InfluxDB
简介
什么是 InfluxDB ?
-
InfluxDB 是一个由 InfluxData 开发的,开源的时序型数据库。它由 Go 语言写成,着力于高性能地查询与存储时序型数据。
-
InfluxDB 被广泛应用于存储系统的监控数据、IoT 行业的实时数据等场景。
-
可配合 Telegraf 服务(Telegraf 可以监控系统 CPU、内存、网络等数据)。
-
可配合 Grafana 服务(数据展现的图像界面,将 InfluxDB 中的数据可视化)。
-
InfluxDB 官网
什么是时序数据?
时间序列数据(TimeSeries Data):按照时间顺序记录系统、设备状态变化的数据被称为时序数据。其应用场景很多,如:
- 无人驾驶车辆运行中要记录的经度、纬度、速度、方向、旁边的距离等。
- 某一地区的各车辆的行驶轨迹数据。
- 传统证券行业实时交易数据。
- 实时运维监控数据等。
时序数据特点:
- 性能好:关系型数据库对于大规模数据的处理性能糟糕,而 NoSQL 可以比较好地处理大规模数据,但依然比不上时间序列数据库。
- 存储成本低:高效的压缩算法,节省存储空间,有效降低 I/O 。
数据存储结构
与 MySQL 的基础概念对比:
| 概念 | MySQL | InfluxDB |
|---|---|---|
| 数据库(同) | database | database |
| 表(不同) | table | measurement |
| 列(不同) | column | tag(带索引的,非必须)、field(不带索引)、timestemp(唯一主键) |
-
tag set:不同的每组 tag key 和 tag value 的集合。
-
field set:每组 field key 和 field value 的集合。
-
retention policy:数据存储策略(默认策略为 autogen)InfluxDB 没有删除数据操作,规定数据的保留时间达到清除数据的目的。
-
series:共同 retention policy、measurement 和 tag set 的集合。
示例数据:
- census 是 measurement
- butterflies 和 honeybees 是 field key
- location 和 scientist 是 tag key
name: census
————————————
time butterflies honeybees location scientist
2015-08-18T00:00:00Z 12 23 1 langstroth
2015-08-18T00:00:00Z 1 30 1 perpetua
2015-08-18T00:06:00Z 11 28 1 langstroth
2015-08-18T00:06:00Z 11 28 2 langstroth
注意点:
- tag 只能为字符串类型。
- field 类型无限制。
- 不支持 join。
- 支持连续查询操作(汇总统计数据):CONTINUOUS QUERY。
部署
新建容器网络:docker network create grafana
运行容器:docker run -d --name=influxdb --network grafana -p 8086:8086 -v ${PWD}/influxdb/:/var/lib/influxdb influxdb:1.7.10
创建数据库:
- 第一种方式:
curl -i -XPOST http://localhost:8086/query --data-urlencode "q=CREATE DATABASE jmeter" - 第二种方式:
docker exec -it influxdb influx
简单使用:
create database jmeters;
use jmeter;
show measurements;
select * from jmeter limit 3;
常用 InfluxQL
-- 查看所有的数据库
show databases;-- 使用特定的数据库
use database_name;-- 查看所有的 measurement
show measurements;-- 查询 10 条数据
select * from measurement_name limit 10;-- 数据中的时间字段默认显示的是一个纳秒时间戳,改成可读格式
precision rfc3339; -- 之后再查询,时间就是 rfc3339 标准格式
-- 或可以在连接数据库的时候,直接带该参数
influx -precision rfc3339-- 查看一个 measurement 中所有的 tag key
show tag keys-- 查看一个 measurement 中所有的 field key
show field keys-- 查看一个 measurement 中所有的保存策略(可以有多个,一个标识为 default)
show retention policies;
Grafana
简介
Grafana(官网)是一个跨平台的、开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。
它主要有以下六大特点:
- 展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
- 支持多种数据源:Graphite、InfluxDB、OpenTSDB、Prometheus、Elasticsearch、CloudWatch 和 KairosDB 等;
- 通知提醒:以可视方式定义最重要指标的警报规则,Grafana 将不断计算并发送通知,在数据达到阈值时通过 Slack、PagerDuty 等获得通知;
- 混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
- 注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
- 过滤器:Ad-hoc 过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
自动化测试相关教程推荐:
2023最新自动化测试自学教程新手小白26天入门最详细教程,目前已有300多人通过学习这套教程入职大厂!!_哔哩哔哩_bilibili
2023最新合集Python自动化测试开发框架【全栈/实战/教程】合集精华,学完年薪40W+_哔哩哔哩_bilibili
测试开发相关教程推荐
2023全网最牛,字节测试开发大佬现场教学,从零开始教你成为年薪百万的测试开发工程师_哔哩哔哩_bilibili
postman/jmeter/fiddler测试工具类教程推荐
讲的最详细JMeter接口测试/接口自动化测试项目实战合集教程,学jmeter接口测试一套教程就够了!!_哔哩哔哩_bilibili
2023自学fiddler抓包,请一定要看完【如何1天学会fiddler抓包】的全网最详细视频教程!!_哔哩哔哩_bilibili
2023全网封神,B站讲的最详细的Postman接口测试实战教学,小白都能学会_哔哩哔哩_bilibili
总结:
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

如果对你有帮助的话,点个赞收个藏,给作者一个鼓励。也方便你下次能够快速查找。
如有不懂还要咨询下方小卡片,博主也希望和志同道合的测试人员一起学习进步
在适当的年龄,选择适当的岗位,尽量去发挥好自己的优势。
我的自动化测试开发之路,一路走来都离不每个阶段的计划,因为自己喜欢规划和总结,
测试开发视频教程、学习笔记领取传送门!!

