Spring Boot与Kafka从零开始整合指南
- 准备工作
- 创建项目
- Spring Boot与Kafka的初次邂逅
- 配置
- 生产者
- 消费者
- 模拟测试
- 消息处理
- 生产者发送消息
- 消费者处理消息
- 自定义序列化器

主页传送门:📀 传送
准备工作
Spring boot:
- | 基于Spring的开源框架,用于简化新Spring应用的初始搭建以及开发过程
特性:
| 快速开发、轻量级、无代码生成和独立运行等特性
优势:
| 简化配置,提供自动配置,减少开发时间
应用场景:
| 适用于微服务架构、云原生应用等场景
环境搭建
安装jdk:
| 安装适合的JDK版本,为Spring Boot和Kafka提供运行环境
安装Maven:
| 安装Maven,为Spring Boot项目提供构建工具
安装Zookeeper:
| 安装Zookeeper,为Kafka提供协调服务
安装Kafka:
| 安装Kafka,为Spring Boot提供消息队列服务
环境变量:
| 配置JDK、Maven、Zookeeper和Kafka的环境变量,确保环境变量的正确性
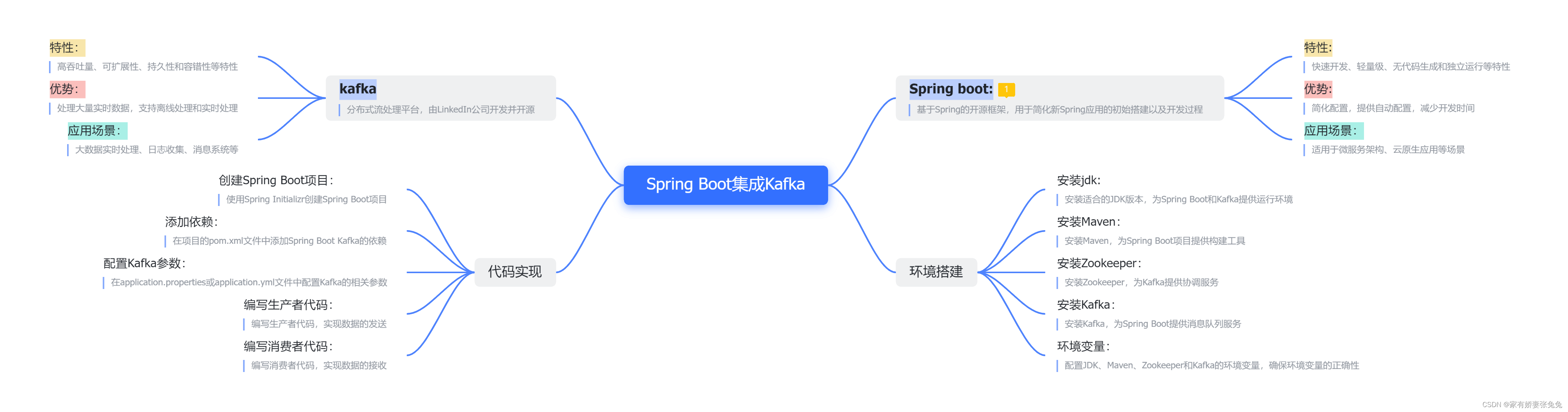
kafka:
| 分布式流处理平台,由LinkedIn公司开发并开源
特性:
| 高吞吐量、可扩展性、持久性和容错性等特性
优势:
| 处理大量实时数据,支持离线处理和实时处理
应用场景:
| 大数据实时处理、日志收集、消息系统等
代码实现
创建Spring Boot项目:
| 使用Spring Initializr创建Spring Boot项目
添加依赖:
| 在项目的pom.xml文件中添加Spring Boot Kafka的依赖
配置Kafka参数:
| 在application.properties或application.yml文件中配置Kafka的相关参数
编写生产者代码:
| 编写生产者代码,实现数据的发送
编写消费者代码:
| 编写消费者代码,实现数据的接收
Kafka不会安装的可以看这篇:kafka安装与启动
Kafka术语:
Kafka 是一个分布式流处理平台,它使用了一些特定的术语来描述其架构和组件。以下是一些常见的 Kafka 术语:
-
Broker:Kafka 集群中的每个服务器节点都被称为 Broker。每个 Broker 存储了消息的一部分数据,处理客户端的读写请求。
-
Topic:消息的类别称为 Topic。在 Topic 中,消息被发布和存储,并且 Kafka 集群中的 Broker 存储了一个或多个 Topic 的数据(用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)。
-
Partition:每个 Topic 被分割成一个或多个分区,每个分区是消息的线性有序序列。Partition 的数量是可配置的,每个消息会被分配到一个特定的分区中。
-
Offset:Offset 是分区中每条消息的唯一标识符,它表示消息在分区中的位置。消费者可以通过指定 Offset 来读取消息。
-
Producer:生产者,负责向 Kafka Broker 发布消息到指定的 Topic。
-
Consumer:消费者,从 Kafka Broker 拉取消息并处理它们的客户端。
-
Consumer Group:消费者可以组成一个消费者组来消费一个 Topic 中的消息。每个消费者组可以有多个消费者,但每个分区只能由一个消费者组中的一个消费者来消费。
-
Replication:Kafka 提供了数据的冗余备份机制,允许将分区的副本存储在多个 Broker 上,以提高数据的可靠性和容错性。
-
Leader 和 Follower:每个分区都有一个 Leader 和零个或多个 Followers。Leader 负责处理读写请求,而 Followers 则同步 Leader 的数据以实现备份和容错。
-
