目录
1.基础简介
1.1基础介绍
1.2基础架构
2.Alexnet与LeNet的对比
3.参考代码
4.李沐老师给出的例子
1.基础简介
1.1基础介绍
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
AlexNet并不是第一个赢得图像识别竞赛的GPU实现的高速卷积神经网络。 K. Chellapilla et al. (2006)在GPU上的卷积神经网络比CPU上的等效实现快四倍,Dan Cireřan等人(4)在IDSIA的深度卷积神经网络已经快了2011倍,并在5年2011月取得了超人的性能。 在6年2011月5日至15年2012月9日期间,他们的卷积神经网络赢得了四次以上的图像竞赛。 它还显著更新了文献中多个图像数据库的最高性能。
根据AlexNet的一篇论文Cireřan的早期网络“有些相似”。 两者都最初是用 CUDA 编写的,可以在 GPU 上运行。 事实上,两者都是Yann Lucan等人(1989)发表的卷积神经网络设计的变体,而福岛邦彦(称为neocognitron)则认为。 这种结构后来被J. Weng的技术修改,称为最大池化。
2015年,AlexNet赢得了亚洲研究院Microsoft 2015多层的超深度卷积神经网络,赢得了ImageNet 100竞赛。
1.2基础架构

- 第一层:11x11的96通道卷积,步长为4,后接ReLU激活函数和局部响应归一化(LRN),再接3x3的最大池化,步长为2。
- 第二层:5x5的256通道卷积,步长为1,后接ReLU激活函数和LRN,再接3x3的最大池化,步长为2。
- 第三层:3x3的384通道卷积,步长为1,后接ReLU激活函数。
- 第四层:3x3的384通道卷积,步长为1,后接ReLU激活函数。
- 第五层:3x3的256通道卷积,步长为1,后接ReLU激活函数和3x3的最大池化,步长为2。
- 第六层:4096个神经元的全连接层,后接ReLU激活函数和Dropout。
- 第七层:4096个神经元的全连接层,后接ReLU激活函数和Dropout。
- 第八层:1000个神经元的全连接层,输出类别预测。
AlexNet使用了两个GPU来并行训练网络,并在第三、第四、第五层中使用跨GPU的连接来增加模型容量。AlexNet在ImageNet数据集上达到了15.3%的top-5错误率,比第二名低了10.8个百分点。AlexNet是计算机视觉领域最具影响力的论文之一,它证明了深度学习在图像识别任务上的优越性,并促进了更多基于CNN和GPU的研究。
2.Alexnet与LeNet的对比
首先对比两者的架构图,具有明显的进步,Alexnet具有更大更深的网络:
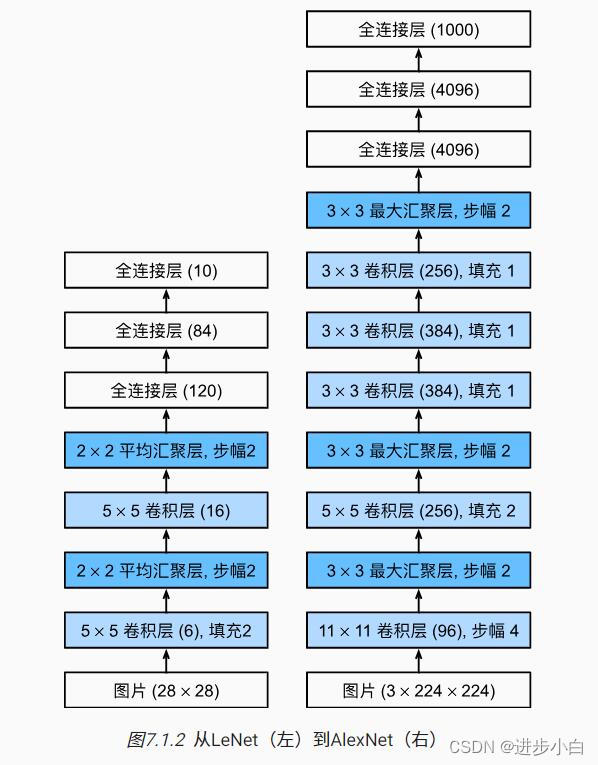
AlexNet和LeNet的异同如下:
- 相同点:都是基于卷积神经网络的图像分类模型,都使用了卷积层、池化层和全连接层的组合来提取图像特征。
- 不同点:
- AlexNet比LeNet更深更宽,有更多的参数和计算量。
- AlexNet使用了ReLU激活函数,而LeNet使用了sigmoid激活函数。
- AlexNet使用了Dropout来抑制过拟合,而LeNet没有。
- AlexNet使用了数据增广来扩充训练集,而LeNet没有。
- AlexNet使用了不同大小的卷积核(11x11, 5x5, 3x3),而LeNet只使用了5x5的卷积核。
- AlexNet使用了最大池化,而LeNet使用了平均池化
3.参考代码
如果你想写一个AlexNet的代码,你可以参考以下的资源:
- AlexNet Explained | Papers With Code 这个网站提供了AlexNet的详细介绍和代码实现,以及在不同的数据集和任务上的结果和排名。
- AlexNet | Papers With Code 这个网站提供了AlexNet的PyTorch实现,以及训练和评估的方法和参数。
- AlexNet convolutional neural network - MATLAB alexnet 这个网站提供了AlexNet的MATLAB实现,以及加载预训练模型和生成代码的方法。
4.李沐老师给出的例子
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(# 这里使用一个11*11的更大窗口来捕捉对象。# 同时,步幅为4,以减少输出的高度和宽度。# 另外,输出通道的数目远大于LeNetnn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 使用三个连续的卷积层和较小的卷积窗口。# 除了最后的卷积层,输出通道的数量进一步增加。# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000nn.Linear(4096, 10))X = torch.randn(1, 1, 224, 224)
for layer in net:X=layer(X)print(layer.__class__.__name__,'output shape:\t',X.shape)
将AlexNet直接应用于Fashion-MNIST的一个问题是,Fashion-MNIST图像的分辨率(28×28像素)低于ImageNet图像。 为了解决这个问题,我们将它们增加到224×224(通常来讲这不是一个明智的做法,但在这里这样做是为了有效使用AlexNet架构)。 这里需要使用
d2l.load_data_fashion_mnist函数中的resize参数执行此调整。
读取数据集:
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)训练网络:
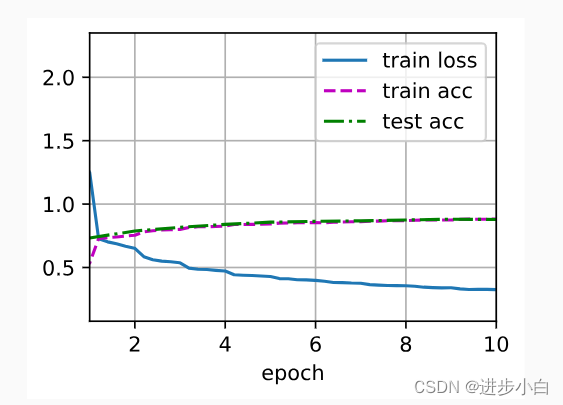
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())