领域转移
根据分布移位发生的具体部分,域移位可分为三种类型,包括协变量移位、先验移位和概念移位

协变量移位:
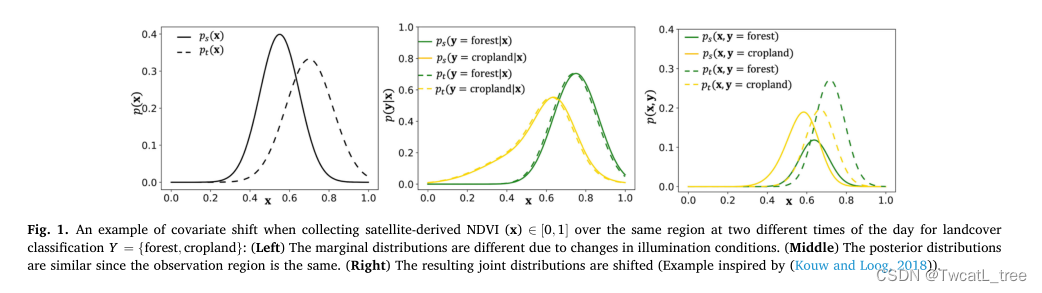
在协变量移位的情况下,源域和目标域的边际分布是不同的,即ps(x)∕= pt(x),而给定x的y的后验分布在域之间保持相似,即ps(y|x)≈pt(y|x)(图1)。当不同的传感器、遥远的地理区域或不同的时间窗采集相同光谱波段的数据时,就会发生协变量移位。例如,Landsat-8和Sentinel-2都提供可见光和近红外波段的观测。然而,其传感器之间的中心波长、带宽和空间分辨率的变化可能导致Landsat-8数据和Sentinel-2数据之间的协变量偏移,即使在观测相同的土地覆盖时也是如此(Wu et al., 2022)。同样,当使用无人机图像进行植物病害识别时,由于光照条件的变化,在一天中的不同时间窗口收集数据时,预计会发生协变量移位(Liu and Wang, 2021)。
先验移位:
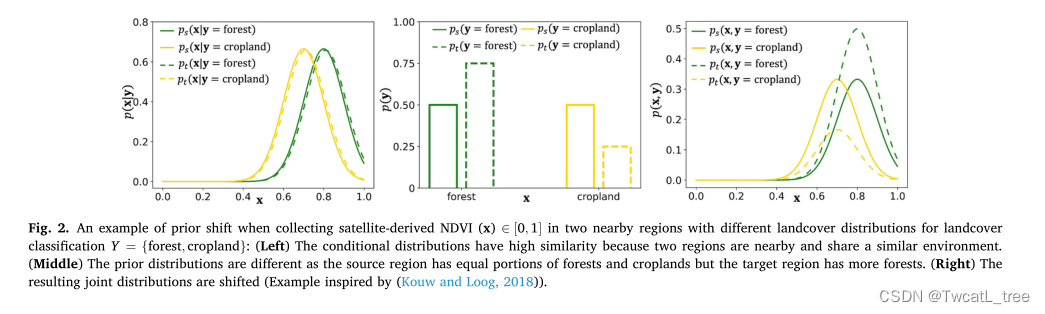
在先验移位的情况下,条件分布具有很高的相似性,但源域和目标域的标签空间的先验分布不同,即ps(y|x)≈pt(y|x)和ps(y)∕= pt(y)(图2)。当源域和目标域的标签空间不同时,就会发生先验移位。例如,在土地覆盖分类中,源域数据集通常包含包含许多土地覆盖类别的广阔区域,每种类型的出现频率相同。相比之下,目标领域可能限于一个较小的地理区域,其特征是标签的分布非常不同。因此,我们预计这两个领域之间将发生重大的先验转变。
概念转移:
在概念转移中,特征变量和响应变量在源域和目标域中的关系是不同的。具体来说,协变量的边际分布是相同的,但条件分布是不同的,即ps(x)≈pt(x)和ps(y|x)∕= pt(y|x)(图3)。当遥感观测未能捕捉到影响因素时,会发生条件移位。例如,两个国家的玉米田即使具有相似的反射率,其产量也可能不同,因为灌溉或虫害防治等因素可能影响作物产量,但遥感观测无法完全捕捉到这些因素,从而导致特征变量与响应变量之间的关系不同。另一个例子是土壤水分估算,由于土壤质地和气候的变化,相同的光谱反射率值可能对应不同地区不同的土壤水分值。
为了解决领域转移问题,提高机器学习模型的可移植性,人们提出了将知识从数据丰富的源领域转移到数据稀缺的目标领域。其思想是将模型在源域中学习到的知识和特征表示转移到目标域中完成任务,减少所需的数据量,提高模型在目标域中的精度和效率。基于不同类型域转移的特点和标记数据的可及性,开发了不同的迁移技术。
迁移学习技术的分类
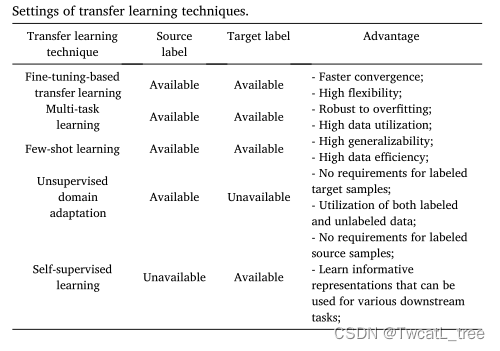
基于微调的迁移学习
基于微调的TL (FTL)是深度神经网络(DNN)的一种流行TL技术,已广泛应用于各种遥感应用(Gadiraju和Vatsavai, 2020;Wang等人,2018b)。FTL涉及首先在Ds中预训练模型,并在Dt中微调其参数(图4)。为了学习鲁棒和可推广的特征表示,使用大型、多样化的数据集预训练模型至关重要。因此,源样本的数量通常大于目标样本的数量(Ns > Nt),并且源和目标域中的学习任务是相关的。然而,当目标域中的标记样本不足时,对整个神经网络进行微调可能导致过拟合(Mehdipour Ghazi et al., 2017)。幸运的是,深度学习模型具有分层架构,可以在不同的层学习不同的特征。研究发现,最初的层倾向于捕捉通用特征,而后面的层更多地关注特定任务(Yosinski et al., 2014)。因此,一些研究冻结了预训练的深度学习架构的早期层的权重,并通过微调或重新训练最后几层来定制给定任务的模型(Abdalla et al., 2019)。超光速的一个优点是,它允许先进的预训练模型适应各种领域。流行的深度架构,如GoogLeNet (Szegedy等人,2015),VGG (Simonyan和Zisserman, 2015), ResNet-50 (He等人,2016),是在具有数百万图像的大型数据集上训练的,如ImageNet (Deng等人,2009)。通过超光速,这些模型可以适用于只有少量数据样本的新任务,并且仍然经常获得最先进的结果。此外,由于FTL在目标域中使用标签,它可以解决所有类型的域转移。然而,需要注意的是,FTL的有效性取决于Ds和Dt中学习任务的相关性。当预训练任务和新任务在同一范围内时(如图像分类),它更有可能起作用。
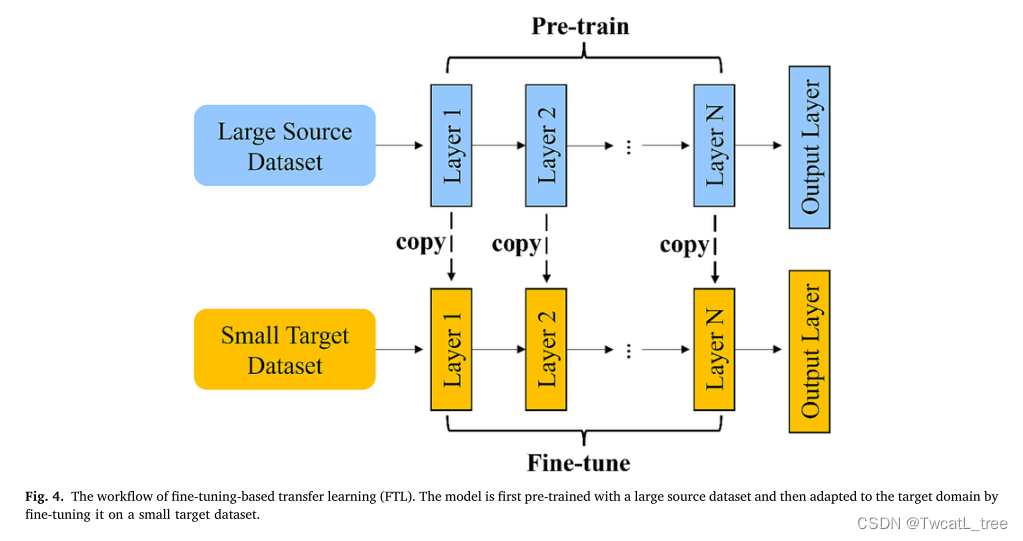
多任务学习
与单任务学习为一个任务建立模型不同,多任务学习(MTL)是一种TL技术,其中训练单个模型同时执行多个任务(Zhang and Yang, 2022)。在MTL中,每个学习任务都可以看作是一个域。MTL的目标是最大化模型的泛化性,并提高模型在一个或多个任务上的性能。所有领域都有一个共享的特性集,而它们的学习任务不同但又相关。对MTL模型进行训练,以提取对两个任务都有信息的跨域特征,从而提高模型的泛化性。例如,神经网络通常用于MTL,其设计为每个域具有一组共享的中间层和特定于任务的输出层(图5)(Feng et al., 2021;Nguyen等人,2019)。权重共享中间层作为特征提取器提取可泛化和鲁棒的特征,而独立的任务特定层用于对每个任务进行预测。在MTL中,从每个任务获得的知识是共享的,与为每个任务训练单独的模型相比,可以提高性能。为多个任务训练单个模型也可以作为一种正则化形式,这可以防止对任何单个任务的过拟合,并提高模型的泛化性能。此外,MTL可以提高可用数据的利用率。当难以为每个任务单独获取大量标记数据时,可以使用MTL来为多个任务利用标记数据的可用性。MTL的有效性取决于任务的相关性,高相关性的任务允许模型学习对每个领域有用且可转移的知识(Zhang and Yang, 2022)。通常,MTL中的每个域都应该共享相同的特征空间。最近一些关于不同领域的相关性和冗余的研究放宽了这一限制,并使MTL可以在多种类型的输入上工作(Zamir等人,2019)。
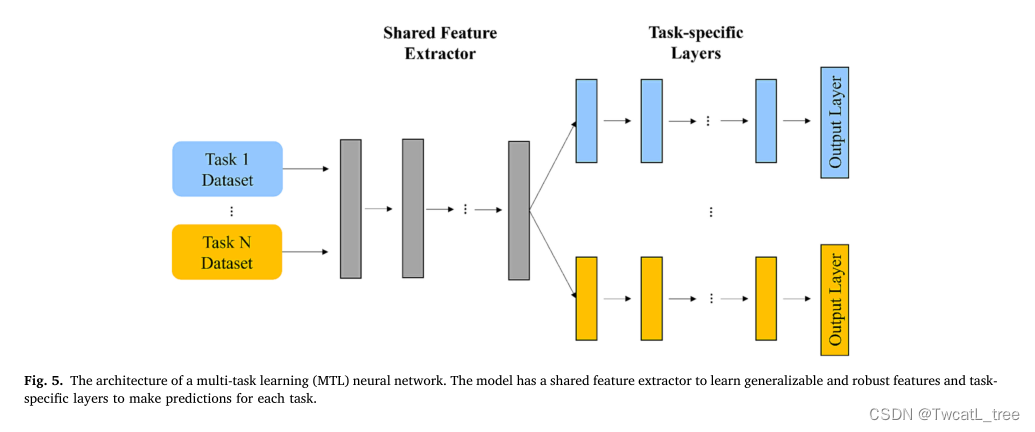
Few-shot学习
few -shot learning (FSL)是一种机器学习技术,其中训练模型使用很少的标记样本来推广到新任务(Wang et al., 2020)。与FTL相比,FSL对标记数据样本的数量有严格的要求。在FSL中,使用了各种技术,如元学习和度量学习(Wang et al., 2020;Yang et al., 2022)。此外,FTL侧重于使预训练模型适应相关任务,如果没有额外的微调或再训练,可能无法很好地泛化到显著不同的任务或领域,而FSL旨在处理不同的任务,并更容易泛化到新的和未见过的数据。支持集和查询集是FSL的两个重要组成部分(图6)。具体来说,支持集是一个小的标记样本集合,用来帮助学习新的任务。查询集是一组来自目标域的未标记样本,用于模型评估。查询集通常包含来自与支持集相同的类的示例,但与支持集中的示例不同。查询集用于评估在给定支持集中有限的标记示例的情况下,模型泛化到新示例和类的能力。FSL中的支持集和查询集可以看作分别类似于源域和目标域。基于样本可用性,FSL方法可以大致分为三种类型,包括few -shot(每个类的几个训练样本),One-shot(每个类的单个训练样本)和zero -shot(每个类的零训练样本)(Lu et al., 2023)。根据学习策略的不同,FSL方法可以进一步分为四种类型(Wang et al., 2020;Yang et al., 2022),包括基于数据的FSL、基于度量的FSL、基于优化的FSL和基于模型的FSL。提出了基于数据的FSL方法,通过生成合成数据样本的数据增强来解决新任务缺少标记训练数据的问题。这种方法包括学习生成模型,如变分自编码器或生成对抗网络(GAN)。基于度量的FSL是研究最广泛的方法(Sung et al., 2018),其中模型旨在学习一个度量或相似性函数,该函数可以将查询示例与任务的支持示例进行比较,并根据相似性进行预测(图6)。基于支持集和查询集之间的相似性得分,模型可以对未见过的查询样本进行推断和预测。基于优化的FSL旨在学习一个合适的初始化参数,并在不过度拟合的情况下,在几个步骤内更新模型参数。基于模型的FSL试图从模型体系结构的角度实现快速适应。示例包括基于外部存储器的方法,其中在模型中添加额外的存储器模块以存储少数未见过的样本的特征信息(Wang et al., 2020;Yang et al., 2022)。总之,FSL使模型能够快速适应和推广到具有有限标记数据的新领域。FSL利用来自类似任务的先验知识,使他们能够有效地学习新概念。更重要的是,FSL提供了高度的灵活性,使模型能够很好地泛化到不可见的任务,这使得FSL适用于经常出现新数据和任务的现实应用程序。相应地,FSL可以用来解决先前的转移,并对新的和未见过的任务表现出很强的适应性。
无监督域自适应
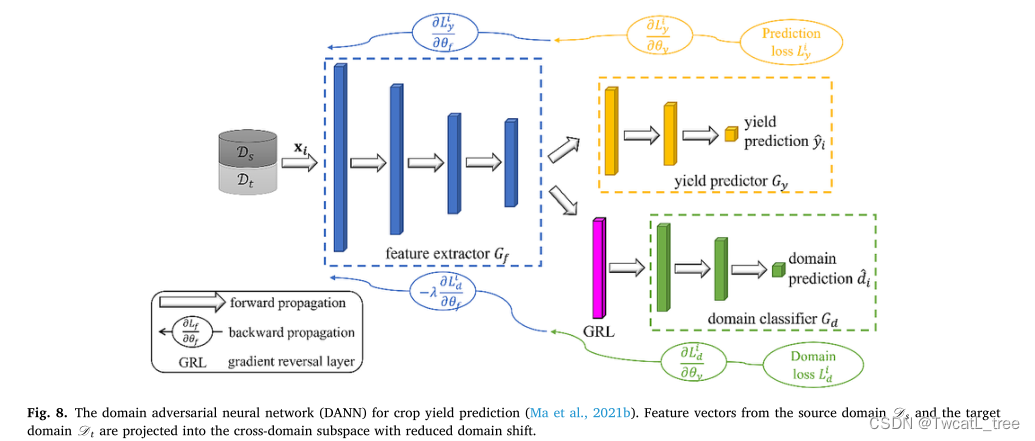
无监督域自适应(UDA)通过基于标记的源数据和未标记的目标数据对齐源和目标域中的特征分布来解决域移位问题(图7)(Tuia et al., 2016)。在UDA设置下,Ds和Dt具有相同的学习任务,Ds中有足够的标记样本,而Dt中只有未标记样本(Zhao et al., 2022b)。UDA模型通常被设计成具有两个目标的共轭体系结构,分别完成主要学习任务和减少域漂移的任务。主要目标是通过最小化相应的损失函数,例如回归的均方误差(MSE) (Sun et al., 2022)和分类的交叉熵损失(Kwak and Park, 2022),来学习基于源域标记样本的任务特定模型。另一个目标是通过减少域移来对齐Ds和Dt之间的特征分布。基于特征对齐策略,UDA方法大致可分为基于转换的方法、基于差异的方法、基于对抗的方法和基于生成的方法(Kouw和Loog, 2019;Wang and Deng, 2018)。基于转换的方法将源域和目标域的实例映射到具有可转移组件的子空间。代表性的例子包括传递分量分析(TCA) (Pan et al., 2011),它通过使用权重矩阵对源数据和目标数据的核特征进行线性组合,将它们转换成一个共同的特征空间。基于差异的方法通过最小化其分布差异来对齐源和目标特征,例如最大均值差异(Othman等人,2017)、Wasserstein差异(Shen等人,2018)和矩差异(Zellinger等人,2017)。