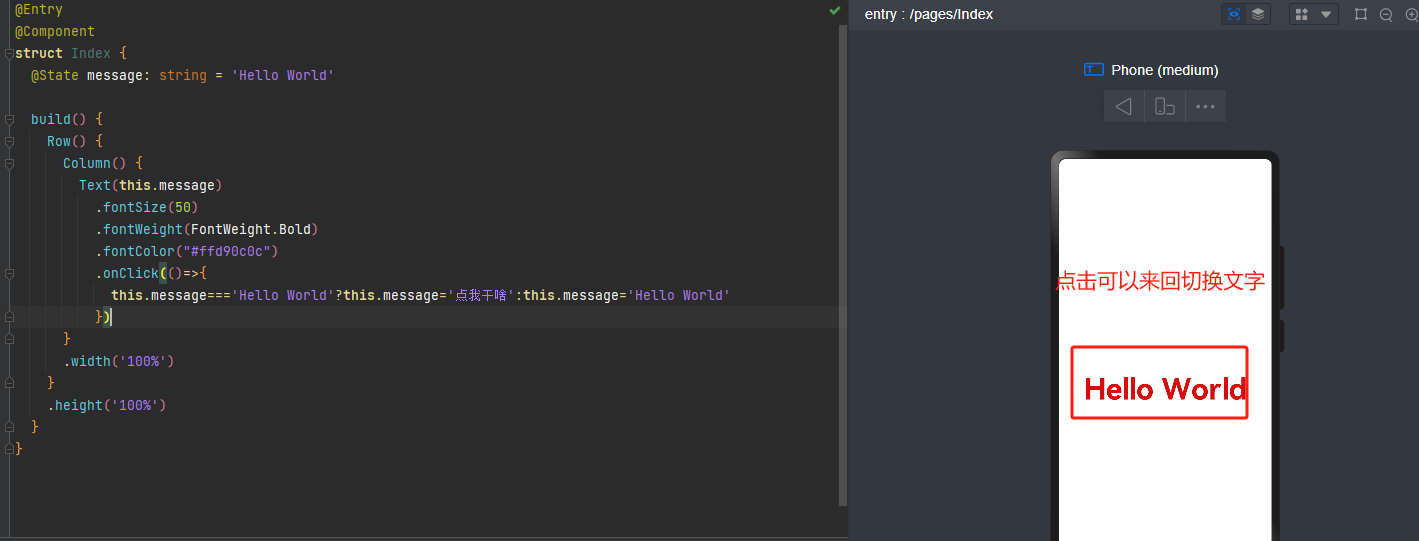
可以使用XPath中的normalize-space函数来定位文本中含有空格的元素。主要包含normalize-space(.)、normalize-space(text())两种用法:
- 使用
normalize-space(.)的例子:
<root><element>Hello, world!</element>
</root>
在上述 XML 文档中,如果你想获取 <element> 元素的内容并规范化其中的空白字符,你可以使用以下 XPath 表达式:
/child::root/child::element/normalize-space(.)
这将返回字符串 “Hello, world!”。
- 使用
normalize-space(text())的例子:
<root><element>Hello,<span>world!</span></element>
</root>
在这个例子中,如果你尝试使用 normalize-space(text()),如下所示:
/child::root/child::element/normalize-space(text())
这可能会导致错误或意外的结果,因为在当前上下文中,text() 返回了一个包含两个文本节点(“Hello,” 和 "\n ")的节点集。由于 normalize-space 函数期望一个单一的字符串作为参数,因此它可能无法正确处理这个情况。
相反,你应该使用 normalize-space(.) 或者迭代每个子文本节点并分别应用 normalize-space() 函数:
/child::root/child::element/normalize-space(.)
