1. 行业背景
1.1 电商发展历史
电商1.0: 初创阶段20世纪90年代,电商行业刚刚兴起,主要以B2C模式为主,如亚马逊、eBay等 电商2.0: 发展阶段21世纪初,电商行业进入了快速发展阶段,出现了淘宝、京东等大型电商平台,同时也出现了C2C模式和O2O模式 电商3.0: 成熟阶段2010年代,电商行业进入了成熟阶段,各大电商平台开始加强自身的品牌建设和服务体系,同时也出现了跨境电商、社交电商、农村电商等新兴模式。 电商4.0: 新零售阶段2016年以后,电商行业进入了电商阶段,以阿里巴巴、京东等为代表的电商巨头开始布局线下实体店,实现线上线下的无缝衔接,推动电商行业向更高层次发展。
1.2 什么是电商4.0
电商4.0其实就是新零售阶段, 主要由三部分组成: 线上服务、线下体验、新物流
线上服务:线上服务指的是通过互联网平台提供的购物、支付、物流等服务 线下体验:线下体验则是指在实体店铺中提供的商品展示、试穿试用、售后服务等体验 新物流:新物流则是指通过物流技术和网络优化提高物流效率和服务质量
1.3 电商企业类型
-
1- 电商服务商
-
2- 货架、售货机
-
3- 无人便利店
-
4- 线上线下实体店
-
5- 生鲜、果蔬平台
1.4 生鲜电商行业概述
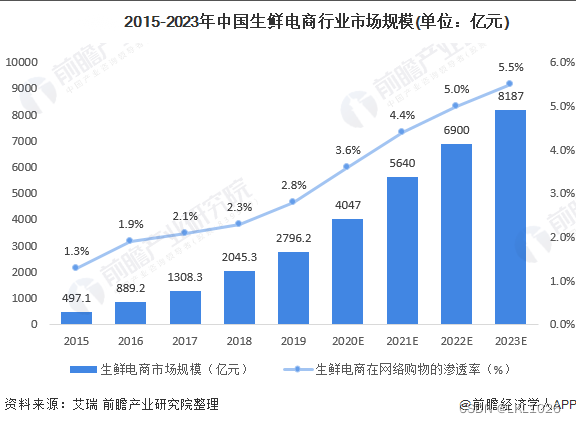
生鲜产品具有高频刚需的特点, 是具有即时性需求, 目前在线下占比要远高于线上, 未来线上生鲜销售将会是庞大的市场

各大头部企业也可以着手布局生鲜市场
1.5 生鲜电商行业发展趋势
随着消费者网购生鲜习惯逐渐养成, 以及目前直播带货等多重作用下, 生鲜市场线上渗透率将不断提高
2. 项目业务流程与需求说明
2.1 公司介绍
黑马甄选与2016年7月成立, 发展至今经过6年时间, 门店遍布全国30多个城市, 超过1300家门店
