大家好,我是白鲸开源的联合创始人代立冬,同时担任 Apache DolphinScheduler 的 PMC chair 和 SeaTunnel 的 PMC。作为 Apache Foundation 的成员和孵化器导师,我积极参与推动多个开源项目的发展,帮助它们通过孵化器成长为 Apache 的顶级项目。
今天的分享的主题其实还是从开源到商业,Apache SeaTunnel 本身就是做数据同步软件,也经历过 Apache 孵化器的孵化,目前已经毕业成为顶级项目,也会跟大家分享一下它的核心特性。包括为什么我们又重新造轮子,那 Doris 和 WhaleTunnel/SeaTunnel 这个多元实时数仓是怎么去解决一些社区用户的问题?另外也给大家分享一下我们社区的 roadmap 和最近的一些进展。
白鲸开源愿景与使命
白鲸开源其实是一家 DataOps 解决方案提供商,目前致力于数据调度和同步领域,简单理解就是大数据的降本增效。我们的目标是通过高效的数据处理解决方案来降低运营成本并提高效率。
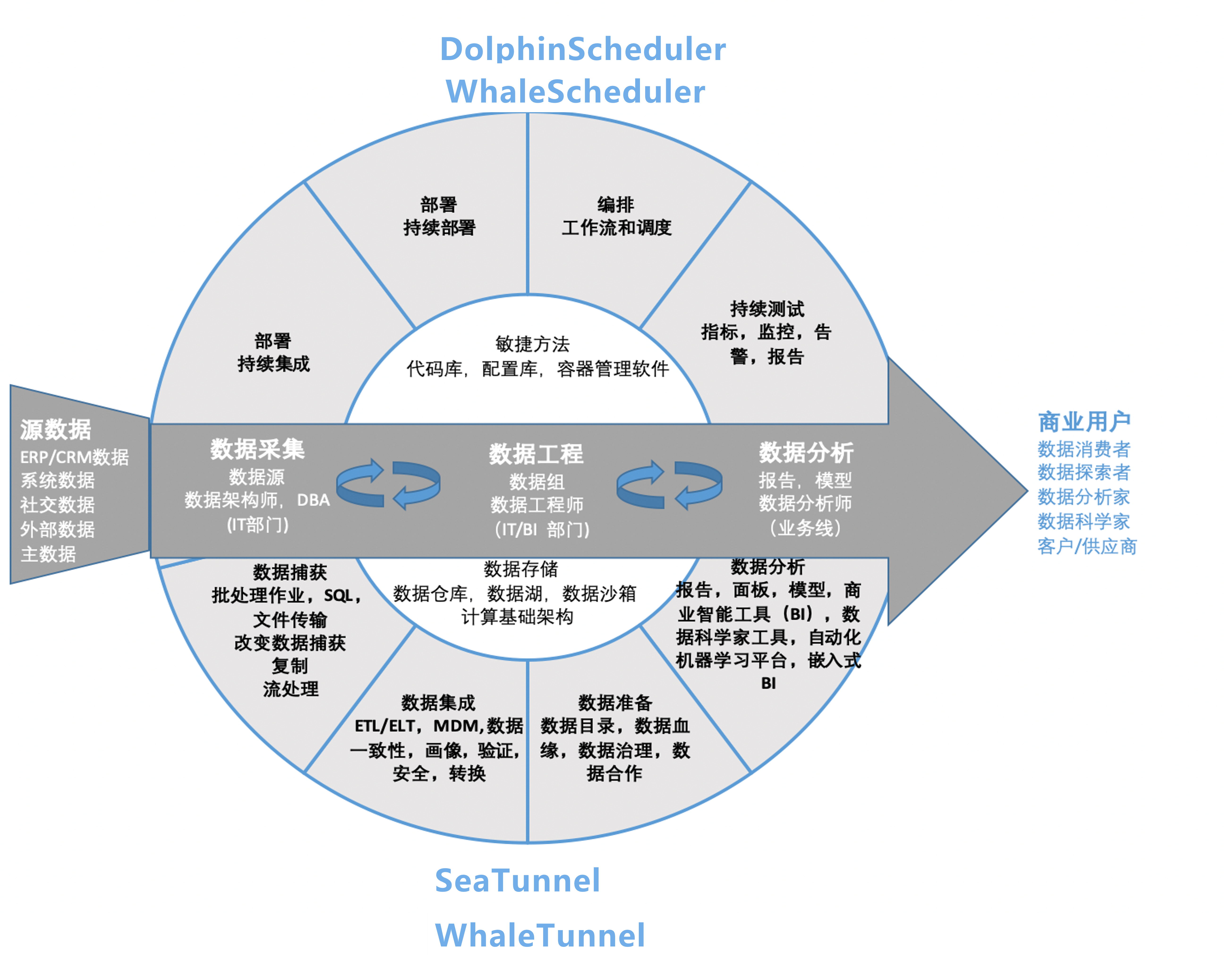
当前的重点是改善数据调度和同步的流程,或者是从开发到生产上线整个流程的打通,从而实现从开发到生产的快速过渡。
核心开源项目
我们主要投入于两个 Apache 顶级开源项目:Apache DolphinScheduler 和 Apache SeaTunnel。
DolphinScheduler 是一个分布式工作流调度平台,而 SeaTunnel 则专注于数据集成和同步。
这两个项目在国内影响力也越来越大,在整个大数据生态包括在数据处理和同步方面发挥着关键作用。
数据同步中的挑战
在数据同步领域,我们面临多种挑战,处理众多数据源、版本兼容问题、大数据量带来的数据丢失或重复问题。比如说像 Oracle,它有很多版本,而且每个版本之间是不兼容的,所以你需要去支持它的 CDC,或者是要能够去捕获到它的 DDL 变更这样的场景,每个版本你都要去考虑怎么去适配,这个工作量是很大的。
此外,如何保证数据的精确一致性,以及在出现问题时如何快速回滚?同步过程中需要监控等等,这些都是数据同步中面临的痛点问题。
还有一个痛点的情况,就是当你频繁地去读取 binlog,对数据源的影响会非常大,DBA 会非常关注对数据库源数据库端产生的压力情况,还有大事务 schema 变更会影响到下游,尤其数据量大的这种场景下,大家都会非常关心!
还有离线跟实时同步,通常以前都是需要分开写,这也是面临的问题,就是批是批,流是流,维护会非常的困难。
经常做数据迁移的小伙伴肯定会面临这样痛苦的过程,就是我要做数据迁移通常都是要以月/季的,数据迁移几个月、小半年这样的一个时间,SeaTunnel 的定位其实就是做一个高性能的数据集成工具,希望能够更多的像调度工具和上下游的这些工具去打通,我们也欢迎大家能够去集成 SeaTunnel 去做数据处理的这个事情!
