Python中的继承
文章目录
- Python中的继承
- 概念明确
- MRO
- 深度优先算法(Python2.2之前及Python2.2的经典类中使用)
- 优化版的深度优先算法(只在Python2.2版本的新式类中使用)
- 广度优先算法(Python任何版本都从未使用过)
- C3算法(Python2.3开始的新式类、Python3.x使用)
- Python中继承的三种形态
- 单继承链
- 无重叠的多继承链
- 有重叠的多继承链
- Python2.2之前
- Python2.2
- Python2.3-2.7
- Python3.x
- C3算法的分步推演
- C3算法检测出有问题的继承
为什么要单独研究Python的继承呢?
因为Python中是存在多继承的。
在 概念明确 阶段,如果看不懂,可以先往后面看,有代码例子,你肯定会明白的。
概念明确
MRO
- Method Resolution Order(方法解析顺序)
- 其实就可以理解为当我们的代码想要访问资源的时候,这个资源的查找顺序。
- 例如A类继承自B类,B类继承自C类。当我们访问A.name的时候如果A没有就会到B类中去找是否有名为name的类属性,如果B也没有则继续找C类的类属性name,如果都没找到则报错,如果过程中找到了就达到了我们的目的,这个过程就是MRO。
深度优先算法(Python2.2之前及Python2.2的经典类中使用)
- 解释:沿着一个继承链 ,尽可能的往深了去找。
- 具体算法步骤:
- 把根节点压入**栈(先进后出)**中
- 每次从栈中弹出一个元素,搜索所有在它下一级的元素(可以是1个,也可以是多个),并把所有这些下一级的元素全部压入栈中。
- 重复第2个步骤到结束
- 问题:
- 在"有重叠的多继承"中 ,违背 “重写可用原则”
- 如下面图所示,即,在C类中重写了D的方法,但是MRO会优先使用D,这样C类的重写就失效了。
- 即,使用深度优先算法算出来后是:A -> B -> D -> C
- 所以在当年都是通过重新设计继承结构的手段,来避免这样的问题。
- 在"有重叠的多继承"中 ,违背 “重写可用原则”
优化版的深度优先算法(只在Python2.2版本的新式类中使用)
-
在Python2.2的新式类中使用了:优化版的深度优先算法
-
如果产生重复元素,会保留最后一个。
-
并且 , 更尊重基类出现的先后顺序
-
注意,并不是"广度优先算法"
-
-
问题:
- 无法检测出有问题的继承
- 有可能还会违背“局部优先”的原则
广度优先算法(Python任何版本都从未使用过)
- 解释:沿着继承链,尽可能往宽了去找。
- 具体算法步骤:
- 把根节点放到队列的末尾
- 每次从队列的头部取出一个元素,查看这个元素所有的下一级元素,把它们放到队列的末尾。注意如果发现这个元素已经被处理过则略过。
- 重复上面步骤
C3算法(Python2.3开始的新式类、Python3.x使用)
-
一定要记住两个公式:
L(object) = [object]L( 本类(父类1, 父类2) ) = [本类] + merge( L(父类1), L(父类2), [父类1,父类2] )
-
解释:
L:表示一个函数,就是待计算的某个类的资源访问顺序所组成的列表,L也就是list。L(object)就是要计算object类本身的访问顺序,那么最终的结果就是由object所组成的列表。merge()函数里的传参就是找到本类的第一个父类并计算出第一个父类的资源访问顺序所组成的列表,第二个参数就是本类所继承的第二个父类所计算出来的资源访问顺序组成的列表,第三个参数就是把本类所继承的所有父类都组成一个列表。+代表合并列表。
-
merge()算法:- 如果第一个列表的第一个元素是:
- 后续列表的第一个元素,则将这个元素合并到最终的解析列表中,并从当前操作的所有列表中删除。
- 或者,后续列表中没有再次出现,则将这个元素合并到最终的解析列表中,并从当前操作的所有列表中删除。
- 如果1中的两个条件都不符合,则跳过此元素,查找下一个列表的第一个元素,重复1的判断规则。
- 如果最终无法把所有元素归并到解析列表,则报错。
- 如果第一个列表的第一个元素是:
-
相信你看完公式后,还是无法理解,可以往后看例子,就会理解了。
Python中继承的三种形态
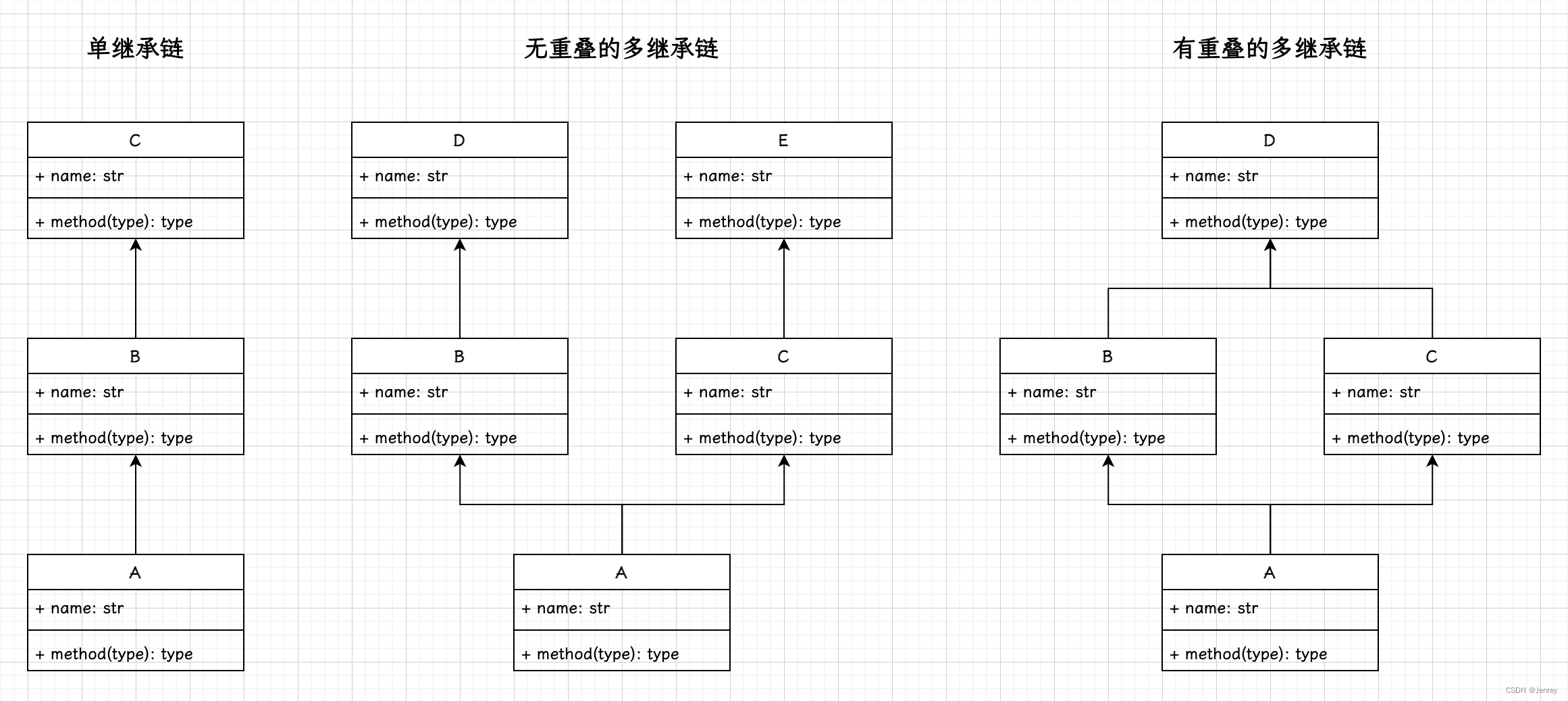
单继承链
- 遵循"从下到上的原则"
- 自己身上没有这个资源,就到父类里面去找,父类里面没有再往上找
# python3.x
import inspect
class C:name = "C"
class B(C):pass
class A(B):pass
print(A.name) # C
print(inspect.getmro(A)) # A -> B -> C -> object
无重叠的多继承链
- 遵循"单调原则"
- 按照继承的先后顺序 , 优先调用左侧继承链上的资源
# python3.x
import inspect
class D:name = "D"
class E:name = "E"
class C(E):name = "C"
class B(D):pass
class A(B,C):pass
print(A.name) # D
print(inspect.getmro(A)) # A -> B -> D -> C -> E -> object
有重叠的多继承链
- 遵循"从下到上的原则"
- A继承B同时继承C,A类没有就找B,B没有就找C,C没有才找D
# python3.x
import inspect
class D:pass
class C(D):pass
class B(D):pass
class A(B, C):pass
print(inspect.getmro(A)) # A -> B -> C -> D -> object
Python2.2之前
- 仅仅存在经典类
- MRO原则:深度优先(从左往右)
- 在"有重叠的多继承"中 ,违背 “重写可用原则”
- 即,在C类中重写了D的方法,但是MRO会优先使用D,这样C类的重写就失效了。
- 即,使用深度优先算法算出来后是:A -> B -> D -> C
- 所以在当年都是通过重新设计继承结构的手段,来避免这样的问题。
Python2.2
-
在Python2.2中,为了方便的同一类的一些内置方法,就产生了object的类,把很多需要统一的方法都设计到了object类里面,这就是新式类的由来。
-
只要继承object的类都是新式类,所以有了object类以后,就非常容易出现重叠继承的问题,为此在Python2.2中针对新式类做了一些优化。
-
在Python2.2中,增加了inspect模块,可以方便我们快速计算MRO。
-
MRO原则:
- 经典类:依旧采用之前的深度优先(从左到右)
- 新式类:在深度优先(从左到右)的算法基础之上,进行优化
- 如果产生重复元素,会保留最后一个。
- 并且 , 更尊重基类出现的先后顺序
- 注意,并不是"广度优先算法"
- 假如!!用的是广度优先算法,在计算无重叠的多继承链时的顺序应该是:A -> B -> C -> D -> E -> object
- 而真实的在Python2.2中计算无重叠的多继承链时的顺序是:A -> B -> D -> C -> E -> object
- 之所以大家误以为是Python2.2的新式类是广度优先算法是因为在计算有重叠的多继承中的结果与真实的优化后的深度优先算法计算出来的结果是相同的。
-
在"有重叠的多继承"中,使用优化后的深度优先算法算出来后是:A -> B -> D -> object -> C -> D -> object,即A -> B -> C -> D -> object
-
问题:
-
无法检测出有问题的继承
-
有可能还会违背“局部优先”的原则
-
例如:这样的继承是有问题的,因为A继承了B、D、object ,而A又继承了C、B、D、object,这两部分是包含关系。
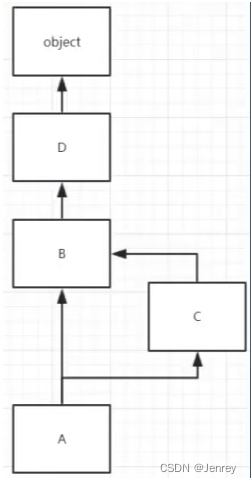
按照Python2.2中新式类的改进深度优先算法是无法检测出来问题的,并且还会计算出一个结果给我们:A -> C -> B -> D -> object