ZooKeeper:Kafka 使用 ZooKeeper 来进行集群协调和管理,包括选举 Broker 的 Leader、维护 Topic、Partition 的状态等。
创建项目
本文以 idea 2020.3 为例创建项目
-
使用
Spring Initializr创建一个SpringBoot程序
next
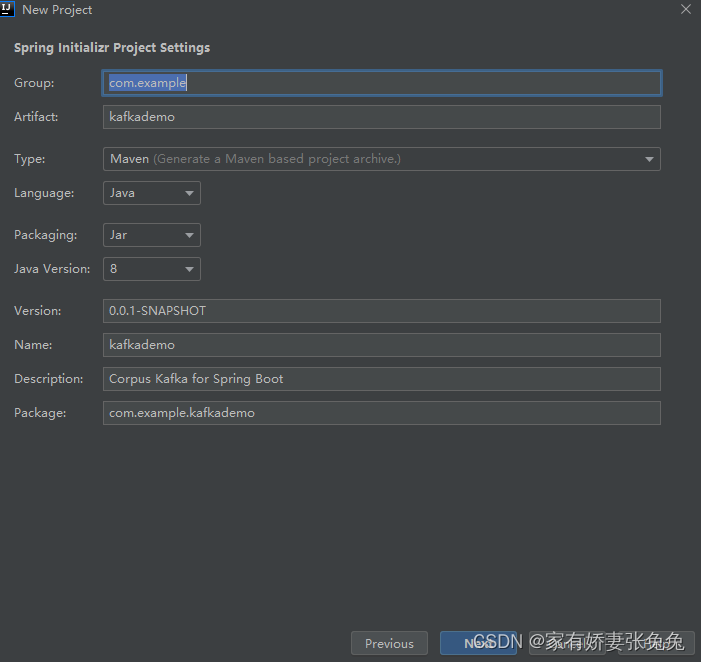
一路next -
添加依赖
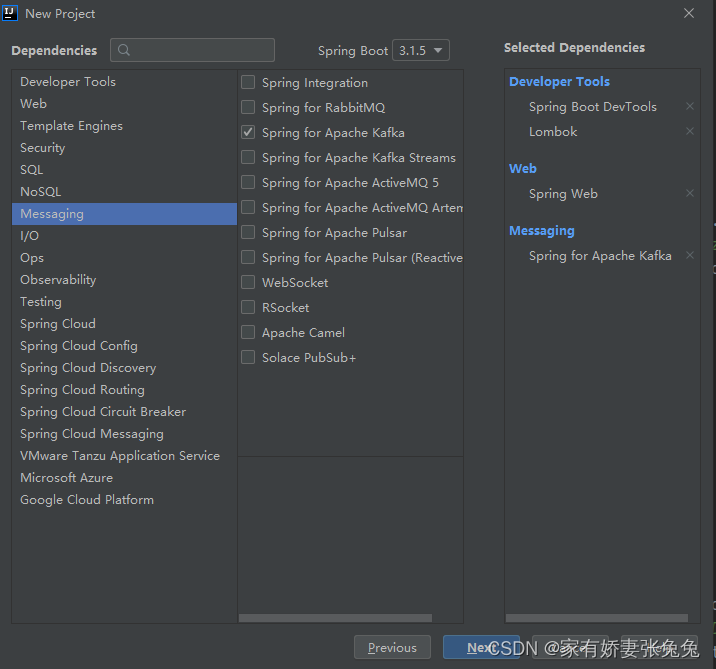
配置完成之后点击Finish。
依赖说明:
-
Lombok简化实体类开发。 -
Spring Web项目集成web开发所有依赖,包括Spring MVC,内置tomcat等。 -
Spring for Apache Kafka是 Spring和Kafka的集成依赖。
- 查看pom依赖
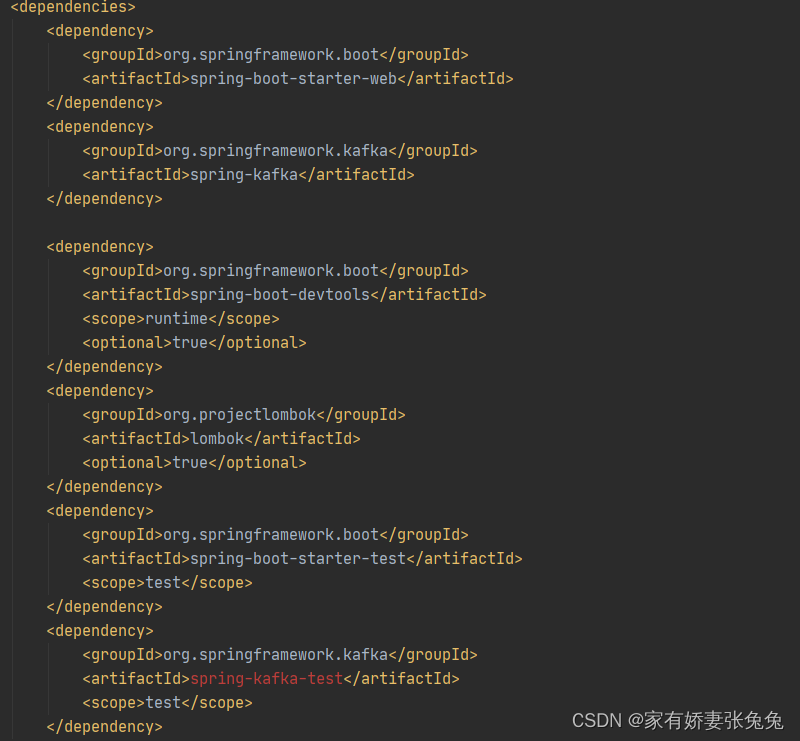
也可以根据自己需要自主添加适配版本的kafka依赖
<!--kafka-->
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>your version</version>
</dependency>
爆红是因为是第一次集成Kafka,配置下maven,下载好Kafka的相关依赖后红色就会消失。
到此就创建好了一个集成了Kafka的SpringBoot Web项目。
Spring Boot与Kafka的初次邂逅
创建好项目,加好必要的依赖之后就可以开始在配置文件中(application.yml 或application.properties)加kafka配置的变量了。
配置
在application.properties/application.yml中添加 kafka 配置变量
application.yml:
kafka:# kafka ipbootstrap-servers: 127.0.0.1:9092# -------------- producer ----------------producer:retries: 3 #acks: 1 #batch-size: 16384 #buffer-memory: 33554432 #key-serializer: org.apache.kafka.common.serialization.StringSerializer# value-serializer: com.itheima.demo.config.MySerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer#---------------- consumer --------------------consumer:group-id: javagroup #enable-auto-commit: false #auto-commit-interval: 100 ## earliest:# latest:# none:topicauto-offset-reset: earliest#max-poll-records: 500key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# value-deserializer: com.itheima.demo.config.MyDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
application.properties:
# Kafka集群的地址(集群配多个的时候中间用逗号隔开)
spring.kafka.bootstrap-servers=127.0.0.1:9092
# 发送失败时的重试次数,默认为3次
spring.kafka.producer.retries=3