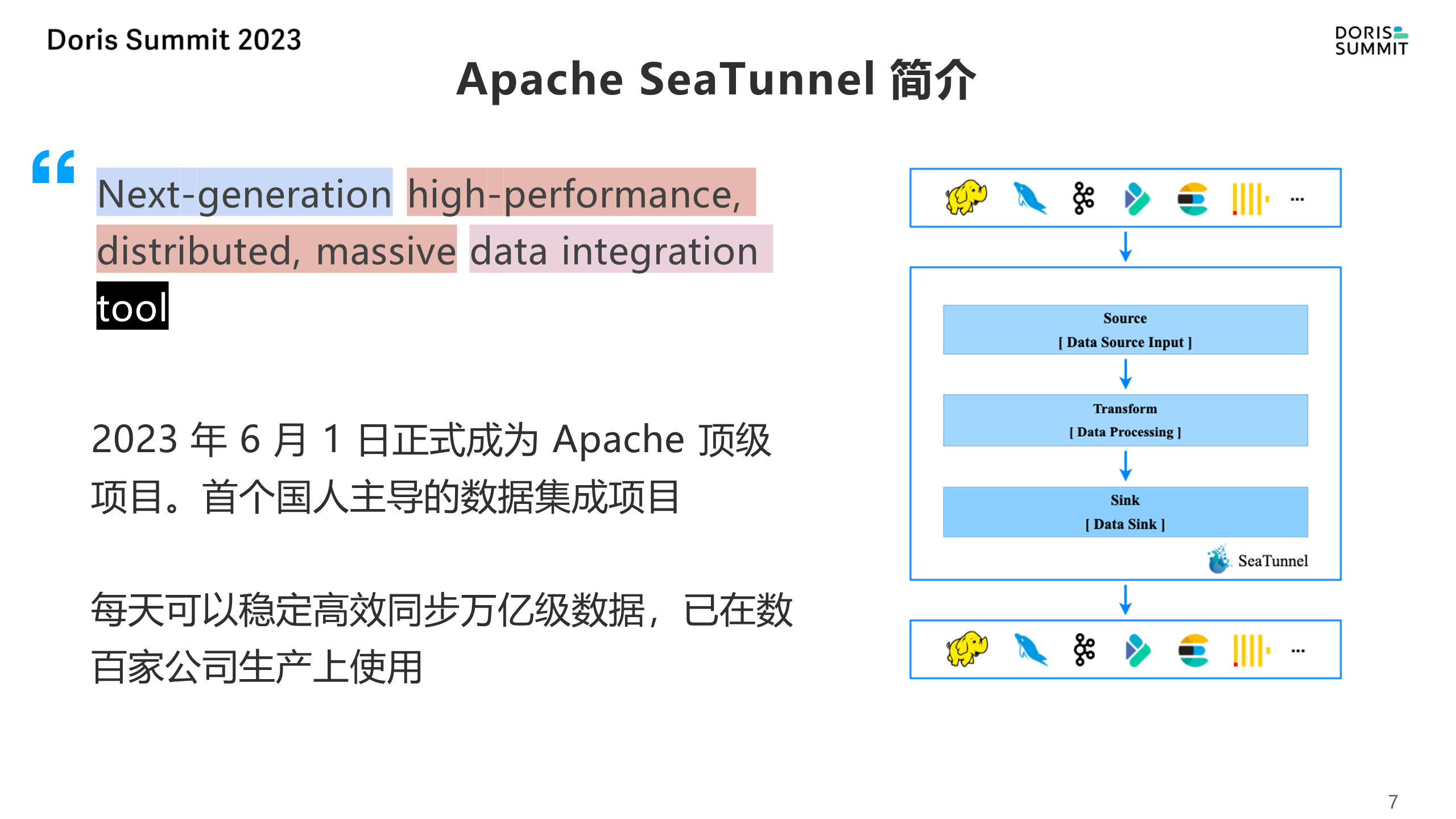
在今年的 6 月,Apache SeaTunnel 正式成为了 Apache 基金会的顶级项目,也是首个国人主导的数据集成项目在 Apache 基金会占了一席之地,它不仅能够应对每天同步万亿级的数据量非常大的场景,包括在海外现在也有一些很典型的案例,像在美国最大的商业银行JPMorgan、印度电信、英国最大的零售商等都应用在了生产的环境中,在国内像哔哩哔哩、唯品会每天同步上千亿的数据,这都是 SeaTunnel 的用户案例。
SeaTunnel 核心功能与目标
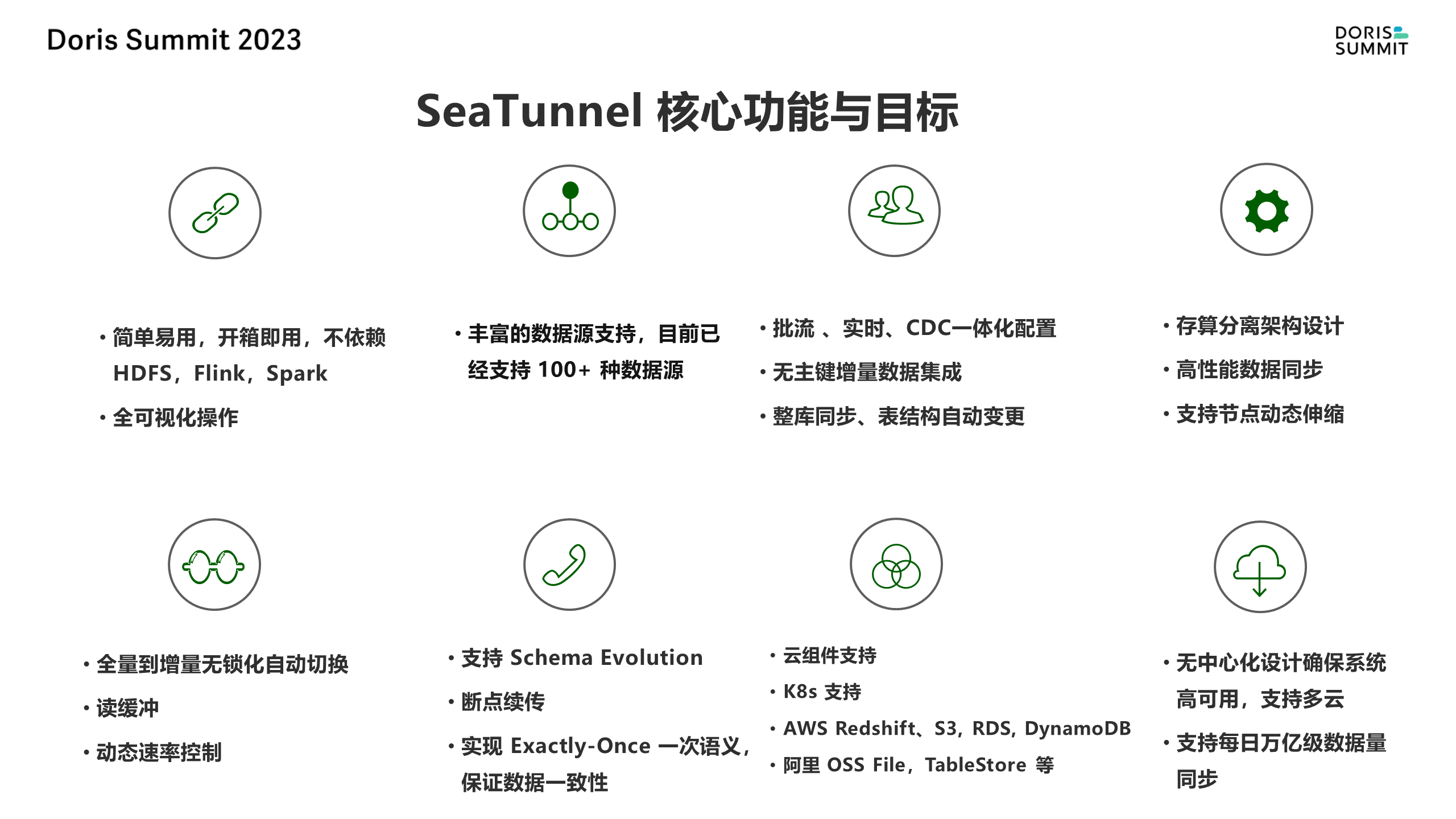
简单易用
SeaTunnel 的第一个目标是简单易用。为此,社区最近开源了一个拖拉拽的可视化版本,但距离真正的简单易用可能还有一些距离。同时,它既支持命令行操作,也支持 Web 可视化的操作。
支持多种数据源
目前,SeaTunnel 已经支持 100 多个数据源。这种广泛的兼容性使得它可以适应不同的数据环境。
批流一体
SeaTunnel 还支持批流一体的操作,这意味着不需要为批处理和流处理编写两套不同的代码。这种设计可以大大提高开发效率和代码维护性。
支持整库同步和自动变更
SeaTunnel 可以支持整库同步,同时也支持自动变更,这主要解决了数据切割的问题。全量到增量的无锁自动切换可以大大提高数据处理的效率。
支持读缓冲和动态速率控制
SeaTunnel 可以支持同一个源同步到多个目标,比如从 MySQL 同步到 Hive 或者 Doris。同时,它还支持动态速率的控制,尤其是源数据库端的小伙伴会非常关注这个功能。这种设计可以在保证数据处理效率的同时,防止因速率过快导致的资源浪费或者其他问题。
支持 schema 变更和断点续传
SeaTunnel 可以支持 schema 变更,即数据库结构的变化。同时,它还支持断点续传和精确一致性,这需要上下游数据库的配合才能实现。这种设计可以大大提高数据处理的稳定性和准确性。
