生成器(Generators)和 生成器表达式(Generator Expressions)是 Python 中用于处理迭代器和序列数据的强大工具。它们允许你按需生成值,而不是一次性生成所有值,从而节省内存和提高性能。
1. 生成器(Generators)
生成器 是一个用于创建迭代器的简单而强大的工具。 它们的写法类似于标准的函数,但当它们要返回数据时(返回一个generator iterator的函数)会使用 yield语句。 每次在生成器上调用 next() 时,它会从上次离开的位置恢复执行(它会记住上次执行语句时的所有数据值)。
1.1 语法
def my_generator():yield 1yield 2yield 3
生成器使用函数中的yield 语句来生成值,每次调用生成器的__next__() 方法时,函数会执行到 yield,返回值并暂停,下一次调用会从上次暂停的地方继续执行。
1)yield: 返回一个值,并暂停生成器的执行。
2)__next__(): 获取生成器的下一个值。
3)生成器可以使用for 循环来遍历。
1.2 应用场景
1)处理大数据集: 生成器适合处理大量数据,因为它们一次只生成一个值,而不是一次性生成所有值。
2)无限序列: 适用于表示无限序列,例如斐波那契数列。
3)懒加载: 用于按需加载大文件中的数据。
4)状态机: 生成器可以用于实现状态机,处理一系列有序事件。
5)异步编程: 在异步编程中,生成器可以用于实现协程。
1.3 简单示例
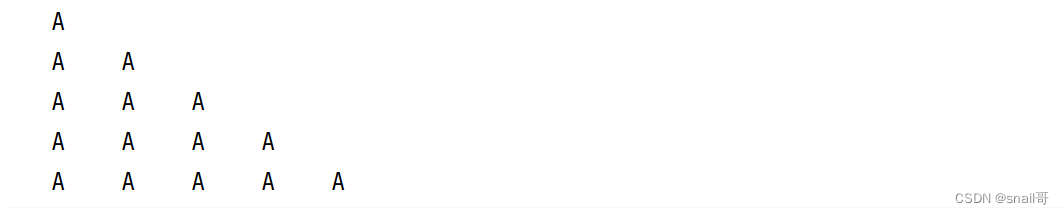
按照指定的模式生成一系列字符串
def pattern_generator(n):for i in range(1,n+1):yield ' A ' * i# 使用生成器生成一系列字符串
pattern_gen = pattern_generator(5)
for pattern in pattern_gen:print(pattern)
1.4 应用场景示例
1.4.1 处理大数据集
"""1)处理大数据集
"""
def read_large_file(file_path):with open(file_path, 'r') as file:for line in file:yield line# 使用生成器遍历大文件
for data in read_large_file('large_data.txt'):process_data(data)
1.4.2 无限序列
"""无限序列实现斐波那契数列
"""
def fibonacci():a, b = 0, 1while True:yield aa, b = b, a + b# 使用生成器获取前 n 个斐波那契数
gen = fibonacci()
fibonacci_values = [next(gen) for _ in range(10)]
print(fibonacci_values)
1.4.3 懒加载
"""懒加载-读取数据库记录
"""
def lazy_load_records_from_database(query):# Simulating database queryrecords = query.execute()for record in records:yield record# 使用生成器按需加载数据库记录
query_result = lazy_load_records_from_database(my_query)
for record in query_result:process_record(record)
1.4.4 状态机
"""状态机
"""
def simple_state_machine():state = "start"while True:if state == "start":yield "Processing Start"state = "middle"elif state == "middle":yield "Processing Middle"state = "end"else:yield "Processing End"state = "start"# 使用生成器实现状态机
state_machine = simple_state_machine()
for _ in range(3):print(next(state_machine))
1.4.5 异步编程
"""异步编程-协程
"""
def simple_coroutine():result = yield "Start Coroutine"yield f"Received: {result}"# 使用生成器作为简单的协程
coroutine = simple_coroutine()
print(next(coroutine)) # Start Coroutine
print(coroutine.send("Data")) # Received: Data
2. 生成器表达式(Generator Expressions)
2.1 语法
某些简单的生成器可以写成简洁的表达式代码,所用语法类似列表推导式,但外层为 圆括号 而非方括号。 这种表达式被设计用于生成器将立即被外层函数所使用的情况。 生成器表达式相比完整的生成器更紧凑但较不灵活,相比等效的列表推导式则更为节省内存。
gen_expr = (x for x in range(5))
与生成器类似,使用 __next__() 方法获取下一个值。
也可以通过for 循环来遍历。
2.2 应用场景
1)列表筛选: 生成器表达式可以用于按条件筛选列表中的元素。
2)简单转换: 适用于对序列进行简单的转换操作。
3)迭代: 用于按需生成值进行迭代。
4)过滤: 通过生成器表达式筛选或过滤元素。
5)字典生成: 用于生成字典中的值。
2.3 简单示例
使用生成器表达式生成一个包含偶数的生成器
sum(i*i for i in range(10)) # sum of squaresxvec = [10, 20, 30]
yvec = [7, 5, 3]
sum(x*y for x,y in zip(xvec, yvec)) # dot productunique_words = set(word for line in page for word in line.split())valedictorian = max((student.gpa, student.name) for student in graduates)data = 'golf'
list(data[i] for i in range(len(data)-1, -1, -1))
# 生成器表达式示例:生成包含偶数的生成器
even_numbers_generator = (x for x in range(10) if x % 2 == 0)# 使用生成器迭代
for number in even_numbers_generator:print(number)
2.4 应用场景示例
2.4.1 列表筛选
"""列表筛选
"""
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# 使用生成器表达式筛选出偶数
even_numbers = (x for x in numbers if x % 2 == 0)
print(list(even_numbers))

