使用 NVProf 检测 CUDA kernel 的 bank conflict
NVProf 指令
使用 NVProf 可以对 bank conflict 进行检测:
nvprof --events shared_ld_bank_conflict,shared_st_bank_conflict <app> [args...]
其中:
--events选项指定的shared_ld_bank_conflict,shared_st_bank_conflict分别代指从 shared memory 加载(读取)时产生的 bank conflict, 以及向 shared memory 存储(写入)时产生的 bank conflict.<app> [args...]即要检测的 CUDA 二进制程序及其参数.
额外说明
值得一提的是, 如果没有从 shared memory 读取的指令, 且没有使用 -G 编译, 则两种 bank conflict 事件都无法检测出来, 即使存在向 shared memory 写入产生的 bank conflict.
(没有读取的 bank conflict 很好理解, 因为都没有从 shared memory 读取数据; 而至于写入的 bank conflict, 应该是编译器做了一定的优化, 即 shared memory 虽被写入但数据没有被读取, 则写入是没有意义的, 这部分代码实际并不执行, 所有写入的 bank conflict 就不会检测到了.)
这个主要作用是, 当我们对自己写的 kernel 的 bank conflict 进行检测的时候, 要确保保留对 shared memory 读取的相关代码或设置 -G 编译选项, 否则可能会影响 bank conflict 的检测.
举例
以下代码是一个很简单的 CUDA kernel 示例, 考虑到 bank conflict 是 warp 层面的问题, 所有 kernel 中我定义了 warp_id, land_id 等变量便于后续 bank conflict 的说明.
#include <iostream>
#include <cstdio>
#include <vector>
#include <cuda.h>using namespace std;constexpr int SIZE_A = 64;
constexpr int SIZE_C = 64;__global__ void kernel(const int* a, int* c) {auto tid = (blockIdx.x * blockDim.x + threadIdx.x);auto lane_id = threadIdx.x & 0x1F;auto warp_id = tid >> 5;auto warp_in_block = threadIdx.x >> 5;__shared__ int shm[SIZE_A];if (tid < SIZE_A) {shm[warp_id * 32 + lane_id] = a[warp_id * 32 + lane_id];}if (tid < SIZE_C) {c[warp_id * 32 + lane_id] = shm[warp_id * 32 + lane_id];}
}int main() {vector<int> a(SIZE_A);for (int i = 0; i < SIZE_A; ++i) {a[i] = i;}int* d_a;cudaMalloc(&d_a, sizeof(int) * SIZE_A);cudaMemcpy(d_a, a.data(), sizeof(int) * SIZE_A, cudaMemcpyHostToDevice);int* d_c;cudaMalloc(&d_c, sizeof(int) * SIZE_C);cudaMemset(d_c, 0, sizeof(int) * SIZE_C);kernel<<<1, 128>>>(d_a, d_c);vector<int> c(SIZE_C);cudaMemcpy(c.data(), d_c, sizeof(int) * SIZE_C, cudaMemcpyDeviceToHost);for (auto x : c) {cout << x << " ";}cout << endl;cudaFree(d_c);cudaFree(d_a);return 0;
}
kernel() 函数完成的功能很简单, 就是想数组 a 中的一部分数据先写至 shared memory shm, 再写入到 c 中. 在没有额外说明时, 不使用 -G 选项编译代码.
很明显的是, 由于 shm 的读写时, 每个 warp 的 32 个线程分片读取不同的 4 字节数据, 因此代码没有 bank conflict.

