随着人工智能技术的不断迭代发展,数字人的开发与应用需求也与日俱增,并且随着大语言模型的发展,数字人也更智能,从最初的语音预制到现在的实时交流,目前已在很多场景都有广泛应用。
- 虚拟客服:数字人可以通过语音或文字与用户进行交互,提供客户服务等支持,从而替代传统的人工客服。
- 虚拟购物助手:数字人可以通过语音或文字与用户进行交互,为用户提供购物建议和推荐,从而提高用户的购物体验。
- 虚拟教师:数字人可以通过语音或文字与学生进行交互,为学生提供个性化的教育服务。
- 虚拟医生:数字人可以通过语音或文字与患者进行交互,为患者提供医疗咨询和诊断服务。
本开发教程将以ERNIE Bot SDK作为语言交互的基础,并结合Stable Diffusion、PaddleGan、Edge TTS等技术,实现数字诗人的实时交互,提高诗词的表现力。 本教程共计分为4部分:定制声音、定制造型、生成数字人、数字人语音聊天。

定制数字人声音
生成诗词:ERNIE Bot SDK
安装ERNIE Bot SDK,将用户输入的描述词或主题,生成七言律诗。

!pip install --upgrade erniebot
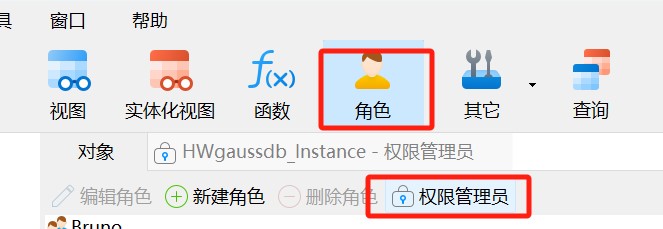
import erniebotdef wx_api(prompt):# List supported modelsmodels = erniebot.Model.list()print(models)erniebot.api_type = "aistudio"erniebot.access_token = "请输入自己的令牌" # 令牌来源如下图# ernie-bot-turbo 选用原因,速度快些response = erniebot.ChatCompletion.create(model="ernie-bot-turbo", messages=[{"role": "user", "content": f"{prompt}"}])answer = response.resultreturn answer# 作诗
def poetry(prompt):answer = wx_api( f"你是伟大的诗人,请赋诗一首七言绝句描述以下情景:{prompt}")print("{} 作诗反馈:\n{}".format(prompt, answer))return answerpoetry("观看天津直升机博览会。")

生成声音:Edge TTS
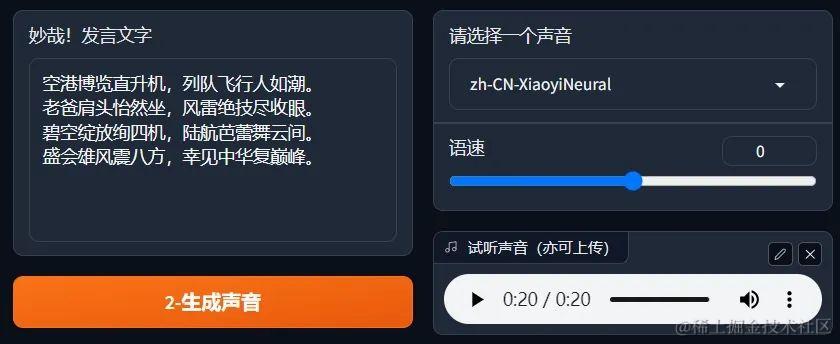
将ERNIE Bot SDK所生成的诗词转为声音。
!pip install edge_tts -i https://mirror.baidu.com/pypi/simple
!pip install librosa==0.8.1
import librosa
import os
boot_path = '/home/aistudio/Gradio_packages/'
sound_path = os.path.join(boot_path,'file/sound.wav')
text = "空港博览直升机,列队飞行人如潮。老爸肩头怡然坐,风雷绝技尽收眼。碧空绽放绚四机,陆航芭蕾舞云间。盛会雄风震八方,幸见中华复巅峰。"
tts_cmd = 'edge-tts --voice zh-CN-XiaoxiaoNeural --text "' + text + '" --write-media ' +sound_path
os.system(tts_cmd)
定制数字人形象
数字人静态形象可以上传图片,也可以直接通过Stable Diffusion生成。

文生图:Stable Diffusion
Stable Diffusion是一种潜在扩散模型(Latent Diffusion), 属于生成类模型,这类模型通过对随机噪声进行一步步地迭代降噪并采样来获得感兴趣的图像,当前取得了令人惊艳的效果。相比于Disco Diffusion, Stable Diffusion通过在低纬度的潜在空间(lower dimensional latent space)而不是原像素空间来做迭代,极大地降低了内存和计算量的需求,并且在V100上一分钟之内即可以渲染出想要的图像。
参数说明:prompts: 输入的语句,描述想要生成的图像的内容。
!pip install paddlenlp==2.6.0rc0
!pip install ppdiffusers #重启内核,项目框架需为:PaddlePaddle develop
# 安装完后import ppdiffusers可能会失败,点击最上面的重启内核即可,不行就重复pip+重启内核几次,总能成功的~
import os
import paddle
from ppdiffusers import StableDiffusionPipeline
from ppdiffusers import DPMSolverMultistepSchedulerfdir_path = '/home/aistudio/Gradio_packages/file/'
diffu_img_path = os.path.join(fdir_path,'diffu_img.jpg')
face_img_path = os.path.join(fdir_path,'face_img.jpg')
temp_img_path = os.path.join(fdir_path,'temp.jpg')# 模型