# 消息确认的方式,1表示只需要leader节点确认即可,其他值表示需要所有副本节点确认。
spring.kafka.producer.acks=1
# 批量发送的消息数量(字节单位)
spring.kafka.producer.batch-size=16384
# 32MB的批处理缓冲区
spring.kafka.producer.buffer-memory=33554432
# 键的序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
# 值的序列化类
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 默认消费者组(消费者组的ID,同一个消费者组内的消费者会消费相同的主题分区)
spring.kafka.consumer.group-id=crm-user-service
# 最早未被消费的offset
spring.kafka.consumer.auto-offset-reset=earliest
# 批量一次最大拉取数据量
spring.kafka.consumer.max-poll-records=4000
# 是否自动提交
spring.kafka.consumer.enable-auto-commit=true
# 自动提交时间间隔,单位ms
spring.kafka.consumer.auto-commit-interval=1000
生产者
创建一个KafkaController, 向测试主题发送消息
/*** 生产者* @author ztt* @date 2023/8/5 15:38*/
@RestController
@RequestMapping("/kafkaMsg")
public class KafkaController {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;//主题private final static String TOPIC_NAME = "testTopic";@PostMapping("/sendMsg")public String sendMsg() {kafkaTemplate.send(TOPIC_NAME,"fffff");return "send success";}
}
消费者
创建一个TestConsumer , 接收消息并处理消息
/*** 消费者* @author ztt* @date 2023/8/5 15:41*/
@Component
@Slf4j
public class TestConsumer {@KafkaListener(topics = "testTopic", groupId = "testGroup")public void listenGroup(ConsumerRecord<String, String> record) {// 参数: 从topic中收到的值log.info("接收到发送消息:" + record);}
}模拟测试
@RunWith(SpringRunner.class)
@SpringBootTest
public class TestDemo {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;private final static Integer countNum = 10;@Testpublic void testSend(){for (int i = 0; i < countNum ; i++) {Map<String, Object> map = new LinkedHashMap<>();map.put("num", i);//向主题推送数据kafkaTemplate.send("testTopic", JSONObject.toJSONString(map));}}
}
消息处理
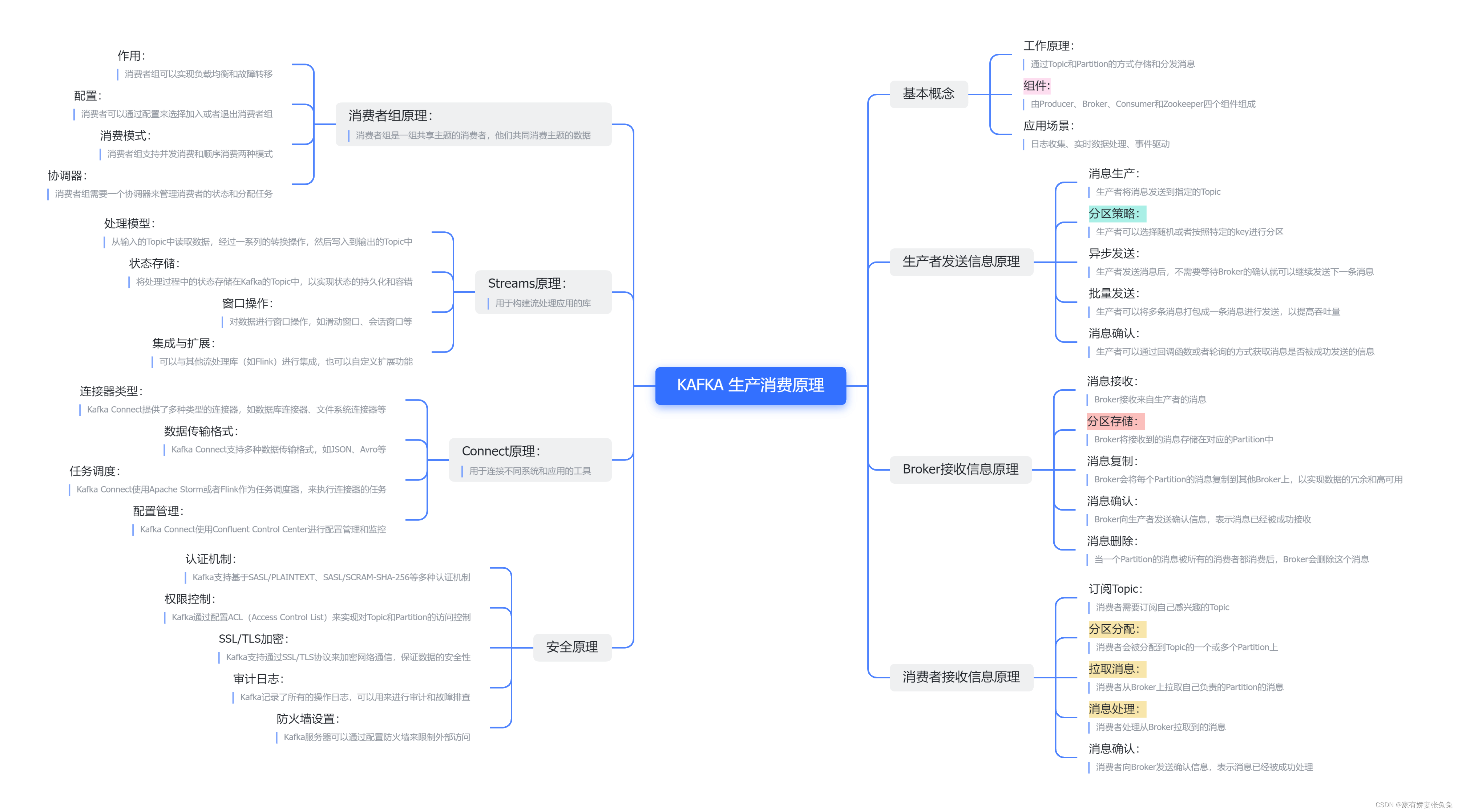
在Kafka中,消息的处理通常涉及到两个主要组件:生产者和消费者。生产者负责将消息发送到Kafka主题,而消费者则从主题中读取这些消息并进行逻辑处理。
基本概念
工作原理:
| 通过Topic和Partition的方式存储和分发消息
组件:
| 由Producer、Broker、Consumer和Zookeeper四个组件组成
应用场景:
| 日志收集、实时数据处理、事件驱动
生产者发送信息原理
消息生产:
| 生产者将消息发送到指定的Topic
分区策略:
| 生产者可以选择随机或者按照特定的key进行分区
异步发送:
| 生产者发送消息后,不需要等待Broker的确认就可以继续发送下一条消息
批量发送:
| 生产者可以将多条消息打包成一条消息进行发送,以提高吞吐量
消息确认:
| 生产者可以通过回调函数或者轮询的方式获取消息是否被成功发送的信息
Broker接收信息原理
消息接收:
| Broker接收来自生产者的消息
分区存储:
| Broker将接收到的消息存储在对应的Partition中
消息复制:
| Broker会将每个Partition的消息复制到其他Broker上,以实现数据的冗余和高可用
消息确认:
| Broker向生产者发送确认信息,表示消息已经被成功接收
消息删除:
| 当一个Partition的消息被所有的消费者都消费后,Broker会删除这个消息
消费者接收信息原理
订阅Topic:
| 消费者需要订阅自己感兴趣的Topic
分区分配:
| 消费者会被分配到Topic的一个或多个Partition上
拉取消息:
| 消费者从Broker上拉取自己负责的Partition的消息
消息处理:
| 消费者处理从Broker拉取到的消息
消息确认:
| 消费者向Broker发送确认信息,表示消息已经被成功处理
消费者组原理:
| 消费者组是一组共享主题的消费者,他们共同消费主题的数据
作用:
| 消费者组可以实现负载均衡和故障转移
配置:
| 消费者可以通过配置来选择加入或者退出消费者组
消费模式:
| 消费者组支持并发消费和顺序消费两种模式
协调器:
| 消费者组需要一个协调器来管理消费者的状态和分配任务
Streams原理:
| 用于构建流处理应用的库
处理模型:
| 从输入的Topic中读取数据,经过一系列的转换操作,然后写入到输出的Topic中
状态存储:
| 将处理过程中的状态存储在Kafka的Topic中,以实现状态的持久化和容错
窗口操作:
| 对数据进行窗口操作,如滑动窗口、会话窗口等
集成与扩展:
| 可以与其他流处理库(如Flink)进行集成,也可以自定义扩展功能
Connect原理:
| 用于连接不同系统和应用的工具
连接器类型:
| Kafka Connect提供了多种类型的连接器,如数据库连接器、文件系统连接器等
数据传输格式:
| Kafka Connect支持多种数据传输格式,如JSON、Avro等
任务调度:
| Kafka Connect使用Apache Storm或者Flink作为任务调度器,来执行连接器的任务
配置管理:
| Kafka Connect使用Confluent Control Center进行配置管理和监控
安全原理
认证机制:
| Kafka支持基于SASL/PLAINTEXT、SASL/SCRAM-SHA-256等多种认证机制
权限控制:
| Kafka通过配置ACL(Access Control List)来实现对Topic和Partition的访问控制
SSL/TLS加密:
| Kafka支持通过SSL/TLS协议来加密网络通信,保证数据的安全性
审计日志:
| Kafka记录了所有的操作日志,可以用来进行审计和故障排查
防火墙设置:
| Kafka服务器可以通过配置防火墙来限制外部访问
生产者发送消息
使用KafkaTemplate或者Producer实例来发送消息到主题
KafkaTemplate是一个方便的高级封装,代码如下:
public class KafkaTemplateDemo {private static final String TOPIC = "testTopicA";@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String message) {kafkaTemplate.send(TOPIC, message);System.out.println("发送消息: " + message);}
}
Producer接口是Kafka原生API中用于发送消息的主要接口, 代码如下:
public class KafkaProducerDemo {private static final String TOPIC = "testTopicB";public static void main(String[] args) {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 创建 Producer 实例try (Producer<String, String> producer = new org.apache.kafka.clients.producer.KafkaProducer<>(props)) {// 生产消息String message = "Hello, Kafka!";producer.send(new ProducerRecord<>(TOPIC, message));System.out.println("发送消息: " + message);}}
}
消费者处理消息
使用@KafkaListener注解或KafkaConsumer实例来订阅Kafka主题,并在相应的方法中处理接收到的消息。
使用@KafkaListener注解来创建一个消费者并订阅Kafka的主题
public class KafkaListenerDemo{@KafkaListener(topics = "testTpoic", groupId = "testGroup")public void listen(String message) {// 处理收到的消息System.out.println("接收消息: " + message);// 逻辑处理接收到的消息// 。。。省略逻辑处理接收到的信息}
}
使用KafkaConsumer类手动创建一个Kafka消费者
public class SimpleKafkaConsumerDemo {public static void main(String[] args) {Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1");props.put(ConsumerConfig.GROUP_ID_CONFIG, "testGroup");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Collections.singletonList("testTpoic"));try {while (true) {ConsumerRecords<String, String> records = consumer.poll(100);records.forEach(record -> {System.out.println("接收消息: " + record.value());// 逻辑来处理接收到的消息});}} finally {consumer.close();}}
}
自定义序列化器
在Kafka 中,可以自定义消息的序列化和反序列化过程,以便按照需求对消息进行定制化处理。一般来说,Kafka 使用的默认序列化器是基于字节数组的序列化和反序列化。但有时候为了处理更复杂的消息格式需要自定义序列化器来处理。
在Kafka中,如果需要使用自定义的序列化器,可以实现org.apache.kafka.common.serialization.Serializer接口。
示例: 假设处理自定义的对象Person:
创建一个Person类:
@Getter
@Setter
public class Person implements Serializable {private String name;private int age;@Overridepublic String toString() {return "Person{name='" + name + "', age=" + age + '}';}
}
然后,实现Serializer接口及对应的configure和serialize方法:
public class PersonSerializer implements Serializer<Person> {@Overridepublic void configure(Map<String, ?> configs, boolean isKey) {// 用于获取配置信息。}@Overridepublic byte[] serialize(String topic, Person data) {if (data == null) {return null;}try (ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream)) {objectOutputStream.writeObject(data);return byteArrayOutputStream.toByteArray();} catch (IOException e) {throw new RuntimeException("实例化人出错", e);}}@Overridepublic void close() {// 执行资源释放等操作。}
}
实现 Deserializer 接口
public class PersonDeserializer implements Deserializer<CustomObject> {@Overridepublic CustomObject deserialize(String topic, byte[] data) {// 在这里实现将字节数组反序列化为 CustomObject 对象的逻辑// 返回反序列化后的 CustomObject 对象return /* 实现反序列化逻辑 */;}@Overridepublic void close() {// 关闭资源的逻辑}
}
生产者端配置:
Properties props = new Properties();
props.put("bootstrap.servers", "127.0.0.1");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "com.test.util.PersonSerializer"); // 指定自定义序列化器类的完整路径
Producer<String, Person> producer = new KafkaProducer<>(props);
消费者端配置:
Properties props = new Properties();
props.put("bootstrap.servers", "127.0.0.1");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "com.test.util.PersonDeserializer"); // 指定自定义反序列化器类的完整路径
props.put("group.id", "testGroup");Consumer<String, Person> consumer = new KafkaConsumer<>(props);
如果喜欢的话,欢迎 🤞关注 👍点赞 💬评论 🤝收藏 🙌一起讨论你的支持就是我✍️创作的动力! 💞💞💞