什么是代码优化
代码优化是编译器后端的两大工作之一,弄懂它,你就掌握了一大块后端技术。
-
代码优化的目标
代码优化的目标,是优化程序对计算机资源的使用。 -
代码优化的对象
大多数的代码优化都是在 IR 上做的,而不是在前一阶段 AST 的后一阶段汇编代码上进行的,为什么呢?
- 在 AST 上做优化,抽象层次太高,含有硬件架构信息太少,难以执行很多优化算法
- 在汇编代码上进行优化会让算法跟机器相关,当换一个目标机器的时候,还要重新编写优化代码。
所以,在 IR 上是最合适的,尽量做到机器独立,又暴露出很多优化的机会。
- 代码优化的范围
从优化的范围看,分为本地优化、全局优化和过程间优化。
优化通常针对一组指令,最常用也最重要的指令组,就是基本块。基本块的基本特点是:每个基本块只能从入口进入,从最后一条指令退出,每条指令都会被顺序执行。
这种针对基本块的优化,我们叫做本地优化(Local Optimization)。
超越基本块的范围进行分析,我们需要用到控制流图(Control Flow Graph,CFG)。CFG 是一种有向图,它体现了基本块之前的指令流转关系。如果从 BB1 的最后一条指令是跳转到 BB2,那么从 BB1 到 BB2 就有一条边。一个函数(或过程)里如果包含多个基本块,可以表达为一个 CFG。
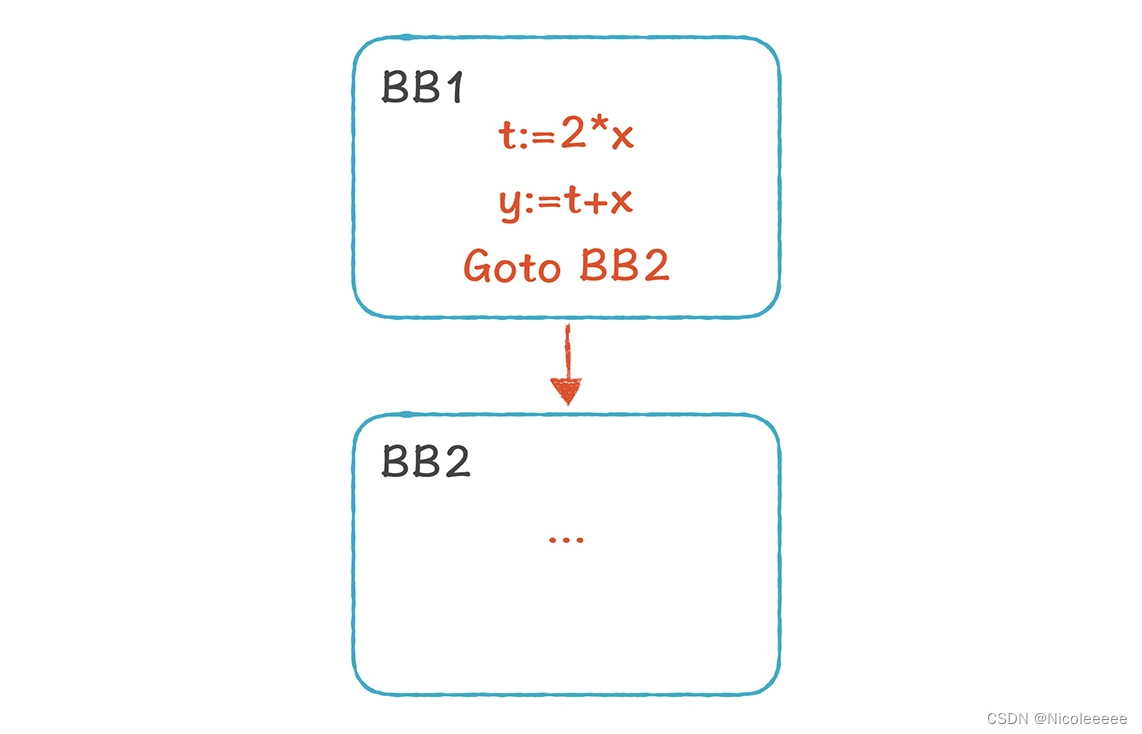
如果通过分析 CFG,我们发现 t 在其他地方没有被使用,就可以把第二行删掉。这种针对一个函数、基于 CFG 的优化,叫做全局优化(Global Optimization)。
比全局优化更大范围的优化,叫做过程间优化(Inter-procedural Optimization),它能跨越函数的边界,对多个函数之间的关系进行优化,而不是仅针对一个函数做优化。
常见的代码优化场景
- 代数优化(Algebraic Optimazation)
代数优化是最简单的一种优化,当操作符是代数运算的时候,你可以根据学过的数学知识进行优化。
比如“x:=x+0 ”这行代码,操作前后 x 没有任何变化,所以这样的代码可以删掉;又比如“x:=x0” 可以简化成“x:=0”;对某些机器来说,移位运算的速度比乘法的快,那么“x:=x8”可以优化成“x:=x<<3”。
- 常数折叠(Constant Folding)
