本文已收录至《Linux知识与编程》专栏!
作者:ARMCSKGT
演示环境:CentOS 7


文件系统概述
- 前言
- 正文
- 文件与磁盘
- 磁盘介绍与机械硬盘
- 机械硬盘基础结构
- 机械硬盘数据存储与管理
- 文件操作的细节
- 创建文件
- 访问文件
- 删除文件
- 恢复文件
- 其他情况
- 最后
前言
我们知道文件的存储一般在磁盘上,操作系统需要管理这些文件就需要通过其文件系统进行管理,高效的管理机制有利于提高我们IO的速度,本节我们将对Linux系统的文件系统进行概述!

正文
本节理论较多,还请耐心阅读和理解!
文件与磁盘
文件被打开后会加载到内存,而没有被打开的文件存储在磁盘上!
对于磁盘文件的管理,主要为了解决快速定位,快速读取和写入
对于在磁盘上的文件,当我们对文件进行操作时,操作系统会通过文件的inode编号找到文件属性进行文件操作,对于文件的inode编号我们可以通过以下命令查看:ls -il
文件的inode编号就如同进程的pid一样,inode编号与文件一 一对应,通过文件的inode编号就可以访问文件属性进而读取文件内容!
我们可以将磁盘对文件的管理比喻为物品寄存点,每一个柜子有一个箱号,可以存放一个物品,存放成功后物主获得箱号牌;待物主来取时通过箱号牌取出物品并归还箱号牌;这就是文件的一次写入和删除操作!
向磁盘中写入一个文件,存放在磁盘中,获取一个inode编号,在删除这个文件时归还这个inode编号即可!
以上对文件的 “管理” 描述只是抽象概念,结合我们后面介绍的磁盘结构,才能更好的理解!


磁盘介绍与机械硬盘
在现代,磁盘分为两种,即
机械硬盘和固态硬盘!
机械硬盘速度慢,但是便宜稳定;固态硬盘速度快,但是价格比较贵且数据损坏率大于机械硬盘!
为了更好的介绍文件系统,我们主要围绕机械硬盘进行讲解!
机械硬盘基础结构
机械硬盘是我们计算机中的一个外部设备,也是计算机中唯一的机械设备,根据冯诺依曼体系,机械硬盘的速度远远低于CPU。如果要有一个数据去衡量,CPU的运行是纳秒级别的话,机械硬盘则是毫秒级别!
而机械硬盘之所以这么慢,是由其内部结构决定的:
注意:不同磁盘中磁盘的盘片数量不一样,但因为磁头是通过一个磁头臂驱动的,所以一个机械硬盘上的所有磁头是共进退的!机械设备的操作动作需要时间,相当于固态硬盘中电子间的光速传输来说,非常慢!机械硬盘的主要结构:
- 盘片:有两面都可以存储数据,一般是多个盘片组合成一组
- 磁头:盘片的每一面都配有一个磁头读写数据
- 主轴:带动盘片转动进行寻址
- 音圈马达:控制磁头进退换道
- 磁头臂:磁头在磁头臂的一端,通过音圈马达的摆动,控制磁头切换磁道
- 伺服电路板:对数据的读写进行处理,控制机械硬盘的运行
- 其他 … …
关于机械硬盘的详细结构介绍,可阅读:机械硬盘的内部结构
机械硬盘数据存储与管理
在计算机中,数据是以二进制存储的,常见的可以表示二进制的存储方式有:高电平与低电平,波峰和波谷,南极和北极等等;而机械硬盘盘片的存储的方式是磁极南极和北极!
读写数据时,距离盘面3纳米的磁头会利用电磁铁,改变磁盘上磁性材料的极性来记录和删除数据,两种极性分别对应 0 或 1 ,磁头移动到指定扇区位置,向扇区写入数据时磁极由N->S,在扇区删除数据时磁极由S->N(S为1 N为0)
磁头和盘片的近距离操作,使得机械硬盘在运行时我们不能随意移动,更不能发生碰撞,一旦因为外力使磁头接触到盘片损伤了盘片就会导致数据丢失!
