注意力机制彻底改变了自然语言处理和深度学习领域。它们允许模型在执行机器翻译、语言生成等任务时专注于输入数据的相关部分。
在这篇博客[1]中,我们将深入研究被称为“Flash Attention”的注意力机制的突破性进展。我们将探讨它是什么、它是如何工作的,以及为什么它在人工智能社区中引起了如此多的关注。
在我们深入了解 Flash Attention 的细节之前,让我们快速回顾一下注意力机制的基础知识及其在机器学习中的重要性。
注意力机制
注意力机制使模型能够以不同的方式权衡输入数据的不同部分,在执行任务时关注最相关的信息。
这模仿了人类选择性地关注周围环境的某些方面,同时过滤掉干扰的能力。注意力机制在提高各种人工智能模型的性能方面发挥了重要作用,特别是在序列到序列任务中。
Flash Attention 的诞生
Flash Attention,顾名思义,为注意力机制带来了闪电般快速且高效内存的解决方案。它解决了传统注意力机制中存在的一些低效率问题,使它们更适合大规模任务和复杂模型。
但 Flash Attention 到底是什么?为什么它会在 AI 社区中引起如此大的轰动?让我们来分解一下 Flash Attention 的关键方面及其核心组件。
Flash Attention的核心组件
-
快:Flash Attention 的速度是其突出特点之一。根据该论文,它可以加快 BERT-large 等模型的训练速度,超越之前的速度记录。
例如,与基线实施相比,GPT2 训练的速度提高了三倍。这种速度提升是在不影响准确性的情况下实现的。
-
内存高效:传统的注意力机制(例如普通注意力)存在二次内存复杂度 (O(N²)),其中 N 是序列长度。另一方面,Flash Attention 将内存复杂度降低到线性 (O(N))。这种优化是通过有效利用硬件内存层次结构并最大限度地减少不必要的数据传输来实现的。 -
准确:Flash Attention 保持与传统注意力机制相同的准确度。它不是注意力的近似值,而是注意力的精确表示,使其成为各种任务的可靠选择。 -
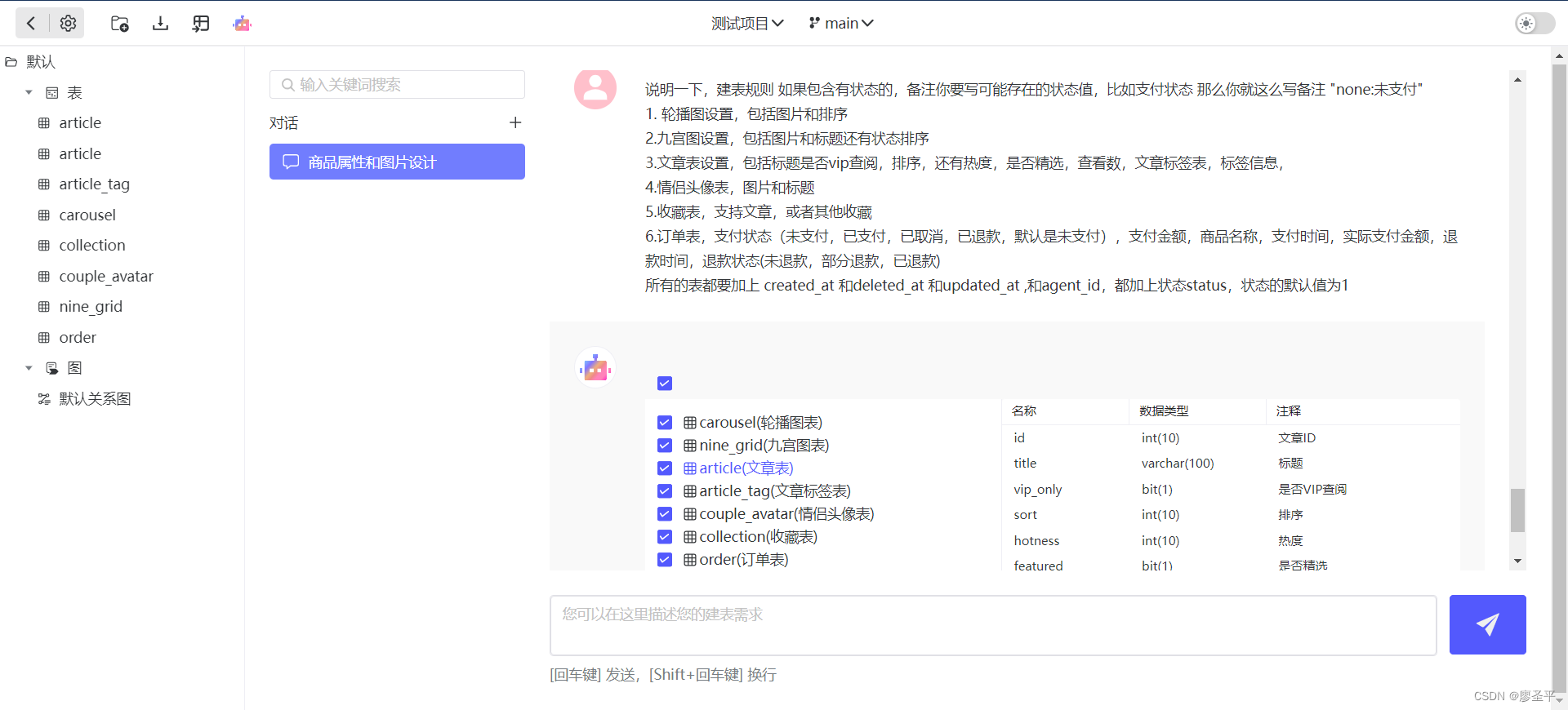
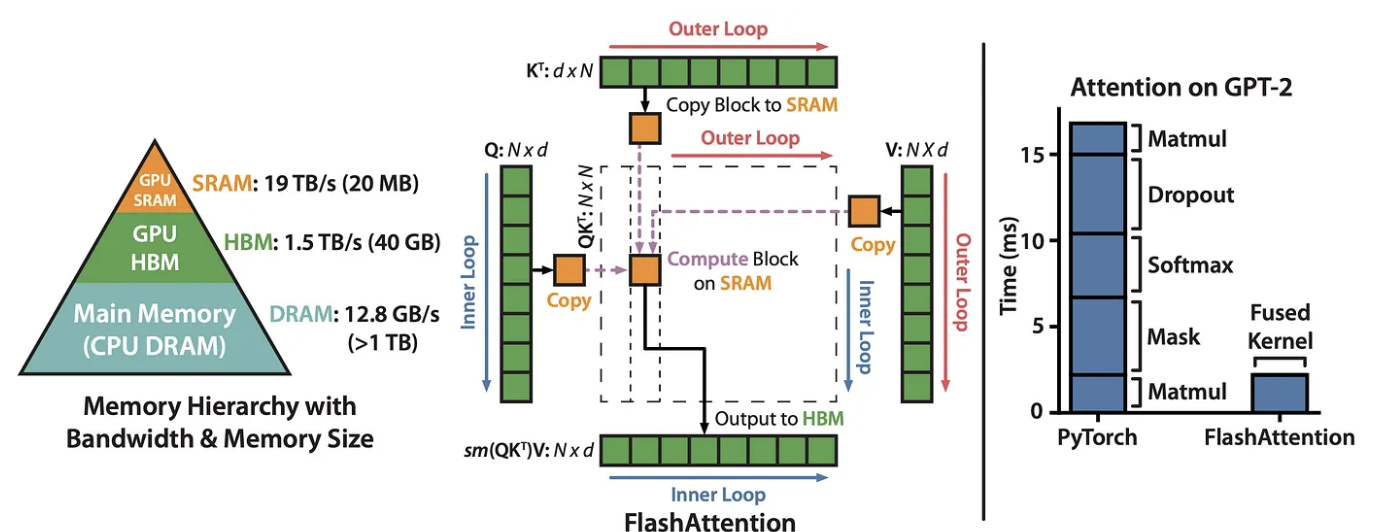
IO 提升:Flash Attention 的“IO 提升”是指它优化现代 GPU 中不同级别内存之间的内存访问和通信的能力。通过考虑内存层次结构并减少通信开销,Flash Attention 充分利用高速内存并最大化计算效率。
