文章目录
- Python下载安装
- 开发工具IDEA
- 包管理
- 安装pip
- 基本用法
- 从 requirements.txt 安装依赖
- 项目示例
- 部署
- 在 Linux 上安装Python
- 在 Linux 上创建虚拟环境:
- 安装依赖:
- 运行你的爬虫
Python下载安装
Python 安装包下载地址:https://www.python.org/downloads/
- https://www.python.org/downloads/windows/
1.有两个版本的 Python,分别是 Python 3.x 和 Python 2.x,选择3.x
embeddable zip file表示.zip格式的绿色免安装版本,可以直接嵌入(集成)到其它的应用程序中;executable installer表示.exe格式的可执行程序,这是完整的离线安装包,一般选择这个即可;
2.下载安装,勾选ADD python to PATH,安装即可
3.验证
# 在控制台输入python
python
# 输出
Python 3.7.9 (tags/v3.7.9:13c94747c7, Aug 17 2020, 18:58:18) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
# 输入exit()退出
exit()
开发工具IDEA
1.下载Python插件
2.新建项目
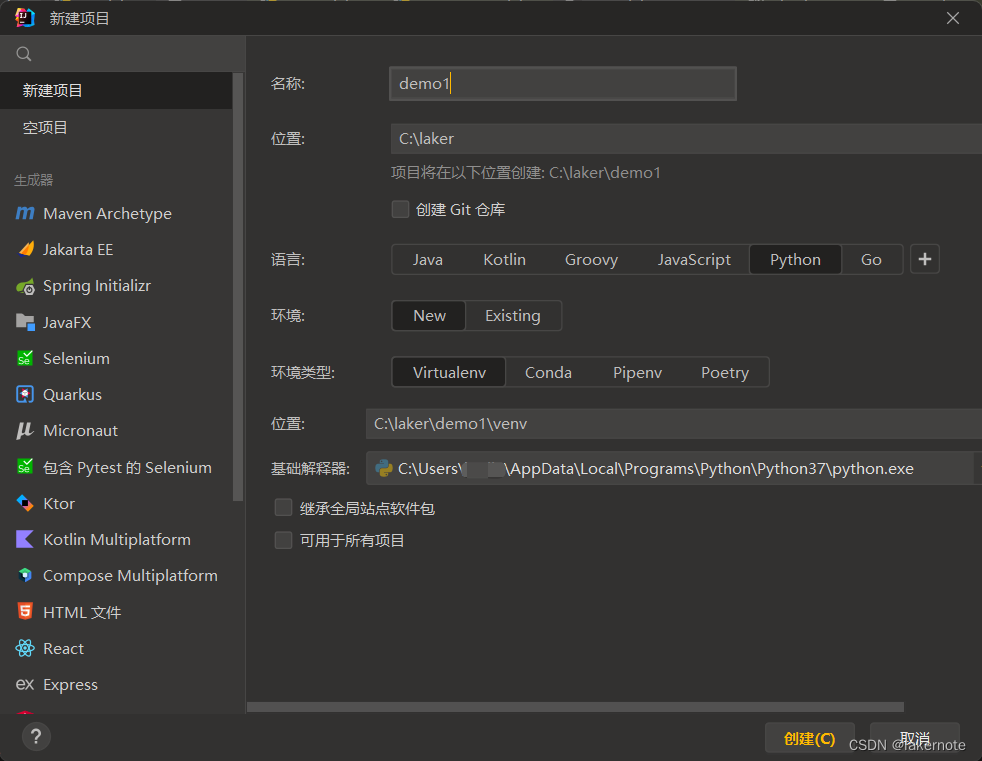
其中的环境类型为:选择第一个虚拟环境【python-virtualenv】
虚拟环境为您的Python包提供了一个干净的工作空间,以便您安装的库不会与为其他项目安装的库发生冲突。
包管理
类似java中的maven,python有很多优秀的管理工具pip、anaconda、poetry
这里我们使用自带的pip
安装pip
大多数情况下,Python 安装时已经包含了 pip。您可以通过以下命令检查是否已安装:
pip --version
如果没有安装,可以使用以下命令安装:
python -m ensurepip --default-pip
基本用法
一般来说,第三方库都会在Python官方的pypi.python.org网站注册,要安装一个第三方库,必须先知道该库的名称,可以在官网或者pypi上搜索,比如Pillow的名称叫Pillow,因此,安装Pillow的命令就是:
pip install Pillow
# 查看已安装的包
pip list
# 查找包
pip search package_name
# 安装包
pip install package_name
# 安装特定版本
pip install package_name==1.2.3
# 安装大于或等于某版本的最新版
pip install "package_name>=1.2.3"
# 升级包 到最新版本
pip install --upgrade package_name
# 卸载包
pip uninstall package_name
# 查看包的信息
pip show package_name
#
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
从 requirements.txt 安装依赖
如果您有一个 requirements.txt 文件,其中列有项目依赖的包及其版本,可以使用以下命令一次性安装它们:
pip install -r requirements.txt
requirements.txt示例
# 项目依赖列表
package1==1.2.3
package2>=2.0.0
package3<4.0.0
根据具体的包和版本要求来编辑这个文件。通常,在团队协作或部署项目时,使用 requirements.txt 是一种标准的做法,以确保每个开发者或部署环境都使用相同的依赖版本。
导出依赖信息
在你的项目目录下,运行以下命令,将当前虚拟环境的依赖导出到 requirements.txt 文件:
pip freeze > requirements.txt
这会生成一个包含项目依赖的文件,其中包括 requests 和 beautifulsoup4。
项目示例
网络爬虫是一种自动化程序,用于抓取互联网上的数据。网络爬虫可以自动访问网页、解析网页内容、提取所需数据、存储数据等。通过使用网络爬虫,我们可以获取大量的数据,从而进行数据分析、数据挖掘等应用。
- 在抓取网站数据时,需要遵守网站的robots协议和使用条款等规定,不得未经授权地进行抓取。
- 在抓取网站数据时,需要考虑网络性能和资源消耗,避免对网站造成不必要的负担。
- 在抓取网站数据时,需要考虑数据质量和数据安全,避免抓取到恶意数据或错误数据。
网络爬虫常用库如下:
- requests库:用于发送HTTP请求和接收HTTP响应。例如,使用requests.get(url)来发送GET请求,使用requests.post(url, data)来发送POST请求。
- BeautifulSoup库:用于解析HTML和XML文档。例如,使用BeautifulSoup(html, ‘html.parser’)来解析HTML文档,使用BeautifulSoup(xml, ‘xml’)来解析XML文档。
以下是一个爬虫示例:
首先安装上面2个依赖库
pip install requests
pip install beautifulsoup4
import requests
from bs4 import BeautifulSoupurl = 'https://www.python.org/'# 发送HTTP请求
response = requests.get(url)# 解析HTML文档
soup = BeautifulSoup(response.text, 'html.parser')# 提取数据
title = soup.title.string
links = [link.get('href') for link in soup.find_all('a')]# 打印结果
print(title)
for link in links:print(link)
部署
在 Linux 上安装Python
sudo yum install python3
# 显示已安装的版本号
python --version
# python3用这个
python3 --version
在 Linux 上创建虚拟环境:
在 Linux 服务器上,进入你的项目目录,并创建一个新的虚拟环境:
python3 -m venv venv
激活虚拟环境:
source venv/bin/activate
安装依赖:
使用 pip 安装项目依赖:
pip install -r requirements.txt
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
pip install --upgrade pip
# 或者手动安装
pip install requestspip install beautifulsoup4
运行你的爬虫
确保你的项目中有一个入口文件(例如,main.py),然后在虚拟环境中运行你的爬虫:
python3 main.py