然而,基于差异的方法通常涉及高复杂性的差异计算(Chadha和Andreopoulos, 2019)。最近,基于对抗性的模型由于其训练简单和在最小化领域转移方面的成功而变得越来越流行。基于对抗性的模型通过对抗性学习进行训练,直到源域和目标域对齐。领域对抗神经网络(DANN)是最流行的基于对抗的UDA模型之一(图8),其中使用领域分类器来测量领域移位,并针对领域分类器对抗性地训练特征提取器以提取领域不变特征(Ganin等人,2017)。此外,基于生成的方法基于GAN来实现源域和目标域之间的风格转换(Bellocchio et al., 2020)。这些方法通常使用生成器,通过转换源数据以匹配目标域的样式来减少域移位。本质上,UDA通过对齐源域和目标域中的特征分布来减少域漂移。它使ML和DL模型在不同的领域之间更加一般化和可转移,而不需要从目标领域获得标记的数据样本。UDA方法利用标记和未标记的数据,从而提高了模型在目标任务上的性能。大多数UDA方法旨在减少协变量移位。一些UDA的变体,如部分域自适应(PDA),可以通过部分对齐共享标签空间中的源域和目标域来解决先验偏移(Gu et al., 2021;Zhang et al., 2018)。还提出了减少概念转移的UDA方法,例如最大分类差异(MCD) (Saito et al., 2018)。

Self-supervised学习
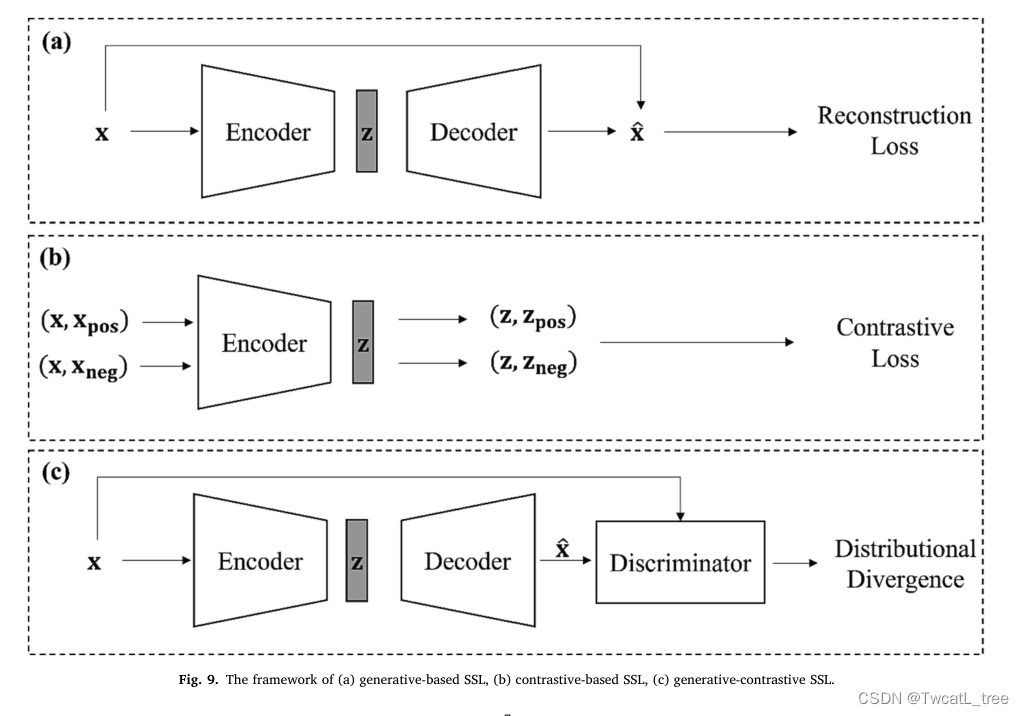
上述TL技术可以有效地减少对标记目标样本的依赖,但仍然需要来自源域的训练样本。然而,识别一个相关的源域仍然需要时间,我们可以从中学习相关的知识并标记数据。减少对源标签的依赖并实现标签效率的一种有希望的方法是自监督学习(SSL),其中模型学习预测输入数据的某些属性或特征,而不需要显式标签或注释(Jaiswal等人,2020;Liu et al., 2023b)。SSL通过构建作为一种监督形式的借口任务来引入监督信号。根据模型架构和学习目标,主流SSL方法可以归纳为三类(Liu et al., 2023b),包括基于生成的SSL、基于对比的SSL和生成-对比的SSL(图9)。具体而言,基于生成的SSL通常采用学习重构输入数据的自编码器架构(图9 (a))。它由一个将输入数据x压缩成低维表示z的编码器和一个输出重构数据x的解码器组成。通过最小化重构误差,它学习到有用的数据表示。例子包括在自然语言处理(NLP)中预测给定前一个单词的下一个单词(Brown et al., 2020)。