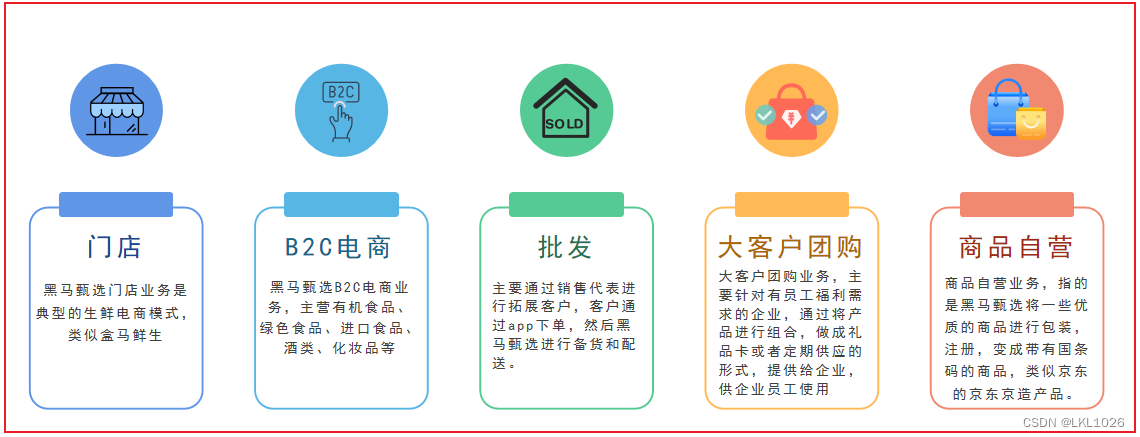
目前主营业务线有五条: ==门店 B2C电商 批发 大客户团购 商品自营==
2.2 业务介绍
2.3 项目背景
随着生鲜电商行业的迅速发展,公司累计了大量数据。为了从已有的数据中挖掘出有价值的信息,搭建了黑马甄选大数据处理平台。主要对各业务线的数据进行分析,从而便于精细化管理,最终提高用户数量及活跃度,提高商品销量,降低运营成本。
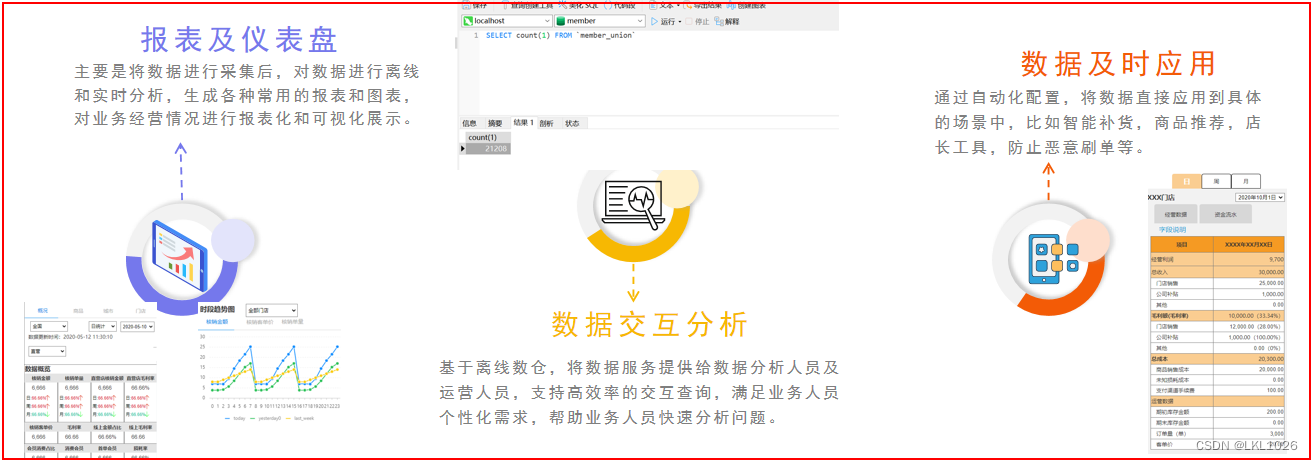
2.4 需求说明
==本次项目共计有四大需求: 销售需求 会员需求 供应链需求 商城需求==
-
销售需求:
划分为线上销售流程和线下销售流程,业务部门需要全面分析线上线下的销售情况,包括销售、取消、退款的金额、成本、单量、SKU以及活动的情况。
-
会员需求:
因为黑马甄选是生鲜电商业务,包括线上和线下,所以会员也分为线上会员和线下会员。 主要统计会员的注册、消费、充值、余额情况。注意线上会员也可以在线下消费,使用相同的手机号即可。
-
供应链需求
划为为要货到货流程与商品划拨流程 为精细化运营,业务部门严格管控供应链,要求计算:库存的数量、金额、SKU、周转、动销、损耗数量和金额、盘点差异以及要货、收货、配送、退货、退配、调入、调出、系统调整的数量和金额。
-
商城需求
商城需求指的是对商城的访问日志进行分析,主要是流量数据和交易数据。如何评价线上平台的好坏,UV/PV/新访客数量/跳出数/浏览时长等都是非常重要的指标
3. 项目架构详解
3.1 离线数仓架构方案
-
经典传统数仓架构
