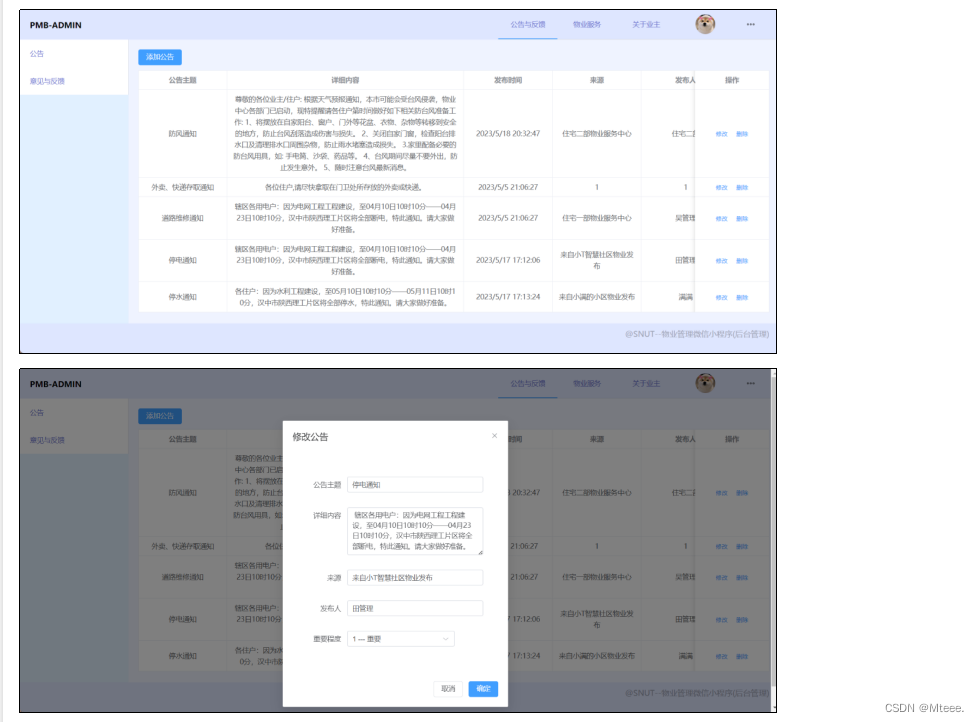
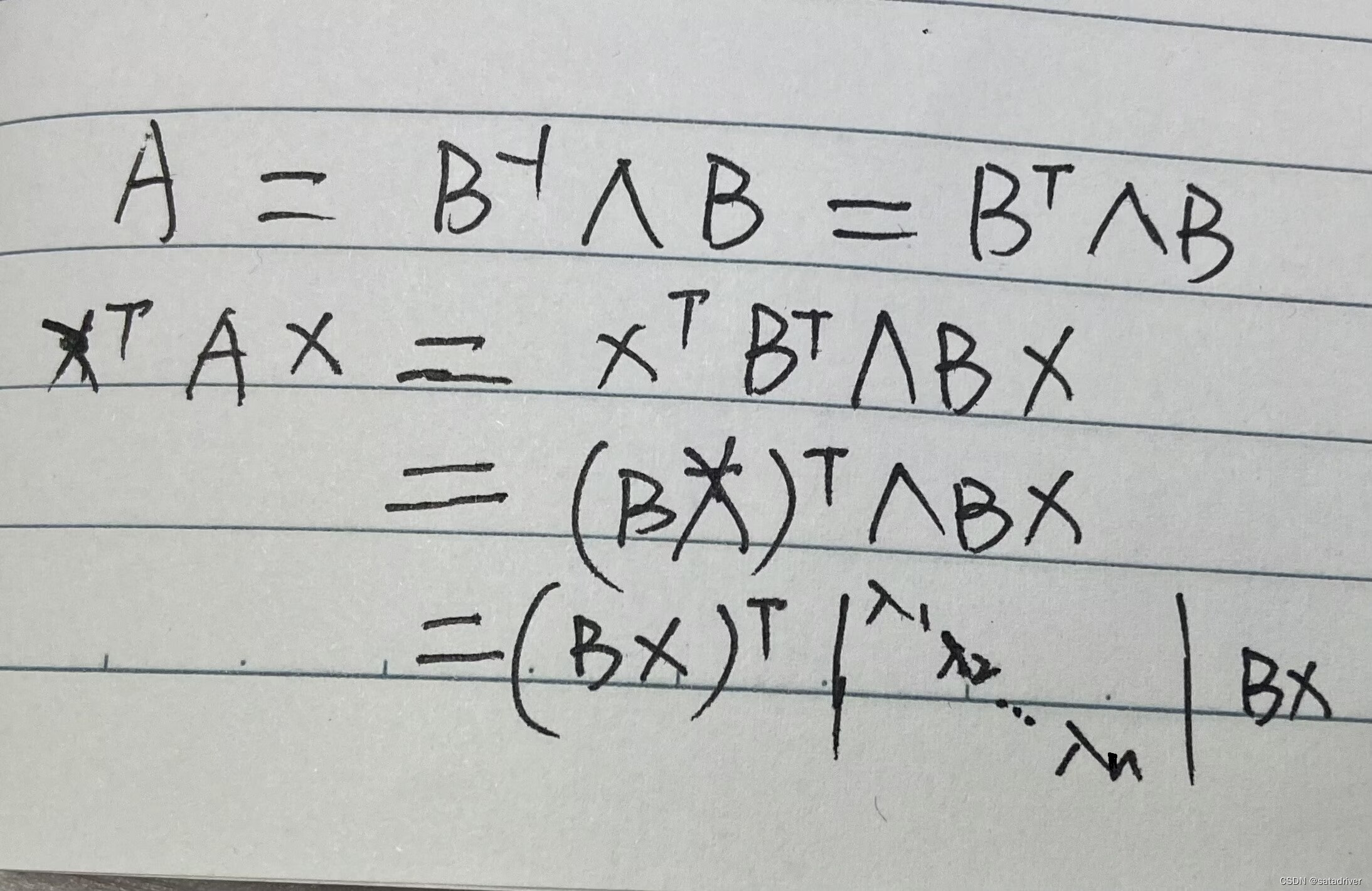目录
1、root用户密码忘记
2、SQL的分类
2.1、DQL数据查询语言
前言
2.1.1、设置别名
2.1.2、去除重复行
2.1.3、空值参与运算
2.1.4、着重号
2.1.5、显示表结构
2.1.6、算数运算符
2.1.7、比较运算符
2.1.8、逻辑运算符
2.1.9、位运算符
2.1.10、 模糊查询
2.1.11、分页
2.1.12、 多表查询
2.1.12.1、多表查询的分类
2.1.12.2、笛卡尔积
2.1.12.3、join实现内、外连接
2.1.13、聚合函数
2.1.13.1、group by
2.1.13.2 having
2.1.14、子查询
2.2、DDL数据定义语言
2.2.1、 create、show...
2.2.2、alter、drop、rename..
2.3、DML数据操作语言
2.4、DCL数据控制语言
1、root用户密码忘记
-
不适用于所有版本,新版本不能实现重置。这边建议直接重装。
重置一下密码的操作:
1、通过任务管理器或者服务管理,关掉MySQL服务进程。
2、通过命令行+特殊参数开启mysql;
mysqld --defaults-file="D:\MySql\data\my.ini" --skip-grant-tables
3、此时,mysql服务进程已经打开,并且不需要权限检查。
4、mysql -uroot 无密码登录服务器。另启动一个客户端进行。
5、修改权限表
use mysql;
update user set authentication_string=password(新密码)where user='root' and Host='localhost';
flush privileges
6、通过任务管理器,关掉mysql服务进程。
7、在此通过任务管理器,打开mysql服务。
8、即可用修改后的新密码登录。
2、SQL的分类
在一些地方会把select语句看作一类语言,DQL,因为他的使用频率非常高。
2.1、DQL数据查询语言
前言
-
select
SELECT * FROM table_name;
在这里 * 表示的是查询的是所有字段。
若是不需要查询所有的,那就在星号的位置改为所需要查询的字段名,多个的话用逗号隔开。
SELECT 字段1, 字段2,... FROM table_name;
-
单引号
mysql中查询的需要表示字符串的时候,用单引号引起来表示字符串,虽然双引号也不会错,但是在标准中是单引号。
-
大小写
