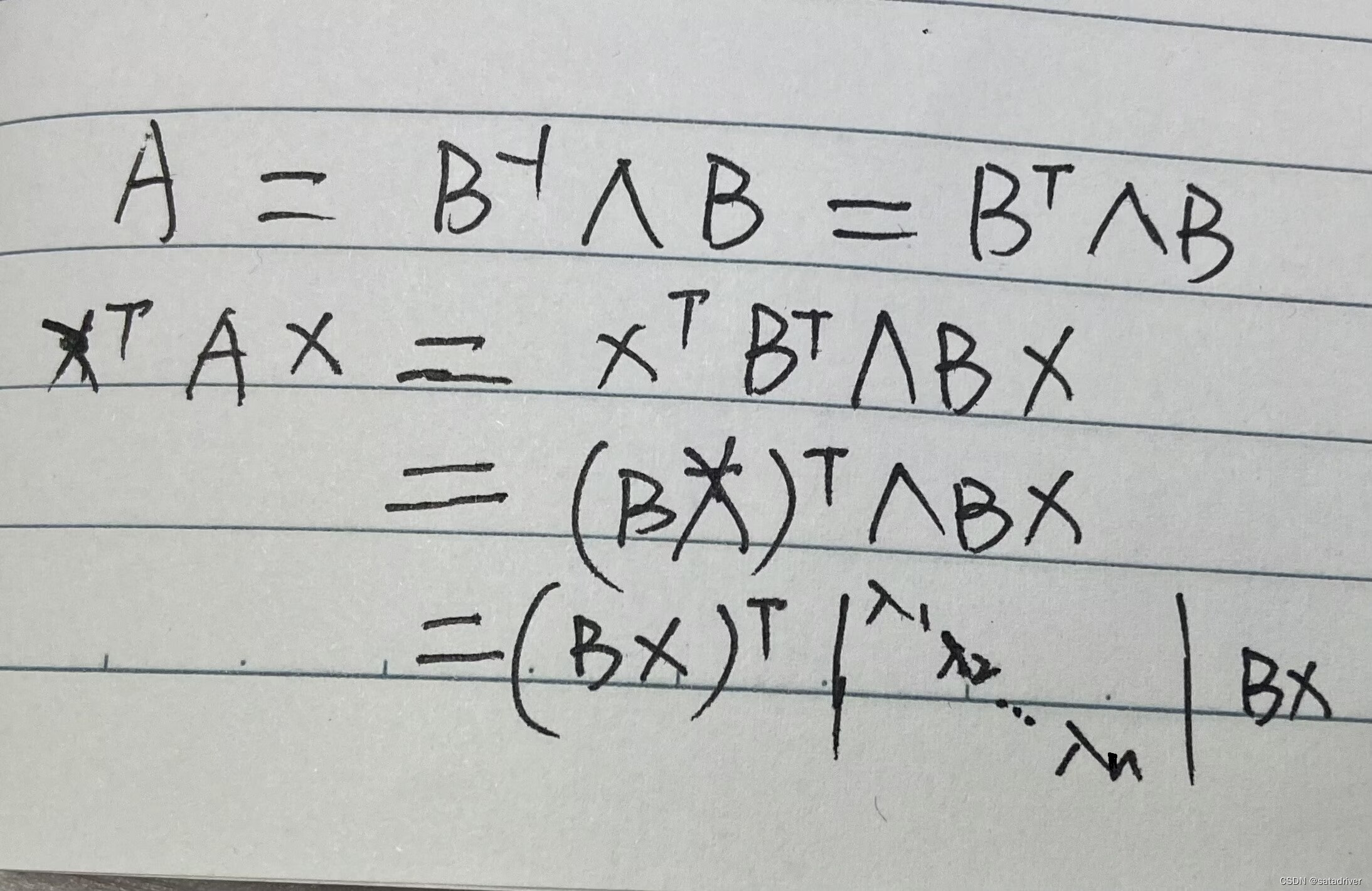- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
1 ResNet理论
深度残差网络ResNet(deep residual network)在2015年由何凯明等提出,因为它简单与实用并存,随后很多研究都是建立在ResNet-50或者ResNet-101基础上完成。
ResNet主要解决深度卷积网络在深度加深时候的”退化“问题。在一般的卷积神经网络中,增大网络深度后带来的第一个问题就是梯度消失或梯度爆炸,这个问题Szegedy提出的BN层后被顺利解决。BN层能对各层的输出做归一化,这样梯度在反向层层传递后仍能保持大小稳定,不会出现过大或过小的情况。但是作者发现加了BN层后再加大深度仍然不容易收敛,其提到了第二个问题--准确率下降问题:层级大到一定程度时准确率就会饱和,然后迅速下降,这种下降既不是梯度消失引起的,也不是过拟合造成的,而是由于网络过于复杂,以至于光靠不加约束的放养式的训练很难达到理想的准确率。
准确率下降问题不是网络结构本身的问题,而是现有的训练方式不够理想造成的。当前广泛使用的优化器,无论是SGD,还是RMSProp,或是Adam,都无法在网络深度变大后达到理论上最优的收敛结果。
作者在文中证明了只要有合适的网络结构,更深的网络肯定会比较浅的网络效果好。证明过程也很简单:假设在一种网络A的后面添加几层形成新的网络B,如果增加的层级只是对A的输出做了个恒等映射(identity mapping),即A的输出经过新增的层级变成B的输出后没有发生变化,这样网络A和网络B的错误率就是相等的,也就证明了加深后的网络不会比加深前的网络效果差。

何凯明提出了一种残差结构来实现上述恒等映射(如上图所示):整个模块除了正常的卷积层输出外,还有一个分支把输入直接连到输出上,该分支输出和卷积的输出做算术相加得到最终的输出,用公式表达就是H(x)=F(x)+x,其中x是输入,F(x)是卷积分支的输出,H(x)是整个结构的输出。可以证明如果F(x)分支中所有参数都是0,H(x)=x,即H(x)与x为恒等映射。残差结构是人为的制造了恒等映射,能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。如果一个网络通过简单的手工设置参数值就能达到想要的结果,那这种结构就很容易通过训练来收敛到该结果,这是一条设计复杂的网络时通用的规则。
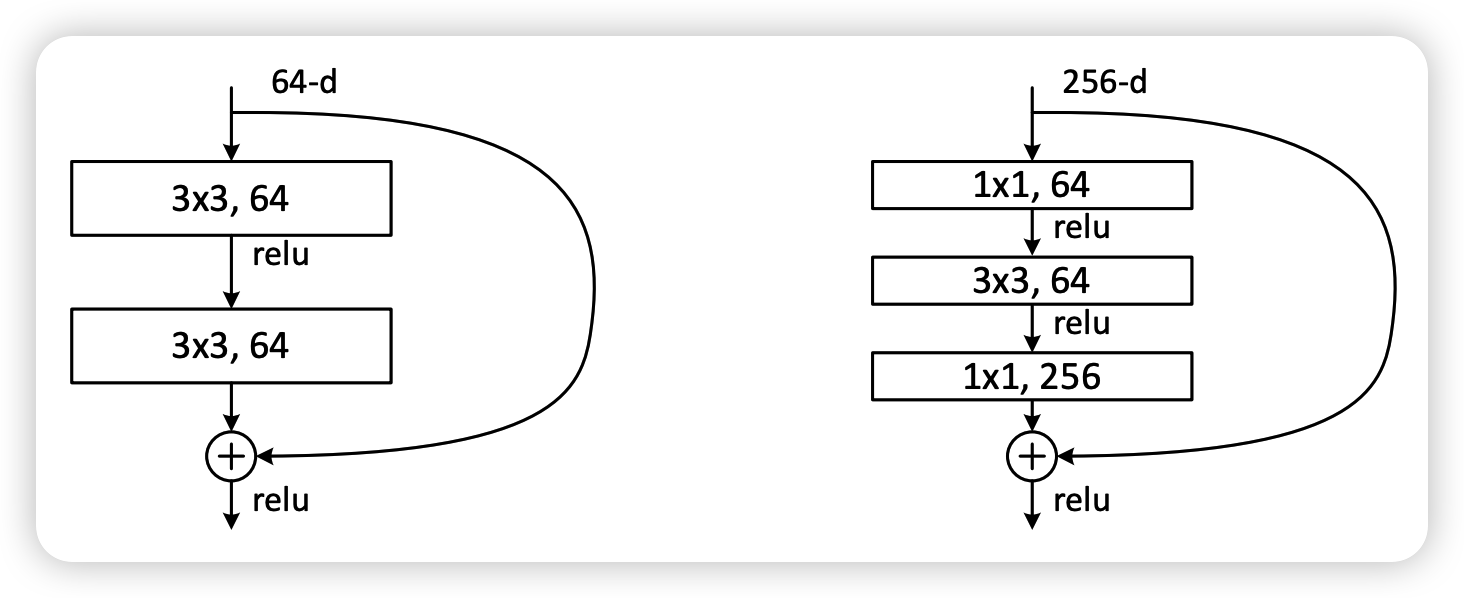
图2 左边的单元为ResNet两层的残差单元,两层的残差单元包含两个相同输出通道数的3*3卷积,只是用于较浅的ResNet网络,对较深的网络主要使用三层的残差单元。三层的残差单元又称为bottleneck结构,先用一个1*1卷积进行降维,最后用1*1升维恢复原有的维度。另外,如果有输入输出维度不同的情况,可以对输入做一个线性映射变换维度,再连接后面的层。三层的残差单元对于相同数量的层又减少了参数量,因此可以拓展更深的模型。通过残差单元的组合有经典的ResNet-50,ResNet-101等网络结构。
2 前期工作
2.1 开发环境
电脑系统:ubuntu16.04
编译器:Jupter Lab
语言环境:Python 3.7
深度学习环境:tensorflow
2.2 设置GPU
如果设备上支持GPU就使用GPU,否则注释掉这部分代码
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) # 设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]], "GPU")2.3 导入数据并查看数据
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号import os, PIL, pathlib
import numpy as npfrom tensorflow import keras
from tensorflow.keras import layers,modelsdata_dir = "../data/bird_photos"
data_dir = pathlib.Path(data_dir)image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)
3 数据预处理
数据集中的种类分别为Bananaquit、Black Skimmer、Black Throated Bushtiti、Cockatoo,他们的数量分别为下表所示:
| 文件夹 | 数量 |
| Bananaquit | 166 |
| Black Skimmer | 111 |
| Black Throated Bushtiti | 122 |
| Cockatoo | 166 |
3.1 加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中。同时,我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
batch_size = 8
img_height = 224
img_width = 224train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)class_Names = train_ds.class_names
print("class_Names:",class_Names)结果输出如下所示:

3.2 可视化数据
plt.figure(figsize=(10, 5)) # 图形的宽为10,高为5
plt.suptitle("imshow data")for images,labels in train_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i+1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_Names[labels[i]])plt.axis("off")结果输出如下所示:

单独查看index为1的图像,结果如下所示,与上图结果一致。
plt.imshow(images[1].numpy().astype("uint8"))
3.3 再次检查数据
for image_batch, lables_batch in train_ds:print(image_batch.shape)print(lables_batch.shape)break
其中:
① Image_batch是形状的张量(8,224,224,3),这是一批形状为240*240*3的8张图片,最后一维的3是指彩色3通道RGB;
② label_batch是形状(8,)的张量,是这8张图片对应的标签。
3.4 配置数据集
AUTOTUNE = tf.data.AUTOTUNEtrain_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)其中:
① shuffle():打乱数据
② prefetch():预取数据,加速运行
③ cache():将数据集缓存到内存当中,加速运行
4 残差网络(ResNet)介绍
4.1 残差网络解决了什么
残差网络是为了解决神经网络隐藏层过多时,而引起的网络退化问题。退化(degradation)问题是指:当网络隐藏层变多时,网络的准确度达到饱和,然后急剧退化,而且这个退化不是由于过拟合引起的。
拓展:深度神经网络的“两朵乌云”
- 梯度弥散/爆炸
简单来讲就是网络太深了,会导致模型训练难以收敛。这个问题可以被标准初始化和中间层正规化的方法有效控制。
- 网络退化
随着网络深度增加,网络的表现先是逐渐增加至饱和,然后迅速下降,这个退化不是由于过拟合而引起的。
4.2 ResNet-50介绍
ResNet-50有两个基本的块,分别名为Conv_Block和Identity Block,其网络结果如下图所示,左边是ResNet-50的整体网络结构,中间是Conv Block的网络结构,右边是Identity Block的网络结构,ResNet-50中包含多个Conv Block和Identity Block的不同组合。

5 构建ResNet-50网络模型
此为本文重点,按照上图构建ResNet-50.
from keras import layersfrom keras.layers import Input,Activation,BatchNormalization,Flatten
from keras.layers import Dense,Conv2D,MaxPooling2D,ZeroPadding2D,AveragePooling2D
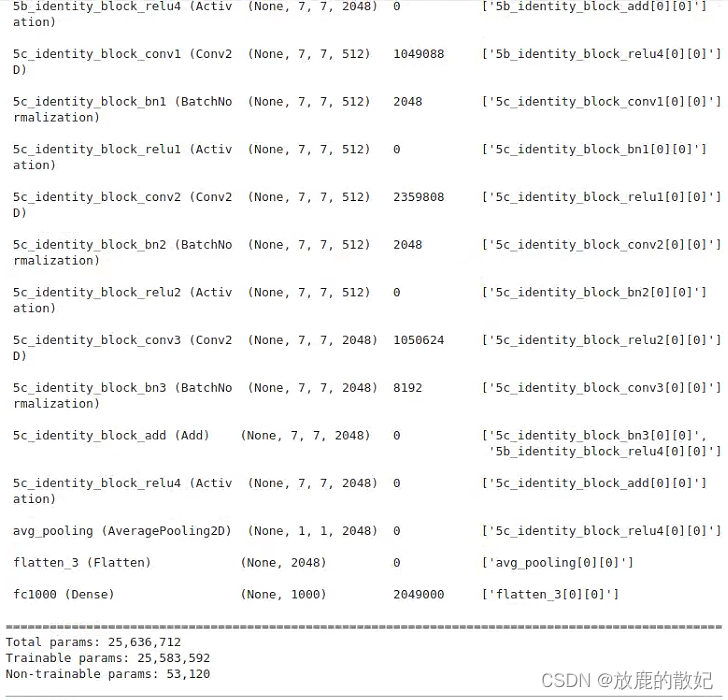
from keras.models import Modeldef identity_block(input_tensor, kernel_size, filters, stage, block):filters1, filters2, filters3 = filtersname_base = str(stage) + block + '_identity_block_'x = Conv2D(filters1, (1, 1), name=name_base + 'conv1')(input_tensor)x = BatchNormalization(name=name_base+'bn1')(x)x = Activation('relu', name=name_base+'relu1')(x)x = Conv2D(filters2, kernel_size, padding='same', name=name_base + 'conv2')(x)x = BatchNormalization(name=name_base+'bn2')(x)x = Activation('relu', name=name_base+'relu2')(x)x = Conv2D(filters3, (1, 1), name=name_base + 'conv3')(x)x = BatchNormalization(name=name_base+'bn3')(x)x = layers.add([x, input_tensor], name=name_base+'add')x = Activation('relu', name=name_base+'relu4')(x)return xdef conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2,2)):filters1, filters2, filters3 = filtersres_name_base = str(stage) + block + '_conv_block_res_'name_base = str(stage) + block + '_conv_block_'x = Conv2D(filters1, (1, 1), strides=strides, name=name_base + 'conv1')(input_tensor)x = BatchNormalization(name=name_base+'bn1')(x)x = Activation('relu', name=name_base+'relu1')(x)x = Conv2D(filters2, kernel_size, padding='same', name=name_base + 'conv2')(x)x = BatchNormalization(name=name_base+'bn2')(x)x = Activation('relu', name=name_base+'relu2')(x)x = Conv2D(filters3, (1, 1), name=name_base + 'conv3')(x)x = BatchNormalization(name=name_base+'bn3')(x)shortcut = Conv2D(filters3, (1, 1), strides=strides, name=res_name_base + 'conv')(input_tensor)shortcut = BatchNormalization(name=res_name_base+'bn')(shortcut)x = layers.add([x, shortcut], name=name_base+'add')x = Activation('relu', name=name_base+'relu4')(x)return xdef ResNet50(input_shape=[224,224,3], classes=1000):img_input = Input(shape=input_shape)x = ZeroPadding2D((3,3))(img_input)x = Conv2D(64, (7, 7), strides=(2,2), name='conv1')(x)x = BatchNormalization(name='bn_conv1')(x)x = Activation('relu')(x)x = MaxPooling2D((3,3), strides=(2,2))(x)x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1,1))x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')x = AveragePooling2D((7, 7), name='avg_pooling')(x) x = Flatten()(x)x = Dense(classes, activation='softmax', name='fc1000')(x)model = Model(img_input, x, name='resnet50')# 加载预训练模型model.load_weights("resnet50_weights_tf_dim_ordering_tf_kernels.h5")return modelmodel = ResNet50()
model.summary()运行结果如下所示(由于输出结果太长,只截取最前面和最后面部分内容):

(中间部分省略)
6 编译
在对模型进行训练之前,还需要对其设置,包括:
- 损失函数(loss):用于衡量模型在训练期间的准确率
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 指标(metrics):用于监控训练和测试步骤。下面的代码使用了准确率,即被正确分类的图像的比率。
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=1e-7)model.compile(optimizer="adam",loss='sparse_categorical_crossentropy',metrics=['accuracy'])7 训练模型
epochs = 10history = model.fit(train_ds,validation_data=val_ds,epochs=epochs)结果显示如下。设置epochs为10,训练集和测试集的准确率在第7个epoch效果最好,分别为99.34%和93.81%。

8 模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.suptitle("ResNet test")plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation loss')
plt.legend(loc='upper right')
plt.title('Training and Validation loss')
plt.show()结果显示如下:

9 预测
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize=(10, 5)) # 图形的宽为10,高为5
plt.suptitle('ResNet test')for images, labels in val_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i+1)# 显示图片plt.imshow(images[i].numpy().astype("uint8"))# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0)# 使用模型预测图片中的鸟类predictions = model.predict(img_array)plt.title(class_Names[np.argmax(predictions)])plt.axis("off")结果显示如下。由于训练的还不够,在测试的两个 Cockatoo被误判为了Black Skimmer。



![[oeasy]python0072_整数类型_int_integer_整型变量](https://img-blog.csdnimg.cn/img_convert/652b3be561f0441892198122b83757cb.png)