初始化Spark Sql
package pbcp_2023.clear_dataimport org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{current_date, current_timestamp}object twe_2 {def main(args: Array[String]): Unit = {
//新建SparkConfval con = new SparkConf().setMaster("local[*]").setAppName("one")//设置权限System.setProperty("HADOOP_USER_NAME", "root")
//新建Spark Sqlval sc = new SparkSession.Builder().config(con).enableHiveSupport().getOrCreate()import sc.implicits._val list = List("date").toDF()}}1.current_date和current_timestamp
current_date:取得当前日期
current_timestamp: 取得当期时间日期
import sc.implicits._val list = List("date").toDF()
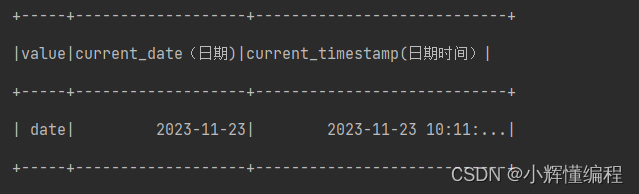
// current_date 当前日期
// current_timestamp 当前时间日期list.withColumn("current_date(日期)",current_date()).withColumn("current_timestamp",current_timestamp())
2.获取各种时间格式
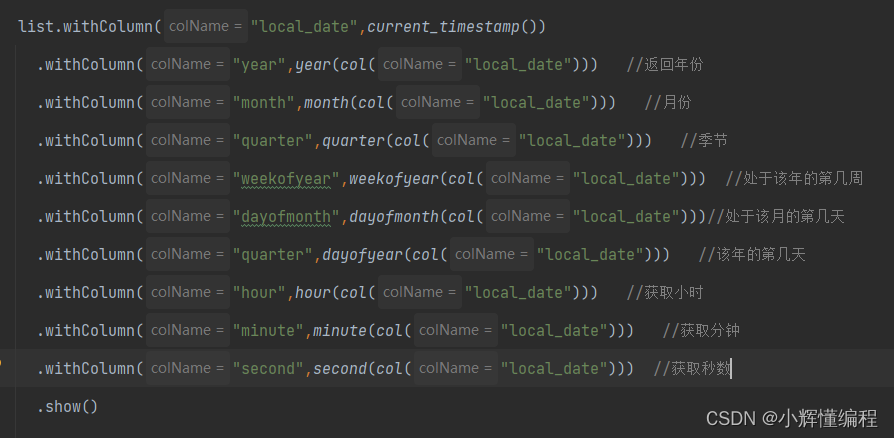
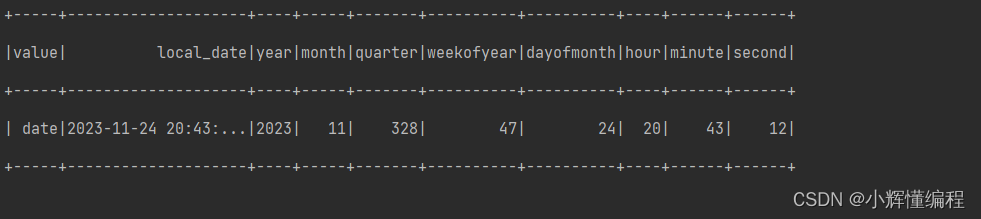
current_timestamp(): 这个函数用于获取当前的日期和时间戳。year(col("local_date")): 这个函数会提取出"local_date"列中的年份。month(col("local_date")): 这个函数会提取出"local_date"列中的月份。quarter(col("local_date")): 这个函数会根据"local_date"列中的日期信息,将日期划分为哪个季度。weekofyear(col("local_date")): 这个函数会提取出"local_date"列中该年度的第几周。dayofmonth(col("local_date")): 这个函数会提取出"local_date"列中该月的第几天。dayofyear(col("local_date")): 这个函数会提取出"local_date"列中该年的第几天。hour(col("local_date")): 这个函数会提取出"local_date"列中的小时数。minute(col("local_date")): 这个函数会提取出"local_date"列中的分钟数。second(col("local_date")): 这个函数会提取出"local_date"列中的秒数。
3.时间格式之间的转换--from_unixtime 和 unix_timestamp
函数:
list2.withColumn("new_date",from_unixtime(unix_timestamp("[要转换的列名]","[要转换的列的格式]"),"[要转换为的格式]").as("date") ).show()
1.from_unixtime :函数通常用于将Unix时间戳转换为日期和时间格式。它接受一个Unix时间戳作为输入,并返回一个表示特定日期和时间的字符串。
2.unix_timestamp:函数通常用于将日期和时间转换为Unix时间戳。它接受一个日期和时间作为输入,并返回一个表示该日期和时间的Unix时间戳。理解是先用unix_timestamp将指点格式转换为时间戳,再用from_unixtime将时间戳转换为你想要的时间格式!所以这两个一般是配合使用的
实例:
//加入题目要求将 yyyyMMdd 格式数据转换成 yyyy-MM-dd HH:mm:ddval list2 = List("20231125").toDF("date") //初始化列list2.withColumn("new_date",from_unixtime(unix_timestamp(col("date"),"yyyyMMdd"),"yyyy-MM-dd HH:mm:ss").as("date") ).show() 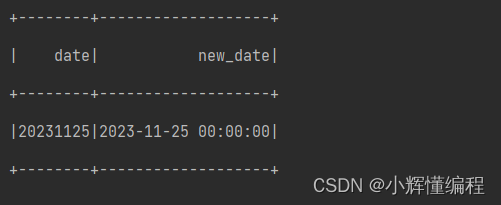


![高级搜索-线段树[C/C++]](https://img-blog.csdnimg.cn/19ff19138926460c91cb9361a5ce7257.png)