关于机械硬盘的工作原理详细讲解:
对于一个盘片,有两个盘面,每个盘面上又分为很多个磁道,每个磁道又分为很多个扇区!

单个扇区大小为 512 字节(或者 4 kb),这些扇区用来存储数据,同一半径中的所有扇区组成一个扇面;而半径相同的扇区组成磁道(柱面)!
注意:磁道上扇区的数量一般相同,因为磁道的面积会随着向外越来越打,对于面积较小的磁道,其扇区比特位会做的相对紧密一些,面积较大的扇区则会做的稀疏一些!
未来要找一个扇区:
- 先找磁头(head):定位在哪一个盘片以及哪一个面,只需要确定哪一个磁头(磁头编号)就能找到哪一个面
- 再找柱面(cylinder):定位在哪一个磁道,由半径决定,柱面也就是磁道
- 最后找扇区(sector):定位读取位置在该磁道的哪一个扇区,根据扇区的编号定位一个扇区
我们称这种:先定位磁头,再定位柱面(磁道),再定位扇区的方式,称为CHS定位法!
一个普通文件的属性和数据都是数据(0/1),无非就是占用一个或多个扇区来进行自己的数据存储的;我们既然能够用CHS定位任意一个扇区,我们就能定位任意多个扇区,从而将文件从硬件角度进行读写!
通过上述,如果操作系统能够得知任意一个CHS地址,就能访问任意一个扇区;但操作系统并非直接使用CHS地址,因为操作系统是软件,磁盘是硬件,硬件是一个地址,如果操作系统直接使用这个地址,如果硬件参数发生了变化,操作系统的磁盘信息也要变化,操作系统要和硬件做好解耦工作,即便是扇区,512字节单IO的基本数据量也是很小的,硬件是按照512字节处理,但操作系统实际进行IO的基本单位是4KB进行处理!
所以,操作系统的一次IO,无论读取数据是多少,都是按照4KB进行读取,因此磁盘也称块设备!
我们将磁盘中一个盘面的所有磁道想象成磁带被全部拉出来的样子,那么就是一直连续的线性结构!
操作系统需要有一套通用的新地址来进行块级别的访问,如果将磁道比方成磁带,那么一个磁道就可以当成一个数组对待,数组天然有下标,此时定位一个扇区,只需要一个数组下标就可以定位一个扇区,假设数组下标为N,而其中我们的操作系统是以4KB为单位进行IO的,故一个操作系统级别的文件块要包括8个扇区,甚至在OS角度,OS不关心扇区!
计算机常规的访问方式是起始地址+偏移量的方式(语言/数据类型);操作系统只需要知道数据所在的起始地址(第一个扇区的下标地址)+4kb(块的类型)就能找到一个数据,我们把数据块看做一种类型!
所以块的地址本质就是数组的一个下标N,以后我们表示一个块,我们可以采用先选下标N的方式定位任意一个块了,我们称这种线性地址为逻辑块地址LBA,这样我们定位磁盘扇区就转换为OS->N->LBA逻辑块地址->CHS;磁盘只认CHS地址,所以LBA地址和CHS地址要相互转换!
操作系统要管磁盘,就将磁盘看做一个大数组,对磁盘的管理,变成了对数组的管理,要对一个数组中的扇区进行管理,就需
要先描述再组织,通过struct对象封装8个扇区,存储中数组中,在数组中每一个下标对应的就是一个数据块!
在操作系统中有描述一个块的的结构体struct block{}
硬盘比较大,为了合理的管理一般操作系统可以分区,对于每个分区操作系统又会分组,这个组就是块组!
对于分区,就相对复杂一些!
我们在电脑中一般会对电脑进行分区,分区的意义在于,磁盘的空间是非常大的,如果不分区,巨大的空间管理会消耗操作系统的资源,我们在现实生活中,各大学都会在学校设立不同的学院进行高效管理,最重要的是上层管理者更好的调用管理资源,这种思想称为分治思想!