支持云组件和精确一致性
SeaTunnel 不仅支持各种云组件,如 RedShift、S3、RDS、DynamoDB 等,还支持像阿里云的 OSS File、TableStore 等。
同时,它可以实现精确一致性,这是通过上下游数据库的配合实现的。这种设计可以大大提高数据处理的可靠性和准确性。
但是像 HDFS 它就做不到这个精确一致。MySQL 这些传统的数据库基本上都是可以做到精确一致
比如说我们要从 MySQL 要去同步到 Doris,或者有些场景可能比如说要从 Mongo 去同步,或者是从 Oracle、MySQL 要去同步到这个像 Doris 的这样的去做 OLAP,去做这个一些实时数仓的一些场景会比较常见一些。比如说它是否能支持双向同步,我也可以支持各种数据源之间的 Source,以及目标端 Sink,这是它的数据去向。
适用场景
SeaTunnel 适用于从各种数据源到各种目标的数据集成和同步场景。它支持双向同步,可以支持各种数据源之间的 Source 以及目标端的 Sink。
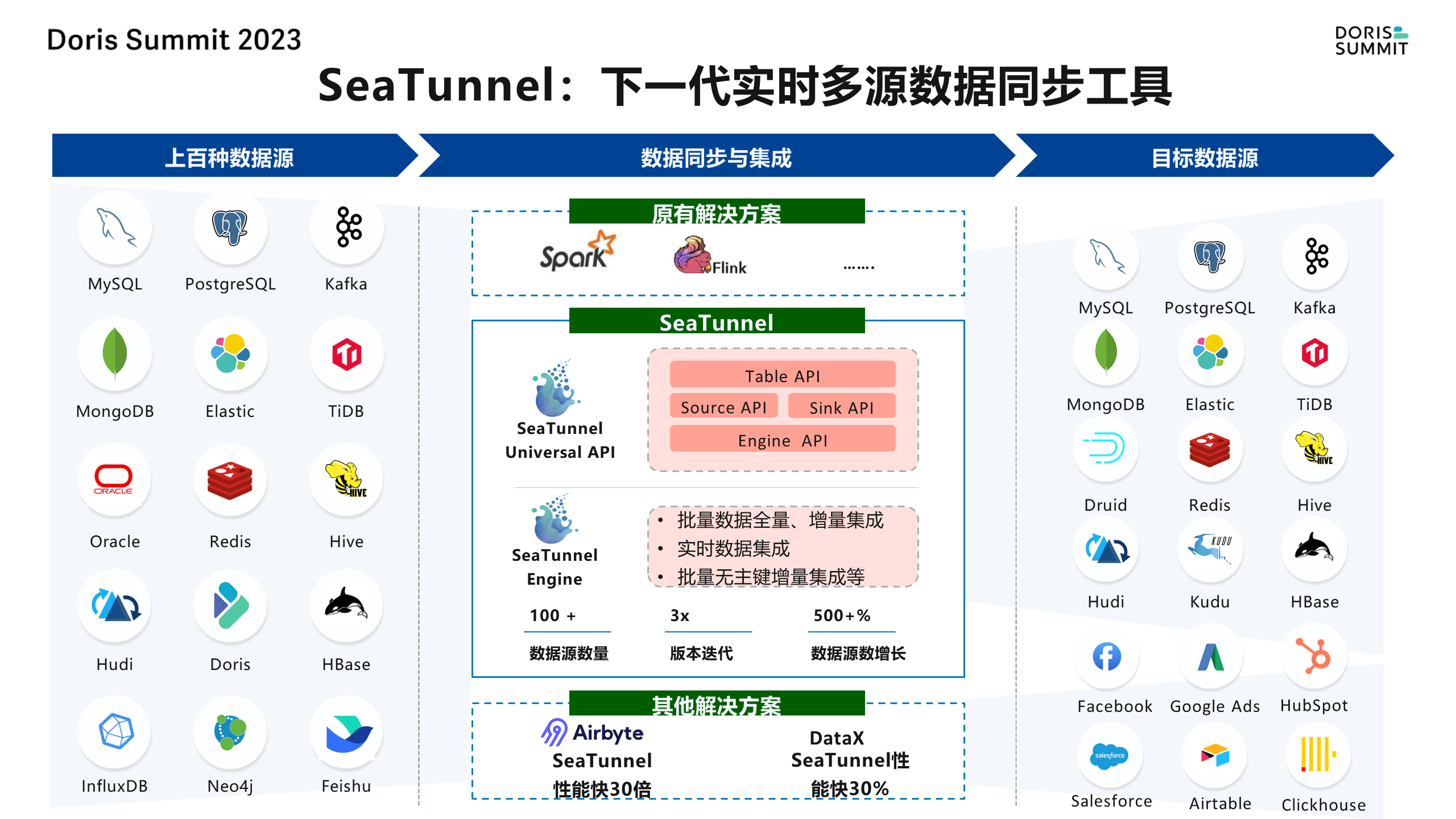
以前常见的互联网解决方案,有一些Spark和Flink的场景,那现在你 SeaTunnel 的时候,它会有一个 API,它其实是可以支持跑在 Spark、Flink 上的。它还有一个 Source API,其实是用于扩展各种数据源,我们的目标其实是连接各种数据源,不仅仅是数据库,那还有 SaaS,还有 API 接口,那还有一些本地的文件数据。
此外,它还支持批量、全量、增量的集成,甚至无主键的数据也可以支持。
性能优势
与一些常见的互联网解决方案相比,例如 Airbyte 和 Data X 单机版,SeaTunnel 的性能要快 30 多倍。
我们跟 Data X 的 PK 时候只有单机,一般是 30% - 50% 之间,它的单机做得还可以。但是它没有集群化的版本,也只能做离线的场景。
迭代速度优势