2.4.2 简单转换
"""简单转换
"""
original_list = [1, 2, 3, 4, 5]# 使用生成器表达式将每个元素平方
squared_values = (x**2 for x in original_list)
print(list(squared_values))

2.4.3 迭代
"""迭代
"""
words = ["apple", "banana", "cherry"]# 使用生成器表达式将每个单词转换为大写
uppercase_words = (word.upper() for word in words)
print(list(uppercase_words))

2.4.4 过滤
"""过滤
"""
data = [10, -2, 8, -7, 4, -1]# 使用生成器表达式过滤出正数
positive_numbers = (x for x in data if x > 0)
print(list(positive_numbers))

2.4.5 字典生成
"""字典生成
"""
keys = ['a', 'b', 'c']
values = [1, 2, 3]# 使用生成器表达式创建字典
dictionary = {k: v for k, v in zip(keys, values)}
print(dictionary)
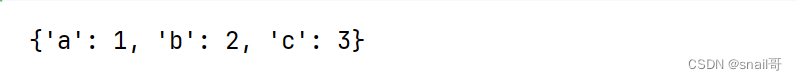
3. 生成器表达式与普通函数不同点
返回(生成)一个迭代器对象。你无需担心显式地创建此迭代器对象,yield关键字为你做了这个工作。
必须包含至少一个yield语句。如果需要,它可能包括多个yield关键字。
内部实现迭代器协议(iter()和next()方法)。
自动保存局部变量及其状态。
在yield关键字处暂停执行,并将控制权传递给调用者。
在迭代器流没有返回值时自动引发StopIteration异常。
4. 生成器的优点
生成器在许多方面都具有显著的优势,特别是在内存效率、延迟计算、处理无限流、易实现和可读性等方面。
1)内存效率(逐次生成)
生成器一次只生成一个值,而不是一次性生成所有值。这意味着在处理大量数据时,生成器可以显著节省内存,因为它们不需要在内存中存储整个序列。
2)延迟计算(按需生成)
生成器在需要时生成值,而不是预先生成整个序列。这种延迟计算的方式使得在处理大数据集或无限序列时能够更加高效。
3)处理无限流(适用于无限序列)
生成器非常适合处理无限序列,例如斐波那契数列。因为它们是按需生成的,所以可以有效地处理无限流而不会耗尽内存。
4)易实现
生成器的语法相对简单,只需使用 yield 关键字即可。这使得实现生成器相对容易,不需要复杂的迭代器或序列处理代码。
5)可读性
生成器允许将代码逻辑分解为可读的小块,每个块生成一个值。这提高了代码的可读性,尤其是在处理复杂的数据流时。
5. 参考
官网:https://docs.python.org/zh-cn/3/tutorial/classes.html#generators
https://docs.python.org/zh-cn/3/tutorial/classes.html#generator-expressions