1.什么是元数据
元数据(Metadata),描述数据的数据(data about data)。
1.1 HDFS元数据
元数据:关于文件或目录的描述信息,如文件所在路径、文件名称、文件类型等等,这些信息称为文件的元数据metadata
命名空间:文件系统中,为了便于管理存储介质上的,给每个目录、目录中的文件、子目录都起了名字,这样形成的层级结构,称之为命名空间;
HDFS元数据:文件目录树、所有的文件(目录)名称、文件属性(生成时间、副本、权限)、每个文件的块列表、每个block块所在的datanode列表;
1.2 元数据存在形式
Edits Log
HDFS编辑日志文件,保存客户端对HDFS的所有更改记录,如增、删、重命名文件(目录),这些操作会修改HDFS目录树;NameNode会在编辑日志edit日志中记录下来;类似mysql的binlog。一旦系统出故障,可从editlog进行恢复。
Fsimage
fsimage:HDFS元数据镜像文件,即将namenode内存中的数据落入磁盘生成的文件;保存了文件系统目录树信息以及文件、块、datanode的映射关系。
以上都是扫盲,具体数据实际长什么样的呢?
2.实体存在形式
NameNode的存放地址: hdfs-site.xml
<property><name>dfs.namenode.name.dir</name><value>file:///dfs/nn</value>
</property>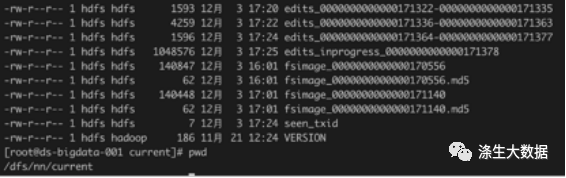
JournalNode: hdfs-site.xml。HA模式下,进行元数据的共享存储。
<property><name>dfs.journalnode.edits.dir</name><value>/hadoop/hdfs/journal</value>
</property>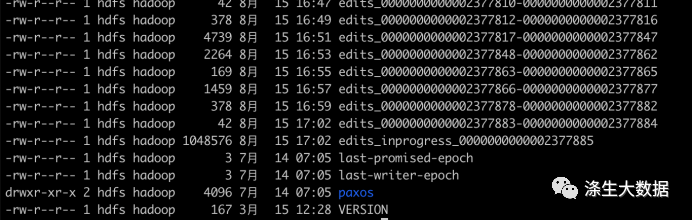
DataNode是HDFS的实际存储节点,负责管理它所在节点的存储;客户端的读写请求。并且定期上报心跳和块的存储位置。
3.元数据生成方式
既然知道存在哪里了,知其燃,还要知其所以燃。接下来,我们从拾材开始:这些数据的生产条件是啥?
1.时间:dfs.namenode.checkpoint.preiod 距离上次的间隔时间:默认3600s,1小时;
2.空间:dfs.namenode.checkpoint.txns edits中的事务限制:默认1000000;
3.人为:使用命令进行保存(集群维护时候操作,防止掉数据);
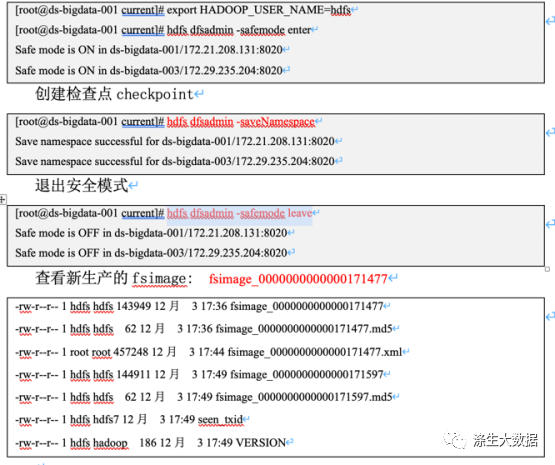
# 1.输入文件
hdfs dfs -put /var/log/messages /tmp/# 2.开启安全模式
hdfs dfsadmin -safemode enter# 3.创建checkpoint
hdfs dfsadmin -saveNamespace# 4.退出安全模式
hdfs dfsadmin -safemode leave操作记录如下:
4.元数据内容剖析
4.1 Fsimage查看
hdfs oiv -i /dfs/nn/current/fsimage_0000000000000171597 -o /dfs/nn/current/fsimage_0000000000000171597.xml -p XML
数据案例
<inode><id>56086</id><type>FILE</type><name>messages</name><replication>3</replication><mtime>1638524892939</mtime><atime>1638524892773</atime><preferredBlockSize>134217728</preferredBlockSize><permission>hdfs:supergroup:0644</permission><blocks><block>
<id>1073758952</id>
<genstamp>18128</genstamp>
<numBytes>239785</numBytes></block></blocks>
<storagePolicyId>0</storagePolicyId>
</inode>目录解释
Path 目录路径
• Replication 备份数
• ModificationTime 最后修改时间
• AccessTime 最后访问时间
• PreferredBlockSize首选块大小 byte
• BlocksCount 块 数
• FileSize 文件大小 byte
• NSQUOTA 名称配额 限制指定目录下允许的文件和目录的数量。
• DSQUOTA 空间配额 限制该目录下允许的字节数
• Permission权限
• UserName 用户
• GroupName 用户组从这里来看,这是我们刚才上传文件message的记录。页面上看到的记录页面如下:

4.2 Edits文件
查询命令格式
hdfs oev -i /dfs/nn/current/edits_0000000000000230755-0000000000000230770 -o edits.xml -p XML
数据案例:随便一个记录
<RECORD><OPCODE>OP_ADD</OPCODE><DATA>
<TXID>230762</TXID>
<LENGTH>0</LENGTH>
<INODEID>69782</INODEID>
