写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:zhuyc@vip.163.com。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
【腾讯云TDSQL-C Serverless产品体验】与云函数一起来一次无服务器体验
本文关键字:腾讯云、云原生、云数据库、Serverless、云函数
文章目录
- 【腾讯云TDSQL-C Serverless产品体验】与云函数一起来一次无服务器体验
- 一、产品介绍
- 1. TDSQL
- 2. 云函数
- 二、云函数配置
- 1. 函数创建
- 2. API创建
- 三、TDSQL配置
- 1. 免费创建
- 2. 连接测试
- (1)云端连接
- (2)外网连接
- 四、整合测试
- 1. 数据导入
- 2. 修改代码
- 3. 调用测试
一、产品介绍
云原生的概念已经出现好一阵了,各大云服务厂商都在争相打磨自己的相关产品,无论是云数据库还是云函数或是其它的功能性产品都在努力的做到Serverless。这样既方便管理,也能节约成本,同时还能提升效率,作为开发者还是有必要了解一下。
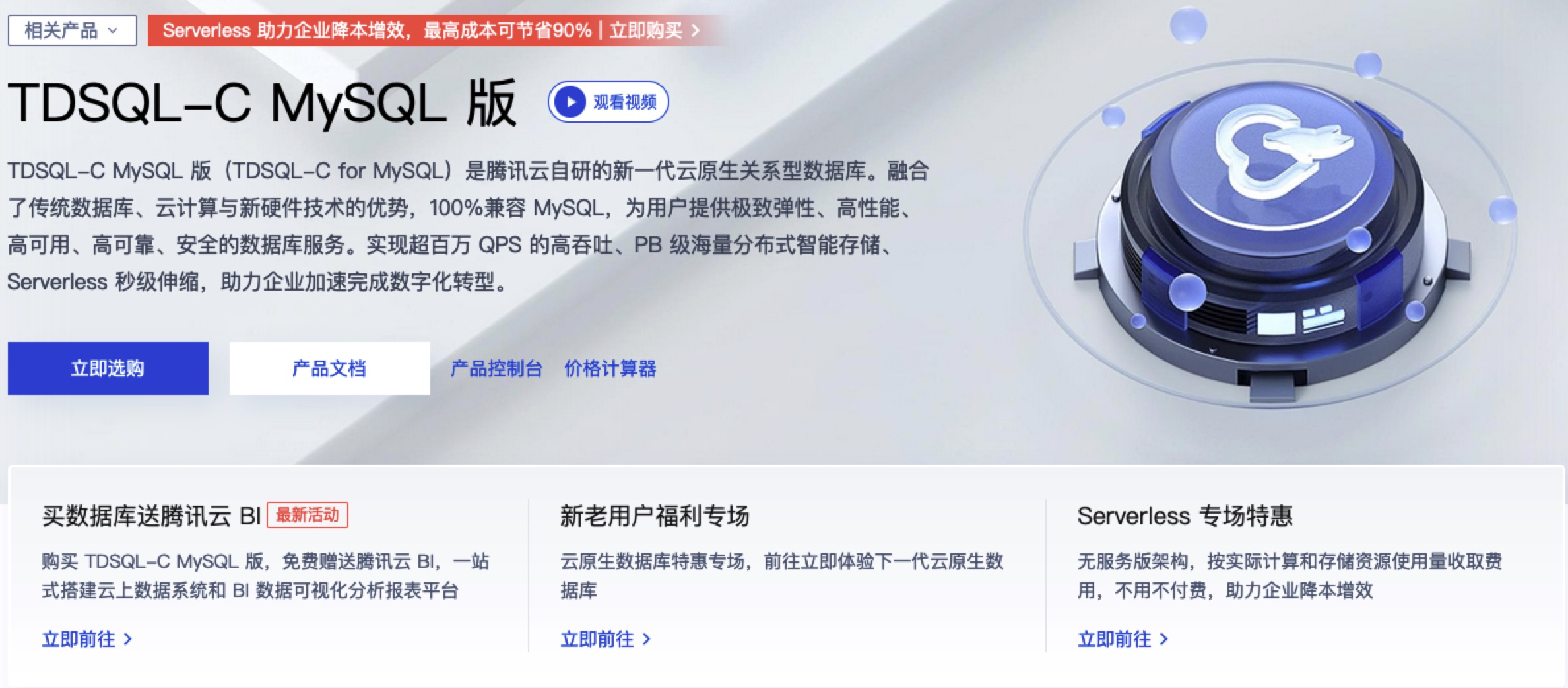
1. TDSQL
TDSQL是腾讯云自研的新一代云原生关系型数据库。支持Serverless计费模式,随用随停,按量付费,并且方便管理,便于快速扩容,兼容MySQL。
2. 云函数
SCF是腾讯云提供的无服务器执行环境,可以在无服务器的情况下运行代码。并且结合云IDE可以直接在线修改,省去了打包发布的麻烦,并且自带多环境切换,更加便于调试和发布上线。

二、云函数配置
1. 函数创建
首先来到函数服务的管理界面:
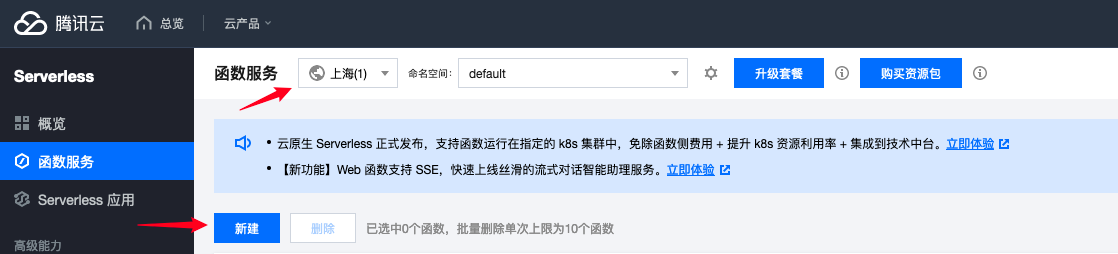
首先切换地区,因为在后面的例子中,会结合云数据库,所以这里的地区推荐选择上海或广州,然后我们点击新建【使用官方模板创建一个函数】:
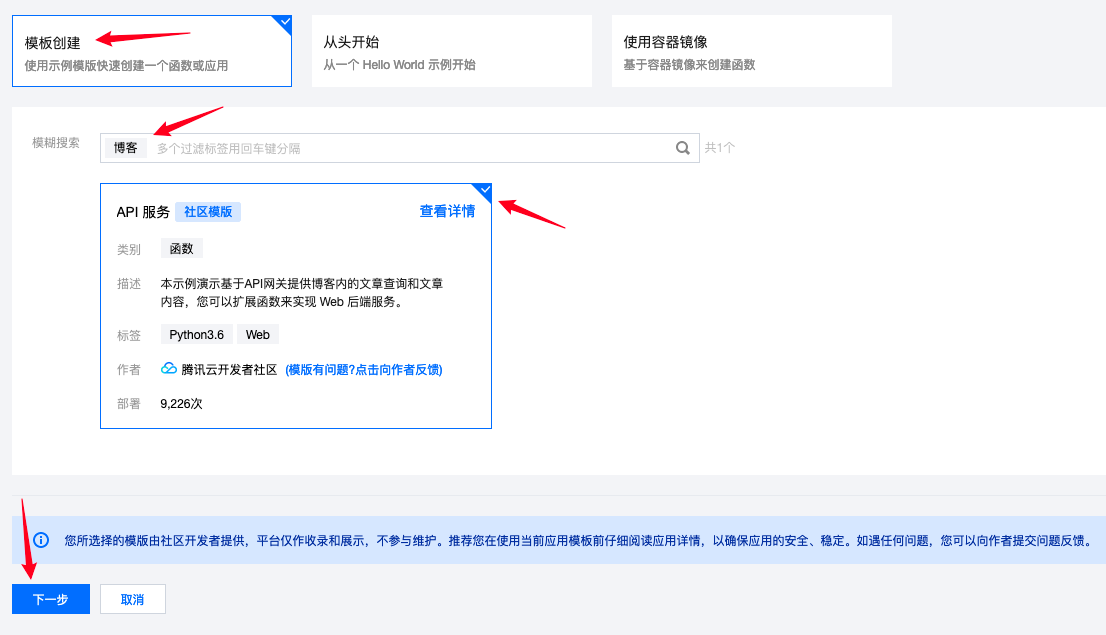
直接搜索博客可以看到一个基于Python的简单案例,支持API访问,继续点击下一步:

这里函数名称可以自定义,注意地域是否正确,描述如果有需要可以修改。
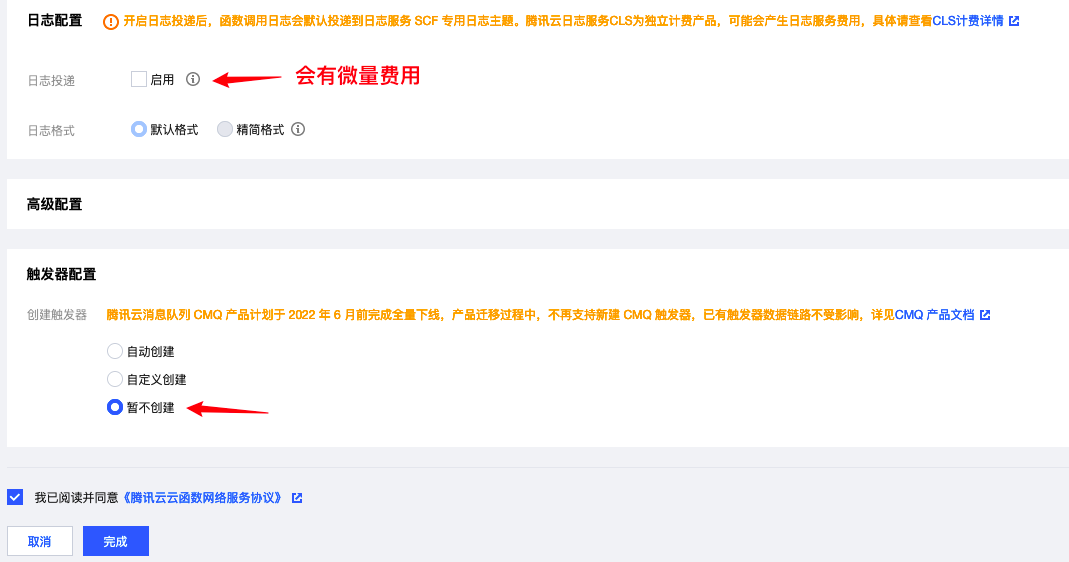
开启日志投递可以看到日志信息,很产生很少的费用,触发器配置这里选择暂不创建即可。然后勾选同意并单击完成。

等待创建后,会自动跳转到函数管理界面,我们可以切换到函数代码来查看在线编辑器,目前已经更换为云IDE:

目前已经有了一个使用静态数据的案例,我们先将完成API的创建,然后再结合TDSQL。
2. API创建
云函数开始运行后,我们需要为其设置访问的API。当然,同样需要在云函数中为其提供响应的支持,在这个例子中,主要提供了两个功能:
- article【GET】:获取文章列表
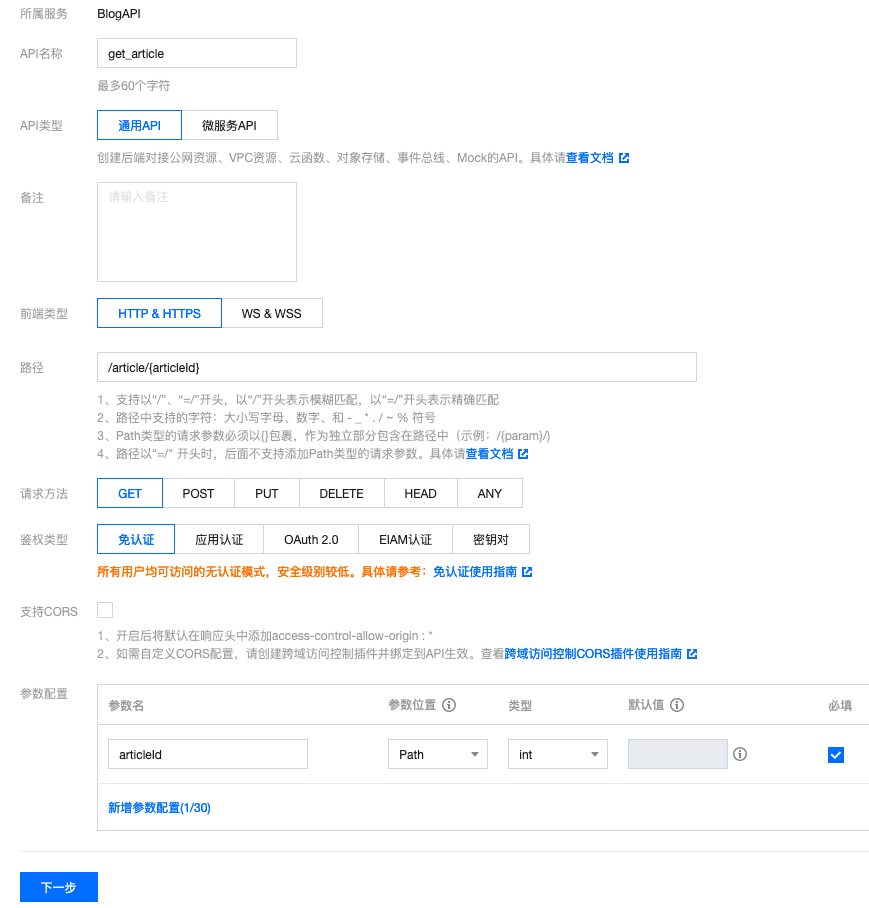
- article/{articleId}【GET】:获取文章内容
如果需要,我们可以扩展更多,现在我们先为已经有的两个功能来创建相应的调用API。首先打开API管理界面【第一次使用需要完成开通和授权流程】:

- 依次选择服务 - 地域,然后点击新建:
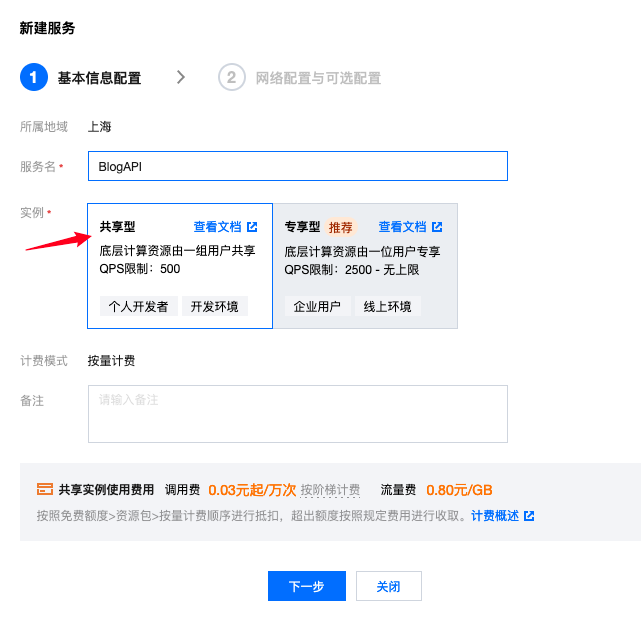
- 自定义服务名后选择共享型即可,继续下一步:

- 勾选公网方便测试,然后点击提交即可。再次点击创建的服务名进入API管理界面:
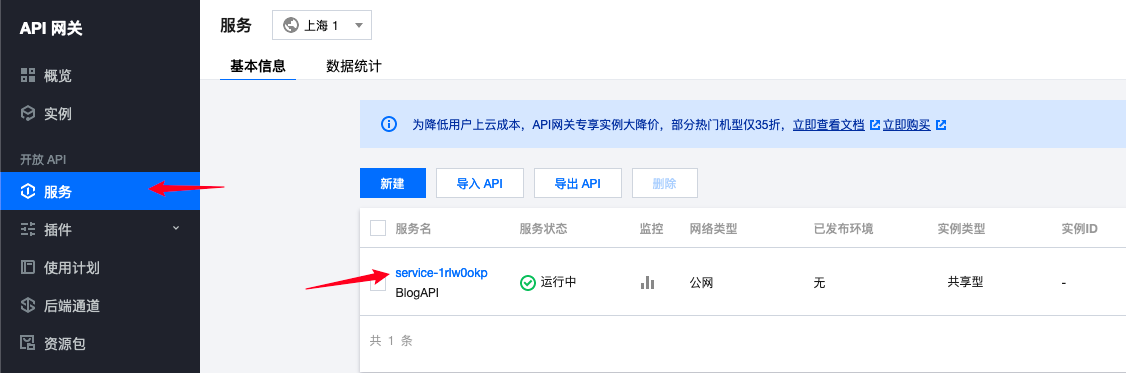
- 点击新建创建API:

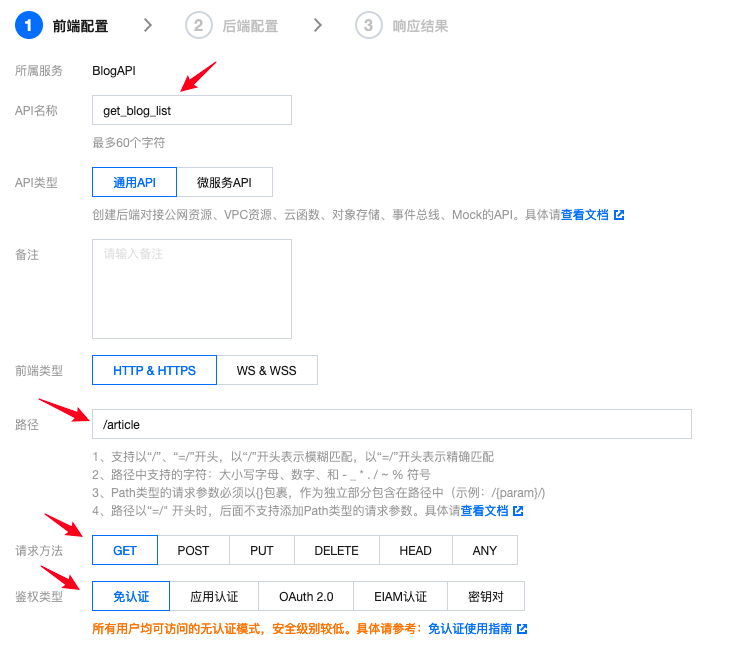
- 根据云函数中的定义配置相应的路径,并开启免认证,继续下一步:
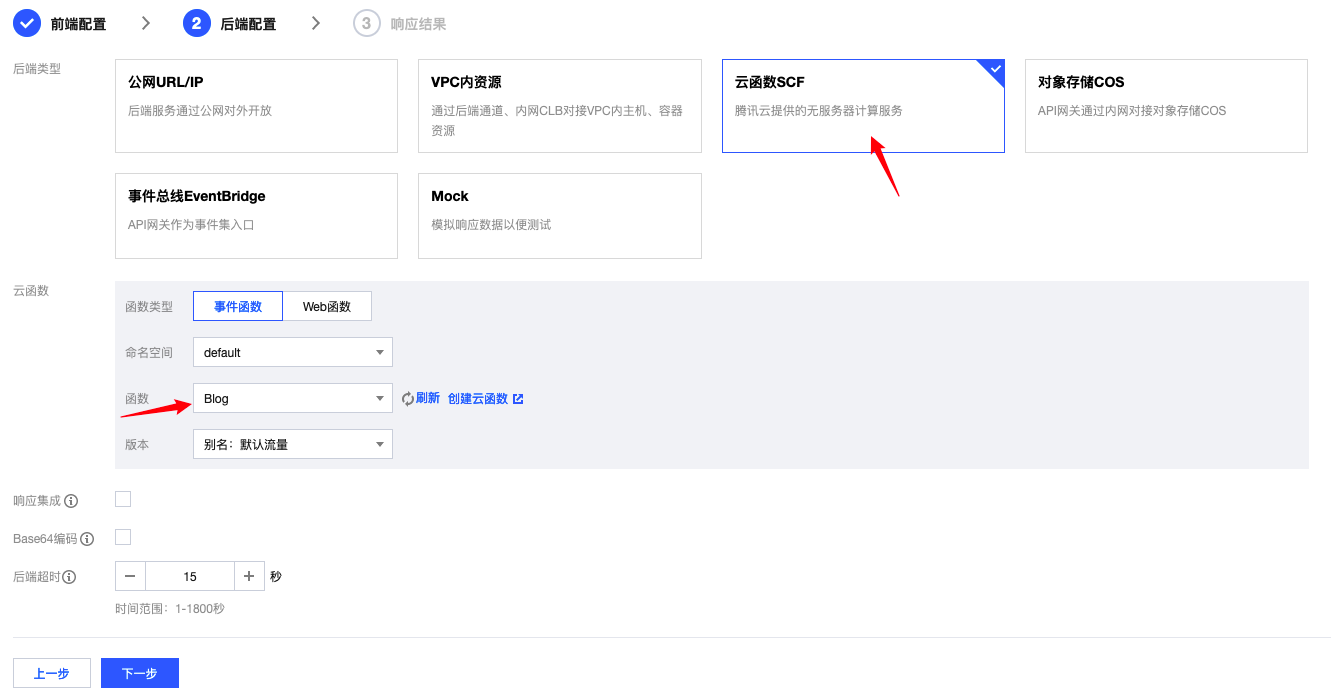
- 后端配置中选择云函数SCF,找到此前创建的Blog,其它如截图所示:
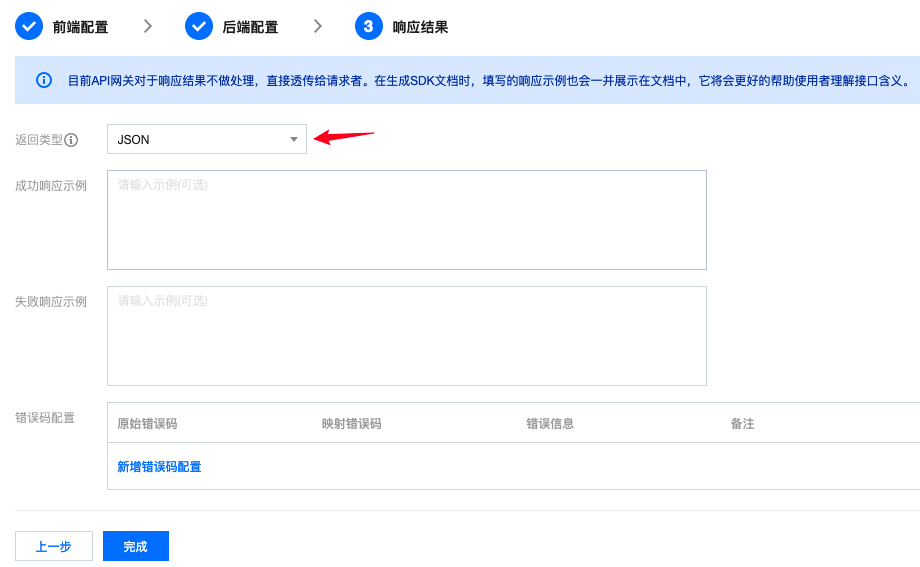
- 响应结果中更改返回类型为JSON,点击完成:
- 最后一步勾选测试,点击发布服务:
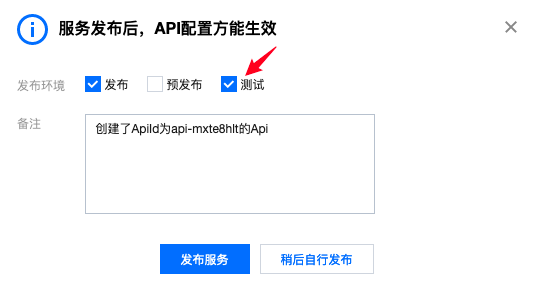
- 回到API列表页,切换到API调试,选择test,然后点击发送:

可以看到如下结果:
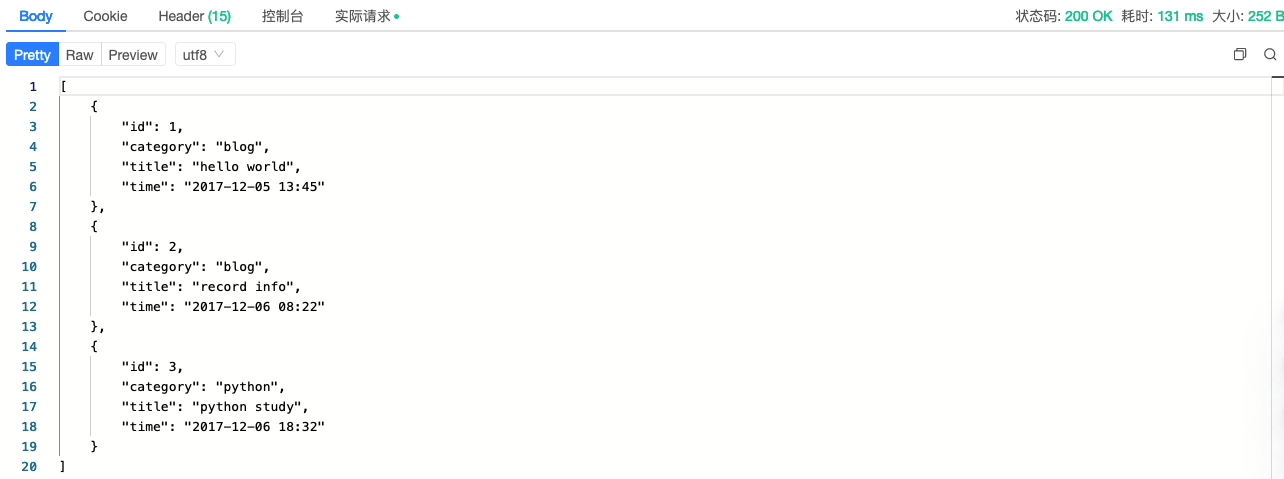
使用本地工具测试也可通过:

其它API可以使用相同的配置流程。
三、TDSQL配置
1. 免费创建
目前在活动页面可以免费获得分布式数据库TDSQL MySQL版 1核2G一个月:
- 选择合适地域后,点击立即购买:
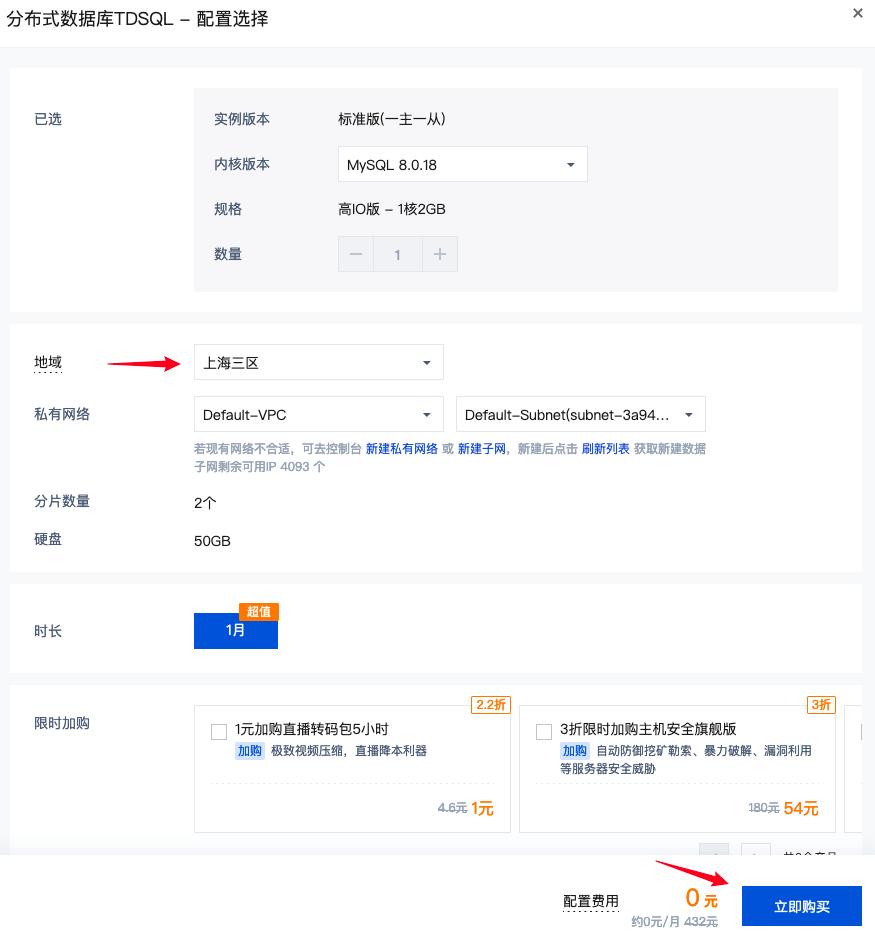
- 确认并0元支付:
- 购买完成后需要一些时间来准备,可以在管理界面查看:

- 准备完毕后需要进行初始化,点击更多,选择初始化来完成相关配置:

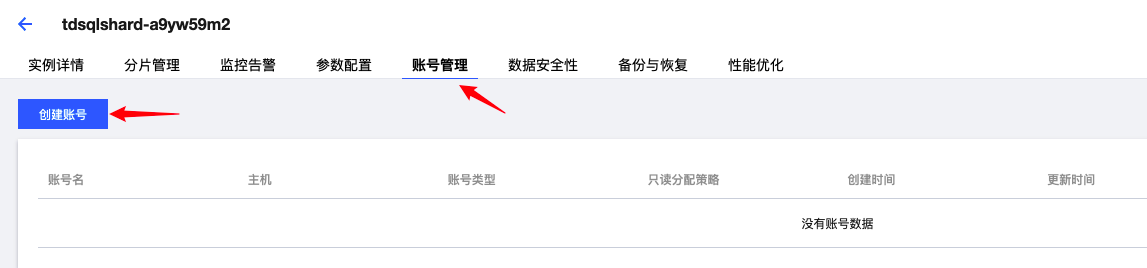
- 初始化完成后点击实例名称进入管理界面,点击账号管理 - 创建账号:
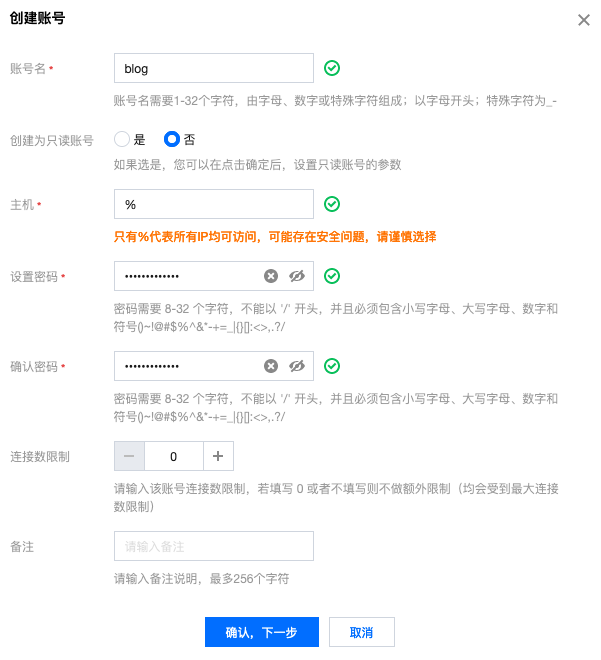
- 创建一个可以从任意IP连接的用户,主机填写%,其它可根据需要设置:
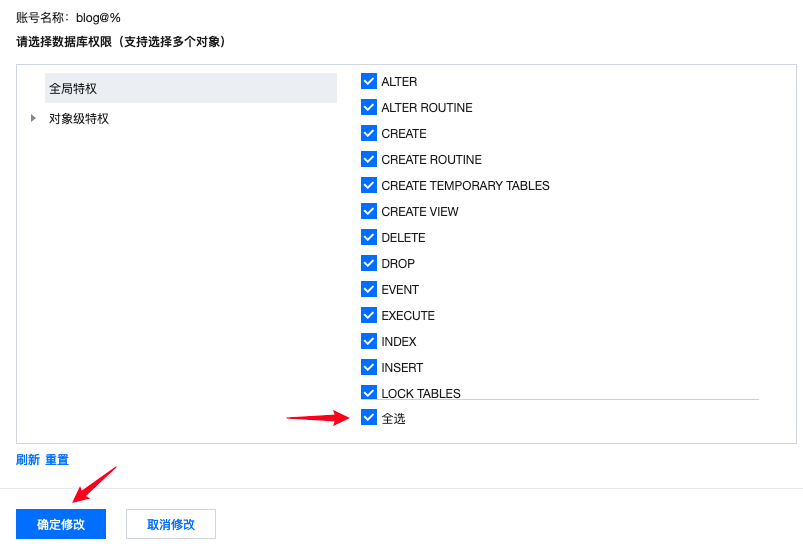
- 确认后继续修改用户权限:

- 为了方便测试,这里全选:
2. 连接测试
(1)云端连接
- 等待用户配置生效后,可以先在云端测试登录:


- 可以在云端通过SQL完成需要的操作:
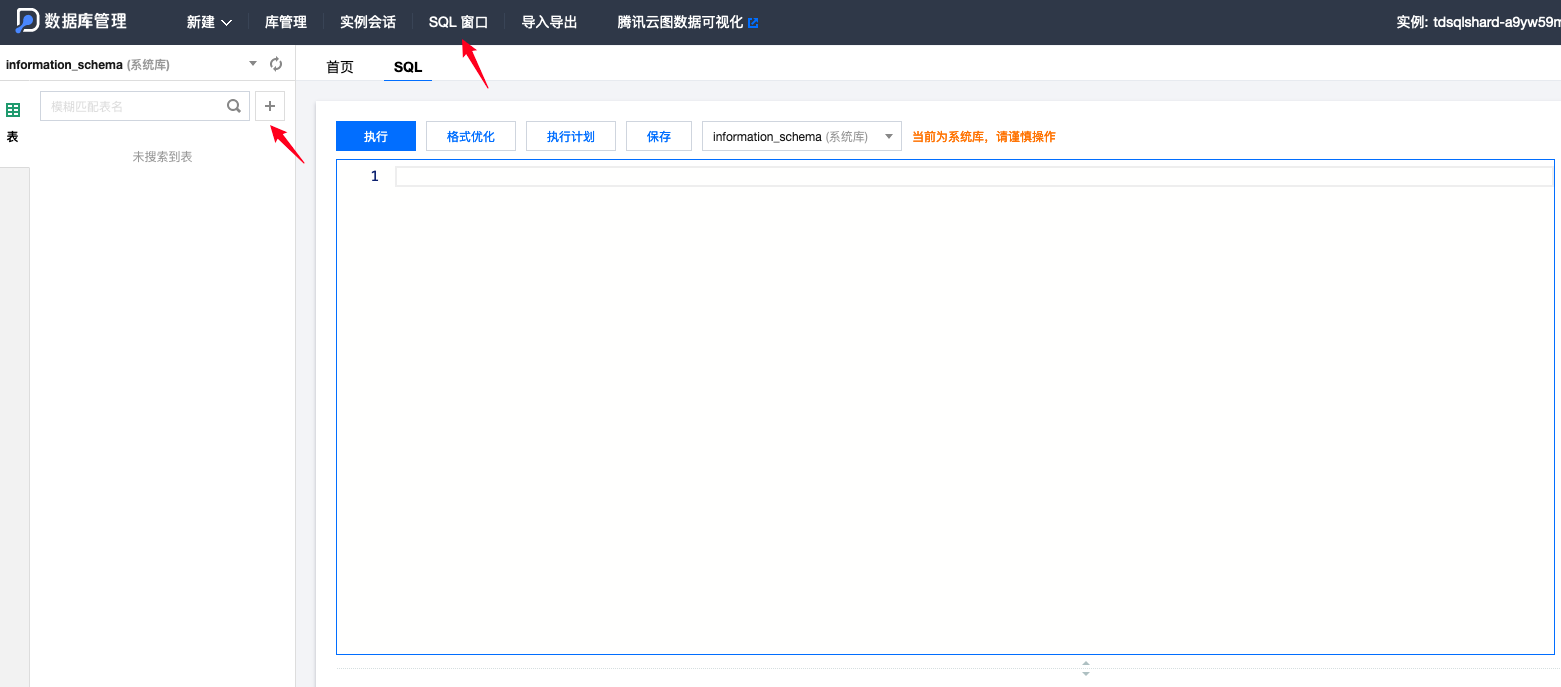
(2)外网连接
如果需要开启公网访问,需要按以下步骤操作:
- 修改网络模式来配置安全组:
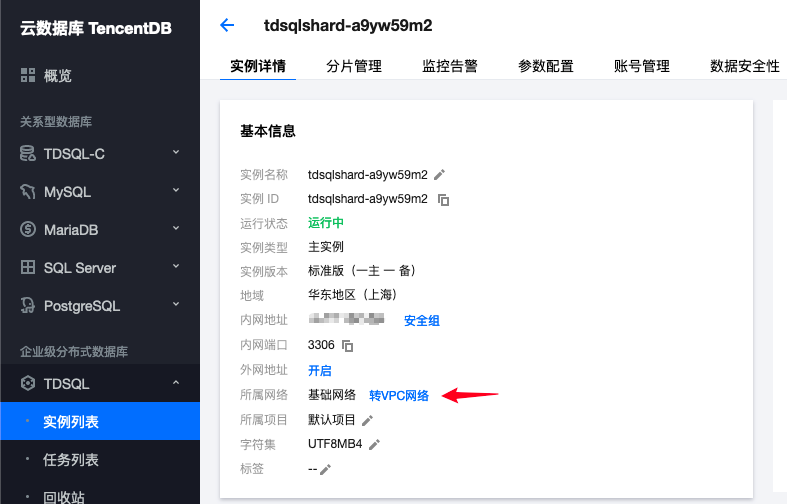
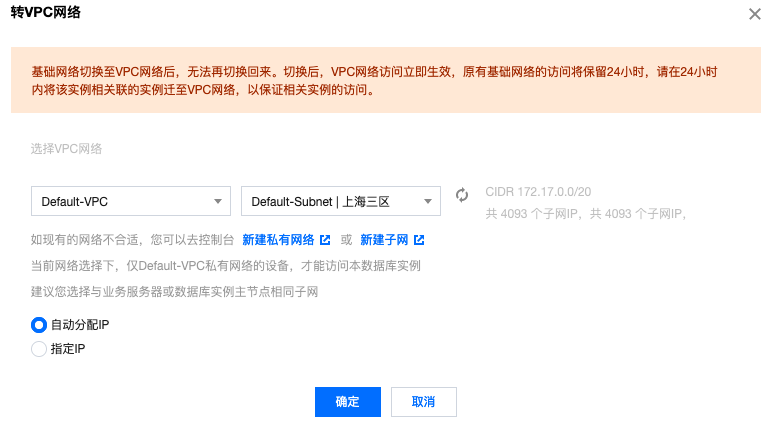
- 在安全组控制台添加一个规则:
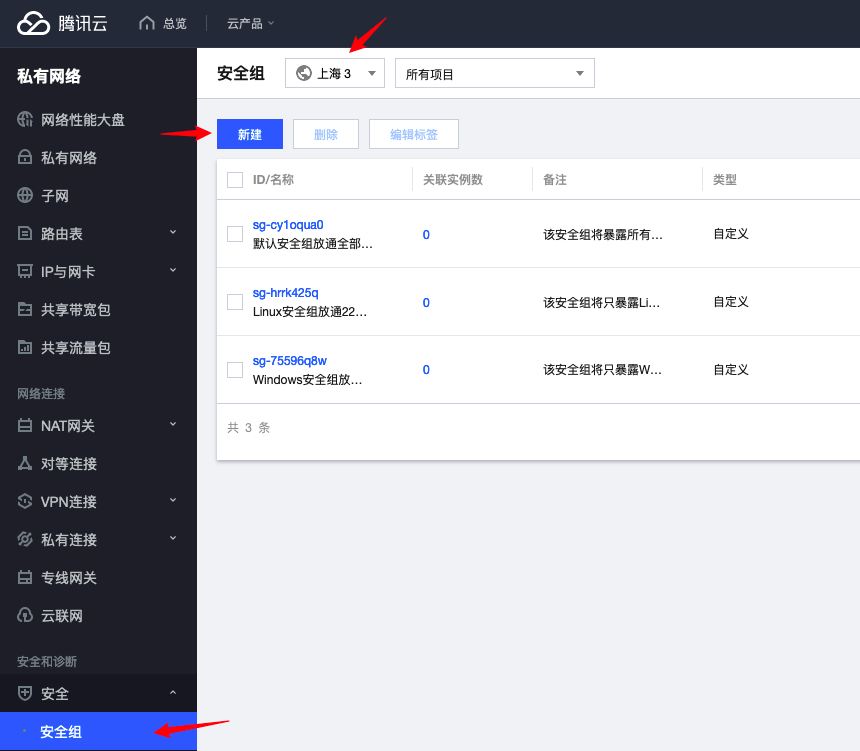
- 检查是否有一个开放所有端口的规则,如果没有,则创建一个:
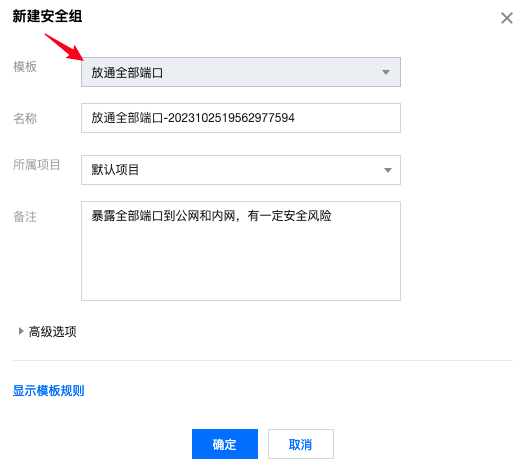
- 回到云数据库实例,点击安全组:
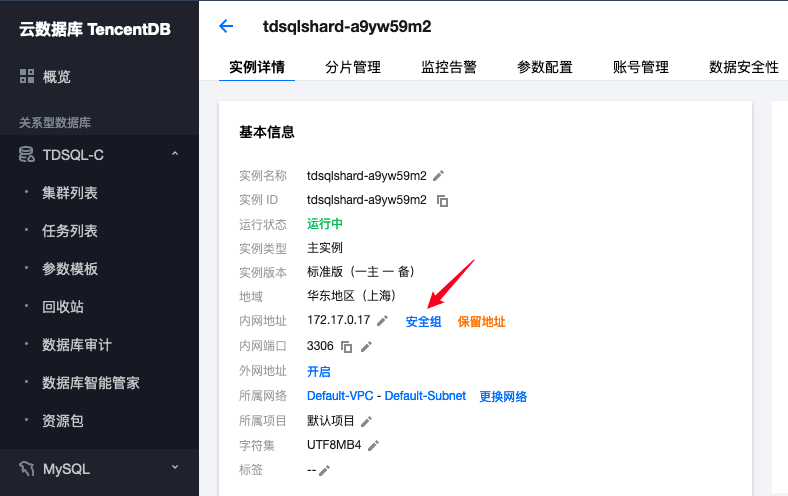

- 选择之前配置好的安全组
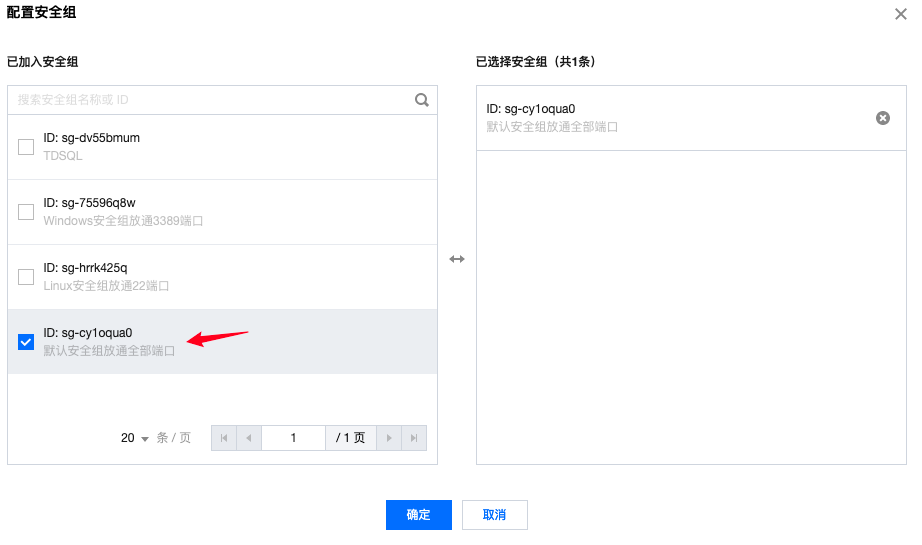
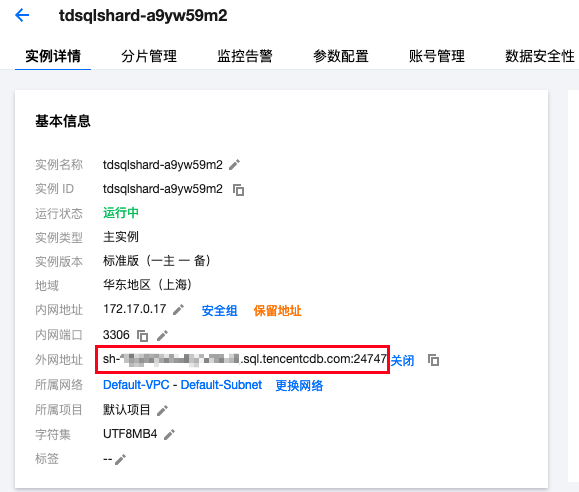
- 开启外网地址:


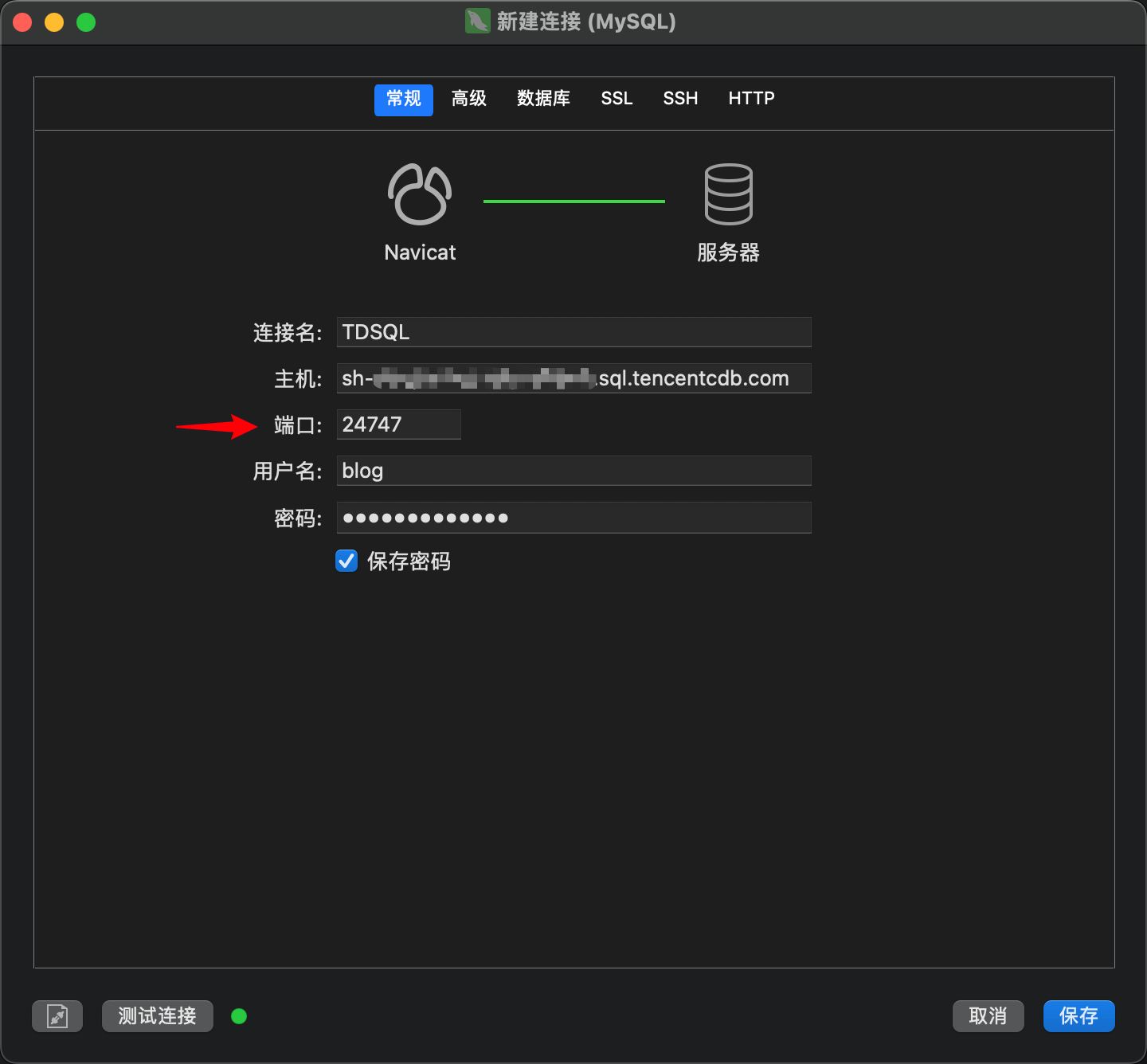
- 等待开启完毕后,可以看到一长串的外网地址,可以用于本地连接或代码调试:
四、整合测试
现在云函数和数据库都已经就位,接下来稍微修改一下云函数中的代码,改为从数据库中动态读取数据,感兴趣的小伙伴也可以添加更多功能。
1. 数据导入
- 创建数据库
创建一个blog数据库,编码使用UTF-8:
CREATE DATABASE blog CHARACTER SET utf8mb4;
- 创建数据表
根据原有代码的样例数据创建一个与之结构相匹配的数据表:
USE blog;CREATE TABLE IF NOT EXISTS articles (id INT PRIMARY KEY AUTO_INCREMENT,category VARCHAR(255) NOT NULL,title VARCHAR(255) NOT NULL,content TEXT NOT NULL,time DATETIME NOT NULL
);
- 插入数据
将样例数据插入到数据表中:
INSERT INTO articles (category, title, content, time) VALUES
('blog', 'hello world', 'first blog! hello world!', '2017-12-05 13:45:00'),
('blog', 'record info', 'record work and study!', '2017-12-06 08:22:00'),
('python', 'python study', 'python study for 2.7', '2017-12-06 18:32:00');
2. 修改代码
现在我们的所有数据已经在数据库中了,接下来我们做亿点点修改,将样例数据改为查询语句:
# -*- coding: utf-8 -*-import sys
import logging
import json
import pymysql
from datetime import datetimelogging.basicConfig(level=logging.INFO, stream=sys.stdout)
logger = logging.getLogger()
logger.setLevel(level=logging.INFO)logger.info('Loading function')db_config = {'host': 'sh-xxx.sql.tencentcdb.com','port': 24747,'user': 'blog','password': 'xxx','database': 'blog','charset': 'utf8mb4'
}def get_db_connection():return pymysql.connect(**db_config)def format_datetime(obj):if isinstance(obj, datetime):return obj.strftime('%Y-%m-%d %H:%M:%S')raise TypeError("Type not serializable")def main_handler(event, context):logger.info('start main_handler')if "requestContext" not in event.keys():return {"errorCode": 410, "errorMsg": "event is not come from api gateway"}if event["requestContext"]["path"] != "/article/{articleId}" and event["requestContext"]["path"] != "/article":return {"errorCode": 411, "errorMsg": "request is not from setting api path"}conn = get_db_connection()try:with conn.cursor(pymysql.cursors.DictCursor) as cursor:if event["requestContext"]["path"] == "/article" and event["requestContext"]["httpMethod"] == "GET": # 获取文章列表cursor.execute("SELECT id, category, title, time FROM articles")articles = cursor.fetchall()for article in articles:article['time'] = format_datetime(article['time'])return articleselif event["requestContext"]["path"] == "/article/{articleId}" and event["requestContext"]["httpMethod"] == "GET": # 获取文章内容articleId = int(event["pathParameters"]["articleId"])cursor.execute("SELECT * FROM articles WHERE id = %s", (articleId,))article = cursor.fetchone()if article:article['time'] = format_datetime(article['time'])return articleelse:return {"errorCode": 412, "errorMsg": "article is not found"}finally:conn.close()return {"errorCode": 413, "errorMsg": "request is not correctly execute"}
在函数代码界面,更新替换代码后,需要点击部署按钮,以发布最新版本。确认右上角显示已部署,测试时也可以考虑开启自动部署,保存后即会部署。

本例中,环境已经内置了PyMySQL来连接数据库,所以我们只需要更新代码就可以了。如果需要安装其它依赖也可以参考文档,使用pip命令进行安装。

3. 调用测试
代码部署完毕后,再次调用API进行测试:

获取某个文章内容的API可以参考如下配置:

至此,我们所有的操作均在无服务器下进行,代码的更新和部署也十分的方便,如果有帮助请点赞留言,支持一下!