PROGRAMMING TENSOR CORES: NATIVE VOLTA TENSOR CORES WITH CUTLASS 源自于 GTC Silicon Valley-2019: cuTENSOR: High-performance Tensor Operations in CUDA,介绍了 CUTLASS 1.3 中基于 Volta Tensor Core 实现高效矩阵乘法计算的策略。主要内容为以下三点:
- CUDA 10.1中
mma.sync指令介绍; - Global Memory–>Shared Memory–>RF 的128 bit 访问实现;
- Shared Memory 上的无冲突转置。
双缓冲内容缺失。
mma
无论是 slides 中的介绍还是源码实现均是采用自底向上的思路,根据硬件规格确定每个层次上的分块策略。Volta Tensor Core 计算能力是4x4x4,HMMA.884.F16.F16需要两个 Tensor Core 计算两遍。
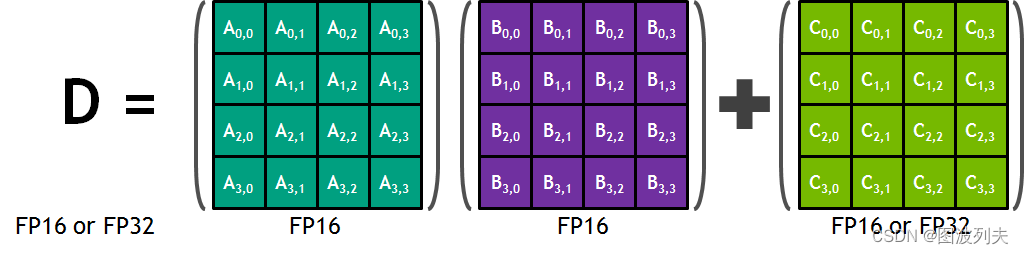
CUTLASS 中封装的 mma 指令计算 m16n16k4的矩阵乘法。

参考 Modeling Deep Learning Accelerator Enabled GPUs 中的介绍。Warp 内四个连续线程划分为一个 threadgroup,两个 threadgroup 组成一个 octet。每个 octet 串行计算一个 Quad Pair。计算不同 QP 时是具备数据复用的,如下图所示:

下图展示了 QP0中线程与数据的对应关系。

Permuted Shared Memory Tiles
对于全局内存上的列优先矩阵 A,每个线程加载8个元素则可以加载 m64k4的分块。然而根据前面介绍的线程和数据的映射关系,直接保存到 Shared Memory 的话,线程取用时会出现 bank 冲突。CUTLASS 中采用了一种无冲突共享内存排列来实现数据转置。


第二组线程
 第三组线程
第三组线程

第四组线程

Pointer Offsets For Permuted Shared Memory
Volta884Multiplicand 中定义了被乘数( A 和 B)的迭代器:
- TileLoadIterator:从 Global Memory 循环读取数据到寄存器;
- Volta884ThreadblockMultiplicandStoreIterator:负责 Permuted Shared Memory 的摆放,Volta884ThreadblockMultiplicandStoreIterator::ThreadOffset 与下图对应;
- Volta884WarpMultiplicandLoadIterator:从 Shared Memory 取数据。

Conflict-Free Shared Memory Loads
从 Shared Memory 上加载数据到线程寄存器,仍然分为4步。前两步线程访问的数据相同,因此共计加载 32x4的 A 矩阵。Shared Memory 上的数据可供使用两次。




Spatially Interleaved
如前所述,每个线程从 Shared Memory 读取8个元素。而执行mma指令时,每个线程提供4个元素。因此计算输出会出现空间交错。对 A 和 B 矩阵进一步分块,一次加载可以支持4次计算。


参考资料:
- # [DOC] Where does cutlass’ detailed GEMM kernel? #526
- Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
- Modeling Deep Learning Accelerator Enabled GPUs
- gpgpu-sim_distribution
- 理解Tensor Core
- Flexible Performant GEMM Kernels on GPUs
- CUDA Tensor Core编程
- PROGRAMMING TENSOR CORES: NATIVE VOLTA TENSOR CORES WITH CUTLASS
- The NVIDIA Titan V Deep Learning Deep Dive: It’s All About The Tensor Cores
- 9.7.13.4.1. Matrix Fragments for mma.m8n8k4 with .f16 floating point type
- Numerical Behavior of NVIDIA Tensor Cores
- CUDA Ampere Tensor Core HGEMM 矩阵乘法优化笔记 —— Up To 131 TFLOPS!
- If we have two or four memory requests by a warp, do they need coalesced access/contiguity? #328
- Do bank conflicts increase when using more shared memory?
- How does parameter computeType affect the computation?
- 2.1.10. GEMM Algorithms Numerical Behavior
- cuBLAS的使用
- RAFT在Knowhere上的一些评估测试[1]
- How does parameter computeType affect the computation?
- cudnn-frontend/tree/main/samples/samples/conv_sample.cpp
- Is a union in C++ actually a class?
- A Generalized Micro-kernel Abstraction for GPU Linear Algebra
- Implementing Strassen’s Algorithm with CUTLASS on NVIDIA Volta GPUs
- Double-buffering in shared memory, details? #227
- Efficient GEMM in CUDA
- Thread synchronization with syncwarp
- Using CUDA Warp-Level Primitives
- CUDA微架构与指令集(3)-SASS指令集分类
- VOLTA Architecture and performance optimization
- How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog
- Determining registers holding the data after executing LDG.E.128



![[autojs]autojs开关按钮的简单使用](https://img-blog.csdnimg.cn/e8af4a4efb98449f81bc9f91b6b4732a.png)