中的先验。 z t z_t zt 在公式(1)中对整个上下文 h t − 1 h_{t-1} ht−1 的依赖性,使得我们难以解开 z t − 1 z_{t-1} zt−1 与 z t z_t zt 之间的关系。但这种关系对于解码对话交换如何从一次流向下一次至关重要。因此,在DD-VRNN中,我们直接在先验中模拟 z t − 1 z_{t-1} zt−1 对 z t z_t zt 的影响,如公式(2)和图1(b)所示。为了将这个先验分布适配到变分推断框架中,我们用公式(3)中的 p ( z t ∣ z t − 1 ) p(z_t|z_{t-1}) p(zt∣zt−1) 来近似 p ( x t ∣ z t , z t ) p(x_t|z_{t}, z_{t}) p(xt∣zt,zt)。稍后,我们将展示设计的新先验在特定场景下的优势。
z t ∼ softmax ( ϕ τ prior ( z t − 1 ) [ ] (2) z_t \sim \text{softmax}(\phi^{\text{prior}}_\tau (z_{t-1})[\tag{2}] zt∼softmax(ϕτprior(zt−1)[](2)
它表示潜在状态 z t z_t zt 的先验分布直接依赖于前一时间步的潜在状态 z t − 1 z_{t-1} zt−1,并通过特征提取函数 ϕ τ prior \phi^{\text{prior}}_\tau ϕτprior 映射和softmax函数来确定。
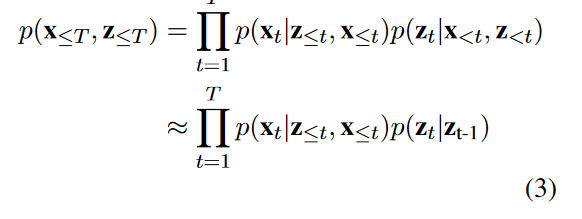
模型整体的概率分布可以近似为:
p ( x ≤ T , z ≤ T ) ≈ ∏ t = 1 T p ( x t ∣ z ≤ t , x < t ) p ( z t ∣ z t − 1 ) (3) p(x_{\leq T}, z_{\leq T}) \approx \prod_{t=1}^{T} p(x_t|z_{\leq t}, x_{<t})p(z_t|z_{t-1})\tag{3} p(x≤T,z≤T)≈t=1∏Tp(xt∣z≤t,x<t)p(zt∣zt−1)(3)
生成
z t z_t zt 是在上下文下当前对话交换的概括。我们使用 z t z_t zt 和 h t − 1 h_{t-1} ht−1 来重构当前的话语 x t x_t xt。这种 x t x_t xt 的重生产允许我们恢复对话结构。
我们使用两个RNN解码器,dec1和dec2,分别由参数 γ 1 \gamma_1 γ1 和 γ 2 \gamma_2 γ2 参数化,以分别生成原始的 u t u_t ut 和 s t s_t st。 c t c_t ct 和 d t d_t dt 是dec1和dec2的隐藏状态。上下文 h t − 1 h_{t-1} ht−1 和特征提取向量 ϕ τ z ( z t ) \phi^z_\tau (z_t) ϕτz(zt) 被连接起来,形成dec1的初始隐藏状态 h 0 dec1 h^{\text{dec1}}_0 h0dec1。 c ( n w , t ) c(n_w,t) c(nw,t) 是dec1的最后一个隐藏状态。由于 v t v_t vt 是 u t u_t ut 的响应,并且会受到 u t u_t ut 的影响,我们将 c ( n w , t ) c(n_w,t) c(nw,t) 与 d 0 d_0 d0 连接起来,将信息从 u t u_t ut 传递给 v t v_t vt。这个连接向量被用作dec2的 h 0 dec2 h^{\text{dec2}}_0 h0dec2。这个过程在公式(4)和(5)中显示。
c 0 = [ h t − 1 , ϕ τ z ( z t ) ] c_0 = [h_{t-1}, \phi^z_\tau (z_t)] c0=[ht−1,ϕτz(zt)]
w ( i , t ) , c ( i , t ) = f γ 1 ( w ( i − 1 , t ) , c ( i − 1 , t ) ) (4) w(i,t), c(i,t) = f_{\gamma_1}(w(i-1,t), c(i-1,t))\tag{4} w(i,t),c(i,t)=fγ1(w(i−1,t),c(i−1,t))(4)
d 0 = [ h t − 1 , ϕ τ z ( z t ) , c ( n w , t ) ] d_0 = [h_{t-1}, \phi^z_\tau (z_t), c(n_{w},t)] d0=[ht−1,ϕτz(zt),c(nw,t)]
v ( i , t ) , d ( i , t ) = f γ 2 ( v ( i − 1 , t ) , d ( i − 1 , t ) ) (5) v(i,t), d(i,t) = f_{\gamma_2}(v(i-1,t), d(i-1,t))\tag{5} v(i,t),d(i,t)=fγ2(v(i−1,t),d(i−1,t))(5)
递归过程
状态级RNN根据以下等式(6)更新其隐藏状态 h t h_t ht 与 h t − 1 h_{t-1} ht−1。 f θ f_\theta fθ 是由参数 θ \theta θ 参数化的RNN。
h t = f θ ( ϕ τ z ( z t ) , ϕ τ x ( x t ) , h t − 1 ) (6) h_t = f_\theta (\phi^z_\tau (z_t), \phi^x_\tau (x_t), h_{t-1}) \tag{6} ht=fθ(ϕτz(zt),ϕτx(xt),ht−1)(6)
推断