pretrained_model_name_or_path = "runwayml/stable-diffusion-v1-5"
#unet_model_path = "./dream_booth_lora_outputs"# 加载原始的模型
pipe = StableDiffusionPipeline.from_pretrained(pretrained_model_name_or_path, safety_checker=None)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
# 将 adapter layers 添加到 UNet 模型
#pipe.unet.load_attn_procs(unet_model_path, from_hf_hub=False)def diffu_result0(prompt):if prompt == '':prompt = 'face'negative_prompt = "lowres, error_face, bad_face, bad_anatomy, error_body, error_hair, error_arm, (error_hands, bad_hands, error_fingers, bad_fingers, missing_fingers) error_legs, bad_legs, multiple_legs, missing_legs, error_lighting, error_shadow, error_reflection, text, error, extra_digit, fewer_digits, cropped, worst_quality, low_quality, normal_quality, jpeg_artifacts, signature, watermark, username, blurry"guidance_scale = 8num_inference_steps = 50height = 512width = 512img = pipe(prompt, negative_prompt=negative_prompt, guidance_scale=guidance_scale, height=height, width=width, num_inference_steps=num_inference_steps).images[0]img.save(diffu_img_path) img.save(temp_img_path) # 备份
在使用stable diffusion时,可以使用ERNIE Bot SDK中的翻译和扩写功能对prompt进行处理。
def magic_prompt(query: str):magic_template = """你是一个提示词扩写大师, 你需要根据我的输入,改写扩写为提示词,直接输出全英文。提示词需要遵循以下规则:遵循示例提示词的结构,这意味着首先描述绘画主体,然后描述场景,然后添加绘画笔触、情绪、绘画风格、灯光、镜头、等, 然后是best quality,、masterpiece、8K这样表达高质量照片的词语,所有这些词语之间用逗号分隔。请不要换行,请用英语表达。举例:输入:一个穿明亮裙子的小姑娘a portrait of a cute girl wearing a luminous, vibrant and colorful dress standing in front of an abstract dreamy background with subtle pastel colors, inspired by the works of Ulyana Aster, digital art made using Adobe Photoshop and Corel Painter, surrealistic elements like glitters, stars and clouds to create a magical atmosphere, RAW photo,hyper-realistic, close-up, product view, artstation trends, cgsociety, super high quality, digital art, exquisite ultra-detailed, 4k, soft lighting, fantasy, fashion, unreal engine rendering,8k uhd, HDR, high quality,untra detailed,film grain输入:一间白色的带有瓷砖的浴室a nature look and chic bathroom with white wall, beige ceramic tile, natural stone flooring, modern fixtures and appliances in silver chrome, contemporary vanity sink and mirror in black marble countertop, spa-like atmosphere with a luxurious freestanding bathtub in the center of the room. Rendered in Unreal Engine 4 for photorealistic lighting effects and textures, RAW photo,hyper-realistic,RAW