基础概念
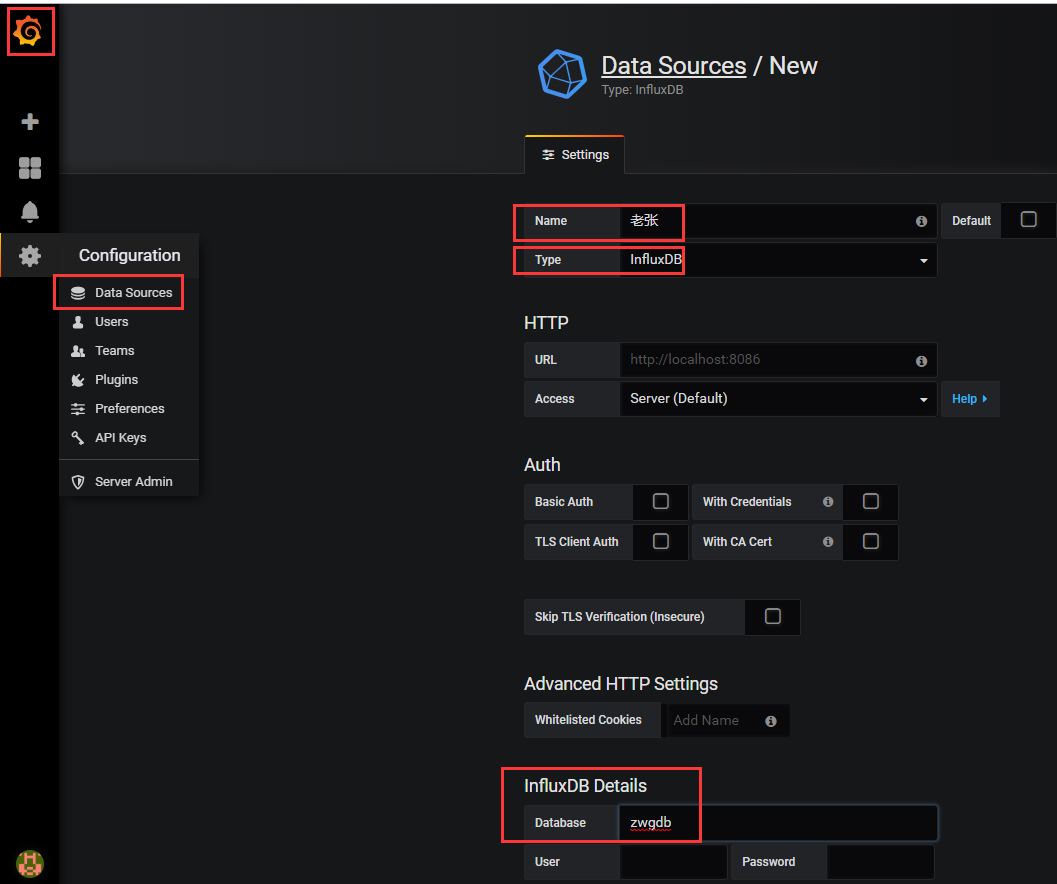
Data Source
- Grafana 确切的说是一个前端展示工具,将数据以非常美观直接的图形展示出来。那么这些数据必须有一个来源吧,那么 Grafana 获取数据的地方就称为 Data Source。
- 官方文档上说 Grafana 支持以下数据源:Graphite、InfluxDB、OpenTSDB、Prometheus、Elasticsearch、CloudWatch。
- 在 Grafana 3.0+ 之后,不仅支持上面说的这些数据源,还支持一些其它的数据源,这些就称为 Grafana Plugins。Grafana 支持的插件非常多,只要做一些简单的插件安装配置,就能获取丰富的数据源。
- 如下所示,添加数据源:
DashBoard
- 就像汽车仪表盘一样可以展示很多信息,包括车速、水箱温度等。Grafana 的 DashBoard 就是以各种图形的方式来展示从 Datasource 拿到的数据。
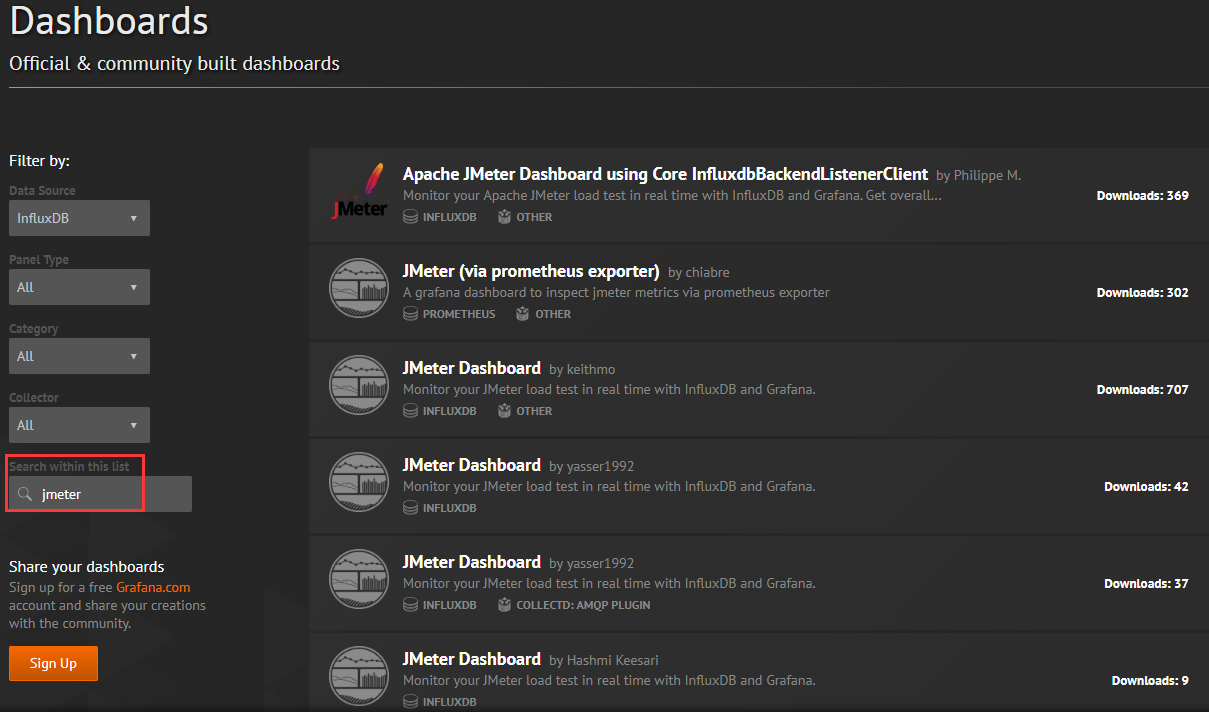
- 添加仪表盘的示例步骤:
- 如搜索 jmeter 仪表盘:
- 选择对应的仪表盘 ID :
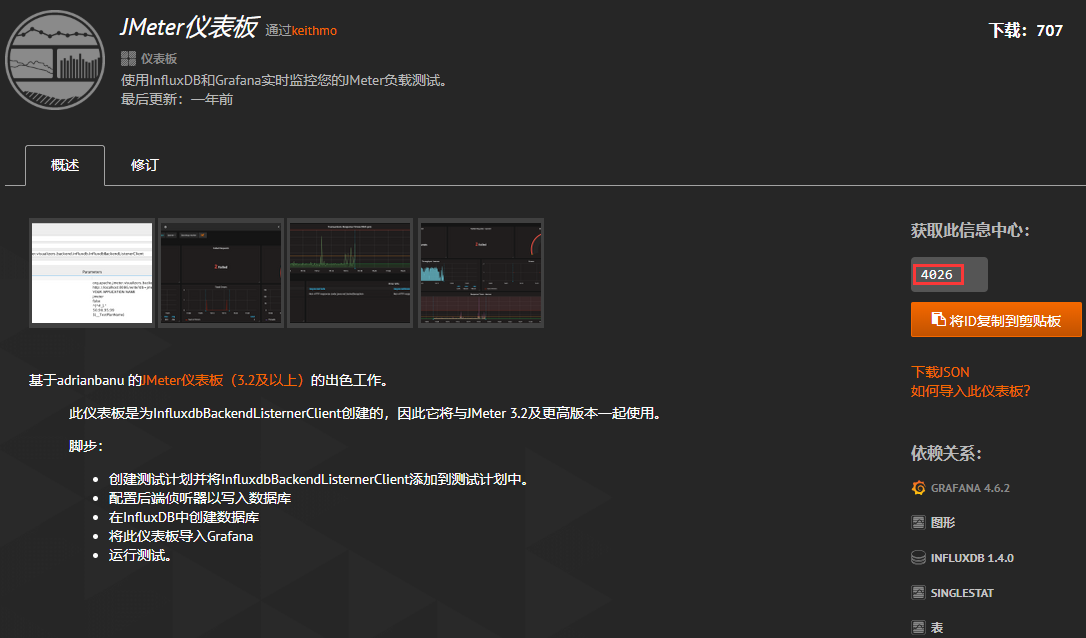
- 复制ID,填入导入界面(导入时需要选择用户组以及对应的数据库):
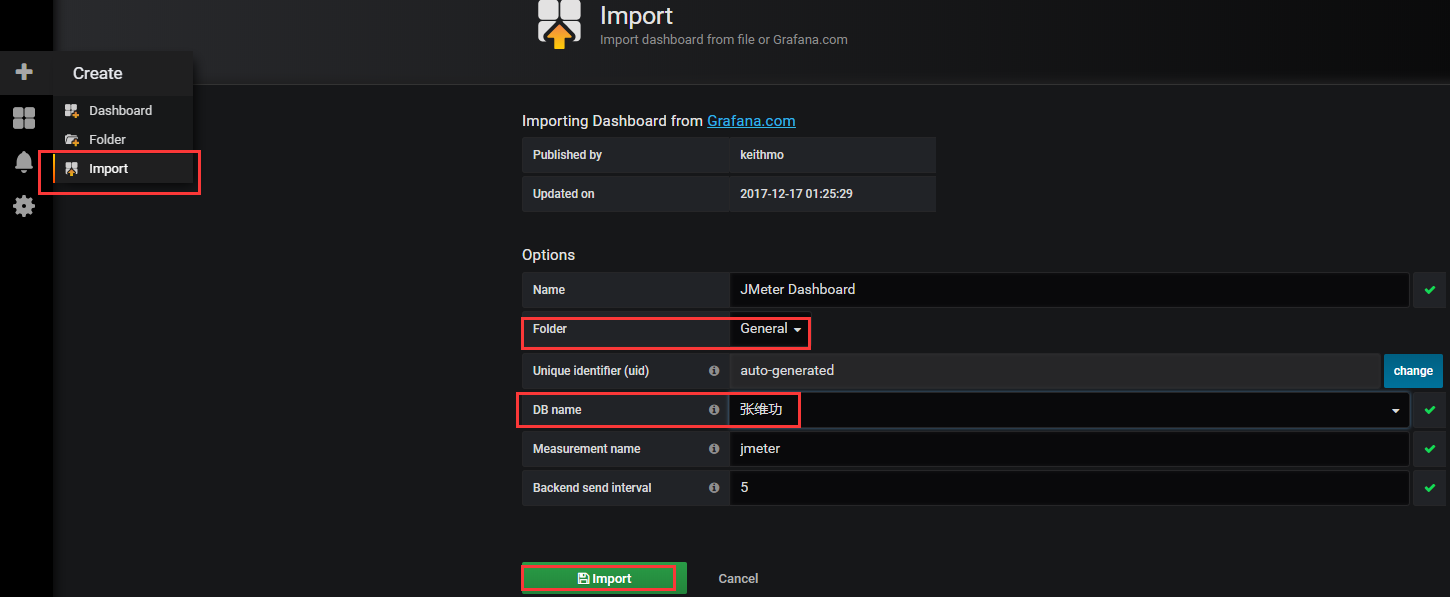
- 展示仪表盘(右上角可以选择数据展示的时间段和刷新频次):
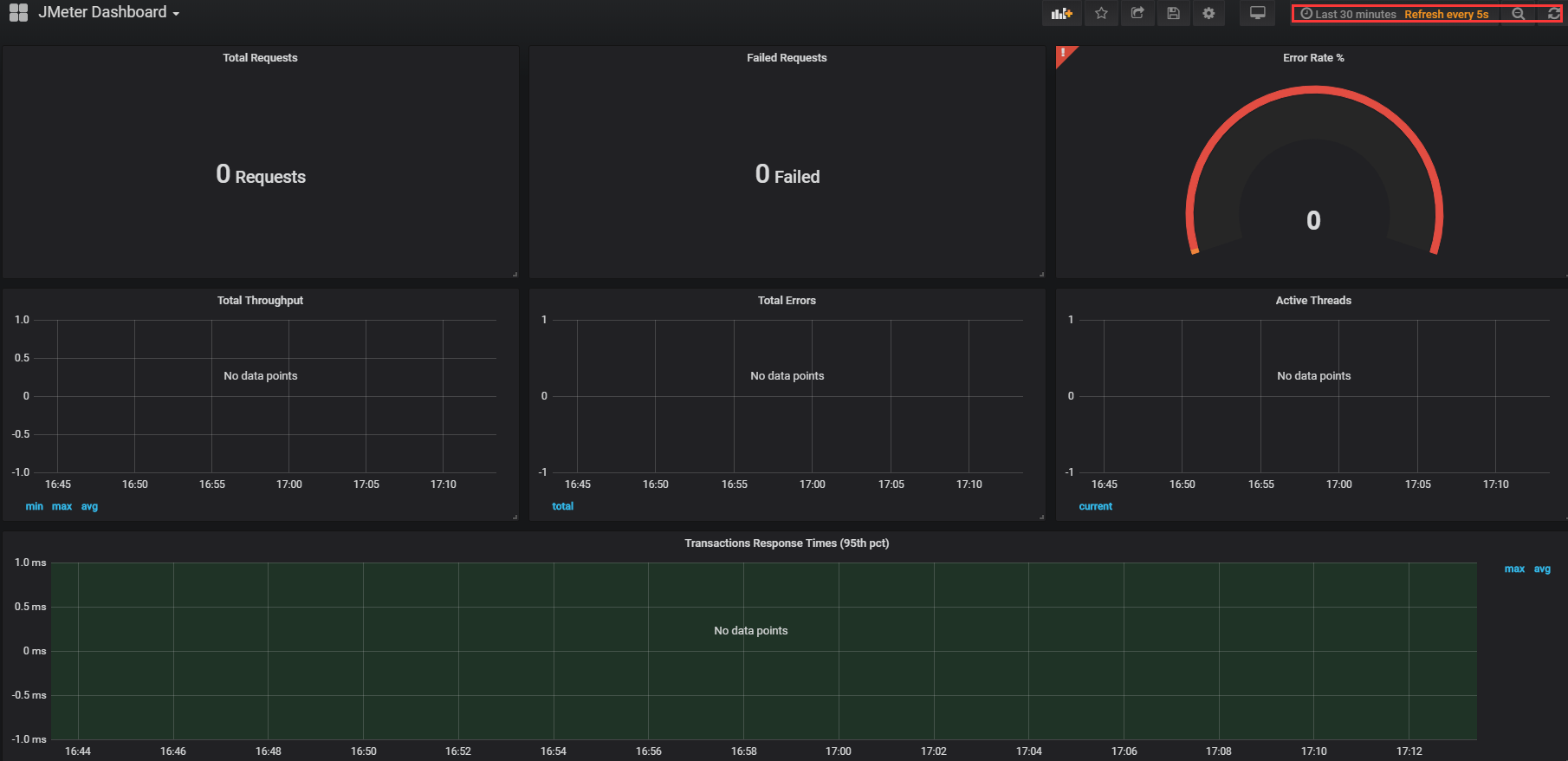
- 如搜索 jmeter 仪表盘:
Row
- Row 是 DashBoard 的基本组成单元,一个 DashBoard 可以包含很多个 Row 。
- 一个 Row 可以展示一种信息或者多种信息的组合,比如系统内存使用率,CPU 五分钟及十分钟平均负载等。所以在一个 DashBoard 上可以集中展示很多内容。