另一个值得称赞的是,SeaTunnel 的版本迭代速度非常快,基本上每个月都会发布一个新的版本。这种快速迭代的速度不仅增加了功能的新颖性和实用性,也提高了整个项目的活力和竞争力。
架构简介
Apache SeaTunnel 的整体架构是无中心化的,类似于 DolphinSchedule 的设计,已经是非常成熟的一个架构了。这种设计可以保证数据从源到目标的流畅传输。
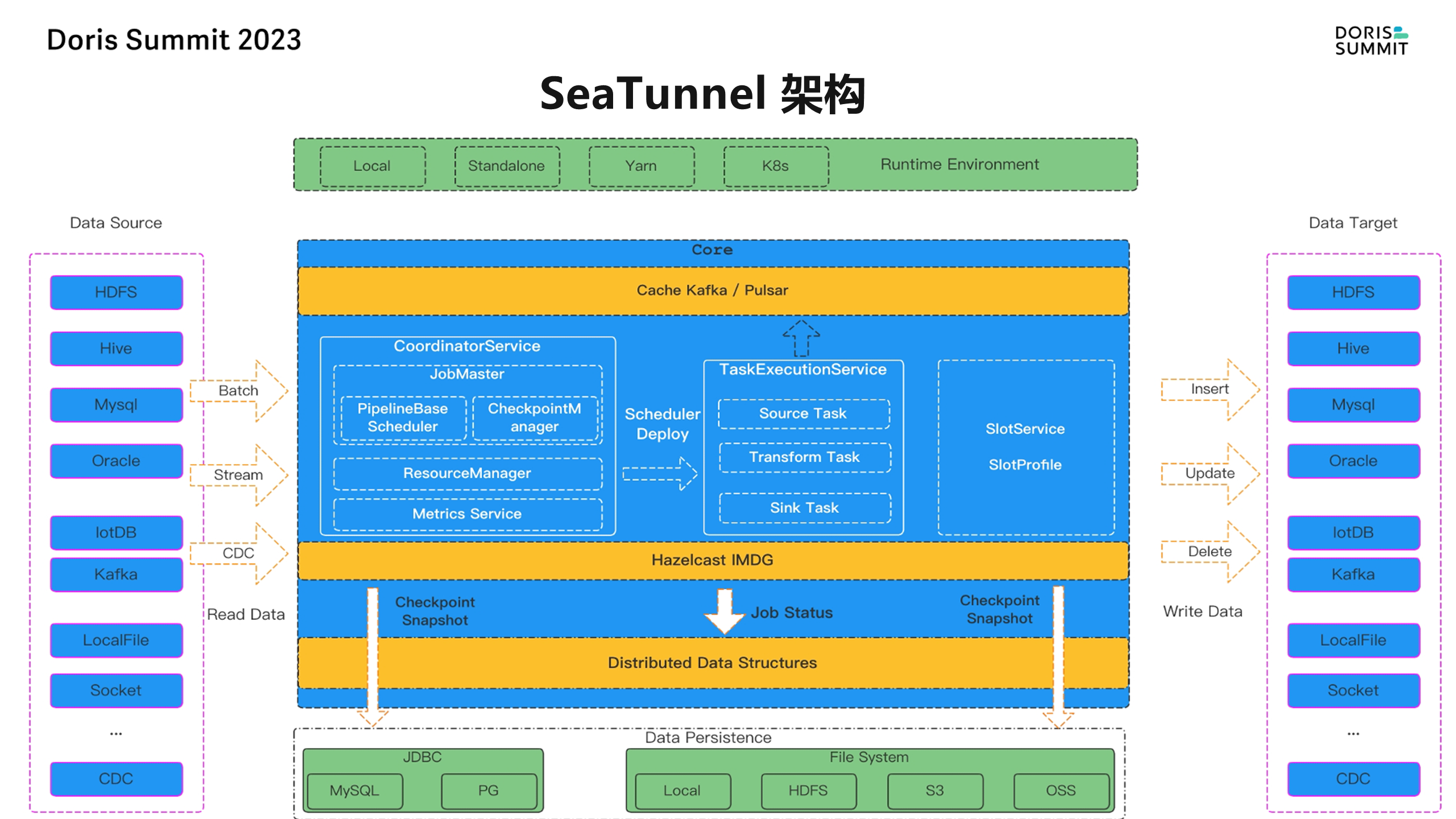
它的核心思想是将任务分解成多个 pipeline,如果某个链条出现问题,用户只需回滚相应的链条,而不是整个作业。这种设计在时间和资源成本上更加节约,同时也提高了性能。
从上图左侧来说它是支持各种源,有 batch、stream、 CDC 的场景,也有这个各种需要去读数据 read data,然后读到 SeaTunnel 这个架构之上,其实就是也有一个 coordinator,是充当了一个 master 的角色,大家把它理解成一个 master,然后 task execution service 其实就是做具体任务的,把它理解成 worker 这样的一个角色,可以这么去理解, master 是负责去分配这任务,然后 worker 是去执行具体的任务,但 worker 执行任务的时候,它其实会分到底是读取的任务,还是做数据转换的任务,还是去写的任务?
而 read task、write task,或是做 convert transform 的 task,这里边其实会有 master,还有 resource manager 去做资源管理以及做 pipeline 设计!
此外,SeaTunnel 使用了动态线程共享技术,避免了资源浪费。以 Spark 为例,启动作业时需要消耗大量的内存,而使用 SeaTunnel 或其商业版 WhaleTunnel,内核可以最大限度地被共享,内核与开源版保持一致。
架构特性
SeaTunnel 支持 Flink 和 Spark,并在近两年设计了一个专为数据同步场景设计的引擎 Zeta。