阶段一: 1991年 比尔-恩门(bill inmon)出版第一版数据仓库的书, 标志数据仓库概念的确立, 称为恩门模型主张自上而下的建设企业级数据仓库, 建设过程中需要满足三范式要求从分散异构的数据源 -> 数据仓库 -> 数据集市存在问题: 由于三范式的建模,导致在数据分析中数据易访问性和系统的性能均收到影响 阶段二: 拉尔夫·金博尔(ralph kimball)提出自下而上的建立数据仓库,整个过程中信息存储采用维度建模而非三范式从数据集市-> 数据仓库 -> 分散异构的数据源优点: 提出了维度建模新思路, 完全以数据分析便利性为前提建设, 推出了事实-维度模型以最终任务为导向, 需要什么, 我们就建立什么弊端:随着业务的发展, 导致数据集市越来越多, 出现多个数据集的数据混乱和不一致的情况 阶段三: 1998年比尔-恩门(bill inmon)推出全新的CIF架构, 核心将数仓架构划分为不同的层次以满足不同场景的需求如: ODS DW DA层等从而明确各个层次的任务分工, 避免原有数据混乱和不一致的问题而这种思想已经成为截止到今天的建设数据仓库的指南
-
离线大数据数仓架构
大数据中的数据仓库构建就是基于经典数仓架构而来,使用大数据中的工具来替代经典数仓中的传统工具,架构建设上没有根本区别
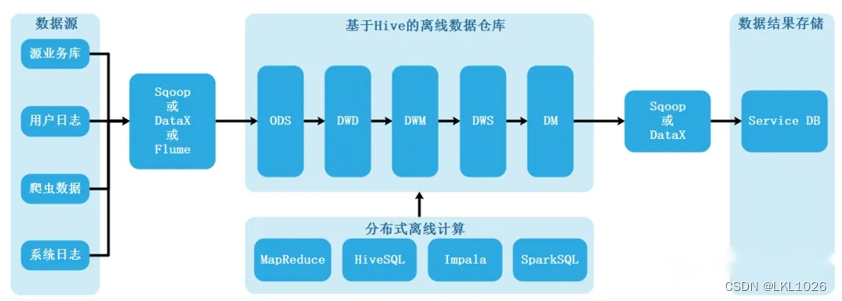
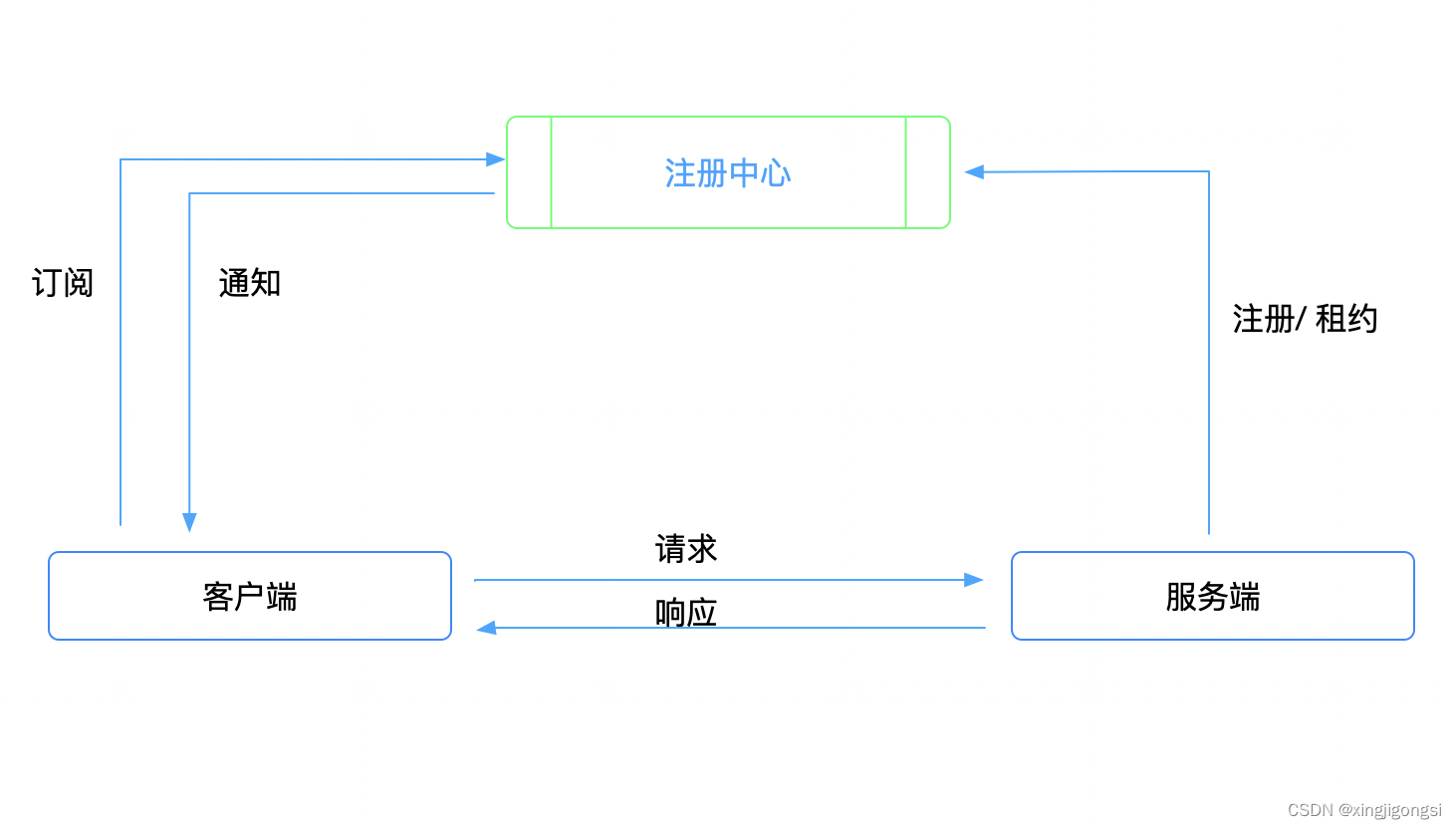
3.2 项目架构图

集群管理工具: Cloudera Manager 数据源: 业务系统的Mysql与SQLServer数据库; 数据抽取: 使用DataX实现关系型数据库和大数据集群的双向同步; 数据存储: HDFS 计算引擎: Hive 交互查询引擎: Presto OLAP: PG 数据可视化: Fine Report 调度系统: DolphinScheduler(海豚调度)
面试中: 你能否讲一下这个项目的基本介绍呢? 你们这个项目的架构大概是再怎么样?