Panel
- Panel(面板)实际上就是 Row 展示信息的方式,支持表格(table)、列表(alert list)、热图(Heatmap)等多种方式,具体可以去官网上查阅。
Query Editor
- 用来指定获取哪一部分数据,类似于 SQL 查询语句。比如要在某个 row 里面展示 test 这张表的数据,那么 Query Editor 里面就可以写成 select * from test。
- 这只是一种比方,实际上每个 DataSource 获取数据的方式都不一样,所以写法也不一样,比如像 zabbix 数据则是以指定某个监控项的方式来获取的。
Organization
- org 是一个很大的概念,每个用户可以拥有多个 org,grafana 有一个默认的 main org 。
- 用户登录后可以在不同的 org 之间切换,前提是该用户拥有多个 org 。
- 不同的 org 之间完全不一样,包括 datasource、dashboard 等都不一样。
- 创建一个 org 就相当于开了一个全新的视图,所有的 datasource、dashboard 等都要再重新开始创建。
User
- Grafana 里面用户有三种角色:admin、editor、viewer。
- admin 权限最高,可以执行任何操作,包括创建用户、新增 Datasource、创建 DashBoard 等。
- editor 角色不可以创建用户、不可以新增 Datasource、可以创建 DashBoard 。
- viewer 角色仅可以查看 DashBoard 。
- 在 2.1 版本及之后新增了一种角色 read only editor(只读编辑模式),这种模式允许用户修改 DashBoard,但是不允许保存。
- 每个 user 可以拥有多个 organization 。
部署
运行容器:
docker run -d --name grafana --network grafana -p 3000:3000 grafana/grafana:6.6.2

默认登录账号密码为 admin/admin 。
压测结果采集:Jmeter + InfluxDB + Grafana
Jmeter 自带的监视器在 Windows 使用 GUI 模式运行时,其渲染和效果都不是太好,而在 linux 环境下又无法实时可视化。
因此如果有一个性能测试结果实时展示的页面,就可以提升我们对系统性能表现的掌握程度,另一方面也可以提升我们的测试效率。
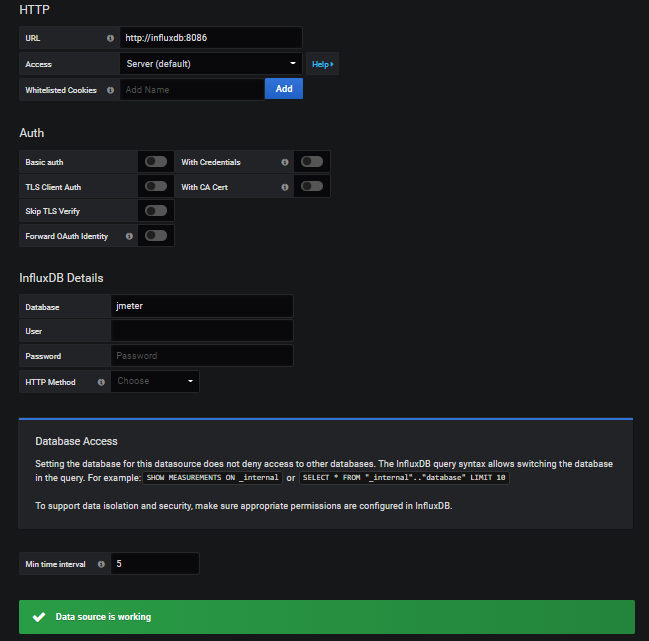
Grafana 添加 InfluxDB 数据源
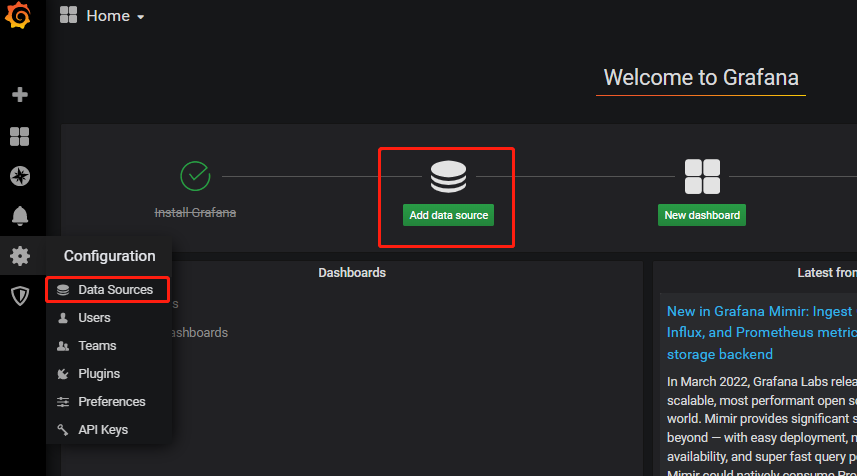
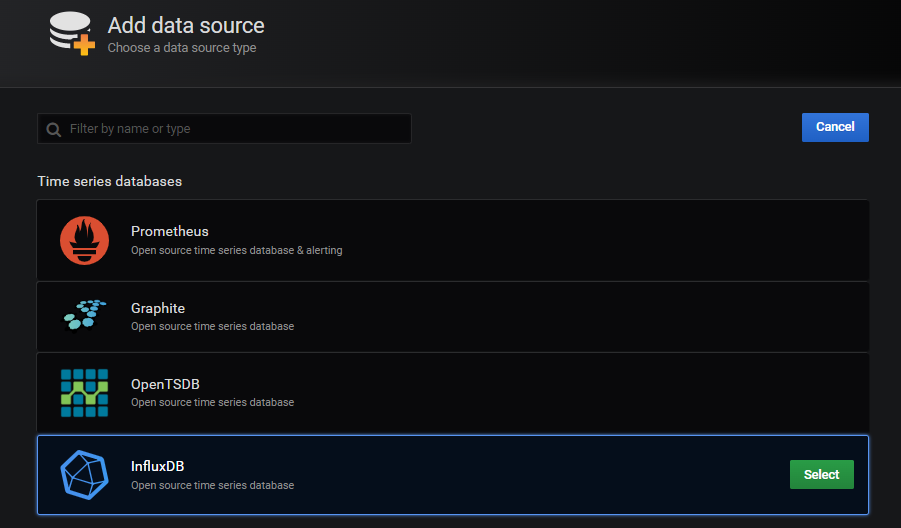
配置项:
URL:http://influxdb:8086:由于 grafana 和 influxdb 在在同个容器网络中,因此可直接填写【influxdb容器名:端口号】。Database:jmeter:在 influxdb 中创建的数据库名。Min time interval:5:每 5 秒刷新一次数据源(这里是与 jmeter backend listener 每 5 秒写入一次数据到 influxdb 保持同步)。
Grafana 创建 Jmeter 仪表盘
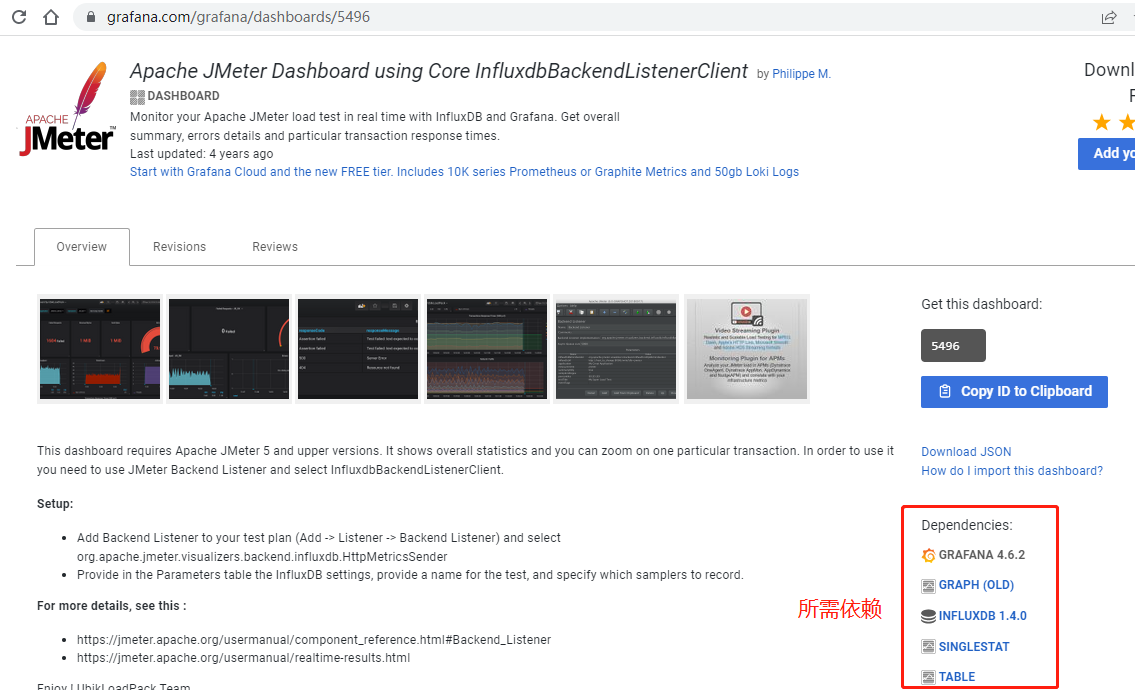
导入 Grafana 官方 Jmeter 仪表盘:Apache JMeter Dashboard using Core InfluxdbBackendListenerClient | Grafana Labs
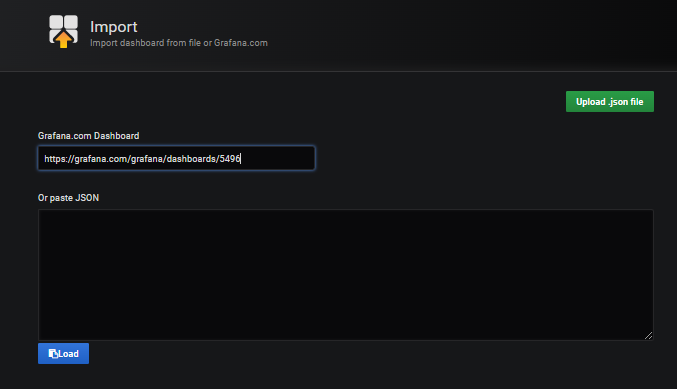
填写自定义配置:
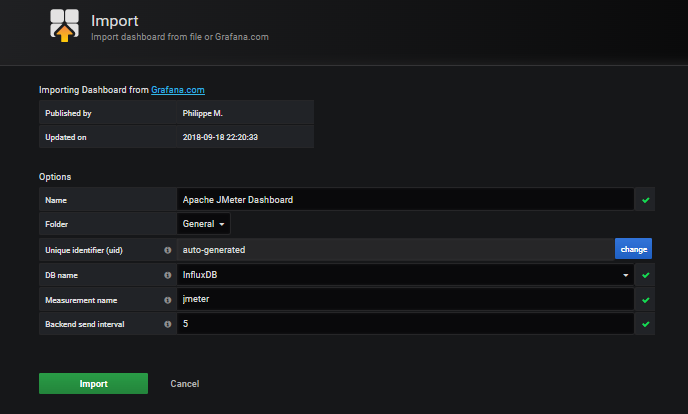
