文章目录
- 摘要
- 关键字
- 结论
- 研究背景
- 1. Introduction
- 常用基础理论知识
- 2. The quadratic assignment problem
- 3. Taboo search
- 3.1. Moves
- 3.2 Taboo list
- 3.3. Aspiration function
- 3.4. Taboo list size
- 4. Random problems
- 5. Parallel taboo search
- 研究内容、成果
- 7. Conclusion
- 潜在研究点
- 文献链接
摘要
目的:为了提高禁忌搜索的速度,提出了两种并行化方法,并显示了它们对于与问题规模成正比的处理器数量的效率。还提出了一种生成随机问题的简单方法
优势:更少的复杂性和更少的参数。
关键字
组合优化;禁忌搜索;并行算法;二次分配问题;效率
结论
研究背景
1. Introduction
二次分配问题 (QAP) 非常困难,以至于 Steinberg在 1961 年提出的尺寸为 36 的实例尚未得到解决。
本文的目标是为 QAP 提出一种更稳健的 TS 形式,它具有最少的参数数量,并且非常容易实现,能够获得与先前找到的最佳解决方案相当的解决方案,而无需多次传递和更改参数值。
常用基础理论知识
2. The quadratic assignment problem
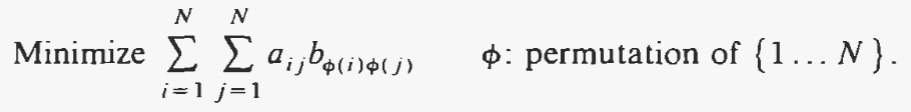
可以自然地用 QAP 表达的问题的示例包括:
- 芯片中逻辑模块的放置,使得连接的总长度最小化;
- 在大型医院中心分配医疗服务。
3. Taboo search
TS的主要思想可以简单概括如下。第一个要素是定义一个邻域,或者一组可以应用于给定解决方案以产生新解决方案的移动。在所有邻近的解决方案中,TS 寻求一个具有最佳启发式评估的解决方案。在最简单的情况下,这样的评估决定了最能改善目标函数的移动的选择。如果没有改进的移动(表明一种局部最优),TS 选择一个对目标函数降级最少的移动。为了避免回到刚刚访问的局部最优,现在必须禁止反向移动。这是通过将这一举动(或更准确地说是该举动的特征)存储在通常像循环列表一样管理并称为禁忌列表的数据结构中来完成的。该列表包含许多定义禁止(禁忌)动作的元素;参数s称为禁忌列表大小。然而,禁忌清单可能会禁止某些相关或有趣的举措,例如那些导致比迄今为止发现的最佳解决方案更好的解决方案的举措。因此,引入了一个愿望标准,如果禁忌动作被认为是有趣的,则允许选择禁忌动作。 TS 的完整版本包含附加元素,但我们将展示如何单独使用这些基本概念来构建 QAP 的有效实现。
3.1. Moves
非常适合此问题的自然移动类型包括交换两个单元,以便每个单元占据另一个单元先前占据的位置。从放置 开始,通过排列单元 r 和 s 获得相邻放置 7r:

如果矩阵是对称的并且具有零对角线(就像“经典”示例的情况一样),则移动的值,写作:

如果矩阵不对称和/或没有零对角线,则表达式(仍可在 O(N) 中计算)会稍微复杂一些。 [3]。
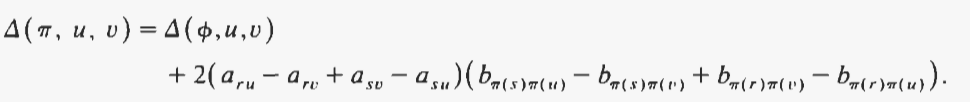
对动作质量的快速评估是提高搜索效率的重要因素。该评估可能与 Fiechter [7] 的旅行推销员应用程序或 Taillard [19] 的流水车间排序中一样精确,或者与 Taillard [20] 的作业车间调度中一样近似。此外,这些动作必须具有与所考虑的问题相关的良好特性。对于 QAP 来说,采用将单元 r 插入到排列 q) 中与单元 s 相邻的移动是不合适的,因为这会改变排列中 r 和 s 之间每个单元的位置 - 一场真正的灾难!
