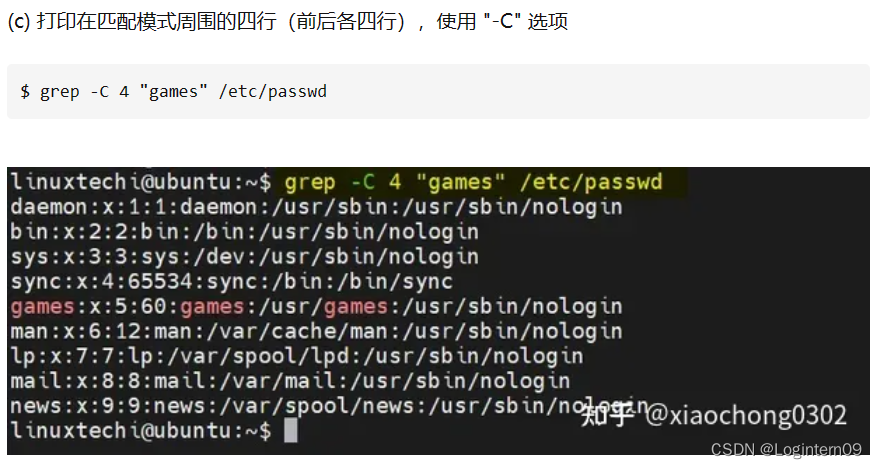
目录
- 说明
- 批量zip2pdf
- 批量zip2pdf下载
- SS号重命名源代码
- SS号重命名源代码下载
- 附录,水文年鉴
说明
1、zip2pdf是一个开源软件,支持自动化解压压缩包成PDG,PDG合成PDF,笔者在其基础上做了部分修改,支持批量转换。
2、秒传的文件是有一部分是根据SS号命名的,下载量大的话修改起来会十分麻烦。可以根据查询接口,读取SS号对应的书名,重命名本地文件。
批量zip2pdf
单文件模式(输入1)即原版模式,多文件模式(输入2)即自动读取目录下的压缩文件,逐一转化,避免手动输入。

批量zip2pdf下载
下载链接
SS号重命名源代码
def get_book_name(ss_id):# 设置请求头header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"}# 构造请求的URLurl = f"https://api.xxxxxxxx.com/search?category=duxiu&q={ss_id}"# 发送GET请求并获取响应response = requests.get(url, headers=header)# 初始化name变量为Nonename = Nonetry:# 解析响应的JSON数据,获取书名name = json.loads(response.text)["books"][0][5].replace(",", " ")except Exception as e:# 如果出现异常,打印异常信息print(e)# 等待1秒time.sleep(1)# 返回书名return namedef export_get_book_list(pdf_path):file_name = ""for f in glob(f"{pdf_path}/*.pdf"):p = Path(f)raw_name = p.name.replace(".pdf", "")file_name += f"{raw_name}\n"with open("file_name.txt", "w") as f:f.write(file_name)if __name__ == "__main__":pdf_path = Path.cwd() / "pdf"for f in glob(f"{pdf_path}/*.pdf"):p = Path(f)ss_id = p.name.replace(".pdf", "")raw_name = get_book_list(ss_id)# 增加汉字年raw_name_lst = raw_name.split(" ")raw_name_lst = list(filter(None, raw_name_lst))if "年" not in raw_name_lst[1]:raw_name_lst[1] = raw_name_lst[1] + "年"new_name = " ".join(raw_name_lst)print(new_name)p.rename(f"{new_name}_{ss_id}.pdf")SS号重命名源代码下载
点击下载
附录,水文年鉴
笔者导出了数据库里面所有水文年鉴,当前版本的数据库包含的水文年鉴,大约总共200多本,且主要为1988年之前的黄河流域水文年鉴。



![[BJDCTF2020]The mystery of ip1](https://img-blog.csdnimg.cn/655cfbc9a0c64a218102a0a0443e1565.png)