问题:
这几天工作遇到了一个问题。千万级别的表,每秒钟产生很多数据,select count(id) from table where flag = 1 and create_time < 2023.11.07;分区表,range级别,已经是走create_time列上的索引,flag的值只有0,1。厂商业务卡死在这条sql语句。有什么办法还能再通过什么手段优化吗。大家不妨想一想。
初看已经走索引,range级别好像已经够优秀了,但是执行计划产生了回表,看查找的列不是select *。很好我们可以通过创建联合索引避免回表。
create index inx_caf on table(create_time,flag);
实验1(name的索引选择性还不错),验证具体有没有优化:
-- 创建结构相似的表
create table lian(id int primary key,name varchar(10),flag varchar(10),unique key inx_name(name),key inx_flag(flag)
)-- 创建存储过程,插入flag分别为0,1的数据
delimiter $$ # 定义结束符
drop procedure if exists addTestData; # 存储过程名叫:addTestData
create procedure addTestData()
begin
declare number int;
set number = 20001;
while number <= 30000 #插入N条数据
do
insert into lian
values(null,number+'1',0); # 为了区分姓名,我们加上后缀
set number = number + 1;
end
while;
end $$;select count(*) from lian;
select count(*) from lian where flag = 0;
select count(*) from lian where flag = 1;

已知:现在表中name列和flag列分别有单列索引,我们按找卡死的sql语句运行。
explain
select count(id) from lian where flag = 1 and name < '1000';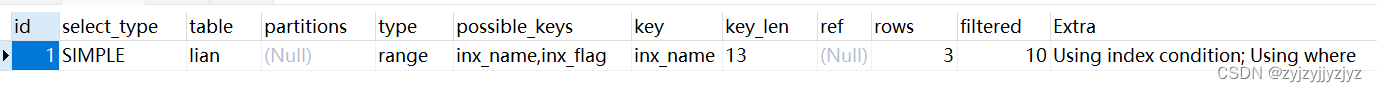
explain format=json
select count(id) from lian where flag = 1 and name < '1000';
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "5.21"},"table": {"table_name": "lian","access_type": "range","possible_keys": ["inx_name","inx_flag"],"key": "inx_name","used_key_parts": ["name"],"key_length": "13","rows_examined_per_scan": 3,"rows_produced_per_join": 0,"filtered": "10.00","index_condition": "(`test2`.`lian`.`name` < '1000')","cost_info": {"read_cost": "5.15","eval_cost": "0.06","prefix_cost": "5.21","data_read_per_join": "9"},"used_columns": ["id","name","flag"],"attached_condition": "(`test2`.`lian`.`flag` = 1)"}}
}可以看到这就如厂商卡到的sql语句一样,并且范围查询如果 范围过大的话,执行计划就会变成全表扫描。执行代价5.21
创建联合索引:
create index inx_naf on lian(name,flag);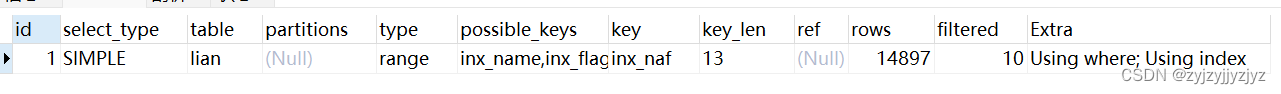
可以看到联合索引消除了回表操作。让我们看看执行代价:
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "2.22"},"table": {"table_name": "lian","access_type": "range","possible_keys": ["inx_name","inx_flag","inx_naf"],"key": "inx_naf","used_key_parts": ["name"],"key_length": "13","rows_examined_per_scan": 3,"rows_produced_per_join": 0,"filtered": "10.00","using_index": true,"cost_info": {"read_cost": "2.16","eval_cost": "0.06","prefix_cost": "2.22","data_read_per_join": "9"},"used_columns": ["id","name","flag"],"attached_condition": "((`test2`.`lian`.`flag` = 1) and (`test2`.`lian`.`name` < '1000'))"}}
}2.22比之走单列索引的5.21小了很多(我后续做了实验,小这么多的原因是因为name列是唯一约束,或者说name列的唯一值特别多。后续也做了唯一值特别少的代价实验,请往后看)
联合索引的考量
众所周知联合索引设在前谁在后是有考量的,规则就是谁的选择性好(相对来说唯一值多)谁就放在前面 ,所以我先入为主就把create_time放在了前面。让我们测试下flag在前面的情况。
-- 还没删除naf
create index inx_fan on lian(flag,name);
explain
select count(id) from lian where flag = 1 and name < '1000';
explain format=json
select count(id) from lian where flag = 1 and name < '1000'; 可以看到在两个索引上还是选择了naf。
可以看到在两个索引上还是选择了naf。
删除naf:

优化器没有选择fan,而是选择了最初的单列索引,产生回表。
让我们强制走fan,看看执行代价:
explain format=json
select count(id) from lian force index(inx_fan) where flag = 1 and name < '1000';explain
select count(id) from lian force index(inx_fan) where flag = 1 and name < '1000'; 变成了索引树扫描而非range。
变成了索引树扫描而非range。
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "35755.00"},"table": {"table_name": "lian","access_type": "index","possible_keys": ["inx_fan"],"key": "inx_fan","used_key_parts": ["flag","name"],"key_length": "26","rows_examined_per_scan": 29795,"rows_produced_per_join": 993,"filtered": "3.33","using_index": true,"cost_info": {"read_cost": "35556.39","eval_cost": "198.61","prefix_cost": "35755.00","data_read_per_join": "31K"},"used_columns": ["id","name","flag"],"attached_condition": "((`test2`.`lian`.`flag` = 1) and (`test2`.`lian`.`name` < '1000'))"}}
}执行代价35755特别大,所以联合索引不可以把flag放在最前面,索引选择性特别低。
实验2(name列的索引选择度也特别低)
create table lian3(id int primary key,name varchar(10),flag varchar(10),key inx_flag(flag)
)delimiter $$ # 定义结束符
drop procedure if exists addTestData; # 存储过程名叫:addTestData
create procedure addTestData()
begin
declare number int;
set number = 40001;
while number <= 45000 #插入N条数据
do
insert into lian3
values(null,'h',0); # 为了区分姓名,我们加上后缀
set number = number + 1;
end
while;
end $$;call addTestData();分别看name和flag的索引选择度
select count(distinct(name))/count(*),count(distinct(name)),count(*) from lian3;
select count(distinct(flag))/count(*),count(distinct(flag)),count(*) from lian3;

explain
select count(id) from lian3 where flag = 1 and name < 'e';
explain format=json
select count(id) from lian3 where flag = 1 and name < 'e';全表扫描执行代价:

{"query_block": {"select_id": 1,"cost_info": {"query_cost": "6035.00"},"table": {"table_name": "lian3","access_type": "ALL","possible_keys": ["inx_flag"],"rows_examined_per_scan": 29690,"rows_produced_per_join": 989,"filtered": "3.33","cost_info": {"read_cost": "5837.09","eval_cost": "197.91","prefix_cost": "6035.00","data_read_per_join": "30K"},"used_columns": ["id","name","flag"],"attached_condition": "((`test2`.`lian3`.`flag` = 1) and (`test2`.`lian3`.`name` < 'e'))"}}
}创建name单列索引,执行计划:
create index inx_name on lian3(name);因为name的选择度特别低,所以必须强制走索引
explain
select count(id) from lian3 force index(inx_name) where flag = 1 and name < 'e';explain format=json
select count(id) from lian3 force index(inx_name) where flag = 1 and name < 'e';
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "20784.01"},"table": {"table_name": "lian3","access_type": "range","possible_keys": ["inx_name"],"key": "inx_name","used_key_parts": ["name"],"key_length": "13","rows_examined_per_scan": 14845,"rows_produced_per_join": 1484,"filtered": "10.00","index_condition": "(`test2`.`lian3`.`name` < 'e')","cost_info": {"read_cost": "20487.11","eval_cost": "296.90","prefix_cost": "20784.01","data_read_per_join": "46K"},"used_columns": ["id","name","flag"],"attached_condition": "(`test2`.`lian3`.`flag` = 1)"}}
}创建联合索引naf,执行代价:
create index inx_naf on lian3(name,flag);
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "5993.18"},"table": {"table_name": "lian3","access_type": "range","possible_keys": ["inx_flag","inx_name","inx_naf"],"key": "inx_naf","used_key_parts": ["name"],"key_length": "13","rows_examined_per_scan": 14845,"rows_produced_per_join": 1484,"filtered": "10.00","using_index": true,"cost_info": {"read_cost": "5696.29","eval_cost": "296.90","prefix_cost": "5993.19","data_read_per_join": "46K"},"used_columns": ["id","name","flag"],"attached_condition": "((`test2`.`lian3`.`flag` = 1) and (`test2`.`lian3`.`name` < 'e'))"}}
}创建联合索引fan,并且删除naf,执行代价:
create index inx_fan on lian3(flag,name);
drop index inx_naf on lian3;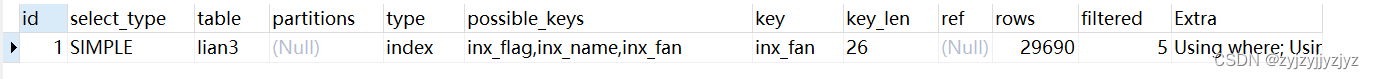
{"query_block": {"select_id": 1,"cost_info": {"query_cost": "6035.00"},"table": {"table_name": "lian3","access_type": "index","possible_keys": ["inx_flag","inx_name","inx_fan"],"key": "inx_fan","used_key_parts": ["flag","name"],"key_length": "26","rows_examined_per_scan": 29690,"rows_produced_per_join": 1484,"filtered": "5.00","using_index": true,"cost_info": {"read_cost": "5738.10","eval_cost": "296.90","prefix_cost": "6035.00","data_read_per_join": "46K"},"used_columns": ["id","name","flag"],"attached_condition": "((`test2`.`lian3`.`flag` = 1) and (`test2`.`lian3`.`name` < 'e'))"}}
}实验2总结:
全表扫描:6035
单列name索引:20784
naf:5993.18
fan:6035
可以看到naf和fan相差不大,这和name列的选择度低有关,但是就算选择度低,naf也是最优解,所以选择naf是最好的。
实验3(flag列选择性好):
这就根本不用做实验了,flag等值查询,选择性还好肯定放在联合索引的左侧。
综上所述,不管是什么做实验时硬道理,实践出真理。也要直到range级别了也可以继续优化,优化的一个思路就是创建联合索引避免回表。