项目介绍: 给谁做的项目 是一个什么项目 项目的简单的背景 项目最终成果 (简历中, 项目介绍部分要体现的内容)项目架构: 技术架构: 本次项目主要涉及了那些组件数据流向: 数据从哪来 --> 到哪去 + 各个组件起到了什么作用本次项目中主要负责的点:后期学到了去整理自己擅长你可以带着面试官走, 让他一直听你说, 他只需要回复 yes
小作业: 完成架构图的梳理(自己制图) –> 讲解项目介绍和项目架构
11.21号晚: 与各位组长
11.22号晚上: 各组自行安排
3.3 人员规划
开发人员:10个人职责划分:经理(1个人)(甲方:技术经理、乙方:项目经理)产品(1个人)大数据开发(4个人)运维(1个人)(DBA/集群搭建与维护/安全等工作)测试(1个人)前端(1个人)Java工程师(1个人)
3.4 开发周期
总周期: 八个月左右 阶段划分:需求调研、评审(7周)设计架构(2周)需求开发(16周)集成测试(3周)上线部署,试运行,调优(4周)
3.5 项目服务器架构选型
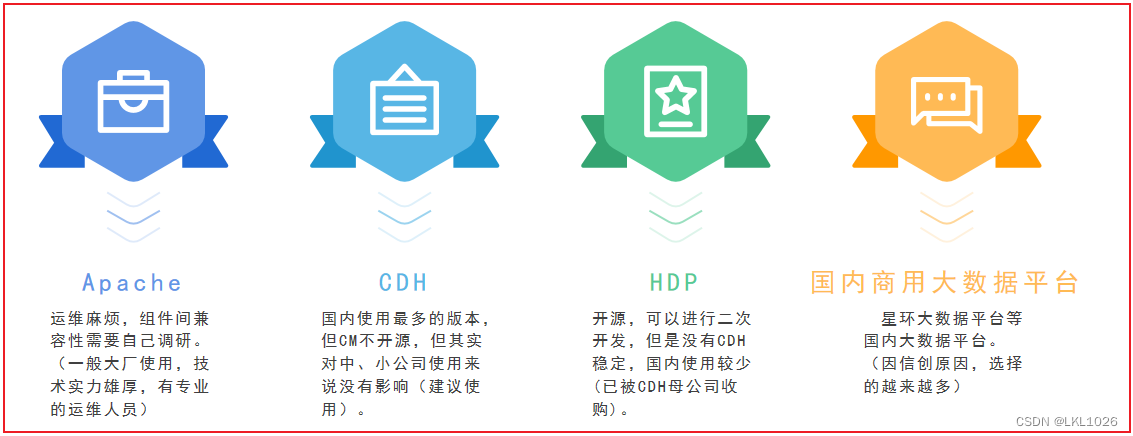
3.5.1 Hadoop发行版本选型
最终选择: CDH平台
兼容性 稳定性 强大的管理平台 基础功能免费
3.5.2 服务器的选型
本次项目中主要以物理机方案
考虑点:1- 机器成本考虑: 物理机: 以128G内存,20核物理CPU,40线程,8THDD和2TSSD硬盘,单台报价4W出头,需考虑托管服务器费用。一般物理机寿命5年左右, 平均每年 8k云主机: 以阿里云为例,差不多相同配置,每年5W2- 运维成本考虑物理机: 需要有专业的运维人员云主机: 很多运维工作都由阿里云已经完成,运维相对较轻松物理机运维成本更高从长远考虑, 随着运维人员的减少, 成本逐步降低, 而云主机成本, 随着依赖程度越高, 成本也会逐步提升, 并且本地物理机数据安全性更高
