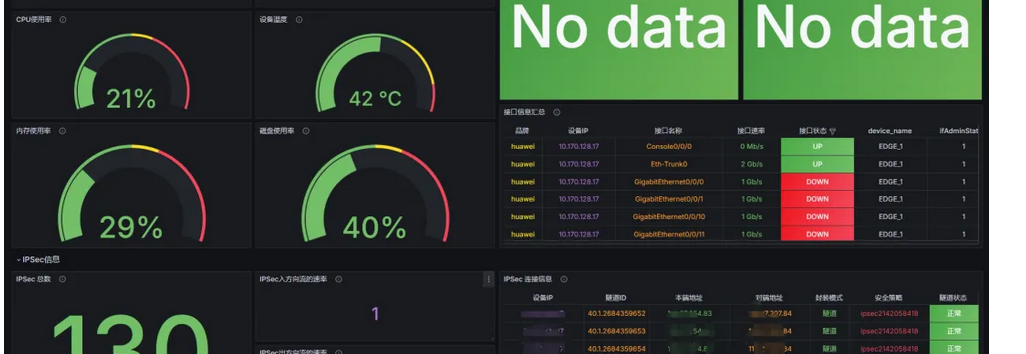
论文链接:HoME: Hierarchy of Multi-Gate Experts for Multi-Task Learning at Kuaishou
背景
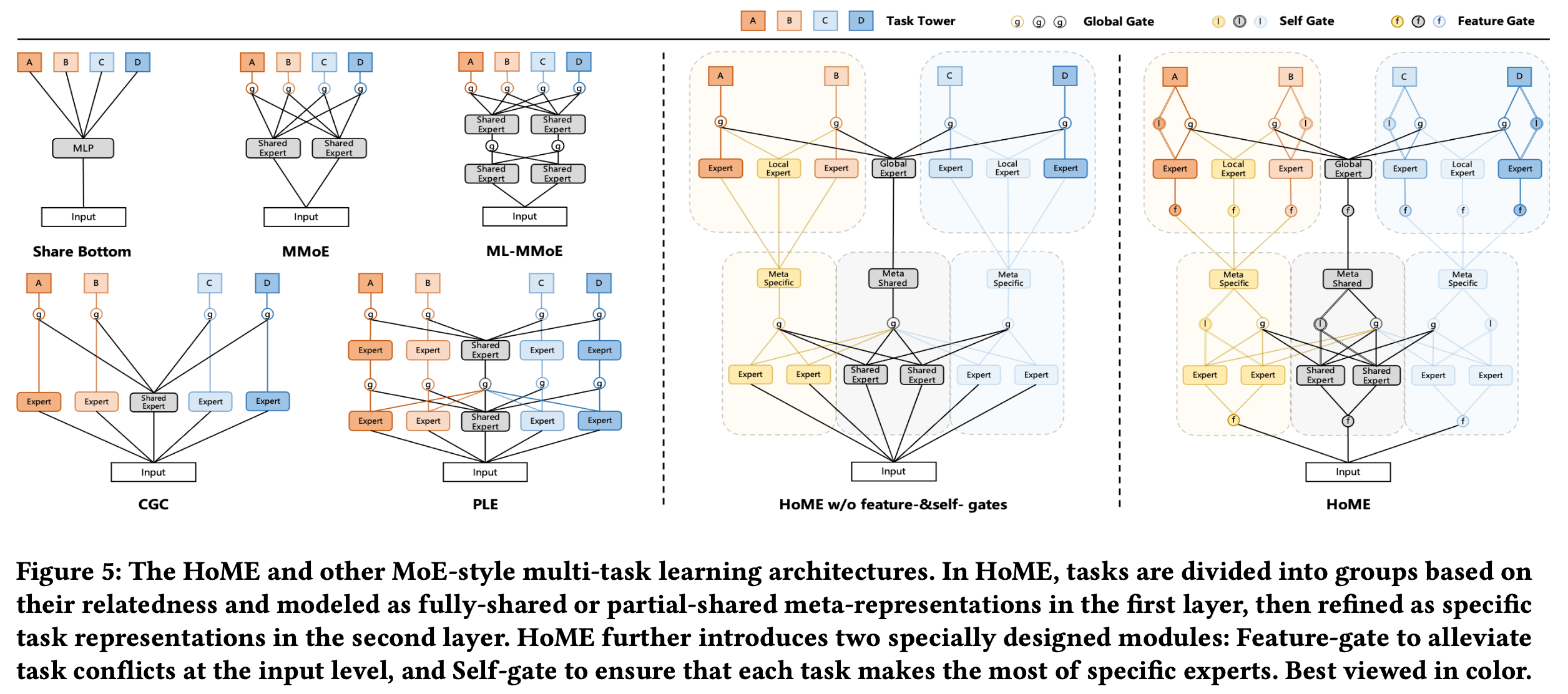
论文指出现在的MMOE/PLE模型存在以下几个问题:
1. 专家崩溃:专家的输出分布存在显着差异,并且一些专家使用 ReLU 的零激活率超过 90%,使得门网络很难分配公平的权重来平衡专家
2. 专家退化:一些共享专家只被一项任务占据,这表明共享专家失去了他们的能力,而是退化为一些特定专家
3. 专家欠拟合(针对特定专家):在我们的服务中,我们有数十个行为任务需要预测,但我们发现一些数据稀疏的预测任务往往会忽略其特定专家,并为共享专家分配较大的权重。原因可能是共享专家可以从密集任务中感知更多的梯度更新和知识,而特定专家由于其稀疏行为很容易陷入欠拟合。
技术方案
Expert归一化和Swish机制
作者研究发现,造成专家崩溃的本质原因是因为不同专家输出尺度差异过大,为了解决问题,论文采用了在专家层之后加BN层,并把激活函数替换成Swish激活函数:
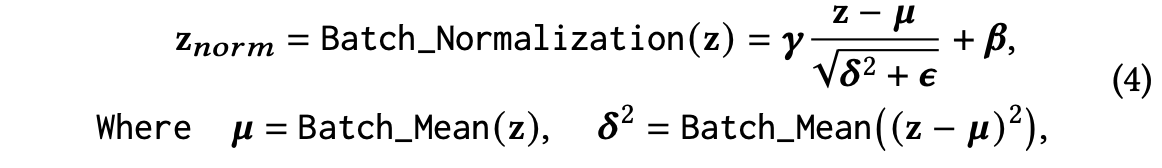
![]()
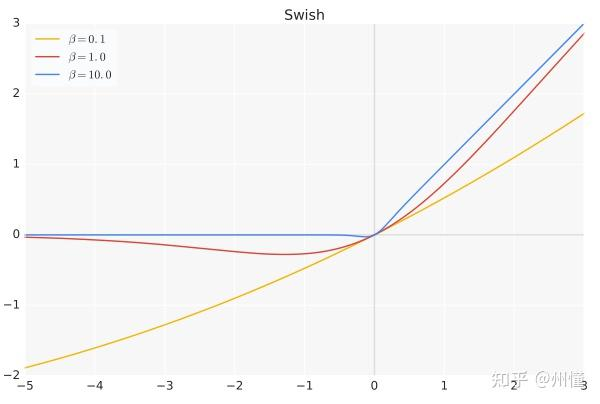

对比一下BN + Swish 和直接用Dice的区别:
BN+Swish:f(s) = BN(s) * sigmoid(BN(s))