虽然在语句里面写的时候大小写不敏感,比如字段名、表名、关键字、以及单引号括起来的字符串。
但是这是因为mysql不严谨的原因,在其它数据库中这方面是很严谨的,所以形成了一套使用上的规范,关键字全大写,表名、字段名等全部小写。
2.1.1、设置别名
就是在查询的时候将结果集的字段名改个名字,又称别名。
-
使用 AS
SELECT name AS new_name
FROM table_name;
-
省略 AS 使用 空格
SELECT name new_name
FROM table_name;
-
使用双引号
虽然使用单引号也可以,在标准中是双引号,单引号的话会显得很业余。
SELECT name "new_name"
FROM table_name;
第三种表面上看相比于第二中会比较多余,但是第三种情况适用于别名中有空格的情况。
2.1.2、去除重复行
SELECT DISTINCT id
FROM table_namel
加一个distinct表示将结果集中重复的行删掉,进行去重。在用的时候最好直接加载select后面,也就是所有字段的前面,因为实现的时候他会把distinct后面的字段进行整体去重,因为后面的字段去重会导致前面没去重的字段和后面去重的字段名行数不同,无法生成结果集,而产生报错。
但是在用的时候经常是对单个字段结果集进行去重,多个字段的话实际意义不大。
2.1.3、空值参与运算
若是在select中空值参与运算,那么结果都是空值,要是想解决这个问题可以在可能为空的值前面加上一个IFNUL(name, value),就说明如果为空则使用value来计算。
2.1.4、着重号
若是在使用的时候字段名、表名等跟关键字冲突。那么可以增加着重号表示该值不是关键字。
``:着重号
SELECT * FROM
order;
2.1.5、显示表结构
显示了表中字段的详细信息,使用DESCRIBLE,或者可以省略为DESC,都是可以的。
DESCRIBE table_name;
DESC table_name;
2.1.6、算数运算符
-
加 +
需要注意的是跟Java语言一样是存在隐式转换的,不一样的是加号在java中可以起到连接作用,但是在sql语句中只有加法运算。若是字符串参与运算,会自动转为数字,但若不是数字的字符形态,那么会看成0进行计算。
-
减 -
-
乘 *
-
除 / 、 div
除法的运算结果都为浮点数,不管数据类型如何结果都是小数。若是除以0那么结果为NULL。
-
模 % 、 mod
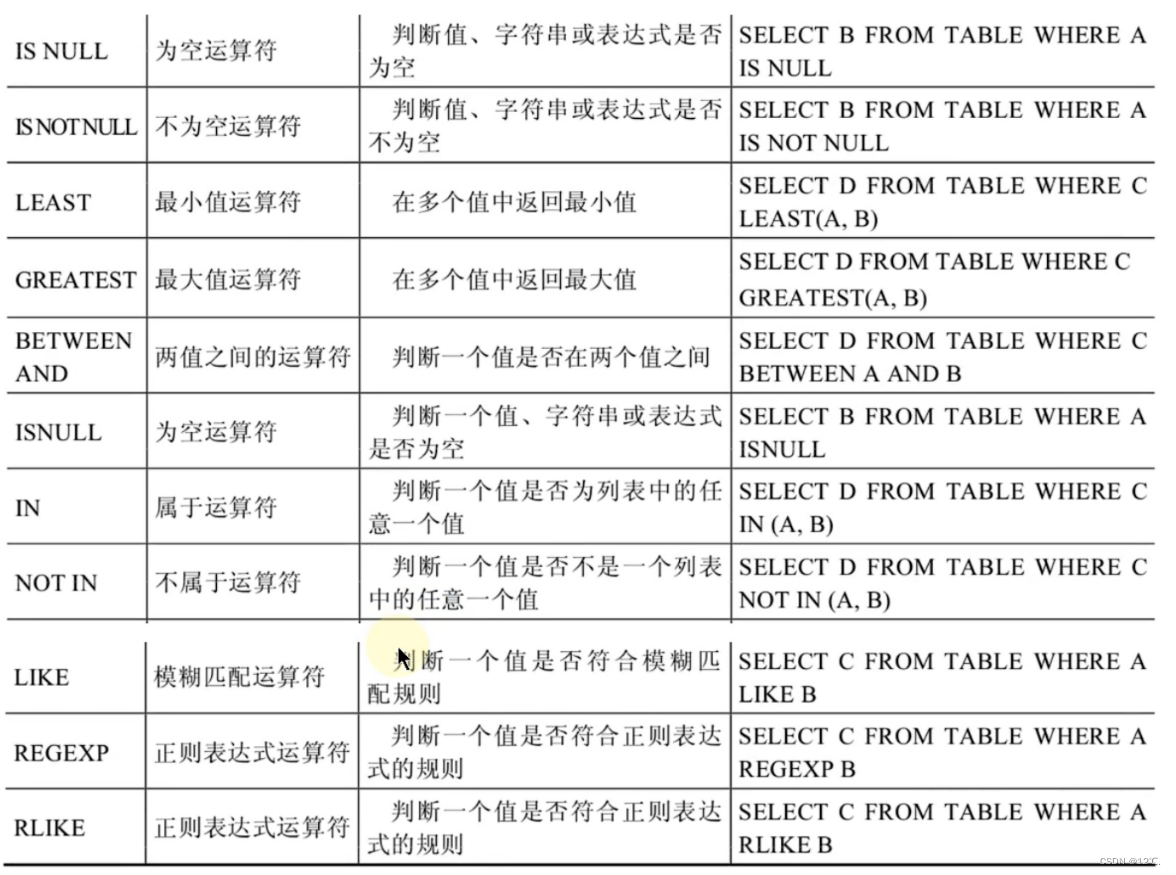
2.1.7、比较运算符
-
= 等于
