个人的一点经验和总结,希望能帮助到大家。有不对的地方请留言和指正!
langchain-GLM是什么
langchain-GLM是一个本地知识库应用解决方案,支持以cli、web、api方式提供以本地知识库或在线资源为知识素材的对话服务,对中英文场景对话支持友好。它由LLM(大语言模型,例如:ChatGLM-6B、星火、文心一言)和Embedding 模型组成,支持私有化部署。
原理
- 加载文件
- 读取文本
- 文本分割
- 文本向量化(将文本表示成计算机可以识别的实数向量的过程)
- 问句向量化(问句向量化是自然语言处理中的一种技术,其目标是将问句转化为计算机可以解析的向量形式。这一过程通常发生在文本向量化之后,作为更复杂任务如问题回答、对话系统等的一部分。)
- 在文本向量中匹配出与问句向量最相似的
top k个 - 匹配出的文本作为上下文和问题一起添加到
prompt中 - 提交给
LLM生成回答。
为什么要选择langchain
优点
- 支持私有化部署
- 几乎支持国内市面上开源的在线或本地模型
- 消费级GPU或者CPU上即可安装并运行
- 支持api方式提供服务,解决了大模型对话嵌入自有应用难的问题
缺点
- 大多数家用电脑配置不够运行大模型。需要 money 购买GPU
- 国内下载镜像难。模型镜像大,好几十G
解决了什么问题
稍微对大模型运行原理了解的童靴们可能都了解,大模型也不是生来什么领域的知识都懂的。需要给它喂数据,不断训练。
企业要想用大模型高效利用数据,把企业数据给大模型,那肯定是不可能的。
这个时候大模型本地部署,私有数据自己管控就是必要条件了。恰恰langchain就解决了这个问题。
langchain-GLM版本0.1.* 和0.2.*区别
- 安装方式:0.1.* 既支持docker方式部署,也支持本地加载模型,0.2.*版本目前仅支持从本地加载模型方式部署;
- 功能上:0.2.*版本支持LLM 更加全面。既包含在线开源大模型,也支持本地模型。
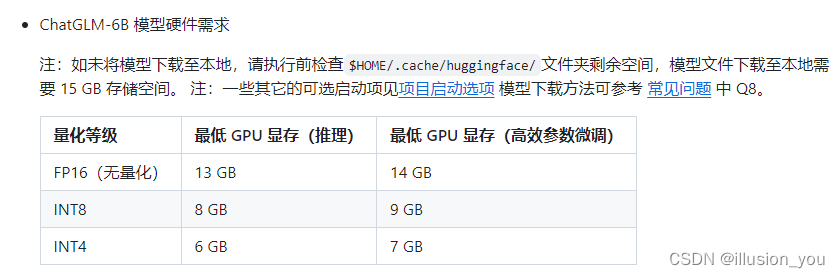
硬件、软件配置以及私有化部署方式
硬件配置要求:

- python >=3.10
第一种:安装0,1.*版本【建议使用docker方式部署】:
1.运行环境安装
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit-base
sudo systemctl daemon-reload
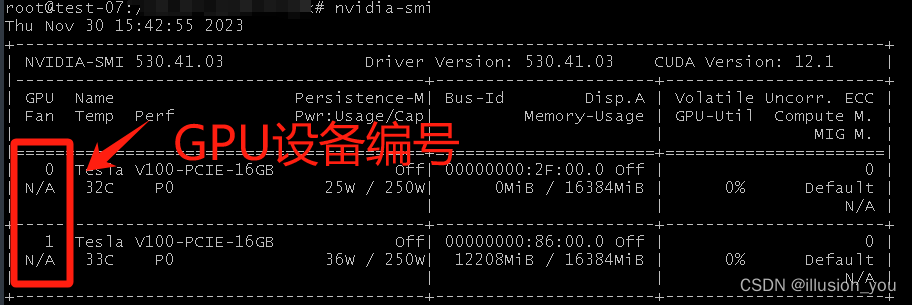
sudo systemctl restart docker2.查看GPU编号,命令:nvidia-smi
3.安装langchain-chatchat镜像
#方式1
docker run -d -p 80:7860 --gpus all registry.cn-beijing.aliyuncs.com/isafetech/chatmydata:1.0#参数解释:
--gpus all 指定给该设备所有可用的GPU
--gpus '"device=1"' 指定设备编号为1的GPU#方式2
git clone -b 0.1.17 --single-branch https://github.com/chatchat-space/Langchain-Chatchat.gitdocker build -f Dockerfile-cuda -t chatglm-cuda:latest .
docker run --gpus all -d --name chatglm -p 7860:7860 chatglm-cuda:latest#若要使用离线模型,请配置好模型路径,然后此repo挂载到Container
docker run --gpus all -d --name chatglm -p 7860:7860 -v ~/github/langchain-ChatGLM:/chatGLM chatglm-cuda:latest3.查看启动日志
docker logs 容器ID4.启用后台服务
docker exec -it 容器ID /bin/bash#命令行服务
python cli_demo.py#接口服务
python api.py#web服务
python webui.py第二种部署方式:
- 下载并安装anaconda。为什么要安装anaconda?【见本文-常见问题2】
wget https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh bash Anaconda3-2023.03-1-Linux-x86_64.shconda create -n ai python=3.11 #创建虚拟环境 conda activate ai #激活虚拟环境 conda list #查看已安装的包 conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia #安装依赖包 - 下载源码,安装依赖
# 拉取仓库 $ git clone https://github.com/chatchat-space/Langchain-Chatchat.git# 进入目录 $ cd Langchain-Chatchat# 安装全部依赖 $ pip install -r requirements.txt $ pip install -r requirements_api.txt $ pip install -r requirements_webui.txt # 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。 - 下载模型
$ git lfs install$ git clone https://huggingface.co/THUDM/chatglm2-6b $ git clone https://huggingface.co/moka-ai/m3e-base###建议:上面地址下载慢的话,访问https://e.aliendao.cn/,搜索 chatglm2-6b和m3e-base,然后按照下面方式下载git clone https://github.com/git-cloner/aliendao cd aliendao pip install -r requirements.txt -i https://pypi.mirrors.ustc.edu.cn/simple --trusted-host=pypi.mirrors.ustc.edu.cnpython model_download.py --e --repo_id 模型ID - 初始化配置模型
$ python copy_config_example.py - 修改配置文件,找到配置文件(路径:/configs/model_config.py),修改模型加载路径。
# 如果模型目录名称和 MODEL_PATH 中的 key 或 value 相同,程序会自动检测加载,无需修改 MODEL_PATH 中的路径。 MODEL_ROOT_PATH = "/usr/local/"#配置LLM线上模型参数 ONLINE_LLM_MODEL = { }#配置本地模型参数,模型的相对路径,相对 MODEL_ROOT_PATH 所配置的路径 MODEL_PATH = { "embed_model":{ "m3e-base": "moka-ai/m3e-base" }, "llm_model":{ "chatglm2-6b": "THUDM/chatglm2-6b", }#### #注意:线上模型和本地模型只需要配置一个即可。 - 初始化数据库
python init_database.py --recreate-vs - 一键启动
python startup.py -a
选择适合你的方式安装即可。
常见问题
部署方式一常见问题:
1、docker: Error response from daemon: could not select device driver “” with capabilities: [[gpu]].或者 apt-get install -y nvidia-container-toolkit找不到或者下载失败
解决方案:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkeyapt-key add gpgkeycurl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listapt-get update && apt-get install -y nvidia-container-toolkit
systemctl restart docker2、为什么要使用anaconda?
anaconda是什么?
Anaconda是Python的一个发行版本,专注于数据分析,能够对包和环境进行管理。它内置了conda、pip等管理工具,以及Jupyter Notebook、Spyder等开发工具
- 避免已安装但是不满足运行大模型的python版本受影响;
- 隔离python运行环境和依赖;
- anaconda的基本操作
conda env list #查看已有的环境 conda create -n ai python=3.11 #创建虚拟环境 conda activate ai #激活虚拟环境 conda list #查看已安装的包 conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia #安装依赖包conda deactivate #退出虚拟环境