Dice:f(s) = s * p(s) = s * sigmoid(BN(s)) + αs * (1 - sigmoid(BN(s)))
层次掩码机制
针对一些共享Expert退化成只起到私有Expert作用的情况, 作者提出基于任务相关性的先验知识来缓解这一问题,以快手短视频推荐为例, 预测任务可以大体分成两类:
- 被动观看的时长类任务: 如完播、长播、快划等
- 主动交互的互动类任务: 如点赞、评论、收藏等
更加这个划分,作者把模型分为两层:
第一层学习更粗粒度的表示,别提取:(1)时长子类别内共享知识;(2)全局共享知识; (3)互动子类目内共享知识
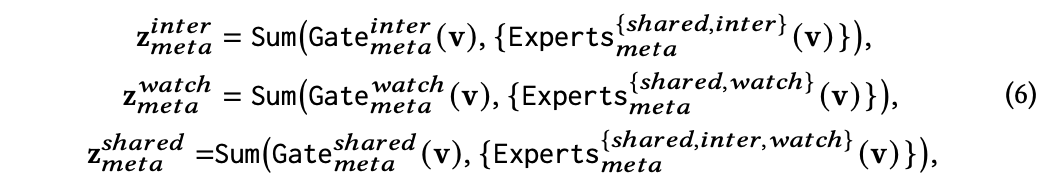
第二层在第一层粗粒度表示基础上,进行正常的多任务预测,以点击率和有效播放两个目标为例, 第2阶段的过程描述如下:

Feature-gate与Self-gate机制
对于数据稀疏任务存在的Expert欠拟合的问题, 作者提出了两种门控机制来确保这些任务能够获得适当的梯度以最大化其有效性。
Feature-gate机制
对于feature-gate,其目的是为不同的任务专家生成不同的输入特征表示,以缓解所有专家共享相同的输入特征时的潜在梯度冲突
Self-gate机制
除了专家输入层面引入feature-gate,作者还在级联层次的各专家输出层面(包含第一层和第二层)添加了一个基于残差思想的self-gate, 比如下图所示的第二层级中, 红圈的I就表示self-gate。self-gaet是用于确保顶层梯度可以有效地传递到底层, 并只关注其特定专家的输出。
参考资料
快手HoME: 推荐系统多任务学习MoE机制的里程碑式改进
快手HOME——PLE的进一步升级