在判断相等的时候,两边若是字符串和非字符串进行比较那么则会把字符串进行隐式转换,要么转为对应的整数,转换失败则为0,两边都是字符串的话则会直接进行字符串比较,不会产生隐式转换。
空值进行运算结果都是空值。
-
<=> 安全等于
它的使用跟等号大多是一样的,只有在空值的相关判断不一样,它可以进行 1 <=> null 这种判断,判断是否为空。为NULL而生。
-
<> 不等号
判断是否不相等,不相等返回1,有null参与结果就是null。
-
!=
-
<
-
<=
-
大于号
-
大于等于
2.1.8、逻辑运算符
-
非 NOT 、 !
-
且 AND、 &&
-
或 OR 、 ||
-
异或 XOR
2.1.9、位运算符
-
按位与 &
-
按位或 |
-
按位异或 ^
-
按位取反 ~
-
右移 >>
-
左移 <<
2.1.10、 模糊查询

like 的匹配规则是 右边是一个字符串,%表示0到任意个字符,_ 表示一个字符。只要符合右边的规则就算匹配成功。
2.1.11、分页
通过关键字limit,第一个参数为偏移量,第二个参数为展示的数据条数。偏移量是指从第几条数据开始,0的话就是从第一个开始,n的话就是从第n+1个开始。若是偏移量为0,则可以省略不写。limit关键字需要放在查询语句的最后。
SELECT *
FROM stable_name
LIMIT 0, 20;
指的就是从第一条数据开始展示20条数据。
8.0新版mysql中一个新的关键字OFFSET,就是偏移量会数据条数顺序反一下。
SELECT *
FROM stable_name
LIMIT 20 OFFSET 0;
2.1.12、 多表查询
-
建议:多表查询的时候每个字段前都知名其所在的表,是一个优化,但是多表共有的字段在使用的时候必须要指明其所在的表名。
2.1.12.1、多表查询的分类
1、等值查询和非等值查询
2、自连接和非自连接
-
自连接:就是自己和自己连,同一张表多次使用拼成一张表。
-
非自连接:就是不同的表拼成一张表。
3、内连接和外连接
-
内连接:合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表不匹配的行。
-
外连接:合并具有同一列的两个以上的表的行,结果集中除了包含一个表与另一个表不匹配的行之外,还查询到了左表或者右表中不匹配的行。
-
左外连接:两个表在连接过程中除了返回满足连接条件的行以外还返回了左表中不满足条件的行。
-
右外连接:两个表在连接过程中除了返回满足连接条件的行以外还返回了右表中不满足条件的行。
-
2.1.12.2、笛卡尔积
这里指的也就是交叉连接,笛卡尔积只是一个数学运算。假设我们有两个集合,为X 和 Y, 那么笛卡尔积之后就会把所有的组合情况列出来在一个表里面,组合数的个数即为两个集合中元素个数的乘积。
所以说这时候不是我们想要的表,因为有太多的错误数据,这时候只需要加一些筛选条件即可,找那种两个表共同可以代表身份的字段。
首先要加上约束条件使表正确,然后可以加一些其它的条件进行约束。
SELECT *
FROM table_1, table_2
where table_1.id = table_2.id;
如果在from 后面给表起了别名,那么在后面使用的时候只能使用表的别名。
2.1.12.3、join实现内、外连接
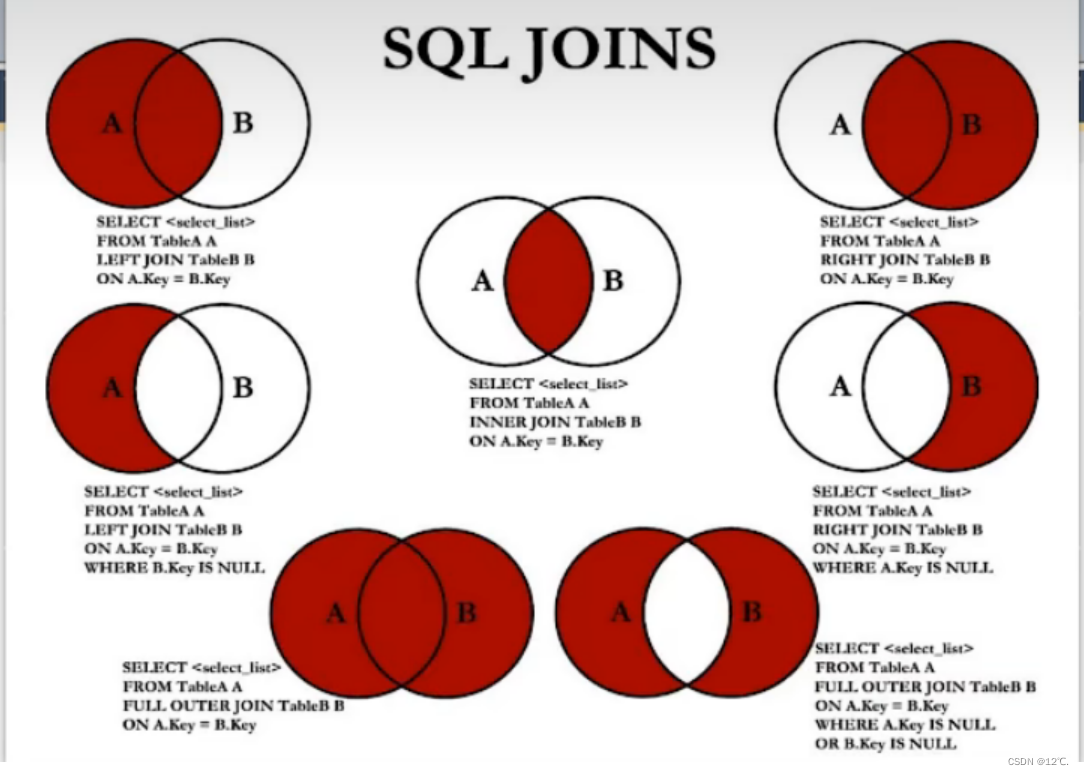
注意左连接和右连接是相对与关键字左右两边的表,left会把左边的的表全部输出,right会把右边的表全部输出。
-
中图:内连接
select * from table1 join table2 on table1.id=table2.id;
-
左上图:左外连接
select * from table1 left join table2 on table1.id=table2.id;
-
右上图:右外连接
select * from table1 right join table2 on table1.id=table2.id;
-
左中图
左中图就是把左连接的结果集中,只要左图为空的部分。
select * from table1 left join table2 on table1.id=table2.id where table1.id is null;
-
右中图
select * from table1 rightjoin table2 on table1.id=table2.id where table2.id is null;
-
左下图 满外连接
虽然这是对的,但是mysql中不支持full关键字,在其他的一些数据库中可以。
select * from table1 full join table2 on table1.id=table2.id;
sql中实现满外连接
就是把之前的左上图和右中图拼在一起,使用的使union all关键字,但是条件是他们的列数是相等的。
select * from table1 left join table2 on table1.id=table2.id union all select * from table1 rightjoin table2 on table1.id=table2.id where table2.id is null;
-
右下图
拿左中图和右中图拼在一起
select * from table1 left join table2 on table1.id=table2.id where table1.id is null union all select * from table1 rightjoin table2 on table1.id=table2.id where table2.id is null;
2.1.13、聚合函数
2.1.13.1、group by
分组函数,就是将其通过某个字段进行分组,然后统计相关信息。
结论:
-
select中出现的非组函数的字段必须声明在group by中,反之group by中声明的字段可以不出现在select中。
-
group by 声明在from后、where后、order by前, limit 前
-
单个字段分组
最好是将id也输出,这样看起来知道哪个结果对应的是哪一组。
select id , sum(salary) from table_name group by id;
-
多个字段进行分组
直接在后面加就行。
select id ,add sum(salary) from table_name group by id, add;
2.1.13.2 having
该关键字也是增加约束条件,因为where中不能出现聚合函数,但是having可以。在正常使用中,where是对行进行筛选,而having是对组进行筛选。
having可以代替where的所有工作,但是在效率上没有where快,所以在使用的时候能用where就用where。
having 必须声明在group by的后面,没有的话基本用不上having。where已经可以解决这个问题
select id, max(salary) from table_name group by id having max(salry) > 1000;
2.1.14、子查询
就是查询语句的嵌套使用
select last_name, salary from table_1 where salary > ( select salary from table_1 where last_name = 'Abel'; );
-
称谓的规范:外查询(主查询)、内查询(子查询)。
-
子查询在主查询之前一次执行完成。
-
子查询的结果被主查询使用。
-
注意事项:
-
子查询要包含在括号内
-
将子查询放在比较条件的右侧
-
单行操作符对应单行子查询,多行操作符对应多行子查询。
-
子查询的分类
-
角度一:从内查询返回的结果的条目数
-
单行子查询
-
多行子查询
-
-
角度二:内查询是否被执行多次
-
相关子查询
-
不相关查询
-
2.2、DDL数据定义语言
2.2.1、 create、show...