在文件系统中,操作系统先将整个大文件系统分为不同的区,存入struct disk数组中进行管理//分区属性 struct disk {struct part[3]; //三个分区 struct part是管理分区的对象类型//其他属性... }我们可以通过以下命令查看当前Linux系统的分区:
ll /dev/vda* -i
也可以通过下面的命令查看分区的信息:# 该命令相当于Windows的 “此电脑” df -h
系统在分区后,需要对区块进行格式化,在格式化时写入管理信息,不同的文件系统在格式化时写入的数据是不同的,这里讨论的是EXT文件系统!对于分区
- 为了使分区能被正常使用,需要对分区进行格式化
- 分区格式化:操作系统向分区写入文件系统的管理属性信息
- 磁盘分区后,分组、填写系统属性是操作系统做的事
当然,分区再细分就是块组!
由块组构成的线性空间亦可称为组线,代表一个分区,而一个struct part对象管理一个分区:struct part {struct part group[512]; //分为512个块组int lba_start; //起始块组位置(分区中第一个块组的下标)int lba_end; //结束块组位置(最后一个块组下标)//其他属性…… }将现有资源再分配后,可以 最大化利用资源,避免造成浪费及拖慢效率,下面我们详细介绍块组!
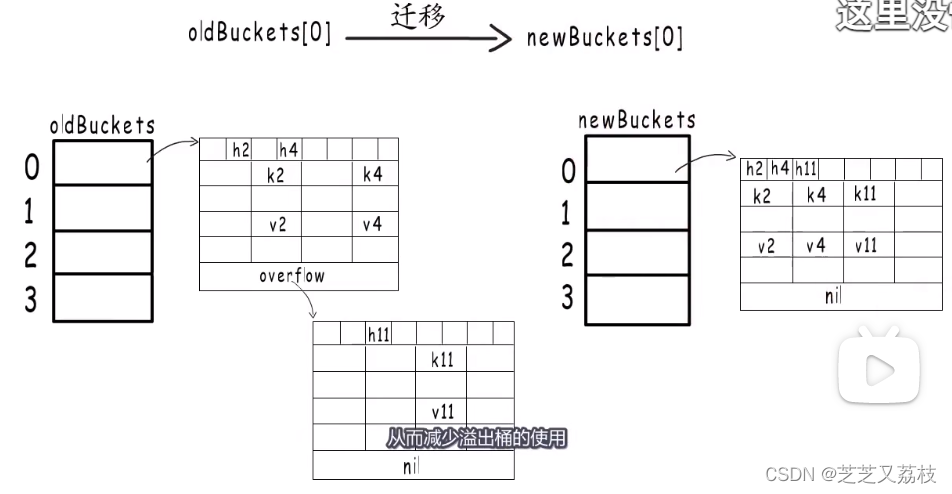
块组是由分区细分出的产物,块组与分区的关系如图所示:
关于这些分组信息的详细介绍:
我们知道文件 = 内容+属性,而Linux系统将文件属性和内容分离存储!
用户只认文件名,Linux系统只认inode号,文件的inode属性中,并不存在文件名,文件名是给用户用的,所以目录也是文件,目录也有inode,而目录存储的是文件名与inode的映射关系!
inode可以确定分组,inode编号在一个分区内唯一有效,不能跨分区,但一个inode是可以在整个分区有效的,所以每一个分区的inode编号有一个范围(因为分组中的inode都有一个范围),分组也是!
当然,对于一些大文件,Linux系统不一定会直接分配块进行存储,而是进行块索引多级存储!














文件操作的细节
创建文件
简单直接的说,就是实例化一个inode对象,就相当于创建了一个文件,但是有一些细节!