3.5.3 集群数据规模
业务情况说明:
用户量:1000W 日活:线上80W + 线下45W(线下只统计购买人数) 门店数量:1300家 门店日均单量:线上100单 + 线下350单 日均营业额:线上5000元 + 线下10000元
每日增量数据:
业务数据: 平均每条订单及其相关表(订单、人员、支付、物流、库存等等)的存储量:20K 20K * 58W = 11g日志数据: 每条数据0.5k-1.5k,平均1k,平均每人产生30条日志 1k * 80w * 30条 = 23g
规模计算(了解)
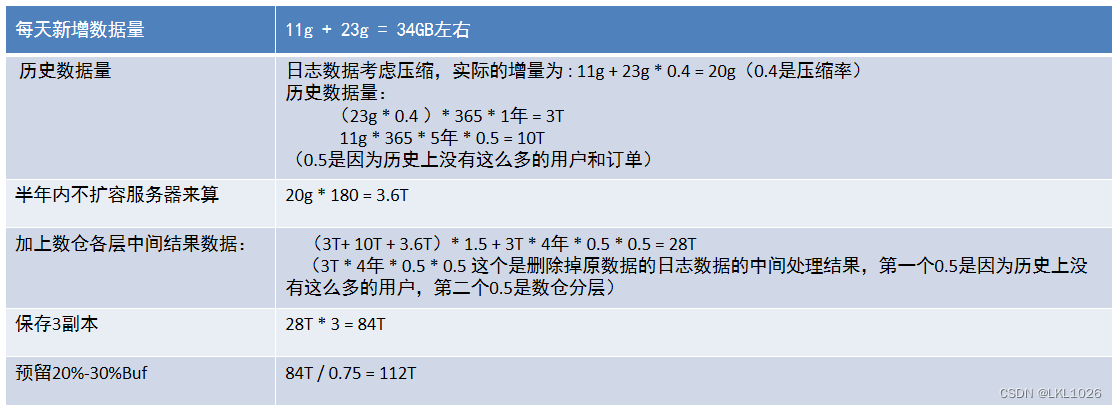
知道最终需要112TB空间
服务器规划:
所以存储+计算服务器需要大概11台(晚上跑批任务,白天进行数据清洗以及查询、交互分析), 因为有Presto基于内存的计算任务,所以计算节点需要再加5台, 另外加上管理服务器3台, 测试服务器3台, 总共需要22台。
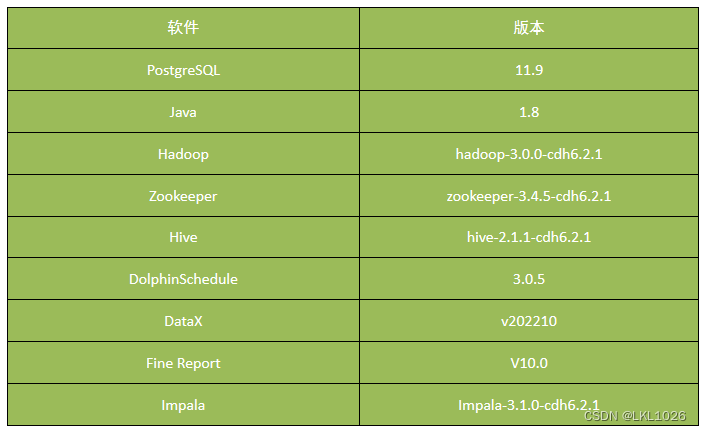
3.5.4 项目服务器架构选型
3.5.5 测试服务器规划
因服务器资源有限,考虑到大部分学员电脑性能配置不高,该项目采用二台服务器进行演示学习,服务器配置如下:

各软件安装节点说明:

注意:
打开虚拟机-> 选择我已移动
用户名: root
密码: 123456
4. 项目环境部署
4.1 CM介绍与架构
cloudera manager 是一款大数据的统一监控管理平台, 此平台主要是对cloudera公司旗下CDH版本软件进行管理工作, 提供的服务: 统一的监控, 自动化部署, 对CDH软件进行相关管理
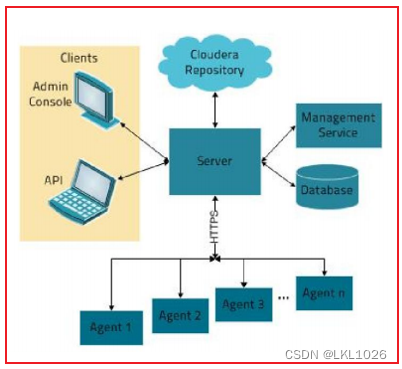
