目录
前言
项目介绍
1.源码目录介绍
2 “调度数据库”配置
3 架构设计
3.1 设计思想
5.3.3 架构图
实战
1.服务端部署
2.执行端配置
3.任务开发
3.1 基于方法注解任务
3.2 基于api任务
3.3 分片广播任务
4.任务执行
4.1 单任务执行
4.2 子任务执行
4.3 分片广播任务执行
5.任务日志
总结
分布式定时任务调度的框架:quartz、elastic-job、xxl-job对比

前言
任务调度是java项目中常用的一种组件,可以指定任务在何时进行触发,最熟悉的是spring框架里面的quartz,较流行的有一些分布式调度组件,比如elastic-job/azkaban,都是基于quartz二次开发的,今天介绍一款分布式的任务调度器xxl-job。
项目介绍
xxl-job是一款极容易学习上手的轻量级开源分布式调度框架,分为管理端和执行端两块,管理端负责配置任务信息以及查看任务执行日志,执行端只需要配置与管理端的连接信息就可以进行具体的任务逻辑开发了,目前版本还在持续迭代中,使用简单,功能强大,具体功能特性可以看下官方介绍。废话不多说,直接进入实战把。
官网地址: 分布式任务调度平台XXL-JOB
1.源码目录介绍
- /doc :文档资料- /db :“调度数据库”建表脚本- /xxl-job-admin :调度中心,项目源码- /xxl-job-core :公共Jar依赖- /xxl-job-executor-samples :执行器,Sample示例项目(大家可以在该项目上进行开发,也可以将现有项目改造生成执行器项目)
2 “调度数据库”配置
XXL-JOB调度模块基于自研调度组件并支持集群部署,调度数据库表说明如下:
- xxl_job_lock:任务调度锁表;- xxl_job_group:执行器信息表,维护任务执行器信息;- xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;- xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;- xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;- xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;- xxl_job_user:系统用户表;
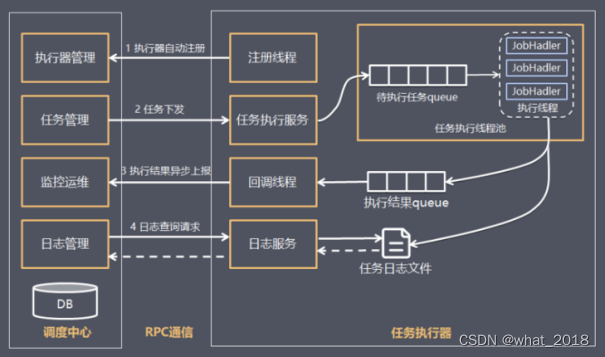
3 架构设计
3.1 设计思想
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
3.2 系统组成
- 调度模块(调度中心):
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。 - 执行模块(执行器):
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等。
5.3.3 架构图

实战
1.服务端部署
从https://github.com/xuxueli/xxl-job下载项目,用mysql客户端工具Navicat执行项目根目录下doc/db/table_xxl_job.sql文件,库名自己可以自行修改,一共8张表,如下:

1.创建一个新的spring boot项目,将下载的xxl-job-admin目录下的文件以及pom.xml文件都拷贝到新建的项目中(如果不想新建项目可以直接用下载下来的项目进行修改部署),修改application.properties中的数据库连接信息。
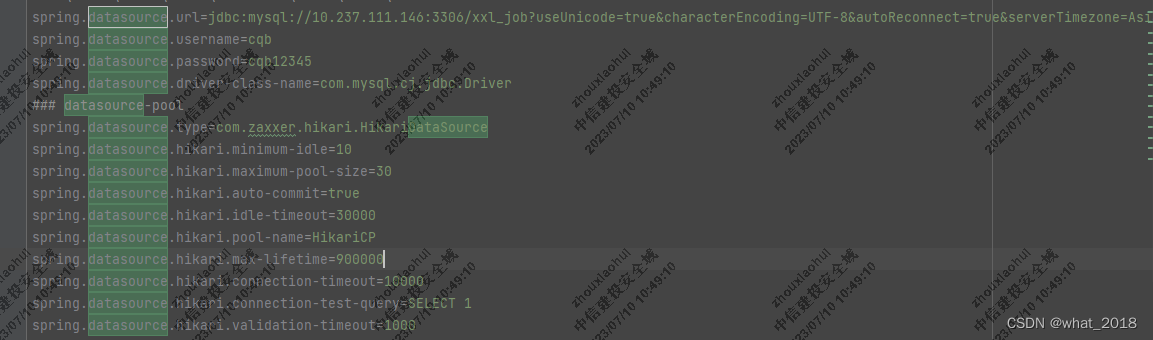
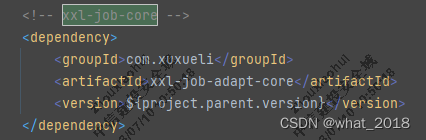
2.小编是自己创建的新项目,需要手动改了pom.xml依赖xxl-job-core的版本为2.2.0
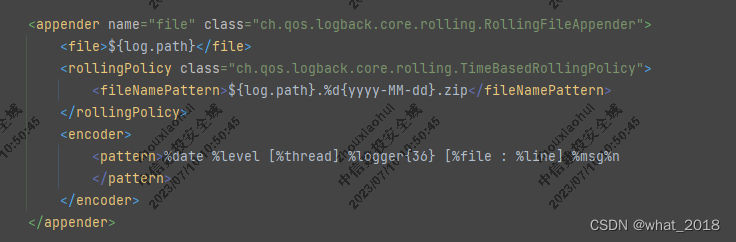
3.修改logback.xml中的日志输出路径。
好了,以上3步曲就搞定整个服务端配置了,启动项目,并访问http://localhost:8080/xxl-job-admin/ ,默认管理员账号admin/123456进行登录。 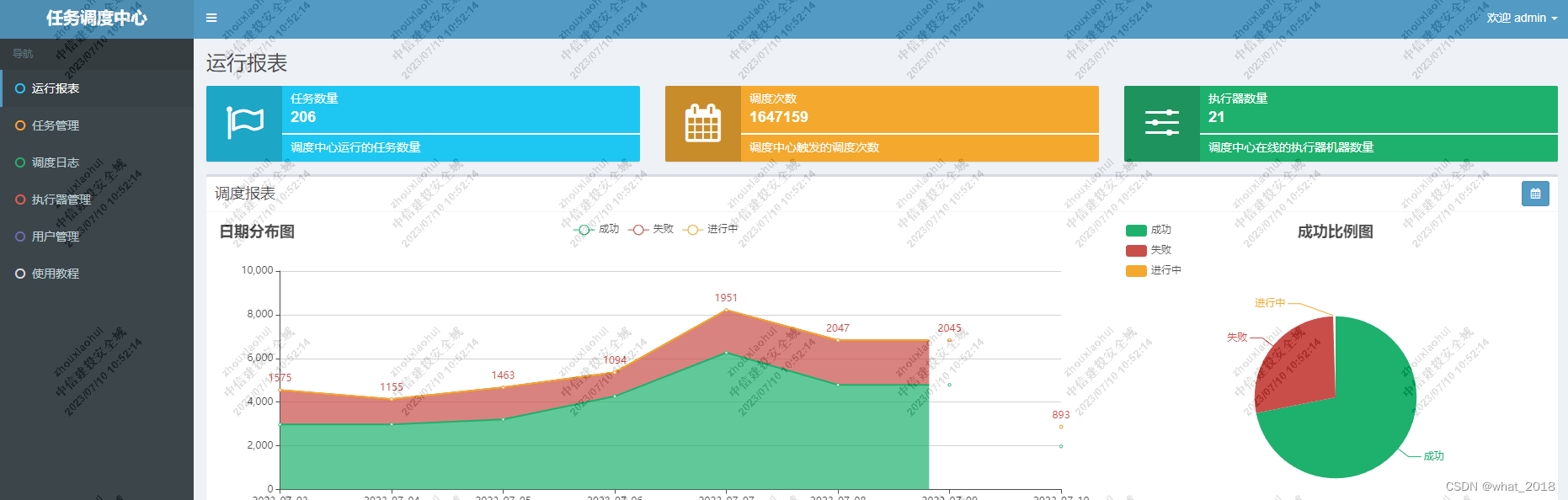 这交互,可以啊,是不是很带感。
这交互,可以啊,是不是很带感。
2.执行端配置
创建一个新的module,跟服务端一样,也需要修改下logback.xml以及在pom.xml添加xxl-job-core的依赖。
为了模拟分布式效果,小编创建了2个配置文件来区分2个执行服务。
application-9998.properties
# web port
server.port=8081
# no web
#spring.main.web-environment=false
# log config
logging.config=classpath:logback.xml### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin### xxl-job, access token
xxl.job.accessToken=### xxl-job executor appname
xxl.job.executor.appname=my-job-executor
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
xxl.job.executor.address=
### xxl-job executor server-info
xxl.job.executor.ip=
xxl.job.executor.port=9998
### xxl-job executor log-path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30application-9999.properties
# web port
server.port=8082
# no web
#spring.main.web-environment=false# log config
logging.config=classpath:logback.xml### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### xxl-job, access token
xxl.job.accessToken=### xxl-job executor appname
xxl.job.executor.appname=my-job-executor
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
xxl.job.executor.address=
### xxl-job executor server-info
xxl.job.executor.ip=
xxl.job.executor.port=9999
### xxl-job executor log-path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30细心的童鞋会发现只有server.port和xxl.job.executor.port不同,执行器服务跟spring boot一样,自带内嵌tomcat,也会暴露一个端口注册到服务端,进行高可用负载。
创建一个java config类,定义一个使用配置的XxlJobSpringExecutor执行类,如下
@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address}")private String address;@Value("${xxl.job.executor.ip}")private String ip;@Value("${xxl.job.executor.port}")private int port;@Value("${xxl.job.executor.logpath}")private String logPath;@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}配置2个启动配置,分别启动,效果如下:


完美启动2个服务,看下服务端平台是不是有这两台执行服务的注册信息。
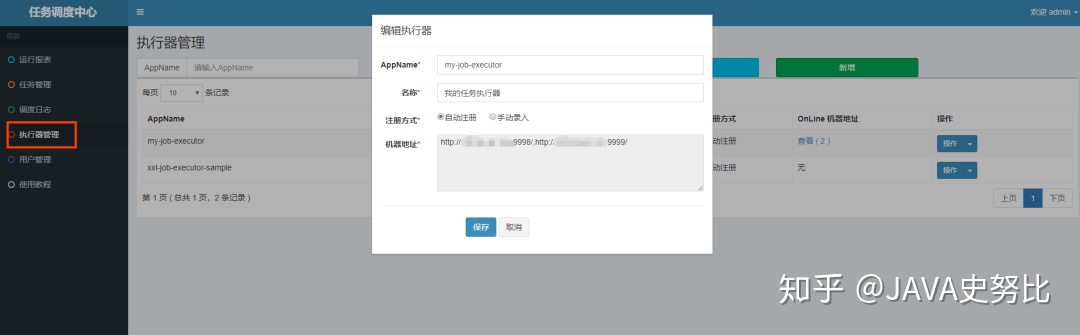
注意:为了演示,事先创建了一个执行器,AppName一定要与配置文件中xxl.job.executor.appname一致。
3.任务开发
3.1 基于方法注解任务
话不多说,直接上代码把,毕竟代码是程序员最好的交流方式。
/*** 1、注解任务*/@XxlJob(value = "myJobAnnotationHandler",init = "init", destroy = "destroy")public ReturnT<String> myJobAnnotationHandler(String param) throws Exception {XxlJobLogger.log("XXL-JOB-ANNOTATION, myJobAnnotationHandler.");log.info("my first annotation job run, param: {},port:{}",param,port);return ReturnT.SUCCESS;}public void init(){log.info("my annotation job init");}public void destroy(){log.info("my job annotation job destory");}3.2 基于api任务
@Slf4j
public class ApiJob extends IJobHandler {@Overridepublic ReturnT<String> execute(String param) throws Exception {XxlJobLogger.log("XXL-JOB-API, Hello World.");log.info("my job api run, param: {}",param);return ReturnT.SUCCESS;}
}
@PostConstructpublic void registerHandler(){XxlJobExecutor.registJobHandler("myJobApiHandler",new ApiJob());}3.3 分片广播任务
/*** 2、分片任务*/@XxlJob("myShardJobAnnotationHandler")public ReturnT<String> myShardJobAnnotationHandler(String param) throws Exception {XxlJobLogger.log("XXL-JOB-ANNOTATION, myShardJobAnnotationHandler.");log.info("my shard job run, param: {}",param);ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();log.info("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal());// 业务逻辑for (int i = 0; i < shardingVO.getTotal(); i++) {if (i == shardingVO.getIndex()) {log.info("第 {} 片, 命中分片开始处理", i);} else {log.info("第 {} 片, 忽略", i);}}return ReturnT.SUCCESS;}上面是整理的比较实用的任务创建方式,个人偏好于注解形式,方法上加一个注解就完事了。
4.任务执行
剩下的就是傻白甜的界面操作了,走起。
4.1 单任务执行
创建一个路由策略为轮询的任务,指定corn表达式,并填入JobHandler为myJobAnnotationHandler,myJobAnnotationHandler其实就是spring IOC容器中管理bean的名称,有兴趣的童鞋可以看下源码。

为了演示效果,点击执行一次并进行任务参数输入。


轮询调用执行器服务效果如下:


4.2 子任务执行
更新任务,并指定子任务id为5,多个子任务的需要以逗号隔开

执行任务结果如下

4.3 分片广播任务执行
分片任务其实就是广播功能,每次触发,每个执行服务的业务执行类都会被调用,类似于kafka里面的不同消费组都要对同一个topic进行消费一样。

执行后的效果如下


太强势了,需要定时刷新项目中的配置信息,用这个方式很完美。
5.任务日志
任务日志其实是很重要的一块,方便回溯任务历史执行情况, 以便跟踪问题并矫正丢失的业务数据

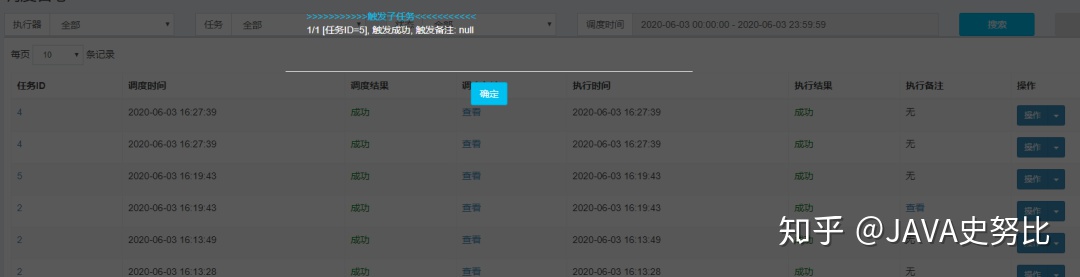
查看调度备注,父子任务调度信息非常详细,子任务可以通过执行备注查看执行情况

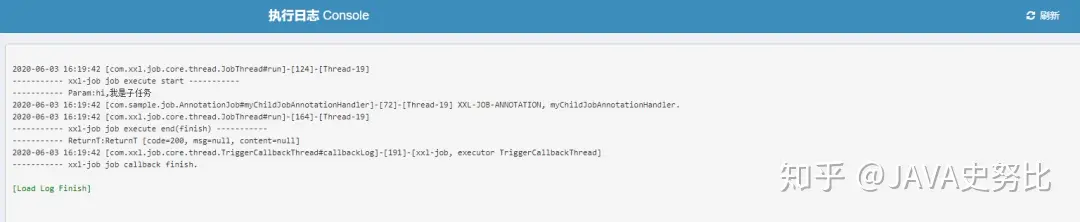
查看控制台输出,里面的日志是执行器中XxlJobLogger类打印出来的
总结
xxl-job还有很多特性,个人觉得实用的有任务超时控制/任务失败重试/任务失败告警 /邮件报警,这些都是与业务紧密相关的功能,能有效的规避生产事故而达到止损目的。
对比下之前使用过的任务调度组件,xxl-job将任务调度和执行进行解耦,大大提高了可用性和扩展性,代码的侵入性几乎没有,与spring boot无配置化,开箱即用的理念非常契合,任务调度平台可视化操作的确是爽爆了,感觉小白都可以用。
分布式定时任务调度的框架:quartz、elastic-job、xxl-job对比
| 功能 | quartz | elastic-job | xxl-job |
| HA(高可用) | 多节点部署,通过数据库锁来保证只有一个节点执行任务 | 通过zookeeper的注册和发现,可以动态添加服务器,支持水平扩容 | 集群部署 |
| 任务分片 | 不支持 | 支持 | 支持 |
| 文档完善 | 完善 | 完善 | 完善 |
| 管理界面 | 没有 | 有 | 有 |
| 难易程度 | 简单 | 较复杂 | 简单 |
| 公司 | OpenSymphony | 当当网 | 个人 |
| 缺点 | 没有管理界面不支持任务分片,不适用于分布式场景 | 需要引入zookeeper,增加系统复杂度,比较复杂 | 通过获取数据库锁的方式,保证集群中执行任务的唯一性,性能不好 |