基于对比的SSL涉及训练编码器以获取表征z,该表征z捕获相似样本(正对(x, xpos))之间的共享特征,同时识别不同样本(负对(x, xnegative))之间的差异(图9 (b))。通常,正对由同一样本的两个不同视角组成,通过随机数据增强获得,而负对则使用数据集中不相关的样本形成(He et al., 2020)。通过最小化对比损失,编码器被训练来提取有意义的特征z,并在未标记的数据中区分相关模式,从而促进下游任务的改进泛化。示例包括识别图像中打乱补丁的正确位置(Misra和Maaten, 2020)。生成-对比SSL,也称为基于对抗性的SSL,也利用了自动编码器架构。一个称为鉴别器的附加组件被引入并与自编码器一起训练(图9 ©)。鉴别器的作用是区分自编码器产生的生成数据x和原始输入数据x。自编码器和鉴别器以对抗的方式进行训练,以最小化生成数据和原始数据之间的分布差异。自编码器和鉴别器之间的这种相互作用促进了高质量表征z的发展,并有助于模型很好地推广到下游任务。例子包括着色(Cheng et al., 2015)和喷漆(Iizuka et al., 2017)。SSL方法适用于源域中没有标记样例的情况。在SSL阶段,训练模型来解决需要理解和从数据中捕获相关信息的借口任务,而不需要显式标记。这允许模型利用大量可用的未标记数据并学习有价值的知识。学习到的表示可以通过微调等技术适应特定的下游任务,其中ssl训练的模型在特定于下游任务的较小标记数据集上进一步训练。总之,特定任务的最佳TL技术取决于各种因素,如标记数据的可用性、源和目标学习任务的相关性以及学习任务的目标。具体来说,如果目标域中可用的标记数据数量有限,则可以考虑利用数据丰富的源域中预训练模型中的知识。如果手头有多个相关的任务,可以应用MTL通过在任务之间共享信息来提高一个或多个任务的性能。如果一个人主要处理先验转移,并且目标是将模型推广到新的任务,那么FSL可能是最佳选择。当源域和目标域具有相同的学习任务,并且目标域中没有可用的标签时,最适合使用UDA。最后,当没有合适的源域并且有大量未标记的数据可用时,最好使用SSL。此外,混合迁移学习(HTL)结合了两种或多种不同的迁移学习方法,在某些条件下可能是一种有效的技术。例如,有研究将FTL和UDA结合起来,使用预训练的深度模型作为UDA的主干(Sicilia et al., 2023)。研究人员还通过SSL对未标记的遥感图像进行模型训练,以学习具有代表性的特征。然后,训练后的模型通过FTL适应下游任务(Cong等人,2022)。html可以解决个别TL技术的一些限制。然而,优势将取决于具体的应用程序和所使用数据的质量。