⽹络模型
国际标准化组织制定的开放式系统互联通信参考模型(Open System Interconnection Reference Model),简称为 OSI ⽹络模型。
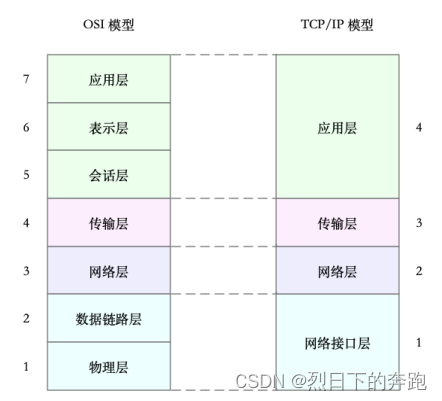
为了解决⽹络互联中异构设备的兼容性问题,并解耦复杂的⽹络包处理流程,OSI 模型把⽹络互联的框 架分为应⽤层、表⽰层、会话层、传输层、⽹络层、数据链路层以及物理层等七层,每个层负责不同的 功能。其中,
应⽤层,负责为应⽤程序提供统⼀的接口。
表⽰层,负责把数据转换成兼容接收系统的格式。
会话层,负责维护计算机之间的通信连接。
传输层,负责为数据加上传输表头,形成数据包。
⽹络层,负责数据的路由和转发。
数据链路层,负责 MAC 寻址、错误侦测和改错。
物理层,负责在物理⽹络中传输数据帧。
在 Linux 中,实际上使⽤的是另⼀个更实⽤的四层模型,即 TCP/IP ⽹络模型。
TCP/IP 模型,把⽹络互联的框架分为应⽤层、传输层、⽹络层、⽹络接口层等四层,其中,
应⽤层,负责向⽤⼾提供⼀组应⽤程序,⽐如 HTTP、FTP、DNS 等。
传输层,负责端到端的通信,⽐如 TCP、UDP 等。
⽹络层,负责⽹络包的封装、寻址和路由,⽐如 IP、ICMP 等。
⽹络接口层,负责⽹络包在物理⽹络中的传输,⽐如 MAC 寻址、错误侦测以及通过⽹卡传输⽹络帧 等。
TCP/IP 与 OSI 模型的关系图,如下所⽰:
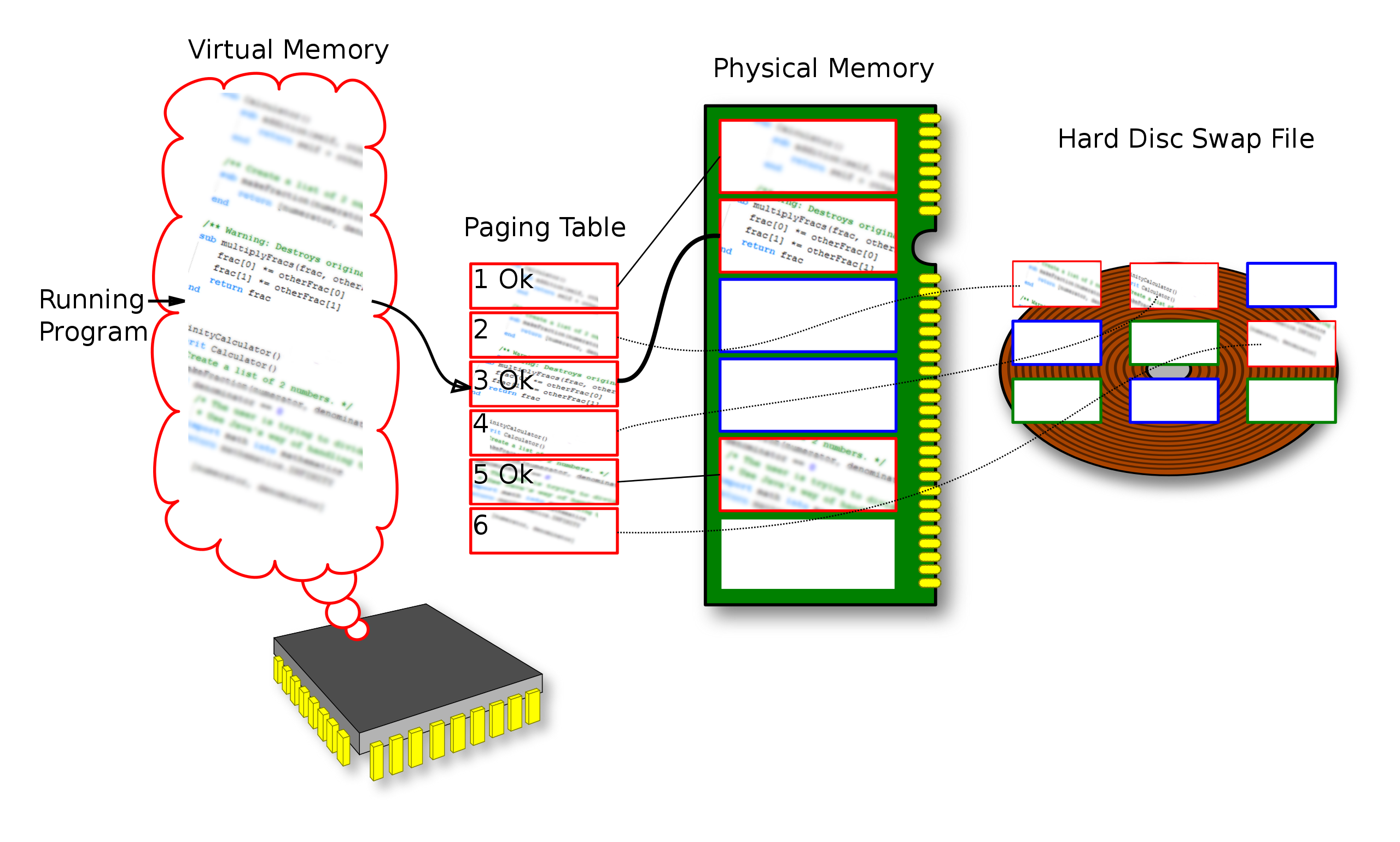
Linux ⽹络栈
在进⾏⽹络传输时,数据包就会按照协议栈,对上⼀层发来的数据进⾏逐层处理;然后封装上该层的协 议头,再发送给下⼀层。
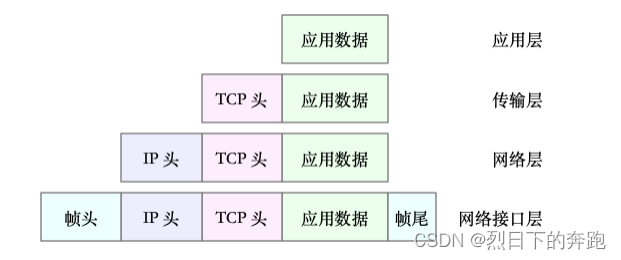 传输层在应⽤程序数据前⾯增加了 TCP 头;
传输层在应⽤程序数据前⾯增加了 TCP 头;
⽹络层在 TCP 数据包前增加了 IP 头;
而⽹络接口层,⼜在 IP 数据包前后分别增加了帧头和帧尾。
这些新增的头部和尾部,都按照特定的协议格式填充
这些新增的头部和尾部,增加了⽹络包的⼤小,但是物理链路中并不能传输任意⼤小的数据包。⽹络接 口配置的最⼤传输单元(MTU),就规定了最⼤的 IP 包⼤小。在最常⽤的以太⽹中,MTU 默认值是 1500(这也是 Linux 的默认值)。
⼀旦⽹络包超过 MTU 的⼤小,就会在⽹络层分⽚,以保证分⽚后的 IP 包不⼤于 MTU 值。显然,MTU 越⼤,需要的分包也就越少,⾃然,⽹络吞吐能⼒就越好。
Linux 通⽤ IP ⽹络栈的⽰意图:
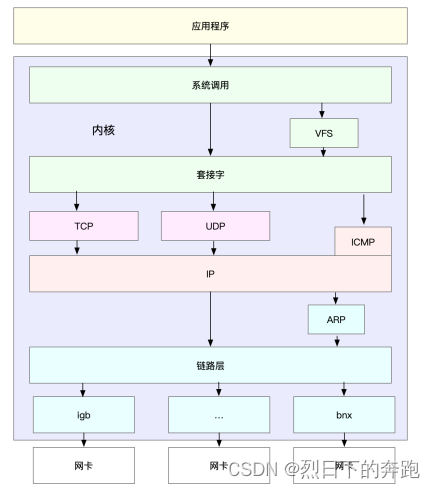
最上层的应⽤程序,需要通过系统调⽤,来跟套接字接口进⾏交互;
套接字的下⾯,就是前⾯提到的传输层、⽹络层和⽹络接口层;
最底层,则是⽹卡驱动程序以及物理⽹卡设备。
⽹卡是发送和接收⽹络包的基本设备。在系统启动过程中,⽹卡通过内核中的⽹卡驱动程序注册到系统 中。而在⽹络收发过程中,内核通过中断跟⽹卡进⾏交互。
⽹卡硬中断只处理最核⼼的⽹卡数据读取或发送,而协议栈中的⼤部分逻辑,都会放到软中断中处理。
Linux ⽹络收发流程
⽹络包的接收流程
当⼀个⽹络帧到达⽹卡后,⽹卡会通过 DMA ⽅式,把这个⽹络包放到收包队列中;然后通过硬中断, 告诉中断处理程序已经收到了⽹络包。
接着,⽹卡中断处理程序会为⽹络帧分配内核数据结构(sk_buff),并将其拷⻉到 sk_buff 缓冲区中; 然后再通过软中断,通知内核收到了新的⽹络帧。
接下来,内核协议栈从缓冲区中取出⽹络帧,并通过⽹络协议栈,从下到上逐层处理这个⽹络帧。⽐ 如,
在链路层检查报⽂的合法性,找出上层协议的类型(⽐如 IPv4 还是 IPv6),再去掉帧头、帧尾,然后 交给⽹络层。
⽹络层取出 IP 头,判断⽹络包下⼀步的走向,⽐如是交给上层处理还是转发。当⽹络层确认这个包是要 发送到本机后,就会取出上层协议的类型(⽐如 TCP 还是 UDP),去掉 IP 头,再交给传输层处理。
传输层取出 TCP 头或者 UDP 头后,根据 < 源 IP、源端口、⽬的 IP、⽬的端口 > 四元组作为标识,找出 对应的 Socket,并把数据拷⻉到 Socket 的接收缓存中。
最后,应⽤程序就可以使⽤ Socket 接口,读取到新接收到的数据了。
左半部分表⽰接收流程,粉⾊箭头表⽰⽹络包的处理路径。
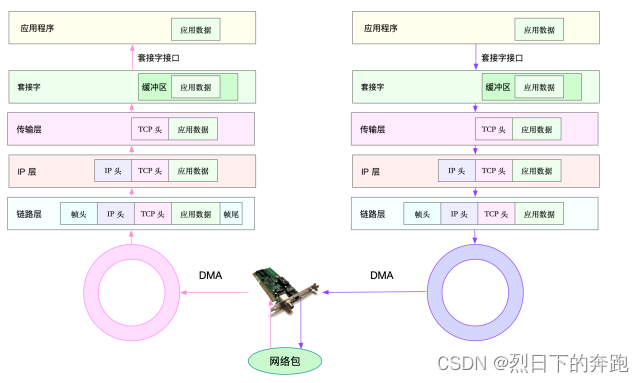
⽹络包的发送流程
上图的右半部分,很容易发现,⽹络包的发送⽅向,正好跟接收⽅向相反。
⾸先,应⽤程序调⽤ Socket API(⽐如 sendmsg)发送⽹络包。 由于这是⼀个系统调⽤,所以会陷⼊到内核态的套接字层中。套接字层会把数据包放到 Socket 发送缓冲 区中。