它是指,对常数的运算可以在编译时计算,比如 “x:= 20 * 3 ”可以优化成“x:=60”。另外,在 if 条件中,如果条件是一个常量,那就可以确定地取某个分支。比如:“If 2>0 Goto BB2” 可以简化成“Goto BB2”就好了。
- 删除不可达的基本块
有些代码永远不可能被激活。比如在条件编译的场景中,我们会写这样的程序:“if(DEBUG) {…}”。如果编译时,DEBUG 是一个常量 false,那这个代码块就没必要编译了。
- 删除公共子表达式(Common Subexpression Elimination)
下面这两行代码,x 和 y 右边的形式是一样的,如果这两行代码之间,a 和 b 的值没有发生变化(比如采用 SSA 形式),那么 x 和 y 的值一定是一样的。
- 拷贝传播(Copy Propagation)和常数传播(Constant Propagation)
下面的示例代码中,第三行可以被替换成“z:= 2 * x”, 因为 y 的值就等于 x,这叫做拷贝传播。
x := a + b
y := x
z := 2 * y
如果 y := 10,常数 10 也可以传播下去,把最后一行替换成 z:= 2 * 10,这叫做常数传播。再做一次常数折叠,就变成 z:=20 了。
- 死代码删除(Ded code elimination)
在上面的拷贝传播中,如果没有其他地方使用 y 变量了,那么第二行就是死代码,就可以删除掉,这种优化叫做死代码删除。
一个优化可能导致另一个优化,比如,拷贝传播导致 y 不再被使用,我们又可以进行死代码删除的优化。所以,一般进行多次优化、多次扫描。
整一个优化过程
- 我们首先做一个正向扫描,进行可用表达式分析,建立可用表达式的集合,然后参照这个集合替换公共子表达式,以及做拷贝传播。
- 接着,我们做一个反向扫描,进行活跃性分析,建立活变量的集合,识别出死变量,并依据它删除给死变量赋值的代码。
- 上述优化可能需要做不止一遍,才能得到最后的结果。
可用表达式分析和活跃性分析是本地优化时的两个关键算法。这些算法都是由扫描方向、值、转换函数和初始值这四个要素构成的。
- D(方向)。是朝前还是朝后遍历。
- V(值)。代码的每一个地方都要计算出一个值。可用表达式分析和活跃性分析的值是一个集合,也有些分析的值并不是集合,在下一讲你会看到这样的例子。