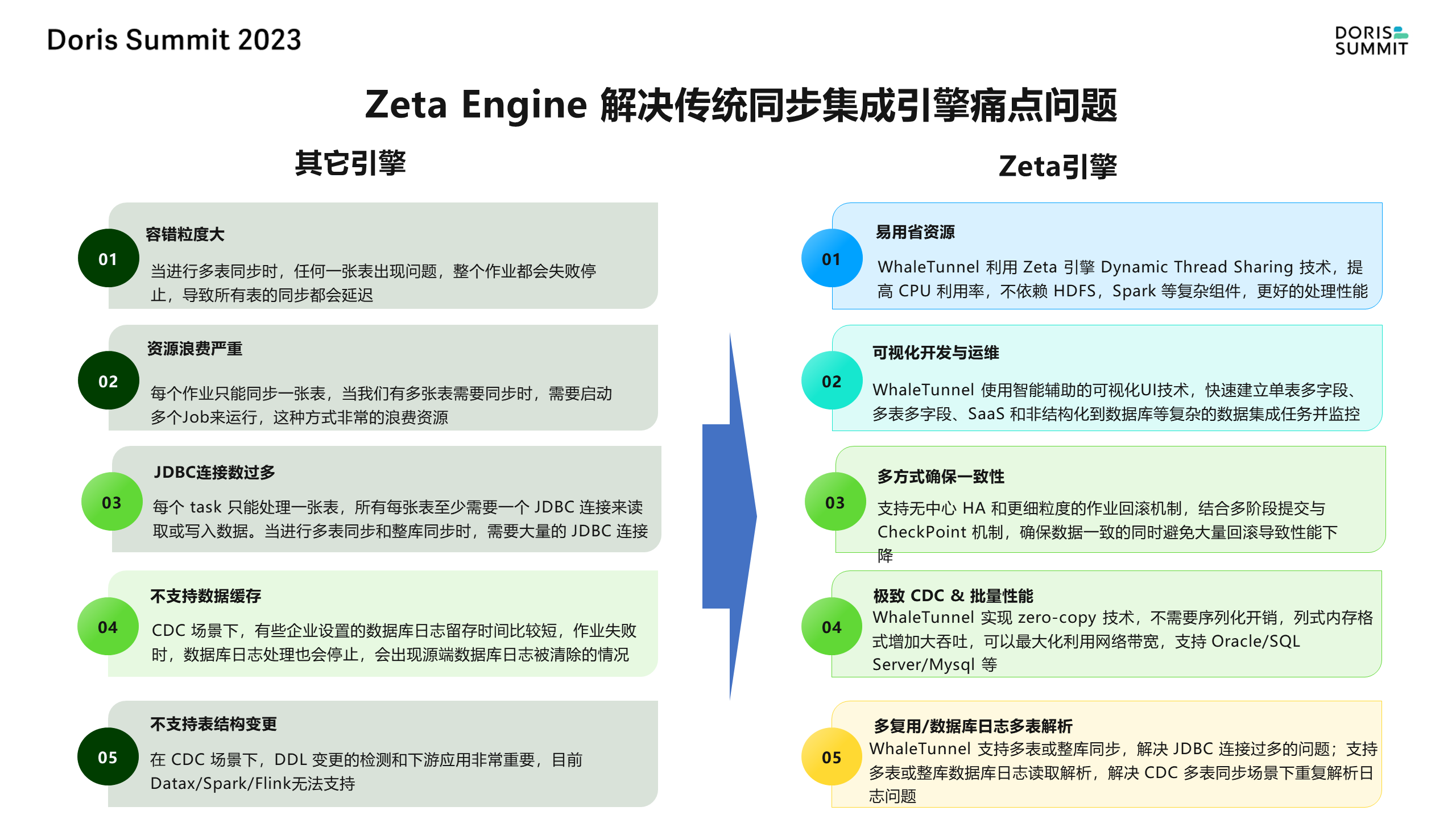 尽管 Spark 和 Flink 也是为计算而生的,但数据同步的要求与计算有所不同,它更强调性能、稳定性和支持的数据源数量。因此,我们推荐使用 Zeta 引擎。
尽管 Spark 和 Flink 也是为计算而生的,但数据同步的要求与计算有所不同,它更强调性能、稳定性和支持的数据源数量。因此,我们推荐使用 Zeta 引擎。
此外,SeaTunnel 解决了 Spark 和 Flink 等场景中存在的问题。 任务出错时需要回滚整个作业; 可视化开发方面也没有提供完整的解决方案; 对于资源占用过多的场景,一个 task 只能处理一张表,这可能导致资源浪费和影响 DBA 业务场景; 以及对表结构变更、CDC 等场景的不支持。
而 SeaTunnel 正是为了解决这些问题而设计的。
解耦设计
另一个重要的特性是 SeaTunnel 与执行引擎解耦。最早的版本只支持 Spark,但随着 Spark 版本的升级,我们面临着兼容性问题。每个 Connector 都需要为不同的版本重新设计实现,这是一项耗时且繁琐的工作。因此,我们定义了一套 SeaTunnel 自己的 API,与具体的执行引擎解耦。这样,当新的更快、更高性能的数据引擎出现时,我们只需要更新 Connector 即可。
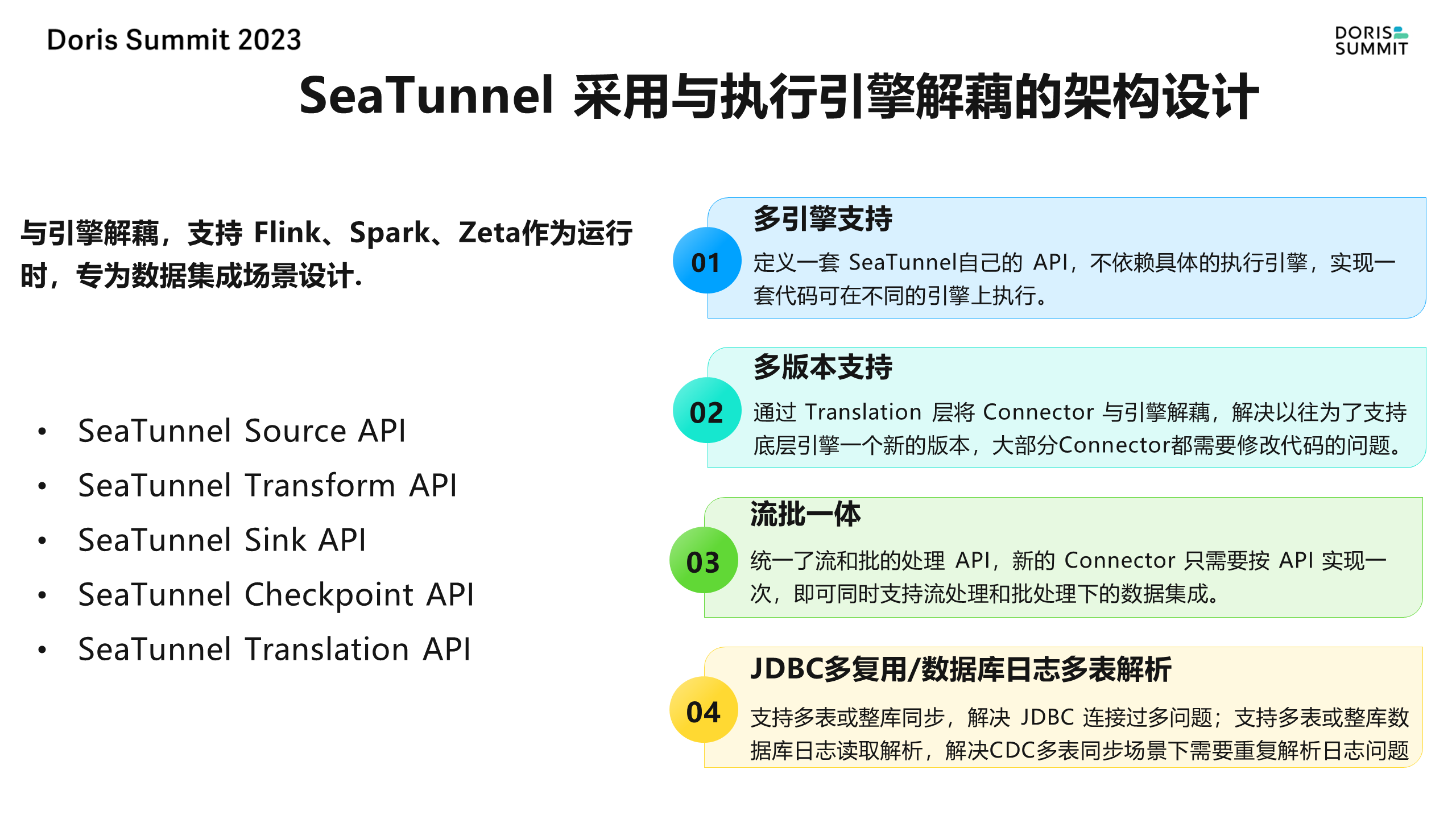
此外,我们还提供了 Source API、Sink API、checkpoint API 和 translation 层等多种 API,通过翻译层将每个卡点翻译成 Flink、Spark、Zata 等不同引擎的底层 API,避免了每个 Connector 都需要适配的问题。同时,也支持流批一体的新 Connector,只需按 API 实现一次即可。
总之,SeaTunnel 的架构和特性使其成为解决数据同步等场景的理想选择。它不仅提供了简单易用的界面和强大的功能,还通过与执行引擎解耦和多种 API 的支持提高了效率和性能。
无中心化设计