当我们增加一个文件时,操作系统需要:
- 首先操作系统在该目录所在分组中的inode Bitmap找到一个没有被使用的inode,在inode table中找到这个inode拿到
文件属性和inode编号- 将文件默认属性写入inode中,一开始文件是空的所以没有数据块
- 在对应目录的存储内容中
追加一条文件名与inode的映射关系,然后文件就创建好了未来对文件进行写入时,先去block Bitmap找到需要的数据块将这些块的bit位置为1,然后将这些数据块的位图信息填入文件inode的blocks数组中,再去data block中找到对应的数据块进行写入(刷新入)即可;同样的,当我们删除了某些数据,减小了数据块的占用时,将该文件不用的数据块在block Bitmap中置为0即可,表示可分配!
访问文件
当我们要访问一个文件时,操作系统需要:
- 首先我们会在特定目录下找到文件名(就相当于找到了inode编号)
- 一个目录也是一个文件,也一定隶属于一个分区,结合inode,在该分区中找到分组,在该分组的inode table中找到文件的
inode属性- 通过inode(的blocks数组)和data block的映射关系,找到该文件的数据块,并加载到内存中(被操作系统管理),并进行访问和操作
删除文件
当我们要删除文件时,操作系统需要:
- 先通过当前目录下文件名找到对应的inode编号
- 根据inode table找到文件的inode属性,然后将inode属性中blocks数组所占数据块对应的block Bitmap的bit位置为0
- 将inode Bitmap中文件inode位置的比特位设置为0,然后文件属性就没了,文件也就不存在了,被删除了
所以删文件只需要修改位图即可,从这里可以看出,操作系统的删除只是改变标识,并没有销毁数据内容,如果要彻底销毁,则需要借助一点手段!
恢复文件
文件被误删不一定没救,有可能可以恢复!
在数据被误删后,此时一定不要再动电脑,立刻断电送修,还可能挽回数据!
前面说过,删除并不是真删除,访问不到就行了,所以只要在删除后,有些操作系统会记录日志,日志中会保存被删的inode编号!所以,理论上可以:
- 根据日志找到被删文件的inode编号
- 根据inode编号找到对应的inode,将分组中的该inode的inode Bitmap表其位置置为1
- 找到其所占用的Data block,将其占用的data block在block Bitmap置为1
其中的内容没有被覆盖的,数据就可以找回来
所以,当我们误删文件后,不进行操作就可以防止被释放的数据块中的内容被覆盖!
当然,如果我们不想这么麻烦,也可以学习Windows创建一个回收站!
其他情况
如果inode只是单单的用数组建立和datablock的映射关系,即只是将inode对象实例化不同的文件系统datablock数组大小不同存在组中inode用完了但datablock没用完的情况,也存在inode没用完但是datablock用完了的情况!
也就是说,存在两种情况
- 如果我们一直只创建文件,但不写入内容,那么就会导致一个分组中indoe table被全部占满,此时就会导致datablock数据块没有占用,但分组已经无法再容纳新文件了
- 如果我们创建几个文件,但是文件内容非常大,用完了这个分组的所有datablock数据块,此时就会导致很多inode没有使用,但分组空间已满的情况
最后
文件系统概述到这里就基本结束了,本节我们带领大家简单的探究了Ext文件系统对于文件的管理方式,从硬件“机械硬盘”入手,再到文件系统的管理,两者的结合,一气呵成,相信大家了解了文件系统之后,才会发现操作系统对于文件的管理是多么高效和巧妙!
本次 <Linux文件系统概述> 就先介绍到这里啦,希望能够尽可能帮助到大家。
如果文章中有瑕疵,还请各位大佬细心点评和留言,我将立即修补错误,谢谢!

🌟其他文章阅读推荐🌟
Linux<重定向和缓冲区理解> -CSDN博客
Linux<文件理解和系统调用> -CSDN博客
Linux<进程控制> -CSDN博客
Linux<进程地址空间> -CSDN博客
Linux<环境变量> -CSDN博客
🌹欢迎读者多多浏览多多支持!🌹