接下来,⽹络协议栈从 Socket 发送缓冲区中,取出数据包;再按照 TCP/IP 栈,从上到下逐层处理。⽐ 如,传输层和⽹络层,分别为其增加 TCP 头和 IP 头,执⾏路由查找确认下⼀跳的 IP,并按照 MTU ⼤小 进⾏分⽚。
分⽚后的⽹络包,再送到⽹络接口层,进⾏物理地址寻址,以找到下⼀跳的 MAC 地址。然后添加帧头 和帧尾,放到发包队列中。这⼀切完成后,会有软中断通知驱动程序:发包队列中有新的⽹络帧需要发 送。
最后,驱动程序通过 DMA ,从发包队列中读出⽹络帧,并通过物理⽹卡把它发送出去。
⽹络丢包分析⽅法
根据彭总讲的补充的
核⼼思想:
1. 收集信息、缩小范围:接收端还是发送端还是⽹络设备
2. 分层原则: 1. 物理层 2. 链路层 3. ⽹络层 4. 传输层 5. socket 6. 应⽤程序
3. 各⼯具⽅法及原理
4. 综合考虑CPU、内存、IO
多⽹卡、bond、虚拟化⽹络、docker,桥接⽹络
Nginx丢包排查
应⽤程序错误
缓冲区满
连接跟踪或内核资源超限
路由错误MTU超限
校验错误QoS
⽹络拥塞
⽹络接口层
ring buffer 溢出造成overrruns
netstat -i
⽹络帧校验失败
ethtool -S eth0或者tcpdump确认
QoS,tc规则导致的丢包不会包含在⽹卡
tc -s qdisc show dev eht0
⽹络层
路由失败
traceroute
分⽚⼤小超过MTU、处理分⽚内存不够
netstat -i/-s
连接跟踪表限制
sysctl -a
传输层
内核资源超限
多⻅于⾼并发、⾼带宽场合
sar -n
ping/hping3
netstat/ss
连接跟踪表或iptables规则
conntrack/iptables
应⽤层
应⽤层协议
http、DNS等
dig nslookup确认DNS问题
⽹络层
接下来,再来看⽹络层的优化。
⽹络层,负责⽹络包的封装、寻址和路由,包括 IP、ICMP 等常⻅协议。在⽹络层,最主要的优化,其 实就是对路由、 IP 分⽚以及 ICMP 等进⾏调优。
第⼀种,从路由和转发的⻆度出发调整下⾯的内核选项。
在需要转发的服务器中,⽐如⽤作 NAT ⽹关的服务器或者使⽤ Docker 容器时,开启 IP 转发,即设置 net.ipv4.ip_forward = 1。
调整数据包的⽣存周期 TTL,⽐如设置 net.ipv4.ip_default_ttl = 64。注意,增⼤该值会降低系统性能。
第⼆种,从分⽚的⻆度出发,最主要的是调整 MTU(Maximum Transmission Unit)的⼤小。 通常,MTU 的⼤小应该根据以太⽹的标准来设置。以太⽹标准规定,⼀个⽹络帧最⼤为 1518B,那么 去掉以太⽹头部的 18B 后,剩余的 1500 就是以太⽹ MTU 的⼤小。
在使⽤ VXLAN、GRE 等叠加⽹络技术时,要注意,⽹络叠加会使原来的⽹络包变⼤,导致 MTU 也需要 调整。
⽐如,就以 VXLAN 为例,它在原来报⽂的基础上,增加了 14B 的以太⽹头部、 8B 的 VXLAN 头部、8B 的 UDP 头部以及 20B 的 IP 头部。换句话说,每个包⽐原来增⼤了 50B。
所以,就需要把交换机、路由器等的 MTU,增⼤到 1550, 或者把 VXLAN 封包前(⽐如虚拟化环境中 的虚拟⽹卡)的 MTU 减小为 1450。
另外,现在很多⽹络设备都⽀持巨帧,如果是这种环境,还可以把 MTU 调⼤为 9000,以提⾼⽹络吞吐 量进⾏组播测试和极限测试
第三种,从 ICMP 的⻆度出发,为了避免 ICMP 主机探测、ICMP Flood 等各种⽹络问题,可以通过内核 选项,来限制 ICMP 的⾏为。
⽐如、可以禁⽌ ICMP 协议,即设置 net.ipv4.icmp_echo_ignore_all = 1。这样,外部主机就⽆法通过 ICMP 来探测主机。 或者,还可以禁⽌⼴播 ICMP,即设置 net.ipv4.icmp_echo_ignore_broadcasts = 1。
链路层
⽹络层的下⾯是链路层
链路层负责⽹络包在物理⽹络中的传输,⽐如 MAC 寻址、错误侦测以及通过⽹卡传输⽹络帧等。 由于⽹卡收包后调⽤的中断处理程序(特别是软中断),需要消耗⼤量的 CPU。所以,将这些中断处理 程序调度到不同的 CPU 上执⾏,就可以显著提⾼⽹络吞吐量。这通常可以采⽤下⾯两种⽅法。
⽐如可以为⽹卡硬中断配置 CPU 亲和性(smp_affinity),或者开启 irqbalance 服务。
再如,可以开启 RPS(Receive Packet Steering)和 RFS(Receive Flow Steering),将应⽤程序和软 中断的处理,调度到相同 CPU 上,这样就可以增加 CPU 缓存命中率,减少⽹络延迟。