Server:Cloudera Manager的核心是Cloudera Manager Server。提供了统一的UI和API方便用户和集群上的CDH以及其它服务进行交互,能够安装配置CDH和其相关的服务软件,启动停止服务,维护集群中各个节点服务器以及上面运行的进程。 Agent:安装在每台主机上的代理服务。它负责启动和停止进程,解压缩配置,触发安装和监控主机 Management Service:执行各种监控、报警和报告功能的一组角色的服务 Database:CM自身使用的数据库,存储配置和监控信息 Cloudera Repository:云端存储库,提供可供Cloudera Manager分配的软件 Client:用于与服务器进行交互的接口1) Admin Console:管理员可视化控制台2) API:开发人员使用API可以创建自定义的Cloudera Manager应用程序
CM的web页面
链接: http://hadoop01:7180/cmf/home 用户名: admin 密码: admin
4.2 部署项目环境
此部分大家可直接参考<<00黑马甄选离线大数据平台项目环境部署文档>>即可
4.3启动环境
先配置本地映射
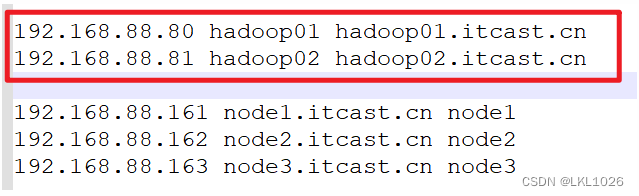
进入C:\Windows\System32\drivers\etc目录,把以下内容复制粘贴到hosts文件内
192.168.88.80 hadoop01 hadoop01.itcast.cn 192.168.88.81 hadoop02 hadoop02.itcast.cn
配置虚拟机内存
演示16g内存情况
设置hadoop01内存10g
设置hadoop02内存4g
大于16g的同学,根据实际情况随时调整即可