<PATH>/tmp/.cloudera_health_monitoring_canary_files/.canary_file_2021_12_07-22_59_58.179c3216fc1fddcf</PATH>
<REPLICATION>3</REPLICATION>
<MTIME>1638889198054</MTIME>
<ATIME>1638889198054</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-580922430_1500</CLIENT_NAME>
<CLIENT_MACHINE>172.21.208.131</CLIENT_MACHINE>
<OVERWRITE>true</OVERWRITE>
<PERMISSION_STATUS><USERNAME>hdfs</USERNAME><GROUPNAME>supergroup</GROUPNAME><MODE>438</MODE>
</PERMISSION_STATUS>
<ERASURE_CODING_POLICY_ID>0</ERASURE_CODING_POLICY_ID>
<RPC_CLIENTID>c56340fe-a1fd-44aa-a726-8e407b9c8f90</RPC_CLIENTID>
<RPC_CALLID>211691</RPC_CALLID></DATA></RECORD>4.3 blockreport
除了NameNode存储的元数据意外,DataNode也有干活,专业词汇叫:blockreport
全量块汇报(Full Block Report,简称FBR)
全量块汇报,顾名思义,就是将DN中存储的所有block信息都汇报给NN。
通常,DN中都存储一定数量级的block,全量汇报时,耗时会相对更长,发送的数据也会更多。因此,全量块汇报的时间间隔相对也会更长,间隔时间可配置,默认间隔为6小时。
增量块汇报(Incremental Block Report,简称IBR)
由于全量块汇报的时间间隔很长,那么在这期间的block信息变更要通知到NN,这就是增量块汇报的逻辑了。
当block块的状态发送变更时,DN就会触发发送增量块汇报信息给NN。增量块汇报的时间间隔也是可以配置的,默认间隔为0。即一旦触发增量块汇报,就立即发送。如果大于0,则按间隔时间发送增量块汇报.
而这个数据,可以在NN服务的startup页面可以查看到信息。最下面的Blocks(141470/141471) 就是DataNode的blockreport信息,就是用来更新元数据信息的。

以上就是HDFS相关的元数据相关的内容,不知看了,有概念了吗?看懂了,就可以加入元宇宙了。
5.元数据异常处理案例
元数据很重要,他的离去,往往会同步带走几个倒霉蛋(被迫离职的背锅侠),虽然搞了很多的保障策略,但是异常还是有概率发生的。那么接下来,我们就来说明下一些常见的元数据异常处理。
5.1 元数据版本不一致
异常表现
这种异常,往往出现在集群安装阶段,特别是高可用集群的安装阶段。主要表现为:
1.两给NN服务节点的元数据不一致,导致无法实现主备搭建。2.NN服务与DN服务版本不一致,导致DN节点无法加入到集群。
原因
这种异常现象表现有:NN服务无法启动、DN服务启动了,但是加入不到集群。
报错日志
23/08/28 05:50:20 WARN namenode.NameNode: Registration IDs mismatched: the DatanodeRegistration ID is NS-145281851-CID-d4fe6b45-8766-441e-8e98-ba09164c211c-1685956713522 but the expected ID is NS-1072740375-CID-abd29939-1b50-4cc1-9585-6964de90a91b-1678793793759
23/08/28 05:50:20 INFO ipc.Server: IPC Server handler 0 on default port 8020, call Call#1053 Retry#0 org.apache.hadoop.hdfs.server.protocol.DatanodeProtocol.sendHeartbeat from 192.168.131.230:52548
org.apache.hadoop.hdfs.protocol.UnregisteredNodeException: Unregistered server: DatanodeRegistration(192.168.131.230:50010, datanodeUuid=14e37d26-4196-433e-8d10-bef402eadd24, infoPort=50075, infoSecurePort=0, ipcPort=8010, storageInfo=lv=-57;cid=CID-d4fe6b45-8766-441e-8e98-ba09164c211c;nsid=145281851;c=1685956713522)at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.verifyRequest(NameNodeRpcServer.java:1744)其中报错关键字:Registration IDs mismatched,注册的ID不匹配。
这种类似的报错信息会出现在DataNode,NameNode,JournalNode服务的启动程序中。遇到这个报错,那么大概可以断定,你的程序的元数据信息出现问题了
异常解析
这种问题一般怎么发生的呢?
经过N年的经验,这种一般都是不按正常部署操作流程导致的。其中,有几个步骤是和元数据相关的。
#1.元数据初始化程序
#该命令,是在集群安装阶段,NN第一个节点初始化集群时候用的。这是元数据数据诞生的地方,会在第一个NameNode节点,dfs.namenode.name.dir配置所在地方。
hdfs namenode -format#2.元数据同步到JournalNode阶段
#该操作的功能,是将步骤1 NN初始化后的元数据信息,同步到所有的JournalNode服务。
hdfs namenode -initializeSharedEdits#3.备份NN节点节点同步
#该操作,是将步骤1中的元数据中的内容,同步到第二个NN节点。
hdfs namenode -bootstrapStandby#4.Data元数据
hadoop-daemon.sh start datanode
hdfs-start.sh
start-all.sh
hdfs datanodeDataNode的元数据生成,或者集群的加入,是在第一次启动服务的时候从NN节点获取的。开启的启动方式有很多种,只要能启动DataNode,都能生成对应的元信息。
元数据版本不一致问题,一般都是上面讨论的几个步骤出了点小小的差异导致的。比如最常见的重复初始化:初始化成功,并同步过元数据,或者启动过DN服务。然后再后续步骤中发现有问题,又重新初始化了集群。这样就会出现以上的报错。具体是哪个服务报错呢?就得看你上面的步骤都做了那些。
异常处理
既然都知道了异常的产生步骤和原理,那么处理起来就方便多了。
1.大招
不管啥,直接删除集群所有的信息,然后直接“梭哈”重新来一次。删除的信息包括:
| 删除内容 | 配置项 | 案例 |
| 主NN节点元数据信息 | dfs.namenode.name.dir | /hadoop/hdfs/namenode |
| 备NN节点元数据信息 | 同上(不同机器) | 同上(不同机器) |
| JournalNode元数据信息 | dfs.journalnode.edits.dir | /hadoop/hdfs/journal |
| DataNode数据 | dfs.datanode.data.dir | /hadoop/hdfs/data |
特别说明,该操作会清空所有hdfs数据,一般用于安装阶段出问题,如果你的集群已经有数据了,那么该方法就不能用了,不然,你就是前辈(背锅侠,最好的结果就是赔偿N+1)。
2.备节点或JournalNode元数据不一致
如果集群有数据了,不能删数据啥的。那么现在正在使用的元数据信息,是保存在主节点(Activate NameNode)服务,遇到这种情况,就删除JournalNode和备节点的NN服务,然后使用Data元数据的步骤再执行同步操作。
3.DataNode元数据不一致
这种情况,应该是你的节点加错集群了。首先确认下这台主机是你操作集群的主机吗(一个公司可能多有个集群)。如果是确认没问题的,那么就备份(删除)现在的DataNode目录数据,然后重新启动服务即可。
5.2 元数据文件错误
异常表现
此处特指的错误,是特指文件的损坏,某个元数据(fsimage,edits_inprogress,edits)文件损坏。
原因
这种异常,一般出现在暴力关机(断电、强制关机)情况下,导致元数据写入不完整。导致下次启动的时候,无法加载文件。
报错日志
23/08/28 23:07:15 ERROR namenode.FSImage: Failed to load image from FSImageFile(file=/hadoop/hdfs/namenode/current/fsimage_0000000000000118333, cpktTxId=0000000000000118333)
java.io.IOException: Negative seek offsetat java.io.RandomAccessFile.seek(RandomAccessFile.java:555)at org.apache.hadoop.hdfs.server.namenode.FSImageUtil.loadSummary(FSImageUtil.java:63)这类报错特别明显,会直接告诉你那个文件有问题。
异常处理
既然知道问题了,原因也知道了,那么处理起来就好办了,不是有问题吗?那么我们就去下载没问题的啊。下载的地方有:运行中的NameNode; JournalNode节点;
建议,优先下载NN节点的内容,因为是最新的,最全的。这样不会掉数据。其次才是JournalNode的。
如果发现拷贝了其他节点的元数据过来但是依旧不能启用,那麻烦就到了,大概率不好修了。
5.3 元数据内容错误
异常表现
在10年+的职业生涯中,这种报错只遇到一个,他属于元数据的内容错误,严格得来说,是元数据是正确的,但是,他执行不了。听起来有点绕,咋们来屡屡。
原因
情况是这样的,这个集群因为历史遗留原因,几乎是放养状态,然后NameNode Standby节点挂了很久很久…
那么问题就来了,没地方做edits日志的合并了,里面超级多的fsimage文件…此处知识点,请自行百度《HDFS 元数据合并流程》。
然后fsimage过多,在NN服务再次启动的时候,那些都得需要执行一次的啊,然后发现,有些操作直接报错了无法执行下去。
具体的操作是OP_CLOSE执行失败,并提升对应的删除目录。到具体的HDFS上去看,发现是一个TMP目录,早就删除了,连父目录都不知删了多久了。
报错日志
情况是这样的,这个集群因为历史遗留原因,几乎是放养状态,然后NameNode Standby节点挂了很久很久…
那么问题就来了,没地方做edits日志的合并了,里面超级多的fsimage文件…此处知识点,请自行百度《HDFS 元数据合并流程》。
然后fsimage过多,在NN服务再次启动的时候,那些都得需要执行一次的啊,然后发现,有些操作直接报错了无法执行下去。
具体的操作是OP_CLOSE执行失败,并提升对应的删除目录。到具体的HDFS上去看,发现是一个TMP目录,早就删除了,连父目录都不知删了多久了。
异常解析
大概的日志报错信息如下,就是加载image的时候直接error,提示某个操作执行失败:
23/08/28 23:55:05 ERROR org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader: Encountered exception on operation CloseOp [length=0, inodeId=0, path=/x/x/x/x, replication=3,
mtime=1693288028609, atime=1693288028005, blockSize=268435456, blocks=[blk_1167720789_98154524], permissions=x:x:rw-r-----, aclEntries=null, clientName=, clientMachine=, opCode=OP_CLOSE, txid=1097889118]
java.io.IOException: File is not under construction: /x/x/x/x其中包含具体的关键词:OP_CLOSE
异常处理
这种问题是OP_CLOSE操作时候,需要验证执行的可行性,需要处于under construction的状态,但是现在的集群状态已经不满足此情况,对此,需要将这些操作做下小小的修改。将OP_CLOSE操作修改OP_TIMES操作。
修改前案例(此处,已经将具体数据进行了脱敏,修改为xxx)
<RECORD><OPCODE>OP_CLOSE</OPCODE><DATA><TXID>1097889118</TXID><LENGTH>0</LENGTH><INODEID>0</INODEID><PATH>/xxx/xxx/xxx/xxx</PATH><REPLICATION>3</REPLICATION><MTIME>1693288028609</MTIME><ATIME>1693288028005</ATIME><BLOCKSIZE>134217728</BLOCKSIZE><CLIENT_NAME></CLIENT_NAME><CLIENT_MACHINE></CLIENT_MACHINE><OVERWRITE>false</OVERWRITE><BLOCK><BLOCK_ID>1212673348</BLOCK_ID><NUM_BYTES>7290666</NUM_BYTES><GENSTAMP>138932875</GENSTAMP></BLOCK><PERMISSION_STATUS><USERNAME>xxxx</USERNAME><GROUPNAME>xxxx</GROUPNAME><MODE>420</MODE></PERMISSION_STATUS></DATA></RECORD>替换后的内容为
<RECORD><OPCODE>OP_TIMES</OPCODE><DATA><TXID>1097889118</TXID><LENGTH>0</LENGTH><PATH>/xxx/xxx/xxx/xxx</PATH><MTIME>1693288028609</MTIME><ATIME>-1</ATIME></DATA></RECORD>整体的步骤如下
1. 使用hdfs oev 将edits日志解析为xml格式;
2. 使用shell 或者其他程序,将xml中的关于OP_CLOSE的操作整段替换为OP_TIMES操作。此处,可以使用shell按关键词 进行分块拆分和替换。
3. 将修改后的xml,重新恢复成edits日志后,再启动服务。
以上,就是笔者关于元数据的一些相关实践,感谢各位大佬的查看。
Hadoop实践指南:揭秘HDFS元数据并解析案例