仪表盘创建成功:
Jmeter 配置 Influxdb 监听器
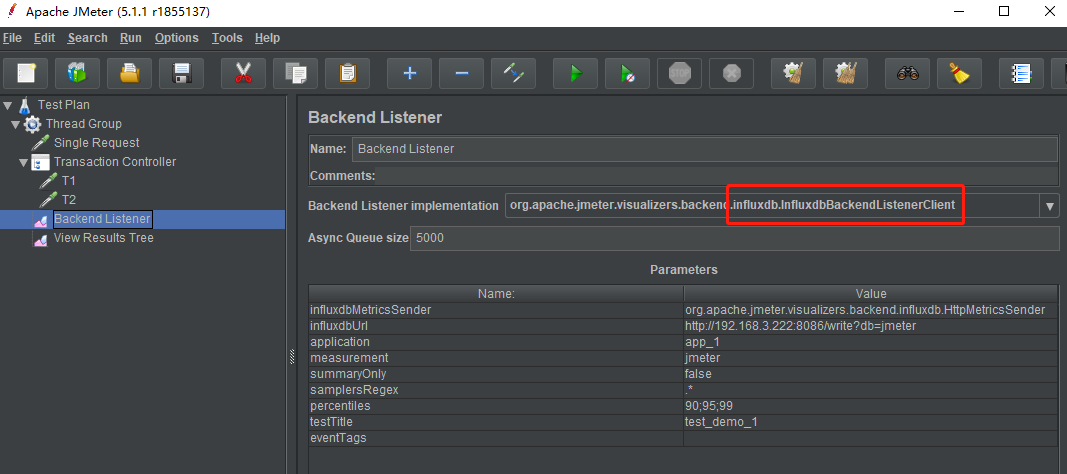
配置项说明:
influxdbUrl:http://192.168.3.222:8086/write?db=jmeter:influxdb 服务器地址以及写入的数据库。application:app_1自定义应用名称,可在 grafana 仪表盘中筛选区分。measurement:jmeter:influxdb 表名,默认为 jmeter(写入数据时会自动创建该表)。summaryOnly:false:在 grafana 仪表盘中显示详细 Error 信息。testTitle:test_demo_1:在 influxdb 表数据中作区分。
查看写入的 Influxdb 表数据:
[root@localhost ~]# docker exec -it influxdb influxConnected to http://localhost:8086 version 1.7.10
InfluxDB shell version: 1.7.10
> show measurements;
name: measurements
name
----
events
jmeter
>
> select * from jmeter limit 3;
name: jmeter
time application avg count countError endedT hit max maxAT meanAT min minAT pct90.0 pct95.0 pct99.0 rb responseCode responseMessage sb startedT statut transaction