或者
/child::root/child::element/text()/normalize-space()
这两种方式都将返回预期结果:“Hello,”。
下面使用项目中真实案例说明:
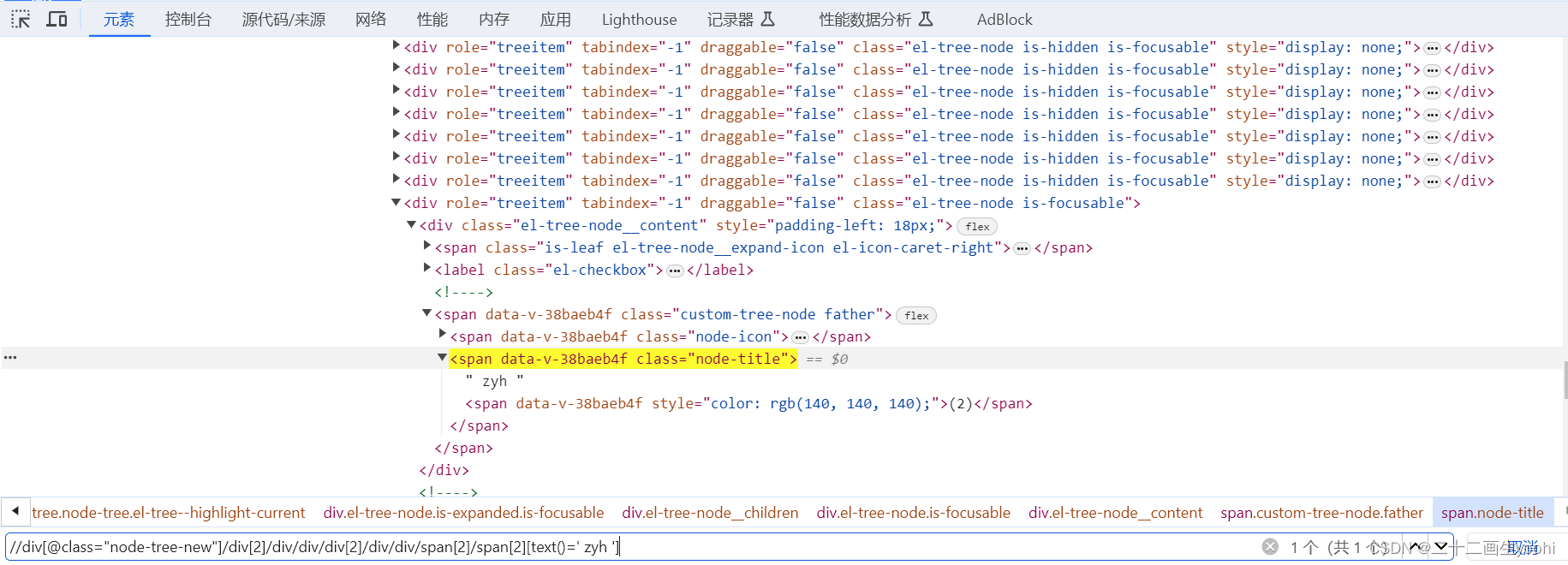
可以使用text()进行定位,但是必须和该元素文本内容完全一致才可定位(包含空格)
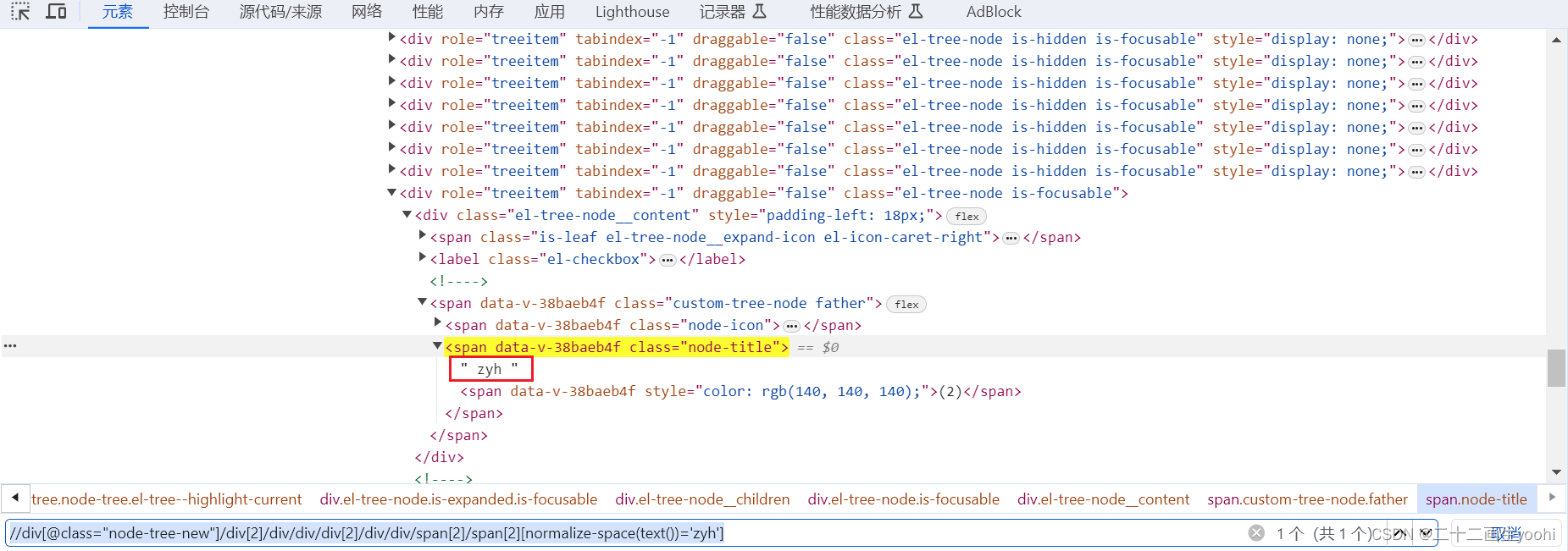
使用normalize-space(text())不用考虑文本前后包含了多少空格,只用考虑文本内容即可。