启动并连接CM
先依次启动hadoop01,hadoop02虚拟机,然后复制以下CM链接到浏览器,进入CM管理页面
CM页面链接: http://hadoop01:7180/cmf/home 用户名: admin 密码: admin
点击主机查看内存使用情况:

注意:
如果内存不够用的同学,建议Cloudera Management Service里面的4个服务都关闭
关闭CM4个服务后,页面如下:
4.4设置交换内存
参考笔记中的 Linux中虚拟内存的配置 文档

5.业务数据介绍与准备
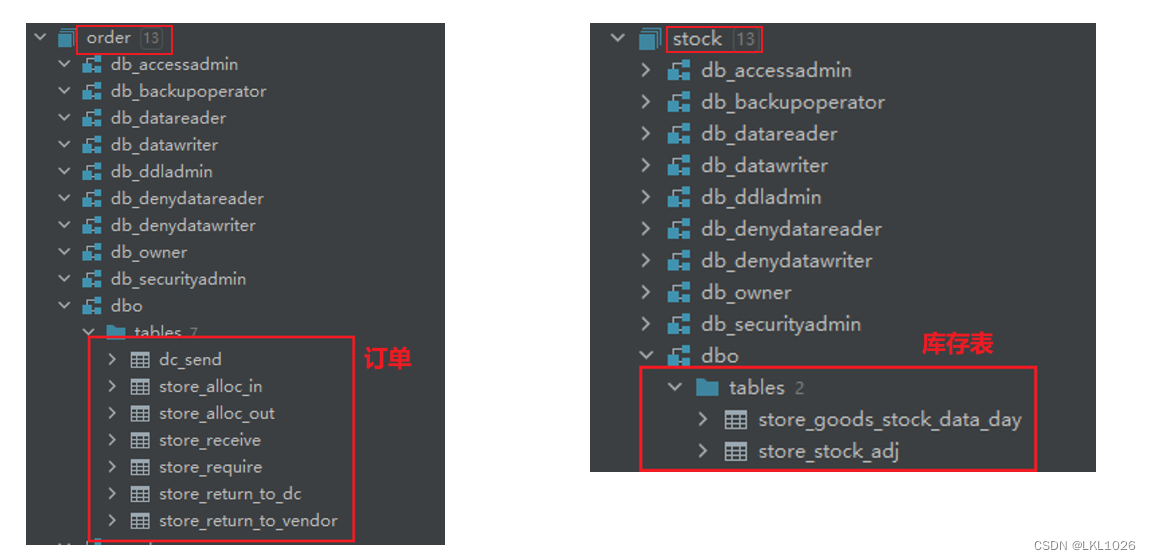
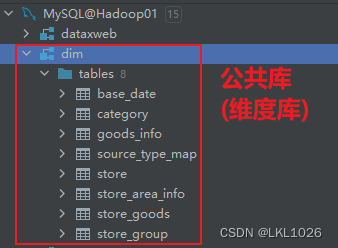
项目涉及核心业务表:
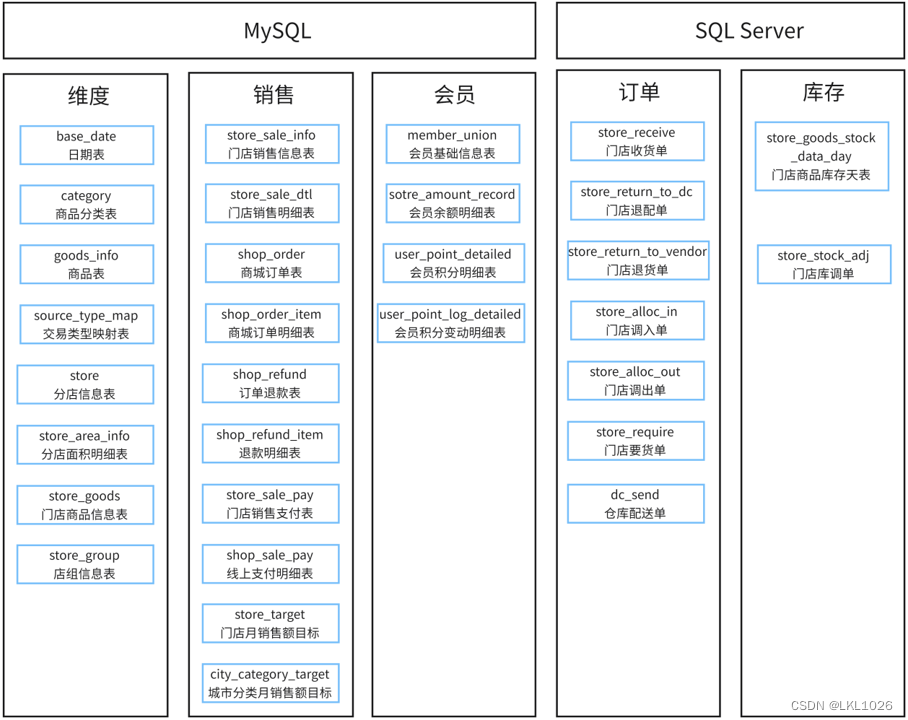
项目一共有有31张表,其中包含8张维度表,23张业务核心表。其中订单表和库存表存储在SQL Server中,其他表存储在MySQL中。
导入业务到指定的数据库中(此操作在实际工作中不存在):
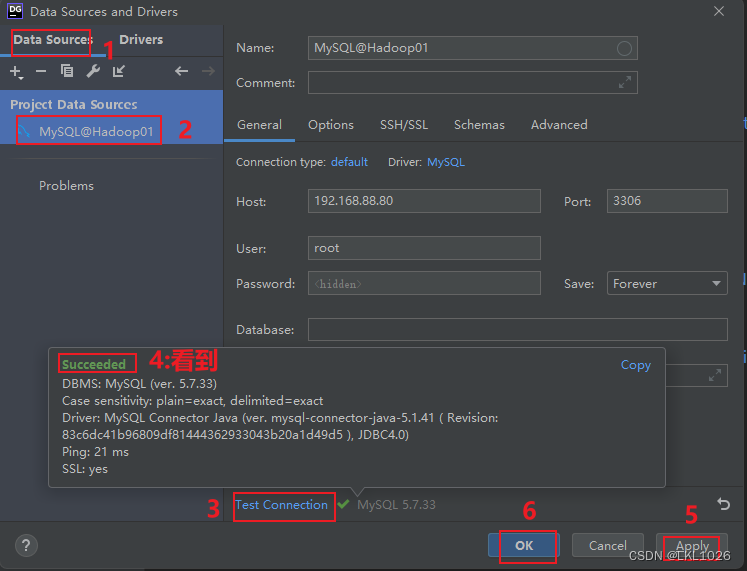
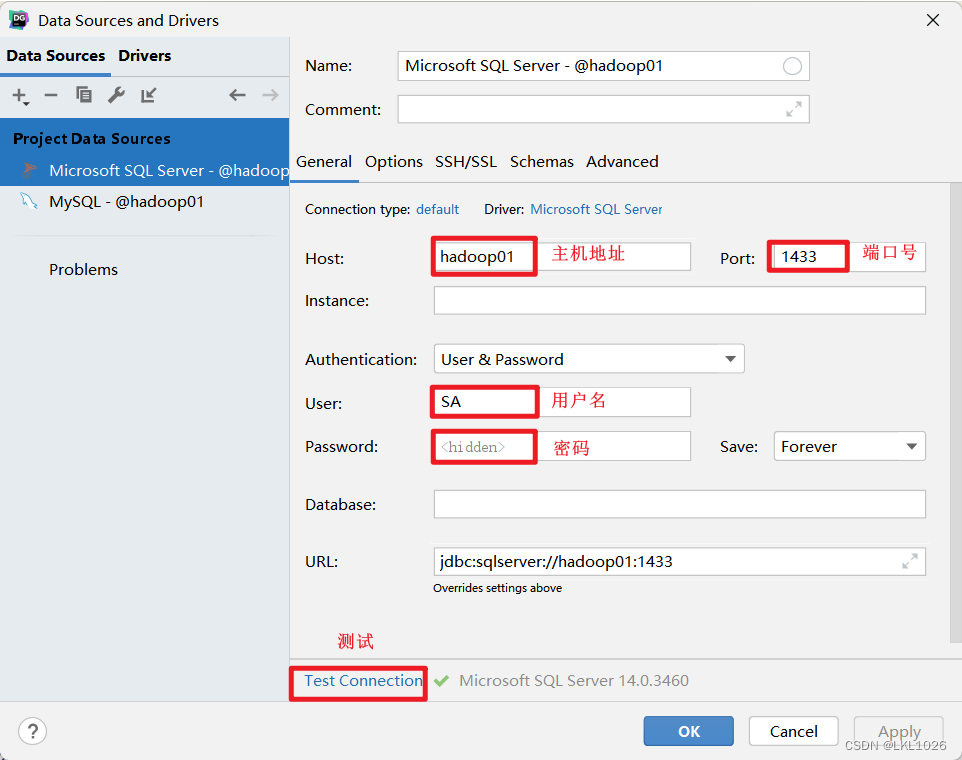
连接数据库
mysql:IP: 192.168.88.80端口号: 3306用户名: root密码: 123456sqlserver:IP: 192.168.88.80端口号: 1433用户名: SA密码: ITheima123
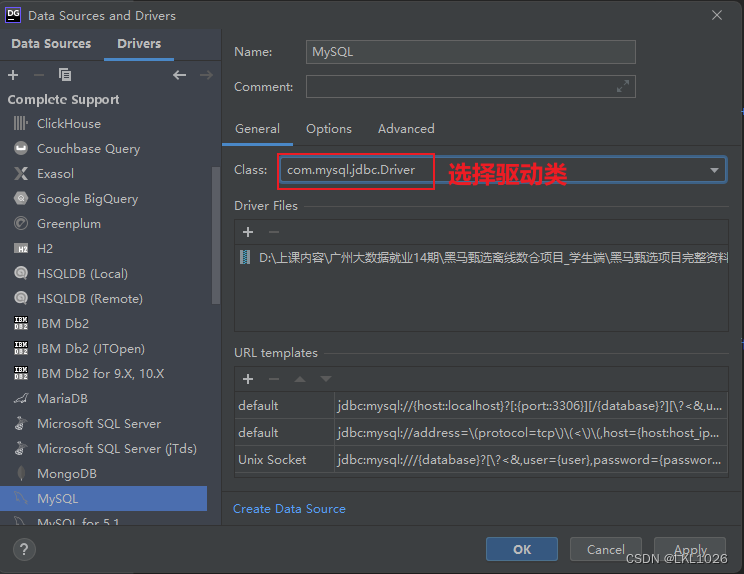
DG连接MySQL
注意: 虚拟机是mysql5,所以选择mysql5和mysql8的驱动jar包都可以连接上,只要保证连接上就行!!!