前面提到了 SeaTunnel 采用了无中心化的设计,每个 server 都可以充当 master 的角色,也可以充当 worker 的角色。这种设计具有自动选举功能,确保了系统的稳定性和可靠性。

同时,它还支持弹性的伸缩,例如在进行精确处理时,会涉及到 checkpoint 以及分布式快照的创建,以确保数据的完整性和一致性。
这种设计也支持断点续传,对于因异常导致的数据传输中断,可以自动回退到上一个切割方向的点,保证数据传输的连续性和完整性。
性能测试与对比
为了测试 SeaTunnel 的性能,我们进行了一些场景的测试。
从 MySQL 到 Hive,PG 到 Hive,SQL Server 到 Hive 和 Oracle 到 Hive 的场景中,SeaTunnel 的同步速度比 Data X快 30%-50%。
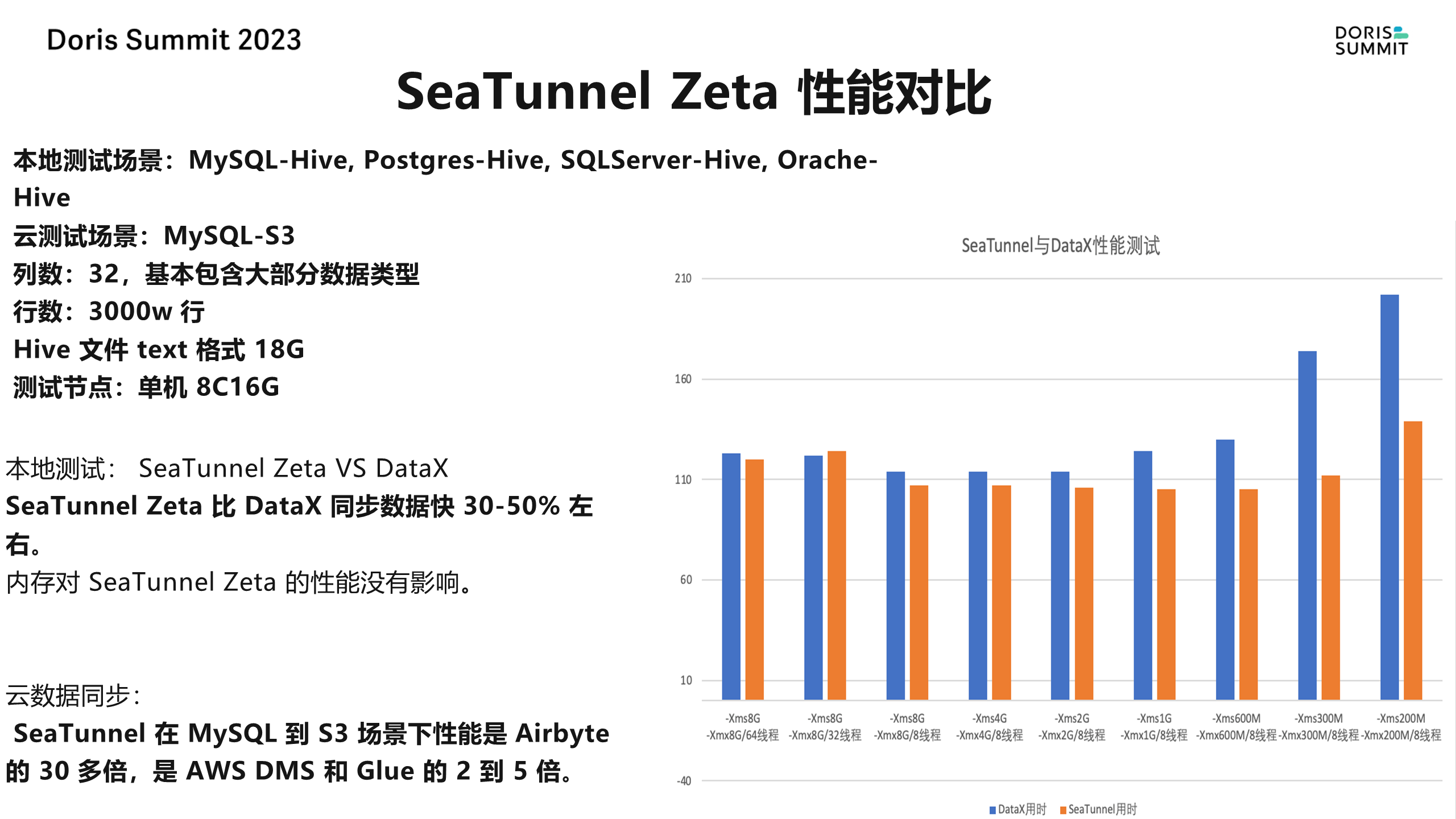
在云同步的场景中,SeaTunnel 的表现更为出色,其性能是 Airbat 的 30 多倍,与 AWS 的数据同步工具 Glue 相比,也快2-5 倍。
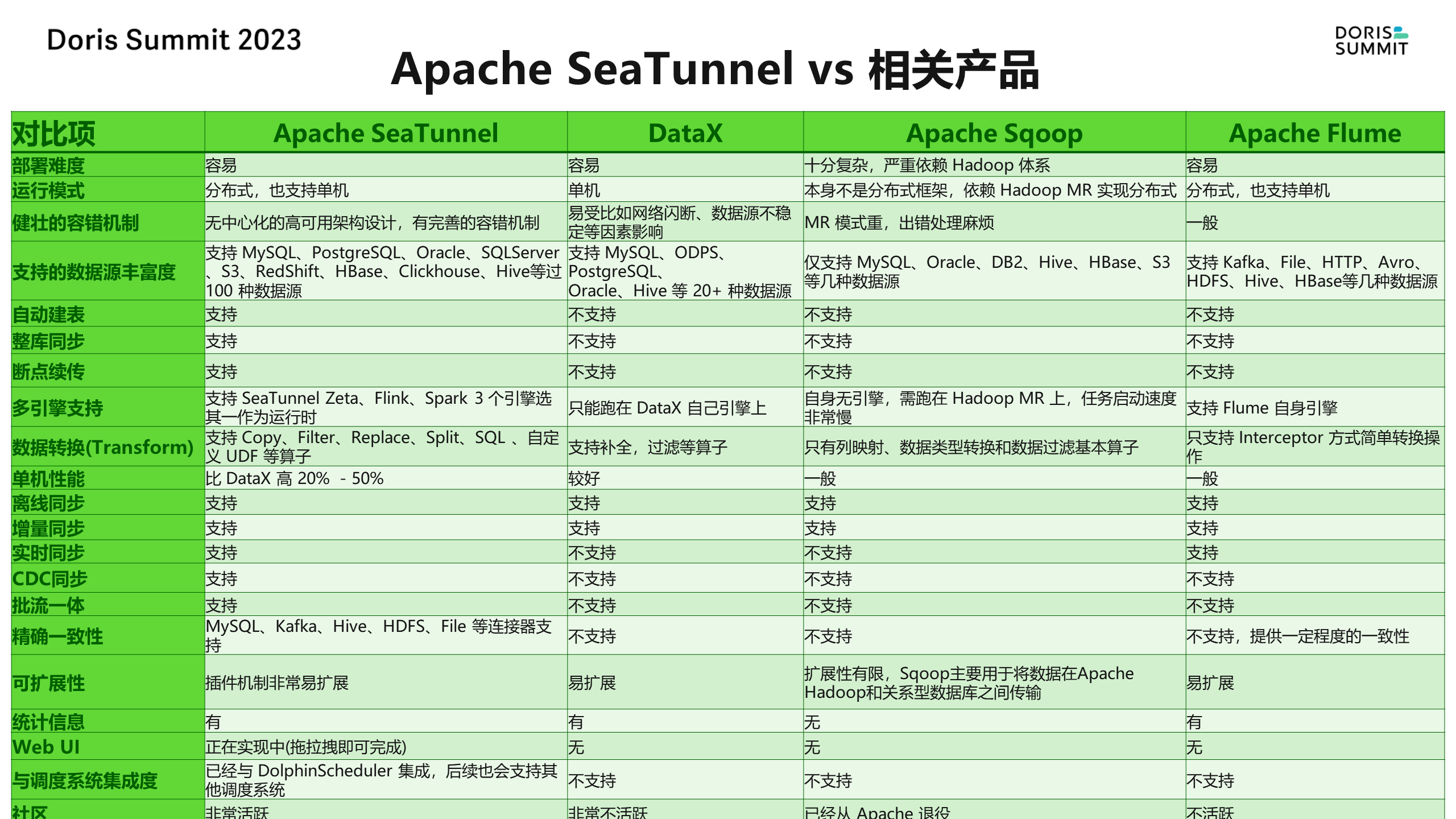
我们还对比了 SeaTunnel 与 Data X、Sqoop、Flume 等数据集成工具。这些工具在支持自动建表、整库同步、断点续传、离线增量和 CDC 等方面的能力各有不同。
其中,Data X 社区虽然已经不再维护,但其用户仍然较多。然而,大多数场景中,Data X 并不能提供很好的支持。相比之下,SeaTunnel 在这些方面表现出色。
支持多种数据源
SeaTunnel 支持多种数据源,包括 MySQL、PostgreSQL、Oracle、SQL Server 等。
它还支持将数据同步到 Doris 等数据库。用户可以通过可视化的界面配置数据源信息,而不需要为每个任务都手动配置。 
字段映射
状态监控
此外,SeaTunnel 还支持流的导入、MySQL 的 CDC 等特性,并支持多表同步或整库同步等场景。
实时数仓方案