---- ----------- --- ----- ---------- ------ --- --- ----- ------ --- ----- ------- ------- ------- -- ------------ --------------- -- -------- ------ -----------
1658844069082000000 app_1 0 0 0 0 1 internal
1658844074048000000 app_1 34.9375 16 42 30 41.3 42 42 39952 1872 all Single Request
1658844074050000000 app_1 34.9375 16 42 30 41.3 42 42 ok Single Request
>
> select * from events;
name: events
time application text title
---- ----------- ---- -----
1658844069036000000 app_1 test_demo_1 started ApacheJMeter
1658844215777000000 app_1 test_demo_1 ended ApacheJMeter
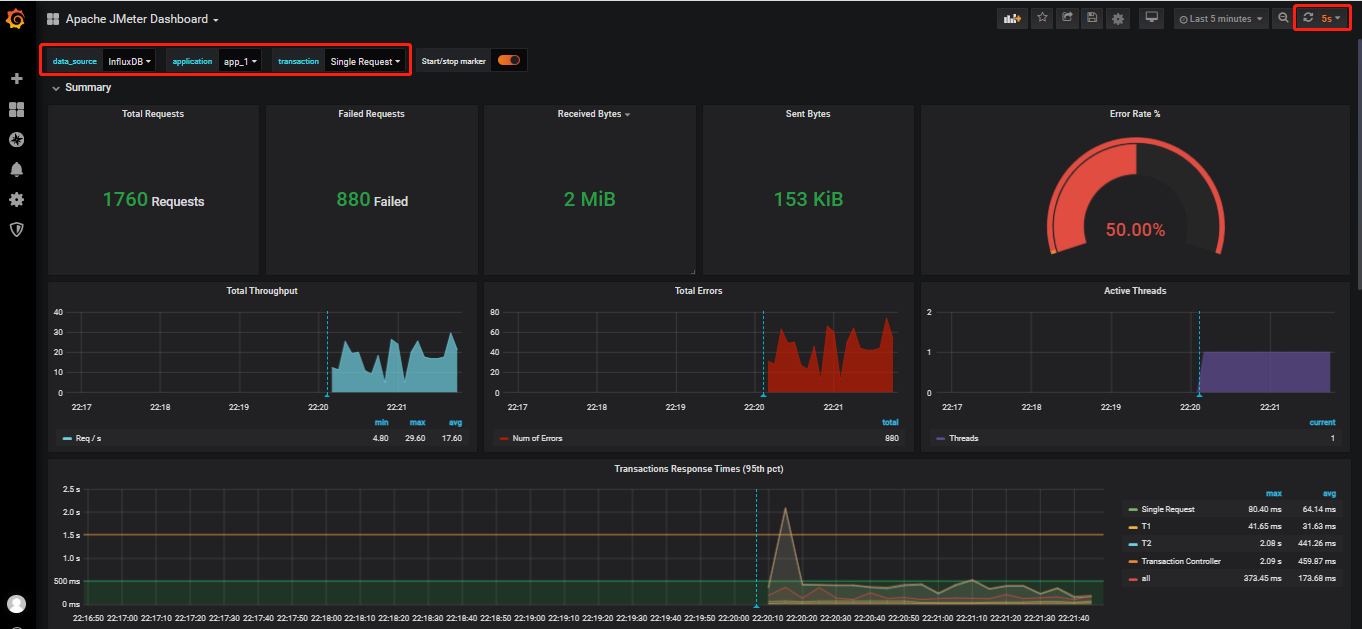
查看仪表盘展示:
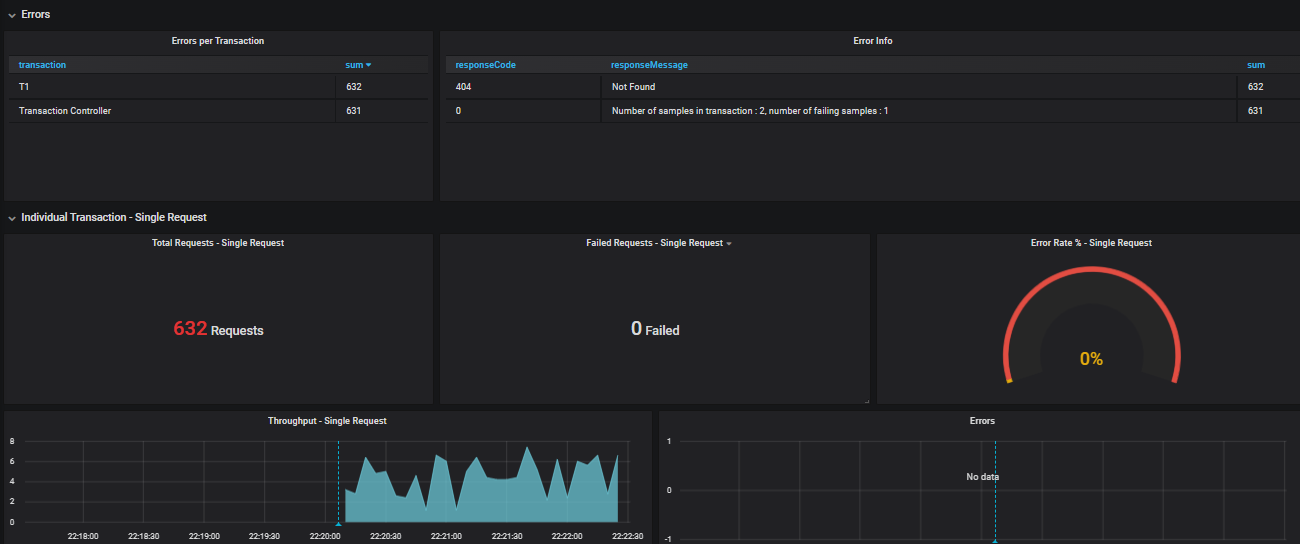
Prometheus(普罗米修斯)
简介
什么是 Prometheus ?
-
Prometheus(官网)是一套开源的监控&报警&时序数据库的组合,适合监控 Docker 容器。因为 Kubernetes 的流行带动了 Prometheus 的发展
-
Prometheus 是最初在 SoundCloud 上构建的开源系统监视和警报工具包,该项目拥有非常活跃的开发人员和用户社区。现在,它是一个独立的开源项目,并且独立于任何公司进行维护。为了强调这一点并阐明项目的治理结构,Prometheus 于 2016 年加入了 Cloud Native Computing Foundation,这是继 Kubernetes 之后的第二个托管项目。
Prometheus 优点:
- 非常少的外部依赖,安装使用超简单。
- 已经有非常多的系统集成,例如:docker、HAProxy、Nginx、JMX 等等。
- 服务自动化发现。
- 直接集成到代码。
- 设计思想是按照分布式、微服务架构来实现的。
Prometheus 特性:
- 多维度数据模型。
- 提供灵活的查询语言(PromQL)。
- 不依赖分布式存储,单个服务器节点是自主的。
- 以 HTTP 方式,通过 Pull 模型拉取时间序列数据。
- 也可以通过中间网关支持 Push 模型。
- 通过服务发现或者静态配置,来发现目标服务对象。
- 支持多种多样的图标和界面展示。
Prometheus 生态系统:
Prometheus 生态系统包含多个组件,其中许多是可选的。且大多数 Prometheus 组件都是用 Go 编写的,因此易于构建和部署为静态二进制文件。
- Prometheus server:它会抓取并存储时间序列数据。
- client libraries:用于检测应用程序代码。
- push gateway:一个支持短期工作的推送网关。
- 诸如 HAProxy、StatsD、Graphite 等服务的专用输出端。
- 一个 alertmanager 处理警报。
- 各种支持工具。
Prometheus 原理架构图:
下图说明了 Prometheus 的体系结构及其某些生态系统组件。
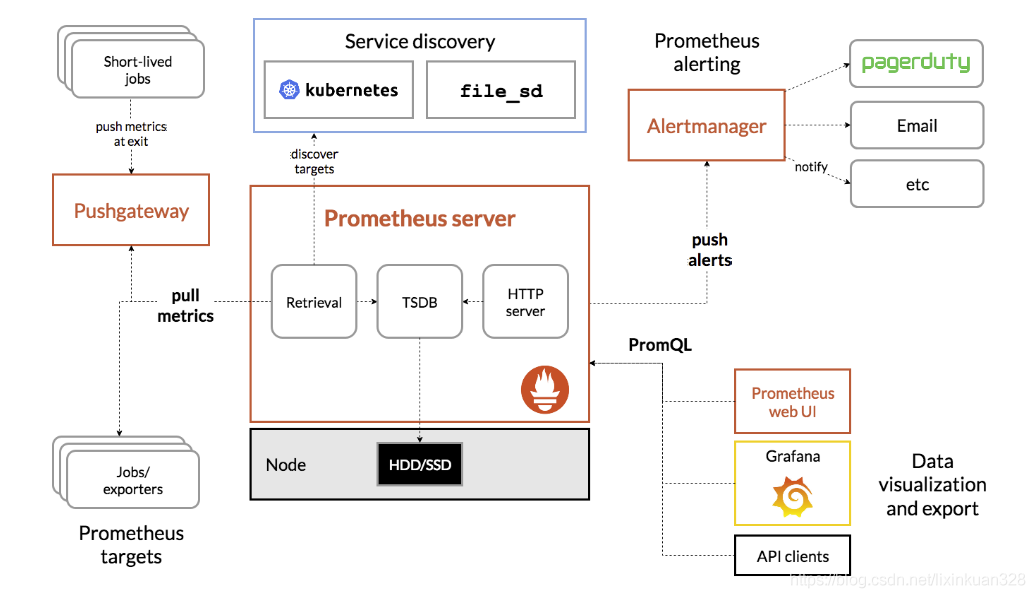
Prometheus 直接或通过中介推送网关从已检测作业中删除指标,以处理短暂的作业。它在本地存储所有报废的样本,并对这些数据运行规则,以汇总和记录现有数据中的新时间序列,或生成警报。Grafana 或其他 API 使用者可以用来可视化收集的数据。
Prometheus 应用场景:
-
什么时候适合?