photo,hyper-realistic,, product view, artstation trends, cgsociety, super high quality, digital art, exquisite ultra-detailed, 4k, soft lighting, dreamy, stylish, unreal engine Rendering Model: Midjourney style, CFG scale: 7, 8k, uhd, HDR, high quality,untra detailed,film grain,8k uhd, HDR, high quality,untra detailed,film grain输入:"{query}""""answer = wx_api(magic_template)# 此处出现过LangChain部署失败问题,故调整方案,放弃使用return answerdef translate_prompt(query: str):translate_template = """你是一个翻译大师, 你需要根据我的输入,把中文翻译为英文。
环境准备:PaddleGAN
PaddleGAN 生成对抗网络开发套件,为开发者提供经典及前沿的生成对抗网络高性能实现,并支撑开发者快速构建、训练及部署生成对抗网络,以供学术、娱乐及产业应用。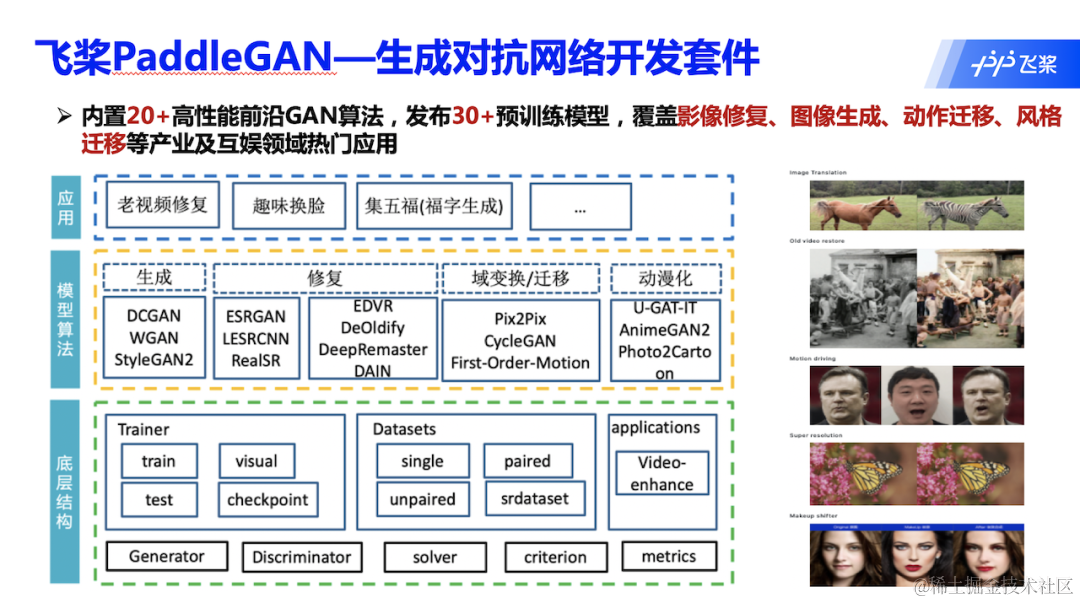
环境准备–若需在main.ipynb中运行以下代码,需将main.ipynb置于Gradio_packages文件夹下。
# 本项目已经修改PaddleGAN文件夹内容,无需再运行此处代码,避免覆盖。
#!git clone https://gitee.com/PaddlePaddle/PaddleGAN
#%cd /home/aistudio/PaddleGAN/
#!python ./setup.py develop
!pip install dlib
!pip install scikit-image
!pip install imageio-ffmpeg
!pip install munch
!pip install natsort
!pip install numpy==1.22 #重启内核
脸部融合:StyleGANv2Fittin StyleGANv2Mixing
将两个来源的图片形象进行脸部融合生成新的形象。
基础知识 StyleGANv2Fitting StyleGANv2Mixing
1、StyleGAN是随机生成向量,根据向量生成图片。
2、Fitting模块是根据已有的图像反推出解耦程度高的风格向量。得到的风格向量可用于人脸融合、人脸属性编辑等任务中。
3、Mixing模块则是利用其风格向量实现两张生成图像不同层次不同比例的混合。
原理步骤
实现人脸融合一共分为三个步骤:
1、Fitting模块提取两张人脸图片的向量,StyleGAN V2根据向量生成StyleGAN世界中的人脸;
2、Mixing模块融合两张人脸的向量;
3、StyleGAN V2根据融合后的向量生成新的人脸。
import os
from PaddleGAN.ppgan.apps.styleganv2fitting_predictor import StyleGANv2FittingPredictorfdir_path = '/home/aistudio/Gradio_packages/file/'
fit_path = '/home/aistudio/Gradio_packages/file/fit1'
diffu_img_path = os.path.join(fdir_path,'diffu_img.jpg')
print(diffu_img_path)img2fit = StyleGANv2FittingPredictor(output_path=fit_path,model_type='ffhq-config-f',seed=None,size=1024,style_dim=512,n_mlp=8,channel_multiplier=2)img2fit.run(diffu_img_path,need_align=True)
import os
from PaddleGAN.ppgan.apps.styleganv2fitting_predictor import StyleGANv2FittingPredictorfdir_path = '/home/aistudio/Gradio_packages/file/'
fit_path = '/home/aistudio/Gradio_packages/file/fit2'
input_face_path = os.path.join(fdir_path,'input_face.jpg')
print(diffu_img_path)img2fit = StyleGANv2FittingPredictor(output_path=fit_path,model_type='ffhq-config-f',seed=None,size=1024,style_dim=512,n_mlp=8,channel_multiplier=2)img2fit.run(input_face_path,need_align=True)
import os
from PaddleGAN.ppgan.apps import StyleGANv2MixingPredictor
from PIL import Imagefdir_path = '/home/aistudio/Gradio_packages/file/'
fit1_path = os.path.join(fdir_path,'fit1/dst.fitting.npy')
print(fit1_path)
fit2_path = os.path.join(fdir_path,'fit2/dst.fitting.npy')
mix_path = os.path.join(fdir_path,'dst.mixing.png')
face_img_path = os.path.join(fdir_path,'face_img.jpg')predictor = StyleGANv2MixingPredictor(output_path=fdir_path,model_type='ffhq-config-f',seed=None,size=512,style_dim=512,n_mlp=8,channel_multiplier=2)
predictor.run(fit1_path, fit2_path)img = Image.open(mix_path)
img.resize((512, 512), Image.LANCZOS).save(face_img_path)
print(face_img_path)
老化和卡通化:Pixel2Style2Pixel,StyleGANv2
可以尝试更多数字人形象。
老化基础知识 Pixel2Style2Pixel StyleGANv2
1、Latent Code:潜在因子,每张图像对应一个潜在因子(高维的向量),stylegan能够用这个向量生成图像。
2、属性编辑:由于潜在因子包含维度比较多,无法确定维度对应的方向以及编辑所带来的变化,因此利用大量的潜在因子和对应的属性(比如年龄或性别)训练线性的分类器,即可将分类器的权重作为潜在因子和对应属性的方向。
3、StyleGAN:根据向量生成图片。
老化原理步骤
1、获取图片的Latent Code,用于后续的属性编辑和人脸生成,使用Pixel2Style2Pixel提取Latent Code。
temp_img_path:原图路径,即需要提取隐藏特征的照片路径。
age_dir:原图的隐藏特征的存放路径,后续需要放在属性编辑和生成的模块中使用。
2、将Latent Code根据特定方向进行编辑,即可编辑对应的人脸属性,如年龄、性别、头发、眼睛等。
3、StyleGAN V2根据第二步中编辑好的Latent Code向量生成目标人脸。
age_pix_path:STEP2中提取的原图的Latent Code(STEP2中的output_path路径)。
age_path:新人脸(年龄变换后)的保存路径。
应用使用说明
老化或卡通化:老化值不为0时,产生效果;老化值为0时,撤销上一步老化或卡通化操作,仅能撤销一步。
import os
from PaddleGAN.ppgan.apps.pixel2style2pixel_predictor import Pixel2Style2PixelPredictor
from PaddleGAN.ppgan.apps.styleganv2editing_predictor import StyleGANv2EditingPredictor
from PaddleGAN.ppgan.apps.photo2cartoon_predictor import Photo2CartoonPredictordef resize_image1(in_path, out_path, w, h):img = Image.open(in_path)img.resize((w, h), Image.LANCZOS).save(out_path)fdir_path = '/home/aistudio/Gradio_packages/file'
diffu_img_path = os.path.join(fdir_path,'diffu_img.jpg')
face_img_path = os.path.join(fdir_path,'face_img.jpg')
temp_img_path = os.path.join(fdir_path,'temp.jpg')
age_dir = os.path.join(fdir_path,'age/')
age_pix_path = os.path.join(fdir_path,'age/dst.npy')
age_path = os.path.join(fdir_path,'age/dst.editing.png')
cartoon_dir = os.path.join(fdir_path,'cartoon/')
cartoon_path = os.path.join(fdir_path,'cartoon/p2c_cartoon.png')age_pixel_predictor = Pixel2Style2PixelPredictor(output_path = age_dir, model_type = 'ffhq-inversion', size = 512)
age_predictor = StyleGANv2EditingPredictor(output_path = age_dir, model_type = 'ffhq-config-f', size = 512)cartoon_predictor = Photo2CartoonPredictor(output_path = cartoon_dir)# 变换年龄提取像素
def age_pixel():age_pixel_predictor.run(temp_img_path)# 变换年龄
def age(num):age_predictor.run(age_pix_path, 'age', num/5)resize_image1(age_path, diffu_img_path, 512, 512) # 变换卡通形象
def cartoon():cartoon_predictor.run(temp_img_path)resize_image1(cartoon_path, diffu_img_path, 512, 512)age_pixel()
age(5)#cartoon()
生成数字人
将静态形象转化为动态,并与声音进行唇形匹配生成数字人视频。
表情迁移:First order motion model
将静态造型转化为动态。
First order motion model的任务是image animation,给定一张源图片,给定一个驱动视频,生成一段视频,其中主角是源图片,动作是驱动视频中的动作,源图像通常包含一个主体,驱动视频包含一系列动作。以人脸表情迁移为例,给定一个源人物,给定一个驱动视频,可以生成一个视频,其中主体是源人物,视频中源人物的表情是由驱动视频中的表情所确定的。通常情况下,我们需要对源人物进行人脸关键点标注、进行表情迁移的模型训练。
参数说明:
face_driving_path: 驱动视频,视频中人物的表情动作作为待迁移的对象。
face_img_path: 原始图片,视频中人物的表情动作将迁移到该原始图片中的人物上。
relative: 指示程序中使用视频和图片中人物关键点的相对坐标还是绝对坐标,建议使用相对坐标,若使用绝对坐标,会导致迁移后人物扭曲变形。
adapt_scale: 根据关键点凸包自适应运动尺度。
import os
from PaddleGAN.ppgan.apps.first_order_predictor import FirstOrderPredictorfdir_path = '/home/aistudio/Gradio_packages/file'
face_img_path = os.path.join(fdir_path,'face_img.jpg')
face_driving_path = os.path.join(fdir_path,'face_dri.mp4')
face_path = os.path.join(fdir_path,'face.mp4')FOM_predictor = FirstOrderPredictor(output = fdir_path, filename = 'face.mp4', face_enhancement = False, ratio = 0.4,relative = True,image_size = 512,adapt_scale = True)def FOM():FOM_predictor.run(face_img_path, face_driving_path)return face_pathFOM()
唇形匹配:Wav2Lip
动态造型并与声音进行唇形匹配生成数字人视频。
Wav2Lip模型是一个基于GAN的唇形动作迁移算法,实现生成的视频人物口型与输入语音同步。Wav2Lip不仅可以基于静态图像来输出与目标语音匹配的唇形同步视频,还可以直接将动态的视频进行唇形转换,输出与输入语音匹配的视频。
Wav2lip实现唇形与语音精准同步突破的关键在于,它采用了唇形同步判别器,以强制生成器持续产生准确而逼真的唇部运动。
此外,该研究通过在鉴别器中,使用多个连续帧而不是单个帧,并使用视觉质量损失(而不仅仅是对比损失)来考虑时间相关性,从而改善了视觉质量。
该wav2lip模型几乎是万能的,适用于任何人脸、任何语音、任何语言,对任意视频都能达到很高的准确率,可以无缝地与原始视频融合,还可以用于转换动画人脸,并且导入合成语音也是可行的。
参数说明:
face_path: 动态造型视频,其中的人物唇形将根据音频进行唇形合成。
sound_path: 驱动唇形合成的音频。
result_path: 指定生成的视频文件的保存路径及文件名。
import os
from PaddleGAN.ppgan.apps.wav2lip_predictor import Wav2LipPredictorfdir_path = '/home/aistudio/Gradio_packages/file'
face_path = os.path.join(fdir_path,'face.mp4')
sound_path = os.path.join(fdir_path,'sound.wav')
result_path = os.path.join(fdir_path,'result.mp4')wav2lip_predictor = Wav2LipPredictor(face_det_batch_size = 2,wav2lip_batch_size = 16,face_enhancement = True)def wav2lip(input_video,input_audio,output):wav2lip_predictor.run(input_video, input_audio, output)return outputwav2lip(face_path, sound_path, result_path)
数字人语音聊天
通过语音识别技术和文心一言能力实现数字人聊天。

语音识别:百度智能云api
调用百度智能云语音识别api——短语音识别标准版。
import os
import base64
import urllib
import requests
import jsonfdir_path = '/home/aistudio/Gradio_packages/file/'
sound_path = os.path.join(fdir_path,'chat_in.wav')def get_access_token():API_KEY = "??????" # 获取方式可参考本项目文档结尾部分—--创建百度智能云语音识别api步骤SECRET_KEY = "??????""""使用 AK,SK 生成鉴权签名(Access Token):return: access_token,或是None(如果错误)"""url = "https://aip.baidubce.com/oauth/2.0/token"params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}print(params)return str(requests.post(url, params=params).json().get("access_token"))def get_file_content_as_base64(path, urlencoded=False):"""获取文件base64编码:param path: 文件路径:param urlencoded: 是否对结果进行urlencoded :return: base64编码信息"""with open(path, "rb") as f:content = base64.b64encode(f.read()).decode("utf8")if urlencoded:content = urllib.parse.quote_plus(content)return contenturl = "https://vop.baidu.com/server_api"
print(sound_path)
speech = get_file_content_as_base64(sound_path,False)print(speech)
payload = json.dumps({"format": "PCM","rate": 16000,"channel": 1,"cuid": "I0MZDdBsn2GsmuQXofM4kXugUrZySh0l","token": get_access_token(),"dev_pid": 1737,"speech": get_file_content_as_base64(sound_path,False),"len": os.path.getsize(sound_path)
})
headers = {'Content-Type': 'application/json','Accept': 'application/json'}response = requests.request("POST", url, headers=head
数字人聊天:ERNIE Bot SDK
使用文心一言能力生成对话内容。
from api import wx_apichat_in = "你是谁"prompt = f"""人物设定:你名叫“奇奇”。是一个知识渊博、善解人意、风趣幽默的聊天小达人,能够与用户进行幽默而富有洞察力的对话。对话案例:用户:“嗨,奇奇!今天天气真好,适合出去散步。你觉得呢?”奇奇:“是的,确实是个散步的好日子。你喜欢去哪里散步呢?是公园还是河边?”用户:“我通常喜欢去公园散步。那里的花草树木都很美丽,还能听到鸟叫声。”奇奇:“听起来很惬意啊!散步在自然环境中可以缓解压力,也有助于健康。你平时还有其他喜欢的户外活动吗?”输出要求:根据用户的输入,生成有趣、相关且富有洞察力的回应。在对话中保持自然、流畅的风格,与用户进行互动。可以根据对话的上下文,主动引导对话的深入和扩展。回答内容尽量简短。回答用户最新的问题:{chat_in}"""answer = wx_api(prompt)
print("{} 聊天最终反馈:{}".format(chat_in, answer))
该教程支持直接一键fork运行并部署为Gradio应用,点击下方链接查看。
https://aistudio.baidu.com/projectdetail/6998882
作者故事
星河小编:可以简单介绍一下自己哦。
司进龙: 大家好,我叫司进龙,现在是神州数码资深RPA工程师,原来从事行业分析咨询工作,于三年前学习Python并成功转行到RPA行业。
星河小编: 是怎么加入到飞桨星河社区的呢?
司进龙: 与飞桨星河社区的结缘是在一年前,最开始是学习飞桨星河社区的课程,从深度学习理论到大模型应用开发等一系列课程,最开始只是自己学,后来甚至推荐家人一起听,一起组队参赛卷卷ai。
星河小编: 可以再介绍下这个项目嘛?
司进龙: 这个应用是为了黑客松5th比赛而准备的。在进行数字人人物设定时,用的就是我家孩子的小名奇奇和思思。他们还喜欢测试作品,思思最喜欢测试数字人生成、老化等功能。奇奇则最喜欢测试与数字人对话的功能,他们找出来好多bug,也玩的不亦乐乎。我妻子高磊不仅提出许多创意,更重要的是给我很多鼓励,使我有了不断前行的动力。
该教程项目来源于飞桨星河社区五周年开发精品教程征集,更多教程或有投稿需求请点击底部下方链接查看。
https://aistudio.baidu.com/topic/tutorial