文章目录
- CUDA与GPU编程
- 1. 并行处理与GPU体系架构
- 1.1 并行处理简介
- 1.1.1 串行处理与并行处理的区别
- 1.1.2 并行处理的概念
- 1.1.3 常见的并行处理
- 1.2 GPU并行处理
- 1.2.1 GPU与CPU并行处理的异同
- 1.2.2 CPU的优化方式
- 1.2.3 GPU的特点
- 1.3 环境搭建
CUDA与GPU编程
1. 并行处理与GPU体系架构
1.1 并行处理简介
计算机基本硬件组成
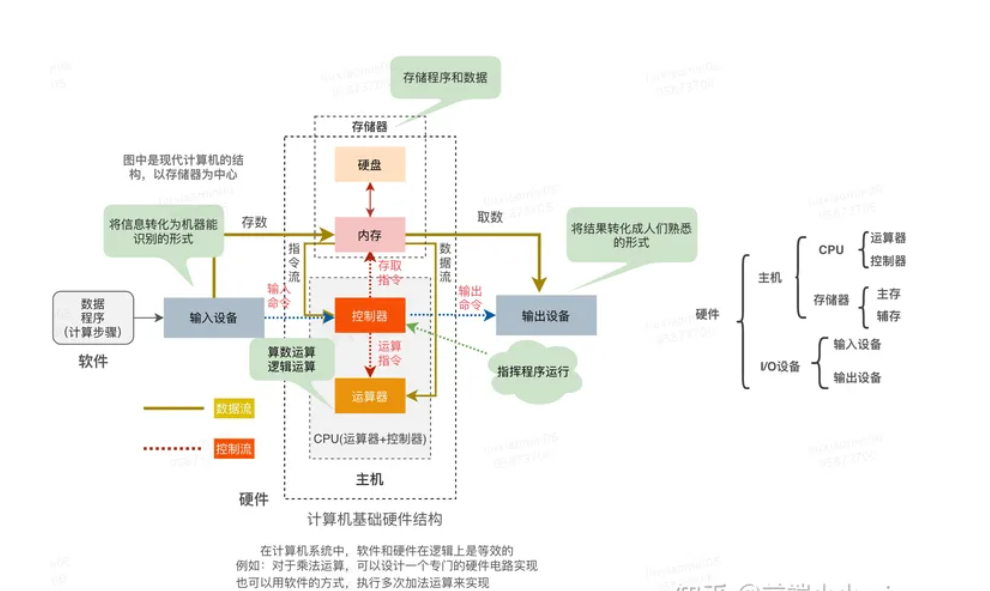
多CPU: 是指简单的多个CPU工作在同一个系统上,多个CPU之间的通讯是通过主板上的总线进行的
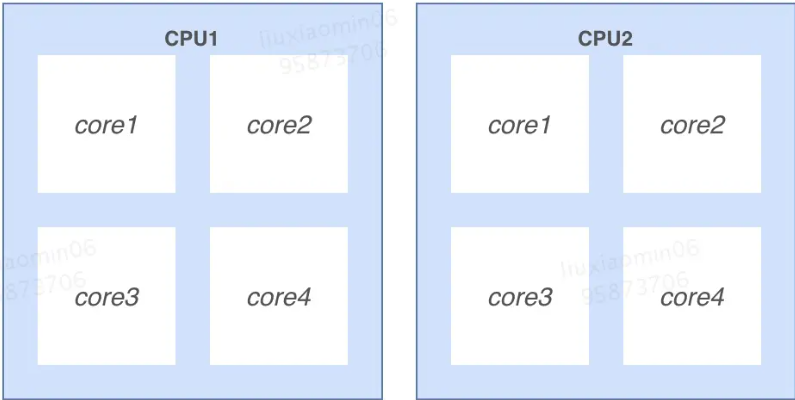
多核 :是指一个CPU有多个核心处理器,处理器之间通过CPU内部总线进行通讯。
进程和线程
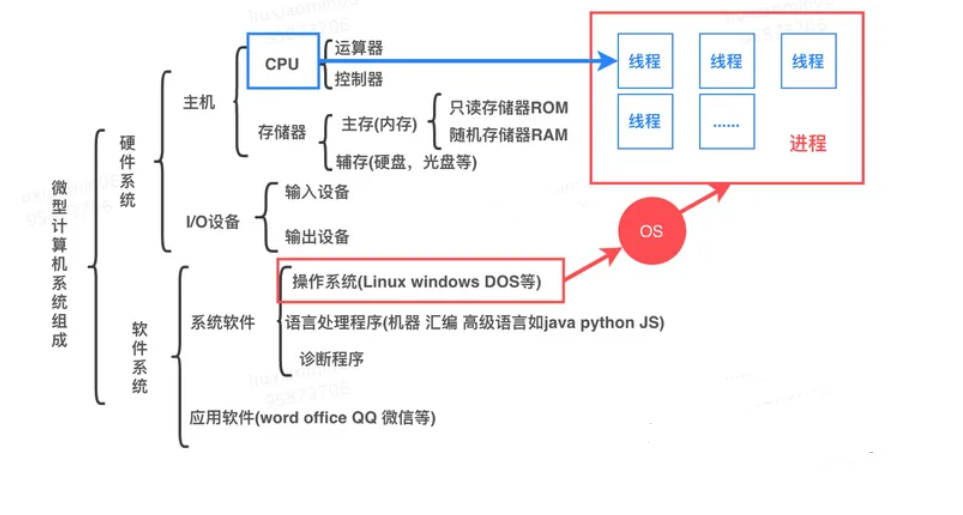
进程:是操作系统(OS)进行资源(CPU、内存、磁盘、IO、带宽等)分配的最小单位。一个进程就是一个程序的运行实例
启动一个程序的时候,操作系统会为该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程,我们把这样的一个运行环境叫进程,例如:打开一个浏览器、一个聊天窗口分别是一个进程。进程可以有多个子任务,如聊天工具接收消息、发送消息,这些子任务成为线程。
线程: 是CPU调度和分配的基本单位。操作系统会根据进程的优先级和线程的优先级去调度CPU。
线程数: 是一种逻辑概念,是模拟出的CPU核心数 。
进程和线程的关系描述如下:
- 进程可以简单理解为一个容器有自己独立的地址空间。一个进程可由多个线程的执行单元组成,每个线程都运行在同一进程的上下文中,共享进程该地址空间以及其内的代码和全局数据等资源即线程之间共享进程中的数据
- 每个进程至少有一个主线程,它无需由用户主动创建,一般由系统自动创建。系统创建好进程后,实际上就启动了执行该进程的执行主线程,执行主线程以函数地址形式,即程序入口函数(如 main函数),将程序的启动点提供给操作系统。主执行线程终止或关闭,进程也就随之终止,操作系统会回收改进程所占用的资源
- 进程中的任意一线程执行出错,都会导致整个进程的崩溃。
- 进程之间的内容相互隔离。进程隔离是为保护操作系统中进程互不干扰的技术,每一个进程只能访问自己占有的数据,也就避免出现进程 A 写入数据到进程 B 的情况。正是因为进程之间的数据是严格隔离的,所以一个进程如果崩溃了,或者挂起了,是不会影响到其他进程的。如果进程之间需要进行数据的通信,这时候,就需要使用用于进程间通信(IPC)的机制了。
- 严格讲应该是线程能够获得CPU资源,进程对CPU资源的获取也是体现在线程上的。CPU内核数,和进程线程没直接关系。操作系统(OS)可以把某个进程部署在某个CPU核上,但这取决于系统设计。
- 进程、线程都是由操作系统调度的,线程只是由进程创建,但是进程本身不会负责调度线程。在操作系统看来,线程和进程其实差不多,不同点是线程是迷你的进程,并且进程可以包含多个线程
- 对于内存堆内存、代码区一般属于一个进程,但是栈(执行栈)却是属于一个线程的,且每个线程拥有一个独立的栈。
1.1.1 串行处理与并行处理的区别
-
串行处理(Serial Processing):
-
指令/代码块依次执行任务按顺序依次执行,一个任务完成后才会开始下一个任务。
-
串行处理是指在一个特定的时间点上,只有一个任务在执行。
-
这意味着任务之间相互等待,执行时间较长的任务会影响整体性能。一般来说,当程序有数据依赖or分支等这些情况下需要串行
-
-
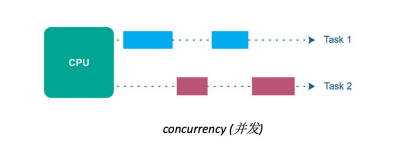
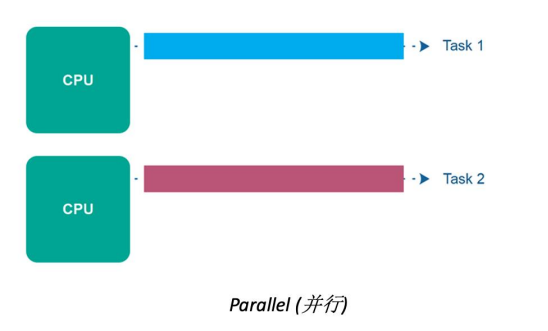
并行处理(Parallel Processing):
- 并行处理是指在同一时刻多个任务可以同时执行。
- 任务被分成多个子任务,这些子任务可以在多个处理单元(例如多核处理器或分布式系统中的多台计算机)上并行执行。
- 并行处理可以显著提高任务的执行速度和系统的性能。
- 指令/代码块同时执行
- 充分利用multi-core(多核)的特性,多个core一起去完成一个或多个任务
- 使用场景:科学计算,图像处理,深度学习等等
在并行处理中,任务之间可以是相互独立的,也可以是相互依赖的。并行处理通常需要额外的硬件支持和编程技巧来管理任务之间的同步和数据共享。
总之:
- 串行处理是按顺序执行任务,而并行处理是同时执行多个任务。
- 并行处理通常用于加速计算和提高系统性能,特别是在需要处理大量数据或计算密集型任务时。
1.1.2 并行处理的概念
在计算机科学中,“并行处理” 是指同时执行多个任务或操作的技术。它利用多个处理单元或线程来并发执行任务,从而提高程序的执行速度。在 Python 中,我们可以利用多线程、多进程或异步编程等技术来实现并行处理。
1.1.3 常见的并行处理
- 多核处理器(Multi-Core Processors):
- 多核处理器包含多个CPU核心,每个核心可以独立执行指令。这意味着多个任务可以在不同核心上并行执行。
- 多核处理器常见于现代计算机和移动设备,使多线程应用程序可以更有效地运行。
- 并行计算集群(Parallel Computing Clusters):
- 并行计算集群是由多台计算机组成的网络,它们可以协同工作来解决大规模计算问题。
- 每台计算机都可以处理一部分任务,通过网络通信和协作,实现任务的并行执行。
- GPU并行处理(GPU Parallel Processing):
- 图形处理单元(GPU)在图形渲染之外也可用于一般计算任务。它们具有大量的小型处理单元,适合并行计算。
- GPU计算用于加速科学计算、深度学习、机器学习等领域。
- 分布式计算(Distributed Computing):
- 分布式计算是将任务分发给多台计算机,这些计算机可能位于不同地理位置。
- 通过分布式系统,可以同时处理大规模数据集或执行计算密集型任务。
- SIMD(Single Instruction, Multiple Data)并行性:
- SIMD是一种并行处理技术,其中一条指令同时作用于多个数据元素。
- SIMD通常用于多媒体处理和向量计算,如图像处理和音频处理。
- 多线程并发(Multithreading):
- 多线程技术允许在同一程序中创建多个线程,每个线程可以执行不同的任务。
- 多线程并发可用于处理并行性较低的任务,如GUI应用程序和服务器。
- 数据流并行性(Dataflow Parallelism):
- 数据流并行性是一种并行处理模型,其中任务的执行取决于数据的可用性。
- 当数据可用时,相关任务可以并行执行,而无需严格的同步。
并行化处理是将一个任务分解成多个子任务,每个子任务可以独立地进行处理。这样可以提高处理速度和效率。
- 分治法:将大问题分解成若干小问题,并且这些小问题可以独立地进行计算,最后将结果合并得到答案。
- 数据划分法:将数据划分成多份,每份数据可以独立地进行计算,最后将结果合并得到答案。
- 流水线法:将一个任务分为若干阶段,每个阶段可以独立地进行计算,并且不同阶段之间的数据传输要尽可能快。
- 线程池技术:在程序启动时创建一定数量的线程,并放入线程池中,当需要执行某个任务时从线程池中取出一个线程来执行,执行完毕后再归还给线程池。
- OpenMP库:OpenMP是一个针对共享内存架构的并行编程API标准。它支持C、C++和Fortran等语言,在代码中使用预处理器指令就能够实现多线程编写。
- MPI库:MPI(Message Passing Interface)是一种消息传递编程模型,在分布式系统上实现进程间通信。MPI库适用于各种形式的并行计算,包括集群、超级计算机和网格计算等。
Python 提供了多个并行处理库,其中一些常用的库包括:
- multiprocessing:这个内置库提供了跨平台的多进程支持,可以使用多个进程并行执行任务。
- threading:这个内置库提供了多线程支持,可以在同一进程内使用多个线程并行执行任务。
- concurrent.futures:这个标准库提供了高级的并行处理接口,可以使用线程池或进程池来管理并发任务的执行。
- joblib:这是一个流行的第三方库,提供了简单的接口来并行执行 for 循环,尤其适用于科学计算和机器学习任务。
- dask:这是一个灵活的第三方库,提供了并行处理和分布式计算的功能,适用于处理大规模数据集。
1.2 GPU并行处理
1.2.1 GPU与CPU并行处理的异同
相同点:
- 并行性支持: GPU和CPU都支持并行处理,但它们的并行性方式有所不同。
- 计算能力: GPU和CPU都可以执行计算任务,但GPU在某些特定类型的计算任务上表现更出色。
不同点:
- 体系结构: GPU和CPU具有不同的体系结构。CPU通常具有较少的核心(一般为几个到几十个),而GPU具有大量的小型核心(通常为数百到数千个)。这使得GPU在同时处理大规模数据时更具优势。
- 用途: CPU通常用于一般计算任务,如操作系统管理、文件处理和串行计算。而GPU主要设计用于图形渲染,但也在科学计算、深度学习和机器学习等需要大规模并行计算的领域中得到广泛应用。
- 指令集: CPU具有复杂的通用指令集,适用于各种计算任务。GPU的指令集通常较简单,适用于执行相同操作的大量数据。
- 内存层次结构: CPU通常具有更大、更快速的高速缓存,适用于较小的数据集。GPU通常具有大量的全局内存,适用于处理大规模数据集。
- 编程模型: 编写针对GPU的并行代码通常需要使用特定的编程模型,如CUDA(用于NVIDIA GPU)或OpenCL。而CPU上的并行编程通常使用多线程和多进程来实现。
- 功耗和散热: GPU通常在相对较高的功耗下运行,因为它们的设计重点是性能。相比之下,CPU通常更注重功耗效率和散热控制。
综上所述,GPU和CPU都支持并行处理,但它们在体系结构、用途、指令集、内存层次结构和编程模型等方面存在显著差异。选择使用哪种处理器取决于具体的计算任务和性能需求。在一些情况下,GPU可以显著加速大规模并行计算,而CPU则更适用于通用计算和较小规模的任务。
1.2.2 CPU的优化方式
- 多核利用: 如果计算机使用多核CPU,确保充分利用所有核心。编写多线程应用程序或使用并行编程框架来将任务分发到多个核心上,以提高性能。
- 高性能编程语言: 选择使用高性能编程语言,如C++或Rust,以编写计算密集型应用程序。这些语言通常具有更好的性能优化支持。
- 编译器优化: 使用优化的编译器选项来生成高效的机器码。编译器可以进行各种优化,包括内联函数、循环展开和代码重排。
- CPU指令级优化: 利用CPU的特定指令集扩展,如SSE(Streaming SIMD Extensions)或AVX(Advanced Vector Extensions),以加速特定类型的计算任务。
- 缓存优化: 编写代码时考虑缓存的层次结构,尽量减少缓存未命中。这包括循环访问数组时考虑局部性,并使用缓存友好的数据结构。
- 减少分支: 避免过多的条件分支,因为分支可能导致流水线停滞。优化代码以减少分支预测错误的可能性。
- 循环优化: 对于性能关键的循环,进行循环展开、循环重排和循环剥离等优化,以提高指令级并行性。
- 数据并行性: 使用SIMD指令和向量化编程,以在单个指令中处理多个数据元素,从而提高并行性。
- 内存优化: 减少内存访问次数,使用局部变量和缓存数据以减少内存延迟。
- 多线程并发: 利用多线程来并行执行任务,特别是在多核CPU上。使用线程池或并发框架来管理线程。
- 性能分析工具: 使用性能分析工具(如Profiling工具)来识别性能瓶颈,并根据分析结果进行优化。
- 硬件加速: 对于某些计算密集型任务,可以考虑使用GPU或专用硬件加速器来提高性能。
- 避免不必要的同步: 减少线程之间的同步操作,以避免竞态条件和锁竞争,从而提高性能。
- 优化算法: 选择适当的算法和数据结构,以减少计算复杂度,从而提高性能。
- 定时和调度: 了解操作系统的定时和调度机制,以便优化任务的调度和响应时间。
1.2.3 GPU的特点
1.3 环境搭建
lspci| grep

lsb_release -a
nvidia-smi
1.全面掌握「进程与线程、并发并行与串行、同步与异步、阻塞与非阻塞」的区别