DGL在 dgl.data 里实现了很多常用的图数据集。它们遵循了由 dgl.data.DGLDataset 类定义的标准的数据处理管道。 DGL推荐用户将图数据处理为 dgl.data.DGLDataset 的子类。该类为导入、处理和保存图数据提供了简单而干净的解决方案。
DGL中的Dataset类
它是处理、导入以及保存dgl.data提供的图数据集的基类,实现了处理图的基本模板。同时,它还提供了一种标准且方便的方式来导入图数据,同时用户可以存储有关数据集的图,也可以存储图中的节点特征、标签、掩码以及诸如类别数标签数等基本信息。该模块的工作方式如下:
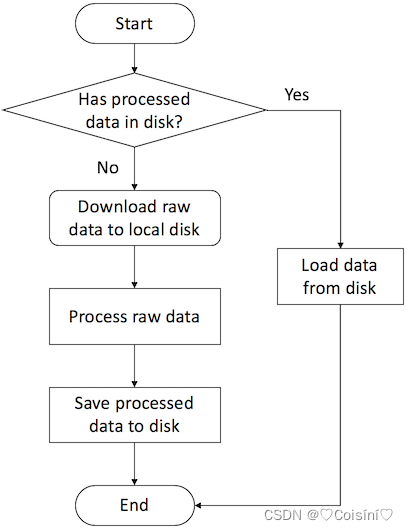
由上图可见,这种加载方式与torch的其他组件导入数据集方式几乎相同。同时Dataset也是学习Pytorch过程中重点关注的内容,这里是一篇Hugging-Face实现中文句子情感分析的完整流程:HuggingFace-利用BERT预训练模型实现中文情感分类(下游任务)
可以看到该部分在定义数据集时直接使用的是Dataset类,而它进一步调用了datasets包中的load_dataset。
搭建自己的Dataset
下面定义了一个名为MyDataset的类,它继承于dgl.data.DGLDataset,我们将它作为处理位于远程服务器或本地磁盘上图数据集的接口。
from dgl.data import DGLDatasetclass MyDataset(DGLDataset):""" 用于在DGL中自定义图数据集的模板:Parameters----------url : str下载原始数据集的url。raw_dir : str指定下载数据的存储目录或已下载数据的存储目录。默认: ~/.dgl/save_dir : str处理完成的数据集的保存目录。默认:raw_dir指定的值force_reload : bool是否重新导入数据集。默认:Falseverbose : bool是否打印进度信息。"""def __init__(self,url=None,raw_dir=None,save_dir=None,force_reload=False,verbose=False):super(MyDataset, self).__init__(name='dataset_name',url=url,raw_dir=raw_dir,save_dir=save_dir,force_reload=force_reload,verbose=verbose)def download(self):# 将原始数据下载到本地磁盘passdef process(self):# 将原始数据处理为图、标签和数据集划分的掩码passdef __getitem__(self, idx):# 通过idx得到与之对应的一个样本passdef __len__(self):# 数据样本的数量passdef save(self):# 将处理后的数据保存至 `self.save_path`passdef load(self):# 从 `self.save_path` 导入处理后的数据passdef has_cache(self):# 检查在 `self.save_path` 中是否存有处理后的数据pass
原始的DGLDataset类中有抽象函数process()、__ getitem __(idx)以及__len __()。DGL要求子类必须实现这些函数,同时DGL建议实现保存和导入函数,这样做的目的是对于处理的大型数据集,可以节省大量的时间开销。
DGLDataset 的目的是提供一种标准且方便的方式来导入图数据。 用户可以存储有关数据集的图、特征、标签、掩码,以及诸如类别数、标签数等基本信息。 诸如采样、划分或特征归一化等操作建议在 DGLDataset 子类之外完成。
下载原始数据
如果用户的数据集已经在本地磁盘中,请确保它被存放在目录 raw_dir 中。 如果用户想在任何地方运行代码而又不想自己下载数据并将其移动到正确的目录中,则可以通过实现函数 download() 来自动完成。
如果数据集是一个zip文件,可以直接继承 dgl.data.DGLBuiltinDataset 类。后者支持解压缩zip文件。 否则用户需要自己实现 download(),其实现的步骤可以参考QM7Dataset类,其内容如下:
import os
from dgl.data.utils import downloaddef download(self):# 存储文件的路径file_path = os.path.join(self.raw_dir, self.name + '.mat')# 下载文件download(self.url, path=file_path)
请注意上面的代码是将.mat的文件下载到用户指定的self.raw_dir中,但是如果是.gz、.tar、.tar.gz或.tgz文件则需要参考下面的BitcoinOTCDataset 类下载.gz文件的方法:
from dgl.data.utils import download, check_sha1def download(self):# 存储文件的路径,请确保使用与原始文件名相同的后缀gz_file_path = os.path.join(self.raw_dir, self.name + '.csv.gz')# 下载文件download(self.url, path=gz_file_path)# 检查 SHA-1if not check_sha1(gz_file_path, self._sha1_str):raise UserWarning('File {} is downloaded but the content hash does not match.''The repo may be outdated or download may be incomplete. ''Otherwise you can create an issue for it.'.format(self.name + '.csv.gz'))# 将文件解压缩到目录self.raw_dir下的self.name目录中self._extract_gz(gz_file_path, self.raw_path)
上面的代码会将文件解压缩到 self.raw_dir 下的目录 self.name 中。 如果该类继承自 dgl.data.DGLBuiltinDataset 来处理zip文件, 则它也会将文件解压缩到目录 self.name 中。一个可选项是用户可以按照上面的示例检查下载后文件的SHA-1字符串,以防作者在远程服务器上更改了文件。
数据处理
本小节主要是用于实现MyDataset中的process()函数,它主要是根据不同图任务进行区分的。
图上的机器学习任务主要包括三个大类:
- 整张图的分类:也就是将看到的图看做一个整体,预测该图属于什么类型或什么领域,一般这种图的数据规模较小
- 节点分类:主要是对于图中的节点进行预测
- 链路预测:这种问题主要是针对于节点分类的回归问题,也就是不需要知道明确的节点分类,只需要预测出边或者节点的特征值
这里着重说一下第三点:这个有点类似于之前完成的Hugging-Face的例子,由于我不想对PLM进行训练,而是直接使用它已经训练好的冻结后的梯度和参数,所以我可以直接使用它作为一个特征提取器,这种做的效果如果不是追求SOTA的话往往也是比较好的。具体的还是参考这篇:
HuggingFace-利用BERT预训练模型实现中文情感分类(下游任务)
本节重点介绍了处理图、特征和划分掩码的标准方法。
处理整图分类数据集
Dataset部分
整图分类数据集与用小批次训练的典型机器学习任务中的大多数数据集类似。 因此,需要将原始数据处理为 dgl.DGLGraph 对象的列表和标签张量的列表。 此外,如果原始数据已被拆分为多个文件,则可以添加参数 split 以导入数据的特定部分。
下面是 QM7bDataset 的示例:
from dgl.data import DGLDatasetclass QM7bDataset(DGLDataset):_url = 'http://deepchem.io.s3-website-us-west-1.amazonaws.com/' \'datasets/qm7b.mat'_sha1_str = '4102c744bb9d6fd7b40ac67a300e49cd87e28392'def __init__(self, raw_dir=None, force_reload=False, verbose=False):super(QM7bDataset, self).__init__(name='qm7b',url=self._url,raw_dir=raw_dir,force_reload=force_reload,verbose=verbose)def process(self):mat_path = self.raw_path + '.mat'# 将数据处理为图列表和标签列表self.graphs, self.label = self._load_graph(mat_path)def __getitem__(self, idx):""" 通过idx获取对应的图和标签Parameters----------idx : intItem indexReturns-------(dgl.DGLGraph, Tensor)"""return self.graphs[idx], self.label[idx]def __len__(self):"""数据集中图的数量"""return len(self.graphs)
加载图数据集
可以看到这里的process()函数并没有直接对原图数据集进行处理,而是使用的_load_graph()函数,对于这个函数我们可以通过QM7bDataset的源码看到:
def _load_graph(self, filename):data = io.loadmat(filename)labels = F.tensor(data['T'], dtype=F.data_type_dict['float32'])feats = data['X']num_graphs = labels.shape[0]graphs = []for i in range(num_graphs):edge_list = feats[i].nonzero()g = dgl_graph(edge_list)g.edata['h'] = F.tensor(feats[i][edge_list[0], edge_list[1]].reshape(-1, 1),dtype=F.data_type_dict['float32'])graphs.append(g)return graphs, labels
_load_graph最终返回了处理后的图特征列表与标签特征列表。
增加额外属性
用户还可以向类添加属性以指示一些有用的数据集信息。在 QM7bDataset 中, 用户可以添加属性 num_tasks 来指示此多任务数据集中的预测任务总数:
@property
def num_tasks(self):"""每个图的标签数,即预测任务数。"""return 14
使用定义的Dataset
编写完以上代码后,就可以使用下面的方式使用定义的QM7bDataset:
import dgl
import torchfrom dgl.dataloading import GraphDataLoader# 数据导入
dataset = QM7bDataset()
num_tasks = dataset.num_tasks# 创建 dataloaders
dataloader = GraphDataLoader(dataset, batch_size=1, shuffle=True)# 训练
for epoch in range(100):for g, labels in dataloader:# 用户自己的训练代码pass
处理节点分类数据集
与整图分类不同,节点分类通常在单个图上进行。因此数据集的划分是在图的节点集上进行。 DGL建议使用节点掩码来指定数据集的划分。
此外,DGL推荐重新排列图的节点/边,使得相邻节点/边的ID位于邻近区间内。这个过程 可以提高节点/边的邻居的局部性,为后续在图上进行的计算与分析的性能改善提供可能。 DGL提供了名为 dgl.reorder_graph() 的API用于此优化。
Dataset部分
以内置数据集 CitationGraphDataset 为例:
from dgl.data import DGLBuiltinDataset
from dgl.data.utils import _get_dgl_urlclass CitationGraphDataset(DGLBuiltinDataset):_urls = {'cora_v2' : 'dataset/cora_v2.zip','citeseer' : 'dataset/citeseer.zip','pubmed' : 'dataset/pubmed.zip',}def __init__(self, name, raw_dir=None, force_reload=False, verbose=True):assert name.lower() in ['cora', 'citeseer', 'pubmed']if name.lower() == 'cora':name = 'cora_v2'url = _get_dgl_url(self._urls[name])super(CitationGraphDataset, self).__init__(name,url=url,raw_dir=raw_dir,force_reload=force_reload,verbose=verbose)def process(self):# 跳过一些处理的代码# === 跳过数据处理 ===# 构建图g = dgl.graph(graph)# 划分掩码g.ndata['train_mask'] = train_maskg.ndata['val_mask'] = val_maskg.ndata['test_mask'] = test_mask# 节点的标签g.ndata['label'] = torch.tensor(labels)# 节点的特征g.ndata['feat'] = torch.tensor(_preprocess_features(features),dtype=F.data_type_dict['float32'])self._num_tasks = onehot_labels.shape[1]self._labels = labels# 重排图以获得更优的局部性self._g = dgl.reorder_graph(g)def __getitem__(self, idx):assert idx == 0, "这个数据集里只有一个图"return self._gdef __len__(self):return 1
为简便起见,这里省略了 process() 中的一些代码,以突出展示用于处理节点分类数据集的关键部分:划分掩码。 节点特征和节点的标签被存储在 g.ndata 中。
这里 getitem(idx) 和 len() 的实现也发生了变化, 这是因为节点分类任务通常只用一个图。掩码在PyTorch和TensorFlow中是bool张量,在MXNet中是float张量。
使用定义的Dataset
下面中使用 dgl.data.CitationGraphDataset 的子类 dgl.data.CiteseerGraphDataset 来演示如何使用用于节点分类的数据集:
# 导入数据
dataset = CiteseerGraphDataset(raw_dir='')
graph = dataset[0]# 获取划分的掩码
train_mask = graph.ndata['train_mask']
val_mask = graph.ndata['val_mask']
test_mask = graph.ndata['test_mask']# 获取节点特征
feats = graph.ndata['feat']# 获取标签
labels = graph.ndata['label']
处理链接预测数据集
链接预测数据集的处理与节点分类相似,数据集中通常只有一个图。
以内置的数据集 KnowledgeGraphDataset 为例,其中省略了详细的数据处理代码以突出展示处理链接预测数据集的关键部分:
Dataset部分
# 创建链接预测数据集示例
class KnowledgeGraphDataset(DGLBuiltinDataset):def __init__(self, name, reverse=True, raw_dir=None, force_reload=False, verbose=True):self._name = nameself.reverse = reverseurl = _get_dgl_url('dataset/') + '{}.tgz'.format(name)super(KnowledgeGraphDataset, self).__init__(name,url=url,raw_dir=raw_dir,force_reload=force_reload,verbose=verbose)def process(self):# 跳过一些处理的代码# === 跳过数据处理 ===# 划分掩码g.edata['train_mask'] = train_maskg.edata['val_mask'] = val_maskg.edata['test_mask'] = test_mask# 边类型g.edata['etype'] = etype# 节点类型g.ndata['ntype'] = ntypeself._g = gdef __getitem__(self, idx):assert idx == 0, "这个数据集只有一个图"return self._gdef __len__(self):return 1
在上面代码中,图的edata存储了划分掩码。
使用定义的Dataset
from dgl.data import FB15k237Dataset# 导入数据
dataset = FB15k237Dataset()
graph = dataset[0]# 获取训练集掩码
train_mask = graph.edata['train_mask']
train_idx = torch.nonzero(train_mask, as_tuple=False).squeeze()
src, dst = graph.edges(train_idx)# 获取训练集中的边类型
rel = graph.edata['etype'][train_idx]
保存和加载数据
DGL建议用户实现保存和加载数据的函数,将处理后的数据缓存在本地磁盘中。 这样在多数情况下可以帮用户节省大量的数据处理时间。DGL提供了4个函数让任务变得简单。
dgl.save_graphs()和dgl.load_graphs(): 保存DGLGraph对象和标签到本地磁盘和从本地磁盘读取它们。dgl.data.utils.save_info()和dgl.data.utils.load_info(): 将数据集的有用信息(python dict对象)保存到本地磁盘和从本地磁盘读取它们。
下面的示例显示了如何保存和读取图和数据集信息的列表。
import os
from dgl import save_graphs, load_graphs
from dgl.data.utils import makedirs, save_info, load_infodef save(self):# 保存图和标签graph_path = os.path.join(self.save_path, self.mode + '_dgl_graph.bin')save_graphs(graph_path, self.graphs, {'labels': self.labels})# 在Python字典里保存其他信息info_path = os.path.join(self.save_path, self.mode + '_info.pkl')save_info(info_path, {'num_classes': self.num_classes})def load(self):# 从目录 `self.save_path` 里读取处理过的数据graph_path = os.path.join(self.save_path, self.mode + '_dgl_graph.bin')self.graphs, label_dict = load_graphs(graph_path)self.labels = label_dict['labels']info_path = os.path.join(self.save_path, self.mode + '_info.pkl')self.num_classes = load_info(info_path)['num_classes']def has_cache(self):# 检查在 `self.save_path` 里是否有处理过的数据文件graph_path = os.path.join(self.save_path, self.mode + '_dgl_graph.bin')info_path = os.path.join(self.save_path, self.mode + '_info.pkl')return os.path.exists(graph_path) and os.path.exists(info_path)
注意:有些情况下不适合保存处理过的数据;
例如,在内置数据集 GDELTDataset 中, 处理过的数据比较大。所以这个时候,在 __getitem__(idx) 中处理每个数据实例是更高效的方法。


![模型优化【2】-剪枝[局部剪枝]](https://img-blog.csdnimg.cn/3eb7ed28fe7b433880a9f2ddf3f6efbc.png)