-
创建数据库
create database 数据库名;
-
创建数据库并指定字符集 b
create database 数据库名 character set 字符集;
-
判断是否已经存在,不存在则创建数据库
create database if not exists 数据库名;
-
创建数据表
括号里面填字段名以及字段的数据类型。if not exits 跟之前的作用是一样的可选。推荐加上。
create table if not exists table_name (
id int, name varchar(15), hire_date date
);
-
查看表结构
desc table_name
-
查看创建表的的语句结构
show create table table_name;
-
基于现有的表创建 就是把其中一个表的信息直接复制到新创建的表,只要是select语句的结果集表都行,多表单表查询的结果都可以。
create table table_2 as select id, name, salart from table_1;
2.2.2、alter、drop、rename..
-
添加一个字段
alter table table add 字段名 数据类型; //默认插在末尾
alter table table add 字段名 数据类型 first; //插在开头
alter table table add 字段名 数据类型 after 字段1; //插在字段1后面
-
修改一个字段:数据类型、长度、默认值
alter table table modify 字段名 数据类型; //只修改字段数据类型或长度
alter table table modify 字段名 数据类型 default '默认值'; // 基本上都是修改长度不会修改类型,非必要不修改类型
-
重命名一个字段
alter table 表名 change 字段名 新字段名 新数据类型; //可以不进行修改某一像
-
删除一个字段
alter table table drop column 字段名;
-
重命名表
rename table 表名 to 新表名;
alter table 表名 rename to 新表名;
-
删除表
drop table 表名;
drop table if exists 表名;
-
清空表
truncate table 表名;
2.3、DML数据操作语言
-
insert
-
一条一条的插入
// 没有指明插入的字段 insert into 表名 values (data1, data2, data3); // 数据的顺序必须跟字段的顺序严格相同。顺序不能乱
//知名插入的字段 insert into 表名(字段1, 字段2, 字段3)// 没有知名的按默认值 values (data1, data2, data3); // 数据的顺序必须跟指明的字段顺序相同。
-
多条插入
insert into 表名(字段1, 字段2, 字段3)// 没有知名的按默认值 values (data1, data2, data3),(data1, data2, data3),... ;//可以一直加下去
-
将查询结果插入
insert into 表名(字段1, 字段2, 字段3) select 字段1,字段2,字段3 // 这里的字段不用跟之前完全一样,但是数据类型要对上。 from 表名2 where 约束条件;
-
-
delete
delete 表名 where 约束条件;
-
update
可以实现批量修改,只需要合理的使用约束条件。
update 表名 set 字段1 = 新数据 // 支持运算操作 where 约束条件;// 可选
2.4、DCL数据控制语言
-
commit 提交数据。一旦执行该操作,数据就被永久的保存在了数据库中,意味着数据不可以回滚。
-
rollback 回滚数据。一旦执行之后,则可以实现数据的回滚。回滚到最近的一次commit之后。
注意:DDL和DML操作不能进行回滚,但是如果在执行操作之前执行set = autocommit = false则执行的DML操作就可以实现回滚,但是DDL不行。



![[oeasy]python0072_整数类型_int_integer_整型变量](https://img-blog.csdnimg.cn/img_convert/652b3be561f0441892198122b83757cb.png)