目录
- 简介
- 实验测试
- 显存占用问题
- GPU占用率波动问题
- num_work不是越大越好
- 总结
本专栏为深度学习的一些技巧,方法和实验测试,偏向于实际应用,后续不断更新,感兴趣童鞋可关,方便后续推送
简介
在PyTorch中使用多个GPU进行模型训练时,各个参数和指标之间存在一定的关系。以下是对这些参数和指标的详细说明和举例:
GPU显存(GPU Memory):
GPU显存是限制模型训练规模的关键因素。当使用多个GPU进行训练时,每个GPU都会分配一部分显存用于存储中间变量、梯度、权重等。GPU显存的使用量取决于模型的复杂度、批量大小(batch size)以及数据类型等因素。
举例:假设我们使用两个GPU(GPU 0和GPU 1)进行训练,每个GPU的显存为12GB。若批量大小为32个样本,模型复杂度为中等,则每个GPU可能需要大约4GB的显存。如果批量大小增加到64个样本,每个GPU可能需要大约8GB的显存。
2. GPU利用率(GPU Utilization):
GPU利用率表示GPU在训练过程中的繁忙程度。高利用率表示GPU在大部分时间都在进行计算操作,而低利用率则表示GPU有空闲时间未被充分利用。
举例:假设我们使用两个GPU进行训练,其中一个GPU的利用率达到了90%,而另一个只有50%。这可能意味着负载分配不均衡,可能影响训练速度和稳定性。可以通过调整批量大小(batch size)或数据并行来优化GPU利用率。
3. Batch Size:
批量大小是每次更新模型权重时使用的样本数量。增加批量大小可以加速训练,但也需要更多的GPU显存。合理选择批量大小需要在速度和内存之间取得平衡。
举例:假设我们使用两个GPU进行训练,批量大小为64个样本。如果模型复杂度较高,可能会导致GPU显存不足,需要减小批量大小或增加GPU数量。如果批量大小过小,则可能无法充分利用GPU的计算能力,导致训练速度变慢。
4. Pin Memory:
Pin Memory是一种将数据固定在内存中的技术,以减少数据在CPU和GPU之间的传输时间。在PyTorch中,通过设置torch.cuda.pin_memory_device()来使用Pin Memory。该选项对于需要频繁访问小块数据的深度学习模型特别有用。
举例:当我们使用多个GPU进行训练时,可以将数据加载到CPU内存中,然后使用Pin Memory技术将其固定在GPU内存中,以减少数据传输开销。这对于需要频繁访问小块数据的深度学习模型特别有用。
5. Num Workers(Number of Workers):
Num Workers是指在数据加载过程中用于并行处理数据加载任务的线程数。增加Num Workers可以加速数据加载,但也需要更多的CPU资源。
举例:假设我们使用两个GPU进行训练,Num Workers设置为2。这将使数据加载并行执行,加速数据加载过程。但是,如果CPU资源有限或数据集较小,增加Num Workers可能不会带来明显的加速效果,反而可能导致资源浪费。
6. CPU利用率(CPU Utilization):
CPU利用率表示CPU在训练过程中的繁忙程度。高利用率表示CPU在大部分时间都在进行计算操作或数据预处理,而低利用率则表示CPU有空闲时间未被充分利用。
举例:假设我们使用两个GPU进行训练,其中一个CPU核心的利用率达到了90%,而另一个只有50%。这可能意味着数据处理或数据预处理不均衡,可能影响训练速度和稳定性。可以通过调整Num Workers或优化数据处理流程来优化CPU利用率。
实验测试
老规矩我们还是拿MMDetection进行测试
显存占用问题
深度学习中神经网络的显存占用,往传有如下公式:
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用
因此我做以下测试:
batch_size为1:

batch_size为3:

batch_size为32:

不难计算出显存不是和batch-size简单的成正比,上述公式也不能准确描述,尤其是模型自身比较复杂的情况下:比如全连接很大,Embedding层很大.但在至少可以确定batch-size和显存占用直接相关
GPU占用率波动问题
这个是Volatile GPU-Util表示,当没有设置好CPU的线程数时,这个参数是在反复的跳动的,0%,50%,80%,99%,0%。这样停息1-2 秒然后又重复起来。其实是GPU在等待数据从CPU传输过来,当从总线传输到GPU之后,GPU逐渐起计算来,利用率会突然升高,但是GPU的算力很强大,0.5秒就基本能处理完数据,所以利用率接下来又会降下去,等待下一个batch的传入。因此,这个GPU利用率瓶颈在内存带宽和内存介质上以及CPU的性能上面。最好当然就是换更好的四代或者更强大的内存条,配合更好的CPU。
设置batch_size=1,num_work为1时,时常出现GPU占用率为0的情况

设置batch_size=1,num_work为8时,GPU占用率为0的情况明显变少

所以num_work可以提高GPU的占用率,不至于时常处于等待数据的空闲状态,因此当然可以提高训练速度,见我的前面博客
num_work不是越大越好
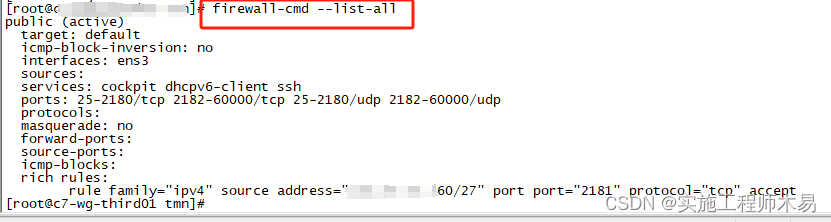
通常可以根据cpu和核数去设置num_work,查看cpu核数的命令
lscpu

图中的CPU(s)就是cpu的核数
实验过程中发现num_work过高导致save权重及其缓慢,num_work不是越大越好。因为越大,虽然线程多了,但是切分到每一个线程消耗也大了,所以会增加CPU的负荷,从而降低对GPU的利用。num_workers数一般和batch_size数配合使用。
设置num_work为32时:


数据读取时间num_work为16时反倒快于num_work为32
总结
要提高GPU的显存和利用率以加快模型的训练速度,可以从以下几个方面进行考虑:
batch_size:Batch Size是每次更新模型权重时使用的样本数量。选择适当的batch size可以提高GPU的显存利用率和训练速度。如果batch size过小,会导致频繁的数据传输开销,降低GPU的利用率。而如果batch size过大,可能会导致GPU显存不足,需要减小批量大小或增加GPU数量。因此,需要根据模型复杂度、显存限制和数据集大小等因素来选择合适的batch size。
使用多个GPU:通过使用多个GPU并行计算,可以显著提高模型的训练速度。可以使用torch.nn.DataParallel或torch.nn.parallel.DistributedDataParallel等包装器来实现数据并行。在使用多个GPU时,需要注意合理分配工作负载,避免负载不均衡导致训练速度下降。
使用Pin Memory技术:对于需要频繁访问小块数据的深度学习模型,可以使用Pin Memory技术。Pin Memory可以将数据固定在GPU内存中,减少数据在CPU和GPU之间的传输时间,从而提高训练速度。在使用Pin Memory时,需要注意合理管理数据生命周期,避免内存泄漏或过度占用。
多线程数据读取:合理选择num_work,保证数据流动的连续性,避免因等待GPU完成计算而造成不必要的延迟。
还有使用混合精度训练:混合精度训练是指同时使用半精度(FP16)和单精度(FP32)数据进行训练。这种方法可以减少显存的使用量,并提高GPU的利用率。通过将权重和梯度等参数存储为FP16格式,可以减少显存的使用。然而,需要注意的是,混合精度训练可能会引入数值稳定性和精度损失的问题。这一部分我后续会进行实验验证,敬请期待