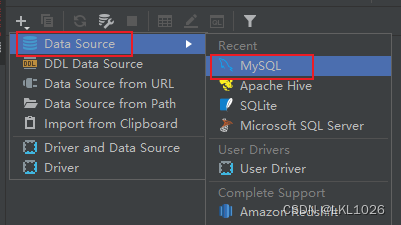
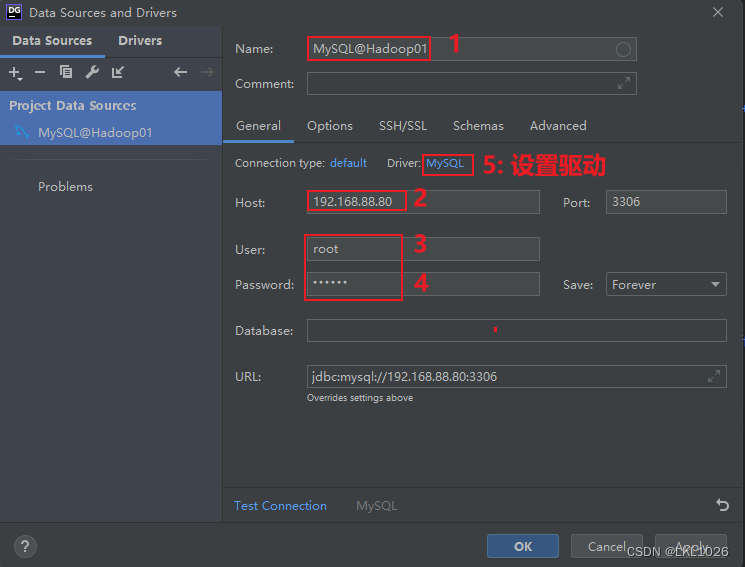
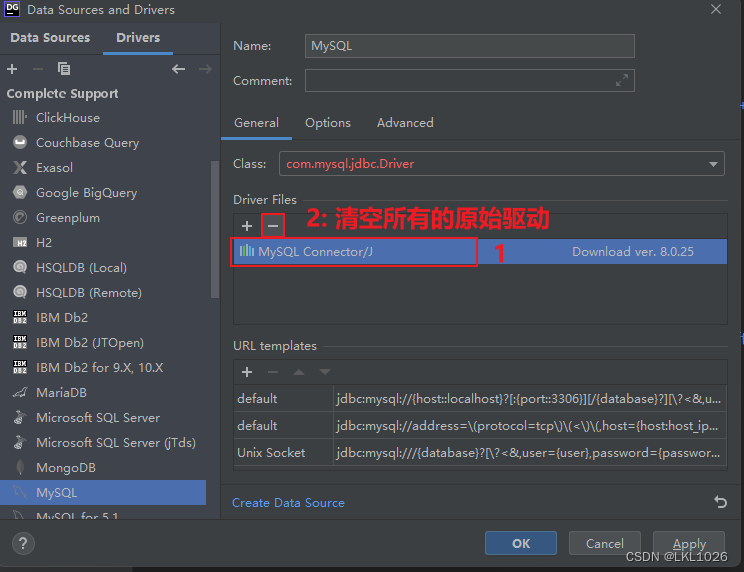
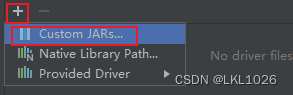
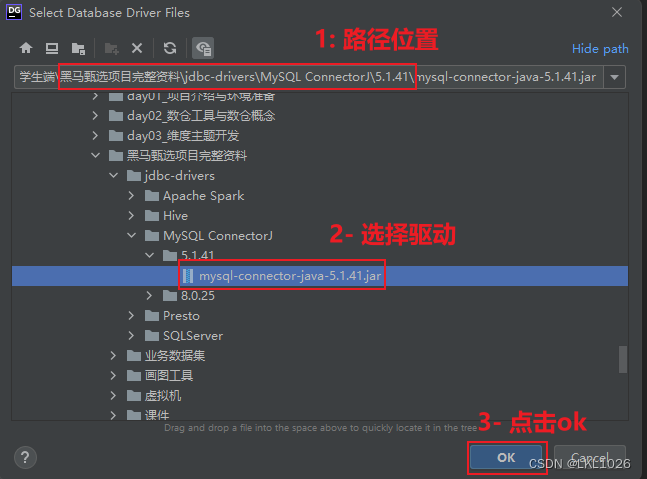
注意: 后续如何基于这个驱动连不上, 可以使用 8的版本的试试
DG连接SqlServer
准备业务数据
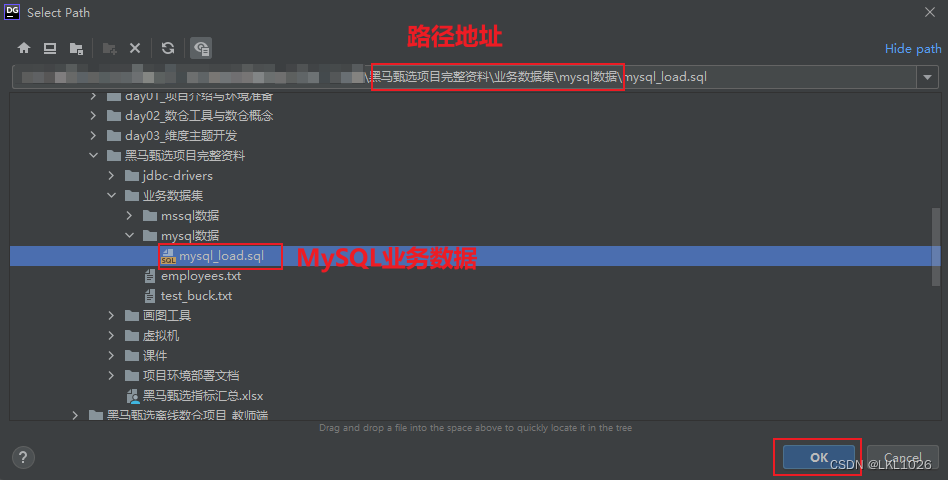
准备MySQL业务数据
连接成功后, 执行数据导入:

结果显示:
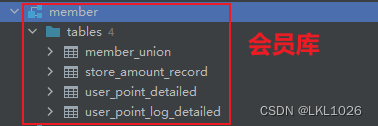
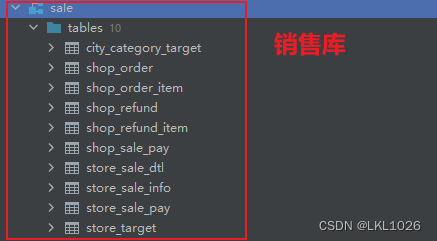
准备SQLServer业务数据
和mysql数据一样,右键选择Run SQL Script -> 去选择黑马甄选离线数仓项目完整资料\06业务数据集\sqlserver数据\mssql_load.sql
最终的结果: