在进行数据标注时,有一些重要的问题需要注意,以确保标注的数据质量和可用性。以下是一些建议和注意事项:
-
明确定义标签: 确保标签的含义和定义是清晰明确的。标签是对数据的关键描述,因此其含义应该在整个团队中共享和理解。
-
一致性: 保持标注的一致性非常重要。不同标注者之间的一致性可以通过提供明确的标注指南、 Schulze 等方法进行训练,以及定期进行互相之间的交叉检验来确保。
-
分配标注者: 如果可能,分配多个标注者来独立标注相同的数据,然后计算它们之间的一致性。这有助于减轻主观性和减小人为错误的可能性。
-
标注平台和工具: 选择适当的标注平台和工具,这可以极大地简化标注的流程,并提高标注效率。一些流行的标注工具包括Labelbox、Supervisely、VGG Image Annotator(VIA)等。
-
处理不确定性: 在标注中,有时标注者可能遇到不确定性的情况,这可能由于数据模糊、模糊或不明确。在这种情况下,建议记录这种不确定性,并在可能的情况下提供进一步的上下文。
-
数据偏差: 注意数据集中是否存在标签分布的偏差。确保标注涵盖了整个数据集,并防止模型在某些标签上过度拟合。
-
质量控制: 实施质量控制步骤,例如审核标注,以确保标注的准确性和质量。这可能涉及到将一小部分数据样本交叉检查给其他标注者或专家。
-
保护隐私: 如果数据中包含敏感信息,确保标注过程中采取了适当的隐私保护措施,如数据脱敏或匿名化。
-
版本控制: 管理标注版本,以便能够跟踪标注的演变。这对于长期项目和数据集的可维护性非常重要。
-
持续学习: 标注者可能会在标注的过程中学到更多关于数据和任务的信息。建议建立反馈循环,以便标注者能够不断学习和改进标注质量。
通过关注这些问题,可以提高标注数据的质量,从而提高训练模型的效果。

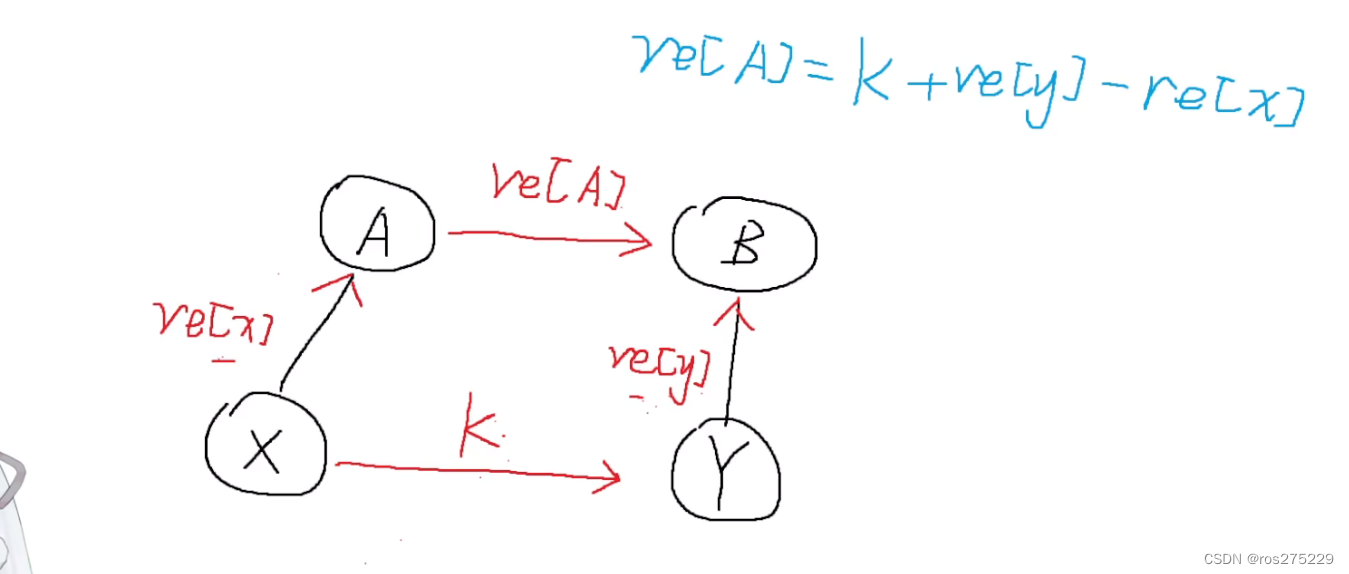
上图是一个数据标注的示例