3.2 Taboo list
我们现在必须定义禁忌列表元素的类型。 Skorin-Kapov [16] 提出禁止交换在前 s 次迭代期间交换过的两个单元。形式上,禁忌列表由不能交换的单元对 (i, j) 组成。列表的禁止可以用整数的二维数组来实现,其中元素(i,j)标识未来迭代的值,在未来迭代中这两个单元可以再次彼此交换。这样一来,检验一个动作是否禁忌,只需要一次比较即可。在恒定时间内评估禁忌条件非常重要,以便在与其大小成比例的时间内评估邻域,从而避免搜索复杂性的增长。
在他的文凭项目中,Rogger 尝试了多种类型的禁忌列表,我们选择了如果列表的大小 s 改变则证明最方便的一种,因为我们采用了以下规则:改变此参数的值(Glover [11] 描述了一般设置中此类列表的优点)。具体来说,我们的禁忌列表构建如下:对于每个单位和位置,记录该单位占据该位置的最新迭代。如果移动将两个互换的单位分配到它们在最近迭代中占据的位置,则该移动是禁忌。这种类型的列表提供的结果与在给定“最佳”大小时使用 Skorin-Kapov 提出的类型获得的结果相当,但对参数 s 不太敏感。
3.3. Aspiration function
对于每个问题,我们都使用经典的愿望函数,如果它导致的解决方案比迄今为止找到的最佳解决方案更好,则允许选择禁忌举措。然而,对于某些问题的最著名的解决方案并不总是能够通过这种最小的实现来获得,即仅使用一种类型的移动、一个禁忌列表和微不足道的愿望功能。仔细检查实现表现较差的问题(特别是 Elshafei [6] 提出的问题),揭示了概念上的错误:这些问题有一个非常特殊的流矩阵,其中包含大量空值或非常小的值和一些非常小的值。高流量。如果搜索在某个时刻未能在局部最优处找到高流量的单元,那么 TS 将以较小的成本执行移动,因为关键单元的第一次交换将大大增加目标函数的值。
我们提出的克服这一困难的技巧非常简单:对于流量或成本非常异构的问题,如果交易所将两个单元放置在不同位置,则移动将通过愿望标准并被选择,解决方案质量完全是从属衡量标准它们在最后 t 次迭代中没有占用。从概念上讲,该函数可以被视为一个长期的多元化过程,每当某些单位成功满足标准时,该函数就会被激活以禁止无法满足其条件的移动。
3.4. Taboo list size
禁忌清单大小的选择至关重要;如果它的值太小,搜索过程中可能会发生循环,而如果它的值太大,有吸引力的移动可能会被禁止,导致探索较低质量的解决方案,产生大量的迭代来找到所需的解决方案。
然而,认为循环现象总是作为小禁忌列表大小的函数出现的想法是错误的,因为我们观察到,对于 Nugent 等人的大小 15 的问题。 [13],禁忌列表大小设置为 s = 30 的循环,对于 26 到 29 之间的大小没有观察到这种循环。为了克服与搜索最佳禁忌列表大小相关的问题,我们提出以下技巧:我们建议在搜索过程中随机更改该值,而不是在整个搜索过程中将大小 s 固定为恒定值。实际上,s 将在 Smin 和 Smax = Smin + A 之间选择,并且经常更改,例如每 2’Smax x 迭代(以便有一定的概率以 s = Smax 执行某些迭代)。
在图 1 中,我们感兴趣的是必须赋予 Smin 的实用值和 A 来解决(最优)N = 15 的 Nugent 问题。当我们从独立的初始解开始并使用少于 10000 次迭代成功找到最优解 30 次时,我们在图中用黑色方块绘制。必须注意的是,当 Smin 和 A 设置为“最佳”值时,允许的迭代次数大约是解决该问题所需的平均迭代次数的 20 倍。