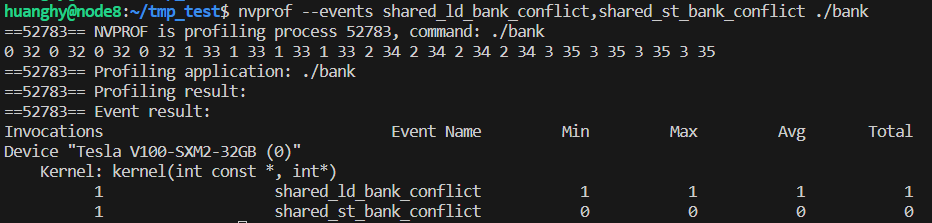
使用上述 NVProf 指令检测, 结果也印证了上述推断.
现在将 Kernel 修改如下:
__global__ void kernel(const int* a, int* c) {auto tid = (blockIdx.x * blockDim.x + threadIdx.x);auto lane_id = threadIdx.x & 0x1F;auto warp_id = tid >> 5;auto warp_in_block = threadIdx.x >> 5;__shared__ int shm[SIZE_A];// if (tid < SIZE_A) {// shm[warp_id * 32 + lane_id] = a[warp_id * 32 + lane_id];// }for (auto i = threadIdx.x; i < SIZE_A; i += blockDim.x) {shm[(i % 2) * SIZE_A / 2 + i / 2] = a[i];}if (tid < SIZE_C) {c[warp_id * 32 + lane_id] = shm[warp_id * 32 + lane_id];;}
}
我们在读取 a 数组到 shared memory 的时候, 进行了一点修改. 可以看到, 对应相邻的两个线程, t 和 t+1 (假设 t % 2 ==0), 则一个写入到 shm[t/2], 一个写入到 shm[SIZE_A/2+(t+1)/2] 即 shm[32+t/2], 由于恰好差了 32 个元素, 因此会访问到相同的 bank, 会触发 bank conflict. 通过 NVProf 检测也得到了证实:

这里的 2 次, 原因笔者猜测为 SIZE_A 大小为 64, 对应 2 个 warp, 每个 warp 相邻的奇数线程和偶数线程访问同一 bank, 以 warp 为单位, 每个 warp 产生 1 个 bank conflict, 共 2 个.
但如果我们将后面将 shm 写入 c 数组的代码注释掉, 即没有从 shared memory 读取的代码, 则可以看到 NVProf 并不会检测到刚刚的 shared_st_bank_conflict.
if (tid < SIZE_C) {c[warp_id * 32 + lane_id] = shm[warp_id * 32 + lane_id];;}

但如果我们在编译的时候使用 -G 选项, 则可以看到刚刚的 shared_st_bank_conflict 有可以被检测到了:
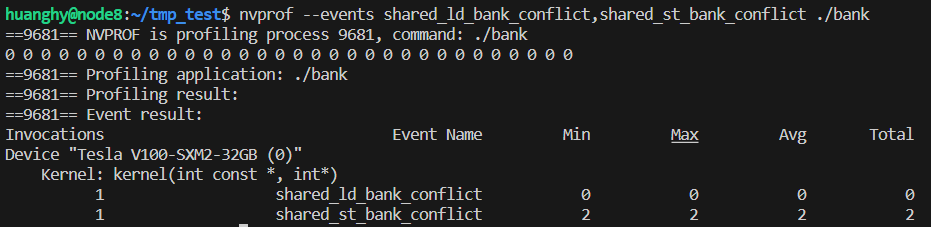
因此, 可以推断出, 在默认情况下, 编译器对于不读取的 shared memory 的写入操作会进行优化, 实际上并不会执行 shared memory 的写入操作, 而 debug 模式 (带 -G 选项)时, 则不会进行该优化.
如下代码展示了在从 shared memory shm 读取到 c 数组时的 bank conflict.
constexpr int SIZE_A = 64;
constexpr int SIZE_C = 32;__global__ void kernel(const int* a, int* c) {auto tid = (blockIdx.x * blockDim.x + threadIdx.x);auto lane_id = threadIdx.x & 0x1F;auto warp_id = tid >> 5;auto warp_in_block = threadIdx.x >> 5;__shared__ int shm[SIZE_A];if (tid < SIZE_A) {shm[warp_id * 32 + lane_id] = a[warp_id * 32 + lane_id];}if (tid < SIZE_C) {// c[warp_id * 32 + lane_id] = shm[warp_id * 32 + lane_id];c[warp_id * 32 + lane_id] =shm[warp_in_block * 32 + lane_id / 8 + (lane_id % 2) * 32];}
}
可以看到, 相邻的 8 个线程分奇偶访问同一 bank 的两个地址. NVProf 输出如下: