CiteSpace概述
CiteSpace 是一个用于可视化和分析科学文献的工具,它专门针对研究者进行文献回顾和趋势分析。CiteSpace 的核心功能是创建文献引用网络,这些网络揭示了研究领域内各个文献之间的相互关系。使用 CiteSpace 可以为论文研究做出贡献的几种方式包括:
-
趋势分析:CiteSpace 可以帮助识别某个研究领域内的热门主题和趋势,以及这些主题随时间的变化情况。
-
关键文献识别:通过分析文献之间的引用关系,CiteSpace 可以帮助研究者找到领域内的关键论文和经典作品。
-
研究空白发现:CiteSpace 的网络图可以揭示当前研究领域的空白,即尚未被深入研究的领域,这对确定研究方向很有帮助。
-
合作网络分析:CiteSpace 还可以分析作者、机构之间的合作网络,帮助研究者找到潜在的合作伙伴或影响力较大的研究团队。
-
引用文献管理:它还可以作为文献管理工具,帮助整理和分析论文研究中引用的文献。
使用 CiteSpace 时,研究者通常需要从数据库(如 Web of Science)中导入相关文献的引用记录。CiteSpace 会根据这些数据生成网络图和各种指标,从而帮助分析文献的影响力、研究领域的演变、以及研究领域之间的关系。通过这些功能,CiteSpace 能够为学术论文的撰写和研究提供重要的辅助。
Zotero
Zotero 是一个免费的、开源的参考文献管理软件,它被广泛用于学术研究和论文撰写中。Zotero 的主要特点和功能包括:
-
文献收集和管理:Zotero 允许用户从各种学术数据库和网站直接导入参考文献。它支持各种文献格式,包括书籍、期刊文章、会议论文等。
-
组织和分类:用户可以在 Zotero 中创建文件夹,对文献进行分类和组织。它还支持标签和注释,便于用户对文献进行更细致的管理。
-
引用生成和文献格式化:Zotero 能够自动生成多种引用格式(如 APA、MLA、Chicago 等),并可以直接插入到 Word 文档或其他文本编辑器中。这极大地简化了论文写作中的引用过程。
-
云同步和共享:Zotero 提供云存储服务,用户可以在不同设备之间同步文献数据库。同时,它支持文献库的共享功能,方便协作研究。
-
浏览器集成:通过安装 Zotero 的浏览器扩展,用户可以轻松地从网页中捕获引用信息和全文。
-
PDF管理和阅读:Zotero 允许用户导入PDF文件,甚至可以直接在软件内阅读和标注PDF。
-
研究网络构建:Zotero 用户可以加入或创建公共或私有的研究组,共享文献资源,促进学术交流。
-
多平台支持:Zotero 可以在多种操作系统上运行,包括 Windows、macOS 和 Linux。
Zotero 的易用性和强大的功能使其成为学术研究人员和学生撰写论文时的重要工具。通过高效管理和引用文献,Zotero 能显著提高研究工作的效率。
文献阅读
题目

题目:"Incorporation of Deep Kernel Convolution into Density Clustering for Shipping AIS Data Denoising and Reconstruction" 可以翻译为:
"将深度核卷积融入密度聚类以实现船舶自动识别系统(AIS)数据的去噪和重构"。
这里的术语解释如下:
- 深度核卷积(Deep Kernel Convolution):这指的是一种深度学习方法,通过将核方法(一种用于处理非线性数据的技术)与卷积神经网络相结合,以提取数据的高级特征。
- 密度聚类(Density Clustering):这是一种聚类算法,用于根据样本分布的密度将数据分为不同的群组。它能够识别出任意形状的簇,并且对噪声数据有很好的鲁棒性。
- 船舶自动识别系统(AIS)数据去噪(Denoising):这是指用于清除从船舶自动识别系统收集的数据中的噪声或错误信息的过程。
- 数据重构(Reconstruction):在去除噪声后,对原始数据进行重建或恢复,以便更准确地反映实际情况。
摘要

- explosion:激增;robust:鲁棒性;kinematics feature:运动学特征;anomalous data/aberrant data异常值;piecewise cubic spline interpolation:分段三次样条插值;
- 简单讲,这篇文章就是为了保证爆炸数量的AIS数据质量和安全性,对数据进行处理。首先利用运动学特征进行数据预处理,去除明显噪声和异常点数据;然后利用深度卷积核结合密度聚类对数据进行更细致的降噪处理;最后为更好平滑轨迹,使用分段三次样条插值法对数据进行重构。
结果展示与分析

首先看到左上角概述,然后看第一点——原始数据。本段关键点是说明选取两个不同地区的海上数据的原因:北冰洋范围大,其数据可以用来验证降噪算法性能performance如何;多佛海峡范围小但数据复杂,可以用来展示算法在此条件下的健壮性robustness如何。

- 英文表述:The visualization result of .. is shown in Figure 3 and 4,respectively. 可视化结果分别如图3和4显示。这个和中文表述不同,中文论文建议图3和图4,英文不必重复。
- It can be seen that ... 可以得出
- As aforementioned in the above assumptions, 不知道能不能这样应用。
- shown 和 listed 我认为对于数据来说可以互换,图片还是shown,不知道demonstrated行不行
核函数选择

首先明确良好去噪效果的体现:首先满足降噪的目的——异常点清理越干净越好,但是往往会出现问题,很有可能将原本的正确轨迹清除导致轨迹不完整。所以去噪效果是要使得二者达到平衡!

明显(b)最优
降噪结果展示
- 英文表述:The original dataset includes much of the data from all the waiting, berthing, and mooring ships.重点关注三个船舶领域动词:waiting 等待;berthing 靠泊;mooring 停泊;
- A lot of trajectories with anchorage points were removed.许多带有锚地点的轨迹被移除。
这里有意思的点是,我当初还没有读后续的异常值筛选标准。文中写到它删除了许多锚地点轨迹甚至部分停留船的位置,我当初想的是,需要考虑一定的停留船的位置,因为如果删除停留位置,就可能撞到停留船只。
分析一下:
在船舶轨迹分析中,异常通常指的是那些不符合正常航行模式的点,例如由于传感器错误、数据传输问题或不正常的船舶行为产生的点。然而,停留点,比如锚地点,通常是船舶正常活动的一部分,特别是在港口或繁忙水域。
在进行轨迹去噪和分析时,关键在于区分船舶的正常活动和潜在的异常行为。例如,删除靠泊或者停泊的船只的位置数据可能会在某些分析中造成信息的缺失,尤其是在需要考虑船舶停靠和等待状态的场合。删除这些点可能会影响对海上交通流的全面理解,尤其是在进行碰撞避免分析时,知道这些船舶的位置是至关重要的,因为即使是不动的船舶也可能对正在移动的船舶构成潜在的风险。
因此,在处理AIS数据时,需要根据应用场景的特定需求来决定是否保留停留点。在某些情况下,可能会选择保留这些点以保证数据的完整性,特别是在需要确保航道安全和规划避碰策略的场合。
所以说为什么要删除锚点?

给学过素描的读者一些启发:

理想的情况下,数据预处理和降噪应该是大大降低数据点和轨迹数据的,然后利用插值稍微填补一下即可。但是也会存在插值填补之后数据点甚至比原始数据集的数据点还多的情况,展示和解答如下图所示。

理解降噪和重构的核心目标,抓住主要矛盾,忽略次要矛盾!
轨迹重构结果展示

其实和上一个图是一样的,都展示了完整的过程。从中可以学到图片排版与放大展示,非常好看有科技感!

为了进一步验证该算法的效能,文章还选取了新的真实的船舶数据进行实验分析,其中首先涉及到一个概念——MMSI。
MMSI(Maritime Mobile Service Identity)是海事移动服务识别码,是一个由九位数字组成的唯一识别码,用来识别船舶无线电通讯设备。这个识别码全球唯一,类似于人们手机的电话号码,用于自动识别系统(AIS)和其他船舶无线电通信系统中。MMSI号码被广泛用于海上交通安全和监管,使得船舶、海岸站、救援团队和其他相关的海事服务机构能够相互通信、识别和交换信息。通过MMSI,可以迅速而准确地识别特定船舶,这对于海上搜救、航行安全和船舶追踪等活动至关重要。

又学到了!
讨论与结论

引言

- 总结一下:数据预处理对数据点的经纬度和速度等因素进行异常条件判断,重构时同样对于位置和速度做了考虑(最后用的就是Pi.time和Pj.time之差 Δt 作为重构依据)。
- 后文讨论未来两个研究方向之一的数据预处理部分,说可以考虑天气因素和其他船只的导航信息,也是很好的出发点。
文献综述
英文表述
probabilistic trajectory prediction model:概率轨迹预测模型;decompose:分解;perform anomaly detection 实现异常值检测;
内容概要
简单来说,文献综述给出的结论为:
- 基于特征的降噪实现简单,但是面对复杂的外部数据时效能不佳,所以更适用于数据预处理阶段。
- 基于聚类的降噪对于小而复杂的数据表现不佳。
- 结合深度学习的轨迹研究方法更受欢迎,但是实现起来方法困难,对硬件的要求也很大。
方法论
最难的部分也是我建议最后看的部分,首先是整篇文章的脉络:

简单概述

Density-Based Spatial Clustering of Applications with Noise (DBSCAN)是常见的空间密度聚类的方法,需要两个参数。一个是MinPts当作密度判别的阈值,一个是半径为Eps的圆形区域。
这样有点小复杂,可以结合深度卷积核将这个圆形区域简化,提取其最重要的部分形成3*3的深度方形卷积核,这个卷积核不必作为参数出现。这样,只要能将数据预处理后的数据网格化形成密度矩阵DM1,然后通过使用动态高斯核函数形成新的矩阵DM2,对DM2的数据进行重构即可。整个算法的伪代码如下:

step3中作者写错了,我找出来了!
手动实现DBSCAN示例
如果不是真的不会,我也想高DBSCANDKC,但是使用动态高斯卷积核难度较大,使用固定的高斯卷积效果像依托答辩,所以我展示效果最好的DBSCAN流程,完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from scipy.interpolate import CubicSpline# 设置随机种子
np.random.seed(0)# 生成正常数据(模拟船舶轨迹)
n_normal_points = 100
normal_longitudes = np.linspace(0, 10, n_normal_points) + np.random.normal(0, 0.1, n_normal_points)
normal_latitudes = np.sin(normal_longitudes) + np.random.normal(0, 0.1, n_normal_points)
normal_timestamps = np.linspace(0, 100, n_normal_points)# 生成异常数据(模拟噪声或错误数据)
n_noise_points = 20
noise_longitudes = np.random.uniform(-5, 15, n_noise_points)
noise_latitudes = np.random.uniform(-3, 3, n_noise_points)
noise_timestamps = np.random.uniform(0, 100, n_noise_points)# 合并数据
longitudes = np.concatenate([normal_longitudes, noise_longitudes])
latitudes = np.concatenate([normal_latitudes, noise_latitudes])
timestamps = np.concatenate([normal_timestamps, noise_timestamps])# 绘制初始数据
plt.figure(figsize=(10, 6))
plt.scatter(longitudes, latitudes, c='blue', label='Original Data')
plt.title('Original Simulated AIS Data')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.xlim(-5, 15) # 设置横坐标范围
plt.ylim(-3, 3) # 设置纵坐标范围
plt.legend()
plt.show()# 运动学特征筛选(假设异常数据具有不合理的速度或位置)
speed_threshold = 10 # 假设的速度阈值
lat_range = (-3, 3) # 合理的纬度范围
lon_range = (-5, 15) # 合理的经度范围# 速度计算(简化版本,假设每个数据点时间间隔相同)
speeds = np.sqrt(np.diff(longitudes, prepend=longitudes[0])**2 + np.diff(latitudes, prepend=latitudes[0])**2)# 筛选条件
filter_mask = (speeds < speed_threshold) & (latitudes >= lat_range[0]) & (latitudes <= lat_range[1]) & (longitudes >= lon_range[0]) & (longitudes <= lon_range[1])# 应用筛选
filtered_longitudes = longitudes[filter_mask]
filtered_latitudes = latitudes[filter_mask]
filtered_timestamps = timestamps[filter_mask]# 绘制筛选后的数据
plt.figure(figsize=(10, 6))
plt.scatter(filtered_longitudes, filtered_latitudes, c='green', label='Filtered Data')
plt.title('Data after Kinematic Filtering')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.xlim(-5, 15) # 设置横坐标范围
plt.ylim(-3, 3) # 设置纵坐标范围
plt.legend()
plt.show()# DBSCAN去噪
epsilon = 0.3 # DBSCAN的半径参数
min_samples = 3 # DBSCAN的最小样本数参数(MinPts)
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples)
clusters = dbscan.fit_predict(np.column_stack((filtered_longitudes, filtered_latitudes)))# 去除噪声点
denoised_longitudes = filtered_longitudes[clusters != -1]
denoised_latitudes = filtered_latitudes[clusters != -1]
denoised_timestamps = filtered_timestamps[clusters != -1]# 绘制去噪后的数据
plt.figure(figsize=(10, 6))
plt.scatter(denoised_longitudes, denoised_latitudes, c='red', label='Denoised Data')
plt.title('Data after DBSCAN Denoising')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.xlim(-5, 15) # 设置横坐标范围
plt.ylim(-3, 3) # 设置纵坐标范围
plt.legend()
plt.show()# 分段三次样条插值
spline_lon = CubicSpline(denoised_timestamps, denoised_longitudes)
spline_lat = CubicSpline(denoised_timestamps, denoised_latitudes)# 插值点
interp_timestamps = np.linspace(denoised_timestamps[0], denoised_timestamps[-1], 500)
interp_longitudes = spline_lon(interp_timestamps)
interp_latitudes = spline_lat(interp_timestamps)# 绘制重构的轨迹和新增的插值点
plt.figure(figsize=(10, 6))
plt.plot(interp_longitudes, interp_latitudes, c='gray', label='Reconstructed Trajectory') # 更浅的连线颜色
plt.scatter(denoised_longitudes, denoised_latitudes, c='red', marker='x', label='Denoised Data Points')
plt.scatter(interp_longitudes, interp_latitudes, c='green', s=10, alpha=0.6, label='Interpolation Points') # 更醒目的插值点颜色
plt.title('Reconstructed Trajectory with Cubic Spline Interpolation')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.xlim(-5, 15) # 设置横坐标范围
plt.ylim(-3, 3) # 设置纵坐标范围
plt.legend()
plt.show()# 绘制重构的轨迹和新增的插值点
plt.figure(figsize=(10, 6))
plt.plot(interp_longitudes, interp_latitudes, c='gray', label='Reconstructed Trajectory') # 更浅的连线颜色
plt.scatter(denoised_longitudes, denoised_latitudes, c='red', marker='x', label='Denoised Data Points')
plt.scatter(interp_longitudes, interp_latitudes, c='green', s=10, alpha=0.6, label='Interpolation Points') # 更醒目的插值点颜色
plt.title('Reconstructed Trajectory with Cubic Spline Interpolation')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.ylim(-1.7, 1.7) # 设置纵坐标范围
plt.legend()
plt.show()
结果图如下:




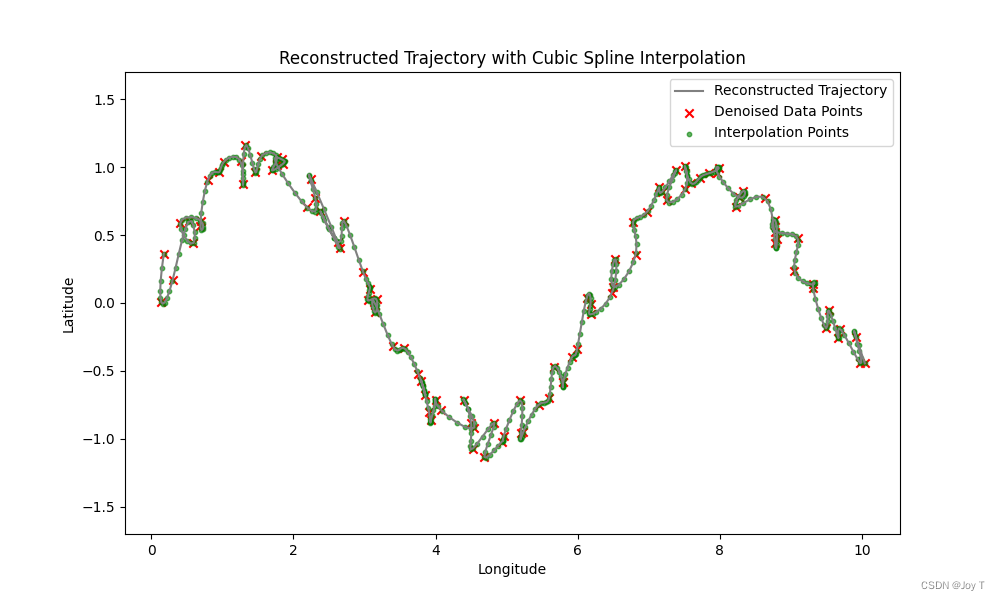
收获好多鸭!