在图 1 中,我们首先注意到随机禁忌列表大小 (A > 0) 的引入使得搜索更加可靠。其次,Smin 和 A 的实际取值范围非常广泛。

事实上,对于大多数问题,我们使用 Smin = [0.9 N] 和 Smax = [1.1 N] 找到了迄今为止已知的最佳解决方案。然而,对于小问题(N <= 15)和非正则矩阵问题(Elshafei,Steinberg)或大问题(Skorin-Kapov,Krarup),使用稍大的禁忌列表大小有时可以更快地找到这些解决方案,其中使用第二个愿望功能时,禁忌列表的大小必须减少,大约30%。第二个愿望函数的参数 t 很大程度上取决于问题。对于最不规则的问题(Elshafei),t 设置为 400,对于较大的问题,它设置为 3000 到 10000 之间。
在图 2 中,我们感兴趣的是寻找次优解决方案的平均迭代次数,这是斯坦伯格问题的第一个实例。因此,我们尝试“解决”这个问题 30 次,从独立的初始解决方案开始,最多允许 500000 次迭代。这是针对 3 个 A 值(0、5 和 10)和 7 个 Smin 值(0、5 … 30)完成的。
当禁忌列表大小固定(A = 0)时,充分选择它很重要:对于我们的示例,我们观察到大小小于 10 的循环,而最佳大小约为 20,并且平均迭代次数增加对于大小为 30 的情况,大约为 50%。但是随机性的引入(A = 5 或 A = 10)使得能够以更可靠的方式找到搜索的解(Smin 的良好值的间隔更大)并且与固定大小相比,需要更少的迭代次数 (- 30%)。
4. Random problems
文献中发表的问题有一个主要缺点:复制和使用数据可能很困难,因为矩阵记录在大量表格中,有时以不可读的方式打印。因此,我们提出了一种自动生成问题的简单方法;这些问题通常比已发布的问题更难解决(使用我们的 TS),因为可以常规验证次优解决方案的最大问题的大小为 35 到 40,而我们很可能已经最优地解决了 Steinberg 的问题( N = 36)和斯科林卡波夫(N = 42 至 N = 64)。在我们的生成过程中,距离和流量矩阵的系数是整数,在0到99(包含)之间随机均匀生成。随机数生成器,在 Bratley 等人的书中进行了分析。 [1],基于递归公式:
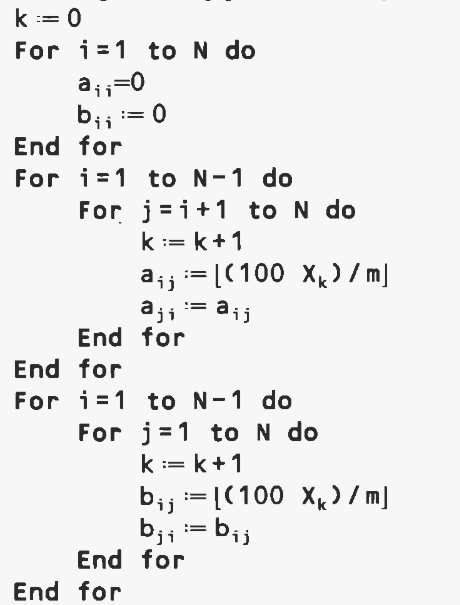
5. Parallel taboo search
研究内容、成果
7. Conclusion
我们在本文中表明,使用基于 TS 的过程并先验地固定其参数,可以找到非常好的 QAP 解决方案。特别是,如果允许 N2 迭代并且禁忌列表大小在问题大小的 10% 范围内随机变化,则有可能获得高质量的解决方案,这更多地取决于问题的类型而不是问题的大小,对于 N >= 20。
我们的 TS 的实现除了简单之外,还将 QAP 的早期 TS 实现的计算复杂度降低了 N 倍,并且通过以下方式可以将复杂度再次降低 N 倍:使用与 N 成比例的处理器数量。结果表明,使用基本 TS(一个禁忌列表和琐碎的愿望函数)对于大多数大小不超过 30 的问题效果很好。对于更大的问题,使用另一个提出了愿望函数 - 添加一个新参数,但不改变算法的复杂性(工作和内存要求) - 并且一些大小高达 64 的问题可能无法得到最佳解决。然而,我们认为寻找更大问题的次优解决方案必须通过另一个过程来完成,例如使用更复杂的 TS 概念(目标分析或更复杂的长期记忆)。最后,给出了一种生成随机问题的可靠方法,这大大减少了获取随机问题实例所需的工作。