另外,现在的⽹卡都有很丰富的功能,原来在内核中通过软件处理的功能,可以卸载到⽹卡中,通过硬 件来执⾏。
TSO(TCP Segmentation Offload)和 UFO(UDP Fragmentation Offload):在 TCP/UDP 协议中直 接发送⼤包;而 TCP 包的分段(按照 MSS 分段)和 UDP 的分⽚(按照 MTU 分⽚)功能,由⽹卡来完 成 。
GSO(Generic Segmentation Offload):在⽹卡不⽀持 TSO/UFO 时,将 TCP/UDP 包的分段,延迟 到进⼊⽹卡前再执⾏。这样,不仅可以减少 CPU 的消耗,还可以在发⽣丢包时只重传分段后的包。
LRO(Large Receive Offload):在接收 TCP 分段包时,由⽹卡将其组装合并后,再交给上层⽹络处 理。不过要注意,在需要 IP 转发的情况下,不能开启 LRO,因为如果多个包的头部信息不⼀致,LRO 合并会导致⽹络包的校验错误。
GRO(Generic Receive Offload):GRO 修复了 LRO 的缺陷,并且更为通⽤,同时⽀持 TCP 和 UDP。
RSS(Receive Side Scaling):也称为多队列接收,它基于硬件的多个接收队列,来分配⽹络接收进 程,这样可以让多个 CPU 来处理接收到的⽹络包。
VXLAN 卸载:也就是让⽹卡来完成 VXLAN 的组包功能。
最后,对于⽹络接口本⾝,也有很多⽅法,可以优化⽹络的吞吐量。
⽐如,可以开启⽹络接口的多队列功能。这样,每个队列就可以⽤不同的中断号,调度到不同 CPU 上执 ⾏,从而提升⽹络的吞吐量。
再如,可以增⼤⽹络接口的缓冲区⼤小,以及队列⻓度等,提升⽹络传输的吞吐量(注意,这可能导致 延迟增⼤)。
还可以使⽤ Traffic Control ⼯具,为不同⽹络流量配置 QoS。
在单机并发 1000 万的场景中,对 Linux ⽹络协议栈进⾏的各种优化策略,基本都没有太⼤效果。因为 这种情况下,⽹络协议栈的冗⻓流程,其实才是最主要的性能负担。
这时,可以⽤两种⽅式来优化。
第⼀种,使⽤ DPDK 技术,跳过内核协议栈,直接由⽤⼾态进程⽤轮询的⽅式,来处理⽹络请求。同 时,再结合⼤⻚、CPU 绑定、内存对⻬、流⽔线并发等多种机制,优化⽹络包的处理效率。
第⼆种,使⽤内核⾃带的 XDP 技术,在⽹络包进⼊内核协议栈前,就对其进⾏处理,这样也可以实现很 好的性能。