我们根据上下文 h t − 1 h_{t-1} ht−1 和当前话语 x t x_t xt 来推断 z t z_t zt,并构建 z t z_t zt 的后验分布,通过另一个softmax函数,如等式(7)所示。一旦我们得到了后验分布,我们应用Gumbel-Softmax来取 z t z_t zt 的样本。D-VRNN和DD-VRNN在它们的先验上有所不同,但在推断上没有不同,因为我们假设在先验中 z t z_t zt 之间的直接转换而不是在推断中。
z t ∣ x t ∼ softmax ( ϕ τ e n c ( h t − 1 ) , ϕ τ x ( x t ) ) (7) z_t|x_t \sim \text{softmax}(\phi^{enc}_\tau (h_{t-1}), \phi^x_\tau (x_t)) \tag{7} zt∣xt∼softmax(ϕτenc(ht−1),ϕτx(xt))(7)
这段文字描述了变分递归神经网络(VRNN)的损失函数,以及为了解决变分自编码器(VAE)中潜在变量消失的问题,如何结合了两种损失函数:bow-loss和Batch Prior Regularization (BPR)。以下是对该段落的翻译以及相关公式的解释:
损失函数
VRNN的目标函数是其在每个时间步的变分下界,如等式(8)所示(Chung等人,2015)。为了缓解VAE中潜在变量消失的问题,我们结合了bow-loss和Batch Prior Regularization (BPR)(Zhao等人,2017,2018)到最终的损失函数中,并引入了可调整的权重 λ \lambda λ,如等式(9)所示。
L VRNN = E q ( z ≤ T ∣ x ≤ T ) [ log p ( x t ∣ z ≤ t , x < t ) ] + \mathcal{L}_{\text{VRNN}} = \mathbb{E}_{q(z_{\leq T}|x_{\leq T})}[\log p(x_t | z_{\leq t},x_{<t})]+ LVRNN=Eq(z≤T∣x≤T)[logp(xt∣z≤t,x<t)]+
∑ t = 1 T − KL ( q ( z t ∣ x ≤ t , z < t ) ∥ p ( z t ∣ x < t , z < t ) ) (8) \sum_{t=1}^{T} -\text{KL}(q(z_t | x_{\leq t},z_{<t}) \| p(z_t | x_{<t},z_{<t}))\tag{8} t=1∑T−KL(q(zt∣x≤t,z<t)∥p(zt∣x<t,z<t))(8)
L D-VRNN = L VRNN-BPR + λ ∗ L bow (9) \mathcal{L}_{\text{D-VRNN}} = \mathcal{L}_{\text{VRNN-BPR}} + \lambda * \mathcal{L}_{\text{bow}} \tag{9} LD-VRNN=LVRNN-BPR+λ∗Lbow(9)
状态转移概率计算
一种既能数值表示又能视觉表示对话结构的好方法是构建一个潜在状态之间的转移概率表。这样的转移概率也可以用来设计在强化学习(RL)训练过程中的奖励函数。我们因为D-VRNN和DD-VRNN的先验不同,所以分别计算它们的转移表。
D-VRNN
从等式(6)我们知道 h t h_t ht 是 x ≤ t x_{\leq t} x≤t 和 z < t z_{<t} z<t 的函数。结合等式(1)和(6),我们发现 z t z_t zt 是 x ≤ t x_{\leq t} x≤t 和 z < t z_{<t} z<t 的函数。因此, z < t z_{<t} z<t 对 z t z_t zt 有一个间接的影响通过 h t − 1 h_{t-1} ht−1。这个间接影响加强了我们的假设,即前面的状态 z < t z_{<t} z<t 影响未来的状态 z t z_t zt,但也使得恢复一个清晰的结构和解开 z t − 1 z_{t-1} zt−1 对 z t z_t zt 直接影响变得困难。
为了更好地可视化对话结构并与基于HMM的模型进行比较,我们通过估算二元转移概率表来量化 z t − 1 z_{t-1} zt−1 对 z t z_t zt 的影响,其中 p i , j = # ( s t a t e i , s t a t e j ) # ( s t a t e i ) p_{i,j} = \frac{\#(state_i,state_j)}{\#(state_i)} pi,j=#(statei)#(statei,statej)。分子是有序对( s t a t e i , t − 1 state_i, t-1 statei,t−1, s t a t e j , t state_j, t statej,t)的总数,分母是数据集中 s t a t e i state_i statei 的总数。我们选择一个二元转移表而不是一个更大 n n n 的 n n n-gram转移表,因为最近的上下文通常是最相关的,但应该注意的是,与HMM模型不同,我们模型中的转移程度既不是有限的也不是预先确定的,因为 z t z_t zt 捕获了所有上下文。根据不同的应用,可能会选择不同的 n n n。
命名实体离散变分递归神经网络(NE-D-VRNN)
在任务导向对话系统中,某些命名实体的存在,如食物偏好,对于确定对话的阶段起着关键作用。为了确保潜在状态捕获此类有用信息,我们在计算等式(9)中的损失函数时,对命名实体赋予更大的权重。这些权重鼓励重构的话语含有更多正确的命名实体,因此影响潜在状态有更好的表示。我们将这个模型称为NED-VRNN(命名实体离散变分递归神经网络)。