揭秘 Flash 注意力
Flash Attention 的有效性在于它对其运行的硬件的理解。它利用了 GPU 中不同类型的内存具有不同容量和速度的事实。例如,SRAM 速度更快但更小,而 HBM(高带宽存储器)更大但速度更慢。通过最大限度地减少这些内存类型之间的通信,Flash Attention 显着加快了计算速度
Flash注意力算法:平铺和重新计算
Flash Attention的算法可以概括为两个主要思想:平铺和重新计算。
平铺:在前向和后向传递过程中,Flash Attention 将注意力矩阵划分为更小的块,从而优化内存使用并提高计算效率。
重新计算:在后向传递中,Flash Attention 使用存储的输出和 softmax 归一化统计数据重新计算注意力矩阵,从而无需过多的内存存储。
挑战
Flash Attention 的空间复杂度与序列长度和注意力头维度呈线性关系。这使得它适合处理大型模型和任务。
然而,实现 Flash Attention 会带来挑战,特别是在编写优化的 CUDA 内核方面。对较低级语言编码的需求可能会阻碍采用,但像 Triton 这样的项目为这个问题提供了潜在的解决方案。
总结
Flash Attention 标志着注意力机制的重大进步,解决了效率问题,并实现了更快、更节省内存的 AI 模型训练。
通过考虑硬件和内存层次结构,Flash Attention 优化了计算,为各种 NLP 和 AI 任务带来了显着的改进。
在这篇博客中,我们只触及了 Flash Attention 的皮毛,但它的潜在影响是不可否认的。随着人工智能研究人员和从业者继续尝试这一突破,我们预计会出现更优化、更高效的注意力机制,从而突破人工智能模型所能实现的界限。
Reference
Source: https://medium.com/@sthanikamsanthosh1994/introduction-to-flash-attention-a-breakthrough-in-efficient-attention-mechanism-3eb47e8962c3
本文由 mdnice 多平台发布


![高级搜索-线段树[C/C++]](https://img-blog.csdnimg.cn/19ff19138926460c91cb9361a5ce7257.png)