白鲸开源基于 Apache DolphinScheduler 和 Apache SeaTunnel 打造的商业产品 WhaleStudio ,是分布式、云原生并带有强大可视化界面的 DataOps 系统,增加了商业客户所需的企业级特性: 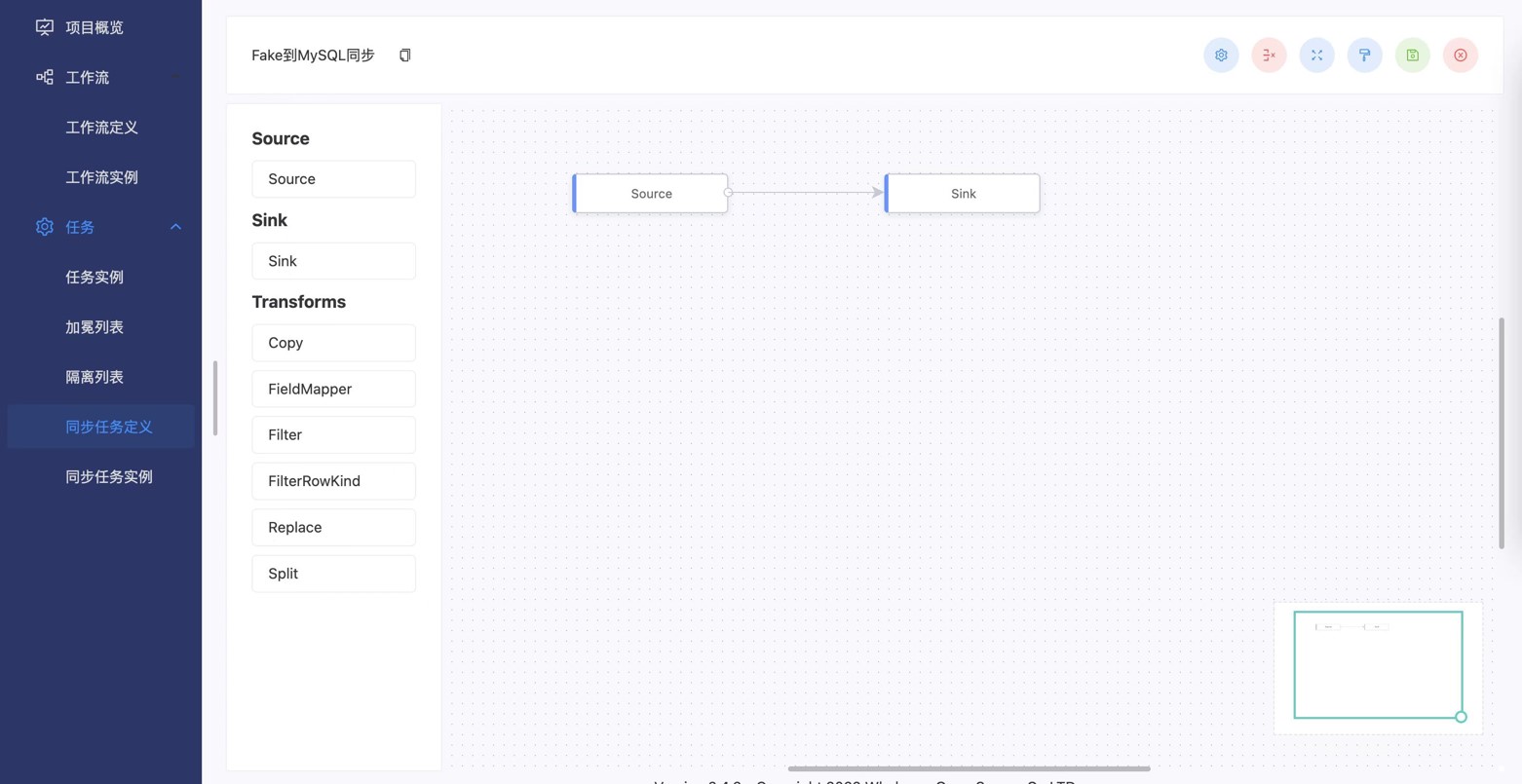
- 全面支持云原生—云、仓、湖 实时/离线批流一体化任务管控
- 低代码实现企业大数据的高可用调度和海量数据批量/实时同步
- 完善的 DataOps 流程可无缝集成代码工具
- 丰富的数据源对接和传统 ETL 数据组件支持
- 增强可观测性和操作性,提高运维与任务运行态人工干预能力
- 复杂时间的管理优化&灵活多样的触发机制&强大的数据科学平台支持
- 完善的权限控制&审计系统等
在 Whalestudio 中,DolphinScheduler 和 SeaTunnel 被视为两个独立的模块,但它们共享一些共同的功能,例如数据源中心的配置只需要进行一次。这种设计使得数据同步和调度更加高效和便捷。
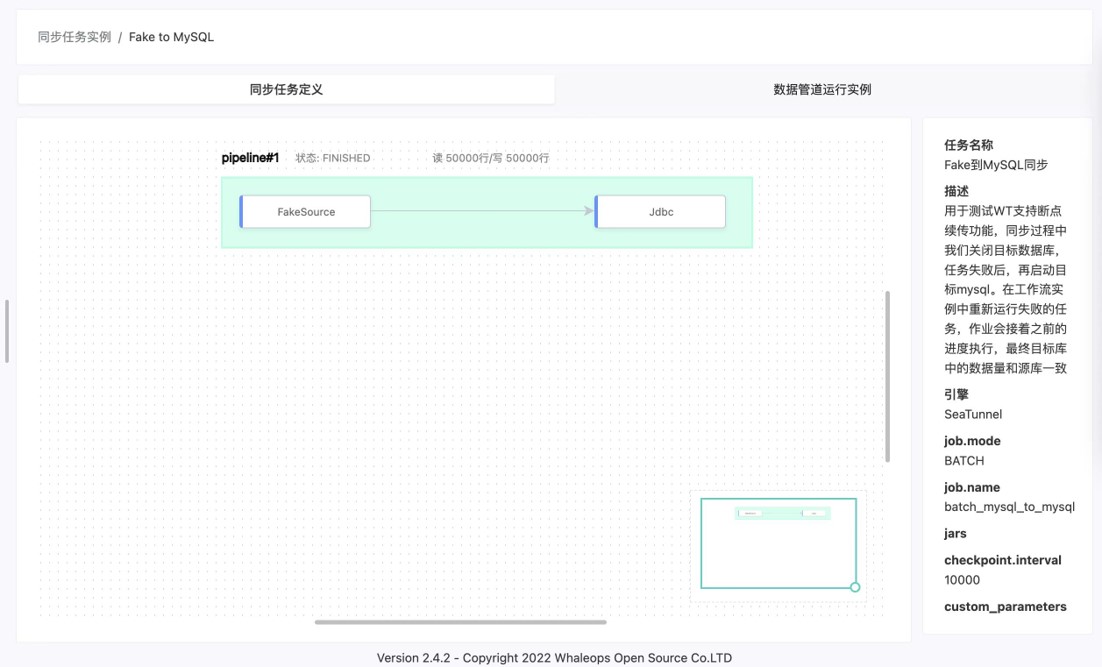
首先,我们需要明白开源并不意味着无限制的免费。在开源世界中,每个项目都有其边界,只有将项目做得非常垂直,才能更好地进行迭代和创新。
因此,我们的开源理念是专注于将项目做得更精细、更垂直,以实现更好的可迭代性。与商业理念不同的是,开源强调的是共享和协作,而商业则更注重整体解决方案和客户的需求。
SeaTunnel 是一个开源项目。在商业版 WhaleStudio 当中,IDE 和可视化配置能力是其中的重要组成部分,它们可以帮助用户轻松地进行 SQL 编写、Python 编程以及业务日期切分等操作。此外,我们还在商业版中提供了一些额外的功能,例如对监管报送等数据的加权处理,以及更丰富的连接器支持。
支持虚拟表
