只需要鼠标的点击就可以自动修图的产品,火爆问世,可以说是超越PS,神一般的存在了,而且没有门槛,对于普通大众来说直接可以上手使用,这个是PS完全不具备的。更关键的是,这款产品跟PS明显区别在于,PS一般来说是做美化处理为主,而Drag Your GAN可以让眼睛真的睁开和闭上,嘴角上扬是可以露出牙齿的,姿态的改变跟真人在摆POSE一般,非常有趣。
大家可以点击下面两个视频感受下,如何神奇的修图:
DragGAN视频1
DragGAN视频2
因为这个DragGAN是基于StyleGAN2的模型,所以在看这篇文章之前,建议先看下StyleGAN系列,熟悉它们的架构:NVIDIA的StyleGAN、StyleGAN2、StyleGAN3系列论文解读,梳理基于风格的生成器架构
论文中的一张图开始介绍:

用户只需要点击图像上的几个手柄点(红点)和目标点(蓝点),我们的方法就会移动手柄点,精确到达相应的目标点。用户可以选择绘制灵活区域(较亮的区域)的掩码,保持图像的其余部分固定。这种灵活的基于点的操作可以控制许多空间属性,如姿态、形状、表情和跨不同对象类别的布局。
主要有三大特点:
1.灵活性:能够控制生成对象的位置、姿态、形状、表情、布局等不同的空间属性
2.精度:能够对空间属性进行高精度控制
3.通用性:适用于不同的对象类别,而不局限于某一类别
对于GAN可以分为无条件GAN和有条件GAN
1.无条件的GAN:将低维随机采样的潜在向量转换为逼真图像的生成模型。它们使用对抗性学习进行训练,可用于生成高分辨率的逼真图像,比如大多数像StyleGAN这样的GAN模型,这些模型不能直接对生成的图像进行可控编辑。
2.有条件的GNA:对图像和分割图的联合分布进行建模,然后计算与编辑后的分割图相对应的新图像,从而实现可以编辑。
虽然目前的文字生成图片很火,但是语义控制输出,也只能在一个粗糙的高级语义层面的控制,不能对图像的空间属性进行细粒度控制。
总的来说这篇论文还是比较简单,DragGAN模型主要分为两大块:运动监督和手柄点跟踪。
1、Motion Supervision运动监督
基于特征的运动监督,驱动手柄点(红点)向目标位置(蓝点)移动,从而在这个迭代过程中进行特征的更新。具体来说,运动监督是通过移位特征补丁损失来实现的,从而优化了潜在代码(同StyleGAN系列中讲述的隐藏代码)
DragGAN还允许用户选择性地绘制感兴趣的区域,以执行特定于区域的编辑。由于DragGAN不依赖于任何额外的网络,如RAFT,它实现了高效的操作,在大多数情况下,单块RTX 3090 GPU上只需要几秒钟。这允许实时的交互式编辑会话,用户可以在不同的布局上快速迭代,直到实现所需的输出。
跟简单地应用扭曲的传统形状变形方法不同,我们的变形是在GAN的学习图像流形上执行的,它倾向于服从底层对象结构。例如,我们的方法可以使闭塞的内容产生幻觉,就像狮子嘴里的牙齿一样,也可以随着物体的刚性而变形,就像马腿的弯曲一样。
视频中看到的那样,还给用户开发了一个GUI,通过简单地单击图像来交互式地执行操作。定性和定量比较都证实了我们的方法优于UserControllableLT(通过转换GAN的潜在向量实现基于点的编辑,但是它的这种方法只支持在图像上拖动单个点进行编辑,而不能很好地处理多点约束。另外,控制不精确,即编辑后往往达不到目标点),下面是两者的对比图:

2、Point Tracking手柄点跟踪
在特征空间中通过最近邻搜索进行点跟踪。然后重复这个优化过程,直到手柄点达到目标点。为了跟踪手柄点,一种显而易见的方法是在连续帧之间进行光流估计(估计两幅图像之间运动场的经典问题),比如用的最广的RAFT。还有一种就是采用“particle video”,粒子视频流获得视频序列中的特征点运动轨迹,并对获得的运动轨迹进行提取,然后利用最长共同子序列LCS(Longest Common Subsequence)聚类轨迹,得到运动的主流方向,这种方法叫做PIPs,PIPs考虑跨多个帧的信息,因此比以前的方法更好地处理远距离跟踪。
而在DragGAN中,我们将不使用任何上述方法或额外的神经网络的情况下对GAN生成的图像进行点跟踪。因为GAN的特征空间具有足够的判别性,使得跟踪可以简单地通过特征匹配来实现。尽管我们的方法很简单,但是在实验中的结果,优于最先进的点跟踪方法,包括RAFT和PIPs。
3、整个迭代流程
我们先来看输入图像经过上述的两大块(运动监督和点跟踪)的处理之后,得到新的图像的过程图:

初始化图像,通过GAN的生成器生成潜在编码w,通过鼠标点击手柄点(红点)和需要达到位置的目标点(蓝点),然后运动监督将驱动手柄点往目标点位置靠近,并更新潜在编码w为w'。在这个过程中我们需跟踪手柄点位置,通过特征空间具备的判别性来更新手柄点的位置,当然这个时候也会同时更新迭代潜在编码,一直迭代直到目标点为止或者满意了也可提前终止。
更详细的介绍,如下图:

运动监督是通过在生成器的特征映射上移动补丁损失来实现,我们通过最近邻搜索对相同的特征空间进行点跟踪。
其中手柄点定义为
对应的目标点为
4、技术实现细节
4.1、运动监督
先来看下运动监督是怎么具体操作的,需要用到哪些数学公式。
我们考虑StyleGAN2的第6块之后的特征映射F,由于在分辨率和判别性之间有良好的权衡,在所有特征中表现最好。我们通过双线性插值来调整F的大小,使其具有与最终图像相同的分辨率。其中想了解双线性插值的,刚好可以看下前几天发的一篇博文:LIBSVM与LIBLINEAR支持向量机库对模式识别与回归的可视化代码实践
当然对于双线性插值,熟悉StyleGAN3就更清晰了,简单来说就是在X,Y方向相邻像素之间分别采样,然后在采样点之间插入数值。这个也是StyleGAN3对StyleGAN2的一个改进,前面的链接也有介绍,欢迎查阅。
将一个手柄点移动到目标点
,我们的想法是监督
外围的一小块区域(红圈)朝
向前移动一小步(蓝圈)。我们使用
表示到
的距离小于
的像素,则我们的运动监督损失公式:
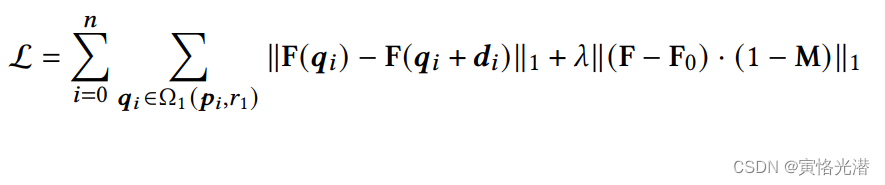 其中F(q)表示F在像素q处的特征值,
其中F(q)表示F在像素q处的特征值,为初始图像对应的特征映射,
是
到
的归一化向量,公式:
另外在给定二进制掩码M的情况下,我们保持没有掩码的区域固定,重建损失表示为第二项。
4.2、点跟踪
我们在前面也说了,不使用光流估计和粒子视频流,因为在GAN中的判别特征能够很好地捕获密集的对应关系,因此可以通过特征补丁中的最近邻搜索有效地进行跟踪。我们将初始处理点的特征表示为
我们将周围的补丁表示为:
然后在中搜索
的最近邻,就可以得到跟踪点
,公式:
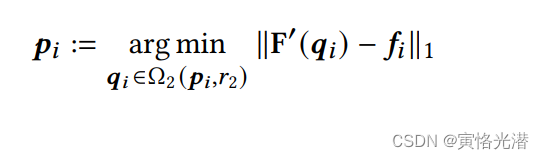
通过这种方式,更新,就能够一直跟踪手柄点了,对于多个手柄点,我们对每个点应用相同的过程即可。
4.3、超参设置
代码是基于PyTorch实现的,目前暂时还没有开放源码。难道要到月末最后一天去了?哈哈
我们使用Adam优化器对FFHQ的潜在代码进行优化,步长为0.002,AFHQCat,LSUN Car和其他数据集的步长设置为0.001。超参数设置为 λ=20,=3,
=12。在我们的实现中,当所有手柄点与相应目标点的距离不超过d像素时,我们停止优化过程,其中,不超过5个手柄点将d设置为1,否则设置为2。
来一张跟PIPs和RAFT的对比实验图:
可以看到我们的方法更精确地跟踪了点,从而产生更精确的编辑。
5、缺陷
前面都显示了DragGAN的强大,当然也会存在缺点,就是当创建偏离训练分布的人体姿势可能导致伪影。此外,无纹理区域的手柄点在跟踪过程中有时会出现更大的漂移,这个一般是在纹理丰富区域效果就会呈现的很好。如下图:
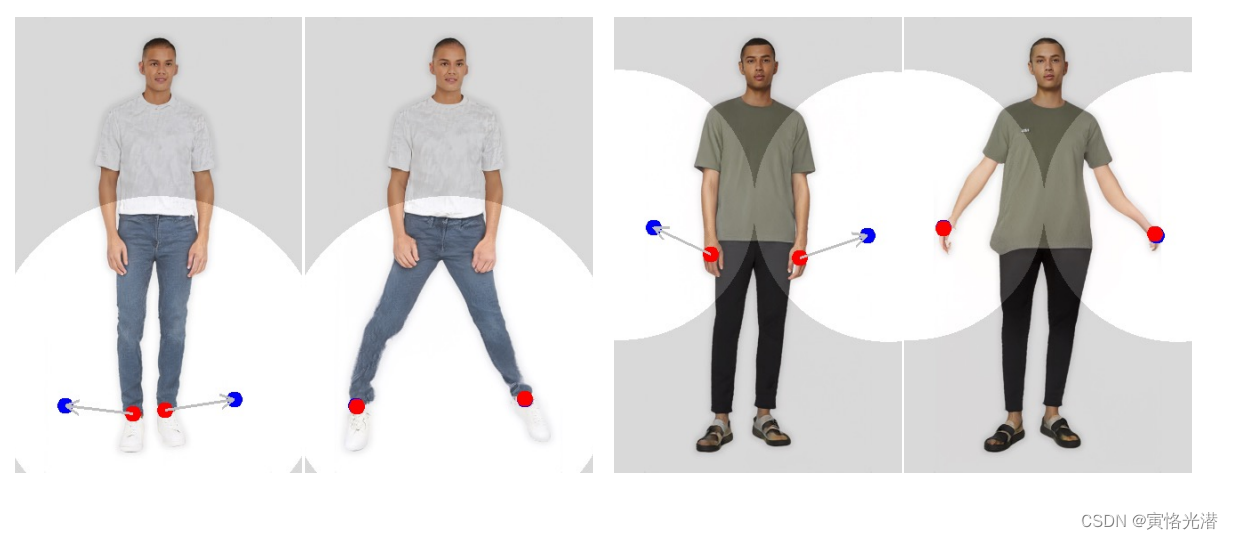

虽然我们的方法具有一定的外推能力,可以在训练图像分布之外创建图像,比如下面这张图,一个极度张开的嘴巴和一个大轮子。但是由于分布在了训练数据集之外,这样容易失真,可以看到车轮变形了。

好了,更多细节可以查阅原论文,相对来说这篇是在StyleGAN2基础上的改进,熟悉StyleGAN的来看就显得很清晰明了。
引用:
论文地址:Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
源码说是6月发布,眼看6月已快过完,暂时还没有公布源码:
github:https://github.com/XingangPan/DragGAN