- F(转换函数,对 V 进行转换)。比如,在做可用表达式分析的时候,遇到了“c := b”时,可用表达式的集合从{a := b, c := a + b}转换成了{a := b, c := b}。这里遵守的转换规则是:因为变量 c 被重新赋值了,那么就从集合里,把变量 c 原来的定义去掉,并把带有 c 的表达式都去掉,因为过去的 c 已经失效了,然后,把变量 c 新的定义加进去。
- I(初始值,是算法开始时 V 的取值)。做可用表达式分析的时候,初始值是空集。在做活跃性分析的时候,初始值是后面代码中还会访问的变量,也就是活变量。
拷贝传播如何实现
如果一个类是从 Value 继承的,意味着它定义了一个值。另一个类是 User 类,函数和指令也是 User 类的子类,也就是说,在函数和指令中,可以使用别的地方定义的值。
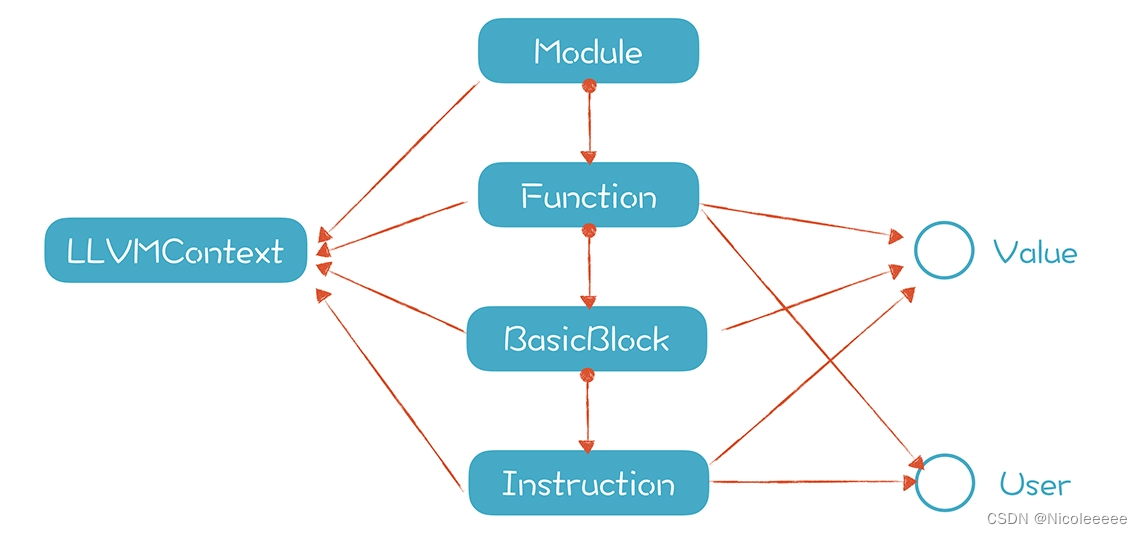
这两个类是怎么帮助到优化算法中的呢?
在 User 中,可以访问所有它用到的 Value,比如一个加法指令(%c = add nsw i32 %a, %b)用到了 a 和 b 这两个变量。
而在 Value 中,可以访问所有使用这个值的 User,比如给 c 赋值的这条指令。
所以,你可以遍历一个 Value 的所有 User,把它替换成另一个 Value,这就是拷贝传播。
接下来,我们看看如何用程序实现 IR 的优化。
在 LLVM 内部,优化工作是通过一个个的 Pass(遍)来实现的,它支持三种类型的 Pass:
- 一种是分析型的 Pass(Analysis Passes),只是做分析,产生一些分析结果用于后序操作。
- 一些是做代码转换的(Transform Passes),比如做公共子表达式删除。
- 还有一类 pass 是工具型的,比如对模块做正确性验证。你可以查阅 LLVM 所支持的各种 Pass。
LLVM 所支持的 各种 Pass
下面的代码创建了一个 PassManager,并添加了两个优化 Pass:
// 创建一个PassManager
TheFPM = std::make_unique<legacy::FunctionPassManager>(TheModule.get());// 窥孔优化和一些位计算优化
TheFPM->add(createInstructionCombiningPass());// 表达式重关联
TheFPM->add(createReassociatePass());TheFPM->doInitialization();