在开源项目中,我们有一个虚拟表的抽象概念。比如说 Kafka、文件这些我们都把它抽象成表,这方便后边去做字段的映射。比如说要去读 Excel 的数据,读到 Doris,或者说其他的数据库,比如说 MySQL,那前面做好了映射,虚拟表建好,后边只是去拖拽一下就 OK 了,不需要再去做这个映射配置这么复杂的事情,我们前阵子跟 SelectDB 做了一个商业的联合解决方案,就是 SelectDB 加上 WhaleTunnel。
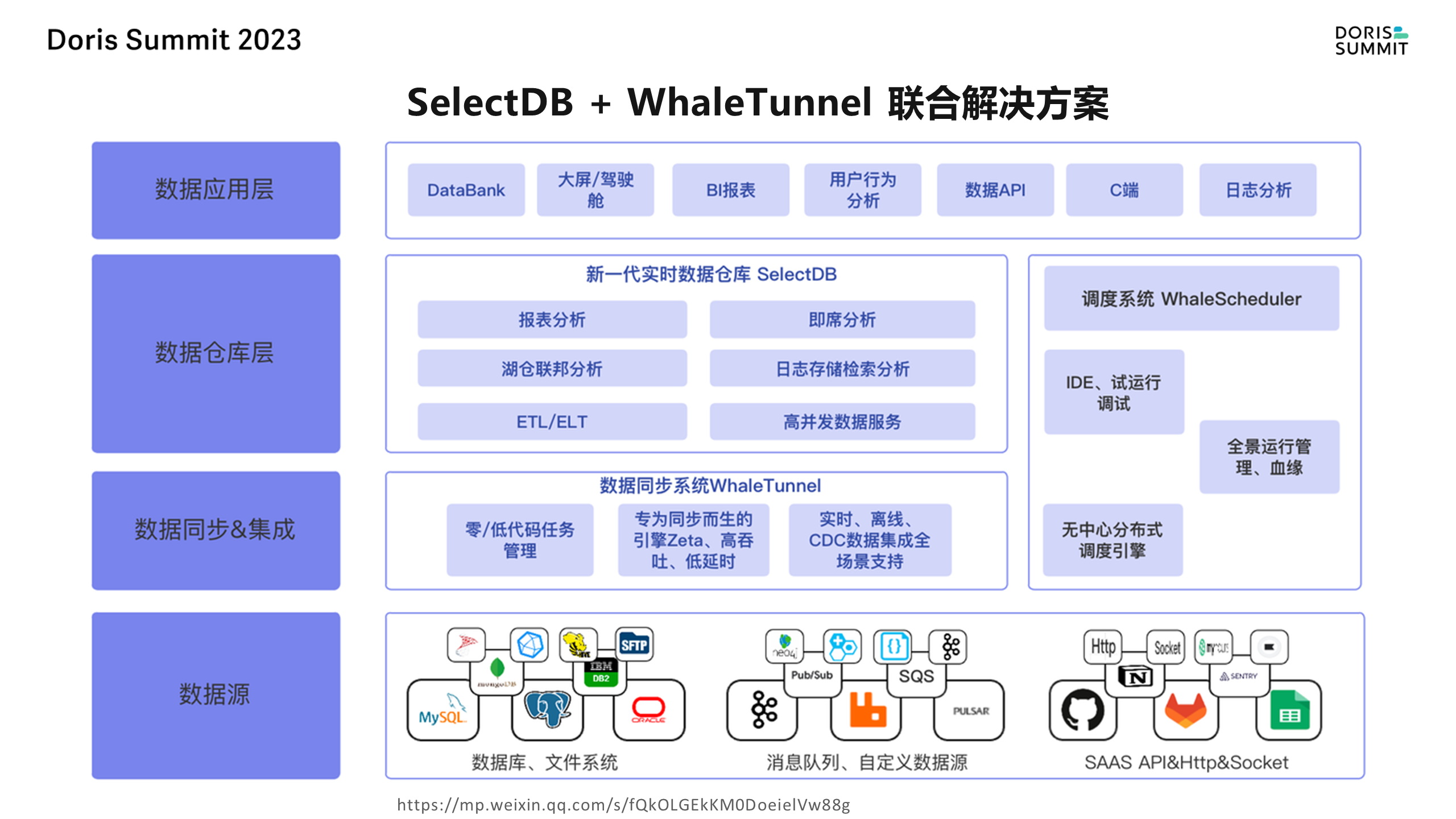
在这个场景中,各种产品充当着不同的角色。SelectDB 用于实时数仓,主要处理数据分析和查询。WhaleTunnel 用于数据同步和导入,它可以从各种数据源获取数据并将其导入到目标位置。WhaleScheduler 用于协调和调度这些任务,确保数据在正确的时间被处理。
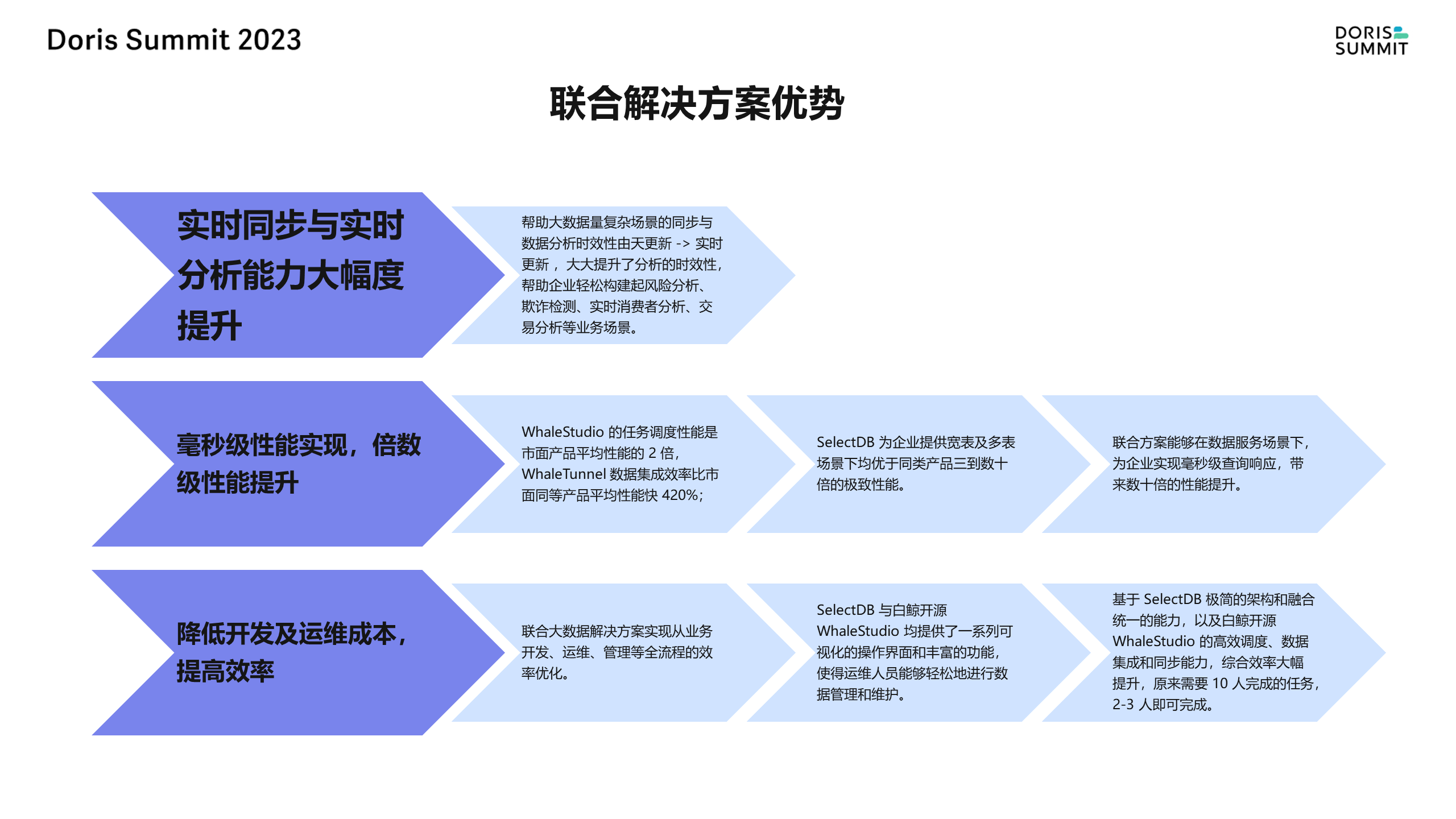
这些产品共同构成了一个完整的数据同步和集成解决方案,可以轻松地处理各种数据源,并通过调度和同步机制将数据导入到实时数仓中进行分析。这种方案具有高效、灵活和可扩展的优点,可以帮助用户快速实现从开发到生产上线的整个流程。
同时,这个解决方案还提供了一些额外的功能,如调试、IDE 支持和数据工作流的血缘关系分析等,这些功能都是在商业版中提供的。用户可以通过这个方案获得更全面的数据同步、集成和分析能力,从而更好地管理和利用用户的数据资产。
Roadmap
在未来的发展计划中,我们将继续丰富连接器支持,例如增加对 Oracle CDC 和 Mongo DB CDC 的支持。同时,我们也将提供更多可插拔能力,以便用户可以根据自己的需求进行定制。
此外,我们还将与主流的调度系统集成,例如 Apache DolphinScheduler 和 Airflow,以提供更全面的解决方案。
最后,我们还将支持 K8S operator 场景,以帮助用户更好地管理和调度他们的数据工作流。
总之,我们的目标是让中国的开源项目走向世界,让更多的人了解并参与到开源项目中来。
无论您是开源的支持者还是商业化的拥护者,我们都欢迎您加入到我们的大家庭中来。谢谢大家!
本文由 白鲸开源科技 提供发布支持!