这个图对于“局部优先”原则也是违背的,如图所示A继承B和C,当A尝试去访问一个资源的时候,在A没有的前提下,A应该先选择左侧的B,然后再选择右侧的C,但是结果确实先选择了C后选择了B,但是我们代码写的是class A(B, C) ,所以就违背了局部优先原则。
-
Python2.3-2.7
-
因为在Python2.2版本存在无法检测出有问题的继承同时有可能违背局部优先原则,所以在Python2.3开始直到Python2.7结束,对MRO原则进行了优化。
-
MRO原则:
- 经典类:还是之前的深度优先(从左到右),注意不是优化后的深度优先算法哦!
- 新式类:就不再采用优化后的深度优先算法了,而是采用C3算法
-
注意:C3算法只是类似拓扑排序,但是并不是,这里要切记。
- 拓扑算法:
- 选择一个入度为0 的顶点并输出之;
- 从网中删除此顶点及所有出边
- 拓扑算法:
Python3.x
- 在Python3.x版本中只有新式类,没有经典类,所以只有C3算法。
- 查看MRO的三种方式:
- 使用inspect模块的
getmro(A)方法 - 打印
A.__mro__ - 打印
A.mro()
- 使用inspect模块的
C3算法的分步推演
# 这里使用 Python 2.7.13
# 这里就不画图了,就是文章开始的“有重叠的多继承链”,也称棱形继承
# 注意这里是经典类,使用的是深度优先算法。
import inspect
class D:pass
class B(D):pass
class C(D):pass
class A(B, C):pass
print inspect.getmro(A) # A -> B -> D -> C
# 这里使用 Python 2.7.13
# 这里就不画图了,就是文章开始的“有重叠的多继承链”,也称棱形继承
# 注意这里是新式类,使用的是C3算法。
import inspect
class D(object):pass
class B(D):pass
class C(D):pass
class A(B, C):pass
print inspect.getmro(A) # A -> B -> C -> D -> object
# 手动计算C3算法
# 这里仍旧使用 Python 2.7.13
# 这里就不画图了,就是文章开始的“有重叠的多继承链”,也称棱形继承
# 注意要继承object后成为新式类"""C3算法如下:
L(object) = [object]
L(本类(父类1, 父类2)) = [本类] + merge(L(父类1), L(父类2), [父类1,父类2])merge算法:1. 如果第一个列表的第一个元素是后续列表的第一个元素,则将这个元素合并到最终的解析列表中,并从当前操作的所有列表中删除。或者后续列表中没有再次出现,则将这个元素合并到最终的解析列表中,并从当前操作的所有列表中删除。2. 如果1中的两个条件都不符合,则跳过此元素,查找下一个列表的第一个元素,重复1的判断规则。3. 如果最终无法把所有元素归并到解析列表,则报错。
"""class D(object):pass# L(D(object)) = [D] + merge(L(object), [object])# L(D(object)) = [D] + merge([object], [object])# 此时merge方法中的参数都是列表了,就可以进行merge算法的处理了# 符合merge算法的条件1,即第一个列表的第一个元素object是后续列表的第一个元素,那么将object从当前merge中所有的列表中删除,并添加到最终的解析列表中# L(D(object)) = [D, object] + merge([], [])# L(D(object)) = [D, object] # 所以关于D的资源访问顺序就是先D后objectclass B(D):pass# L(B(D)) = [B] + merge(L(D), [D])# L(D)从上面的结果中得知是[D, object]# L(B(D)) = [B] + merge([D, object], [D])# 此时merge方法中的参数都是列表了,就可以进行merge算法的处理了# 符合merge算法的条件1,即第一个列表的第一个元素D是后续列表的第一个元素,那么将D从当前merge中所有的列表中删除,并添加到最终的解析列表中# L(B(D)) = [B, D] + merge([object], [])# 符合merge算法的条件1,虽然object不是后续列表的第一个元素,但是符合后续列表中没有再次出现object,则将这个object元素合并到最终的解析列表中,并从当前操作的所有列表中删除object# L(B(D)) = [B, D, object] + merge([], [])# L(B(D)) = [B, D, object] # 所以关于B的资源访问顺序就是B -> D -> object
class C(D):pass# L(C(D)) = [C] + merge(L(D), [D])# L(D)从上面的结果中得知是[D, object]# L(C(D)) = [C] + merge([D, object], [D])# 此时merge方法中的参数都是列表了,就可以进行merge算法的处理了# 符合merge算法的条件1,即第一个列表的第一个元素D是后续列表的第一个元素,那么将D从当前merge中所有的列表中删除,并添加到最终的解析列表中# L(C(D)) = [C, D] + merge([object], [])# 符合merge算法的条件1,虽然object不是后续列表的第一个元素,但是符合后续列表中没有再次出现object,则将这个object元素合并到最终的解析列表中,并从当前操作的所有列表中删除object# L(C(D)) = [C, D, object] + merge([], [])# L(C(D)) = [C, D, object] # 所以关于C的资源访问顺序就是C -> D -> object
class A(B, C):pass# L(A(B, C)) = [A] + merge(L(B), L(C), [B, C])# L(B)从上面的结果中得知是[B, D, object]# L(C)从上面的结果中得知是[C, D, object]# L(A(B, C)) = [A] + merge([B, D, object], [C, D, object], [B, C])# 此时merge方法中的参数都是列表了,就可以进行merge算法的处理了# 符合merge算法的条件1,即第一个列表的第一个元素B是后续列表的第一个元素,那么将B从当前merge中所有的列表中删除,并添加到最终的解析列表中# L(A(B, C)) = [A, B] + merge([D, object], [C, D, object], [C])# 不符合merge算法的条件1,即第一个列表的第一个元素D不是后续列表的第一个元素,并且元素D在第二个列表中存在了,所以merge算法的条件1都不满足,则跳过此元素D,查找下一个列表的第一个元素C,重复1的判断规则,发现C确实是后续列表的首元素,则将这个元素C合并到最终的解析列表中,并从当前操作的所有列表中删除元素C# L(A(B, C)) = [A, B, C] + merge([D, object], [D, object], [])# 符合merge算法的条件1,即第一个列表的第一个元素D是后续列表的第一个元素,则将这个元素D合并到最终的解析列表中,并从当前操作的所有列表中删除元素D# L(A(B, C)) = [A, B, C, D] + merge([object], [object], [])# 符合merge算法的条件1,即第一个列表的第一个元素object是后续列表的第一个元素,那么将object从当前merge中所有的列表中删除,并添加到最终的解析列表中# L(A(B, C)) = [A, B, C, D, object] + merge([], [], [])# L(A(B, C)) = [A, B, C, D, object] # 所以关于A的资源访问顺序就是A -> B -> C -> D -> object
C3算法检测出有问题的继承
# C3算法能否解决在Python2.2版本中关于新式类的 优化版深度优先算法 存在的问题呢?
# 这里仍旧使用 Python 2.7.13
class D(object):pass# L(D) = [D] + merge(L(object), [object])# L(D) = [D] + merge([object], [object])# L(D) = [D, object] + merge([], [])# L(D) = [D, object]
class B(D):pass# L(B) = [B] + merge(L(D), [D])# L(B) = [B] + merge([D, object], [D])# L(B) = [B, D] + merge([object], [])# L(B) = [B, D, object] + merge([], [])# L(B) = [B, D, object]
class C(B):pass# L(C) = [C] + merge(L(B), [B])# L(C) = [C] + merge([B, D, object], [B])# L(C) = [C, B] + merge([D, object], [])# L(C) = [C, B, D] + merge([object], [])# L(C) = [C, B, D, object] + merge([], [])# L(C) = [C, B, D, object]
class A(B, C): # 抛出TypeError错误pass# L(A) = [A] + merge(L(B), L(C), [B, C])# L(A) = [A] + merge([B, D, object], [C, B, D, object], [B, C])# 此时merge方法中的参数都是列表了,就可以进行merge算法的处理了# 不符合merge算法的条件1,即第一个列表的第一个元素B不是后续列表的第一个元素,并且元素B在第二个列表中存在了,所以merge算法的条件1都不满足,则跳过此元素B,查找下一个列表的第一个元素C,重复1的判断规则,发现C也不是后续列表的第一个元素,且元素C在后续列表中有再次出现,则跳过此元素C,查找下一个列表的第一个元素B,此时merge函数要处理的列表根本无法处理,出现无解情况,说明当前是错误的继承关系,也就是检测出有问题的继承了# 此时如果我们直接运行代码,会报错:无法创建不矛盾的MRO
# TypeError: Cannot create a consistent method resolution
# order (MRO) for bases B, C
# 这里使用的是Python3.x版本
# 当然你也可以使用Python2.3到2.7版本,但是要注意继承自object,这样才能使用新式类。
# 这里就不画图了,就是文章开始的"无重叠的多继承链"
import inspectclass F:pass# L(F) = [F] + merge(L(object), [object])# L(F) = [F] + merge([object], [object])# L(F) = [F, object] + merge([], [])# L(F) = [F, object]class E(F):pass# L(E) = [E] + merge(L(F), [F])# L(E) = [E] + merge([F, object], [F])# L(E) = [E, F] + merge([object], [])# L(E) = [E, F, object] + merge([], [])# L(E) = [E, F, object]class D(F):pass# L(D) = [D] + merge(L(F), [F])# L(D) = [D] + merge([F, object], [F])# L(D) = [D, F] + merge([object], [])# L(D) = [D, F, object] + merge([], [])# L(D) = [D, F, object]class C(E):pass# L(C) = [C] + merge(L(E), [E])# L(C) = [C] + merge([E, F, object], [E])# L(C) = [C, E] + merge([F, object], [])# L(C) = [C, E, F] + merge([object], [])# L(C) = [C, E, F, object] + merge([], [])# L(C) = [C, E, F, object]class B(D):pass# L(B) = [B] + merge(L(D), [D])# L(B) = [B] + merge([D, F, object], [D])# L(B) = [B, D] + merge([F, object], [])# L(B) = [B, D, F] + merge([object], [])# L(B) = [B, D, F, object] + merge([], [])# L(B) = [B, D, F, object]class A(B, C):pass# L(A) = [A] + merge(L(B), L(C), [B, C])# L(A) = [A] + merge([B, D, F, object], [C, E, F, object], [B, C])# L(A) = [A, B] + merge([D, F, object], [C, E, F, object], [C])# L(A) = [A, B, D] + merge([F, object], [C, E, F, object], [C])# L(A) = [A, B, D, C] + merge([F, object], [E, F, object], [])# L(A) = [A, B, D, C, E] + merge([F, object], [F, object], [])# L(A) = [A, B, D, C, E, F] + merge([object], [object], [])# L(A) = [A, B, D, C, E, F, object] + merge([], [], [])# L(A) = [A, B, D, C, E, F, object]print(inspect.getmro(A)) # A -> B -> D -> C -> E -> F -> object


![速达软件全系产品任意文件上传漏洞复现 [附POC]](https://img-blog.csdnimg.cn/direct/2cd7921a38714229b3874330d47020a8.png)