- Prometheus 可以很好地记录任何纯数字时间序列。它既适用于以机器为中心的监视,也适用于高度动态的面向服务的体系结构的监视。在微服务世界中,它对多维数据收集和查询的支持是一种特别的优势。
- Prometheus 的设计旨在提高可靠性,使其成为中断期间要使用的系统,以使你能够快速诊断问题。每个 Prometheus 服务器都是独立的,而不依赖于网络存储或其他远程服务。当基础结构的其他部分损坏时,你可以依靠它,并且无需设置广泛的基础结构即可使用它。
-
什么时候不适合?
- 普罗米修斯重视可靠性。即使在故障情况下也始终可以查看有关系统的可用统计信息。如果你需要 100% 的准确性(例如按请求计费),则 Prometheus 并不是一个好的选择,因为所收集的数据可能不够详细和完整。在这种情况下,最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 进行其余的监视。
部署
配置文件:
https://github.com/prometheus/prometheus/blob/master/documentation/examples/prometheus.yml
运行容器:
docker run -d --name prometheus --network grafana -p 9090:9090 -v ${PWD}/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus:v2.16.0 --config.file=/etc/prometheus/prometheus.yml
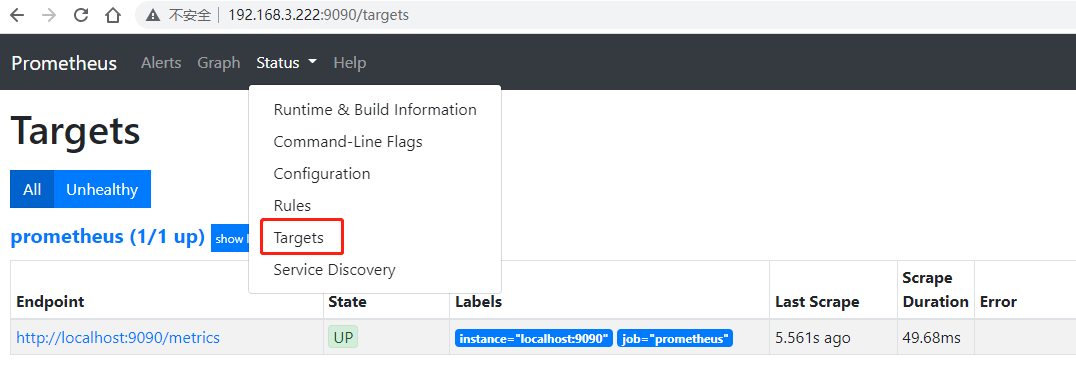
Web 访问 Prometheus:查看默认监控目标
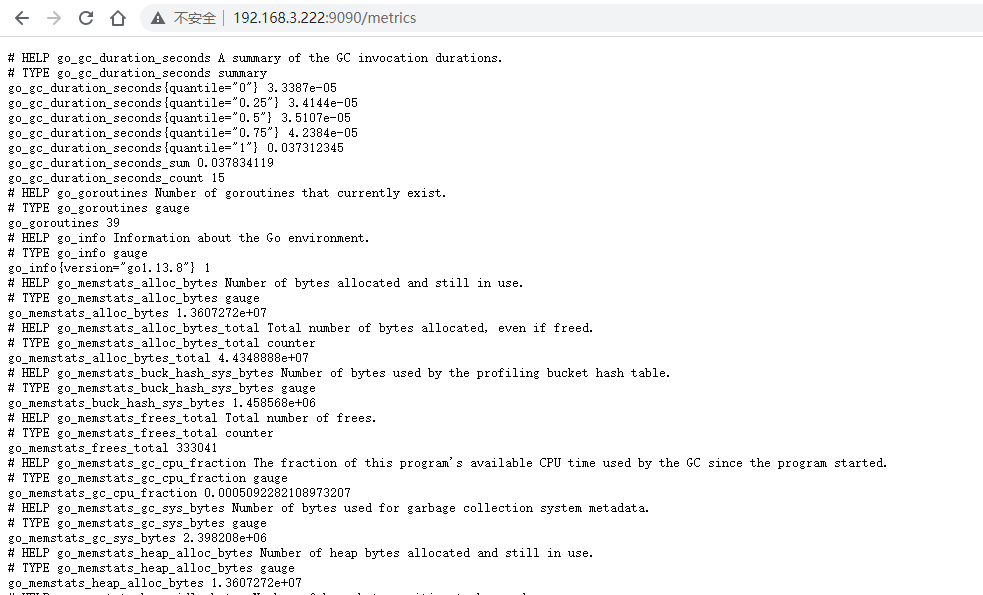
实时抓取监控数据,并存储在 Prometheus 数据库中:
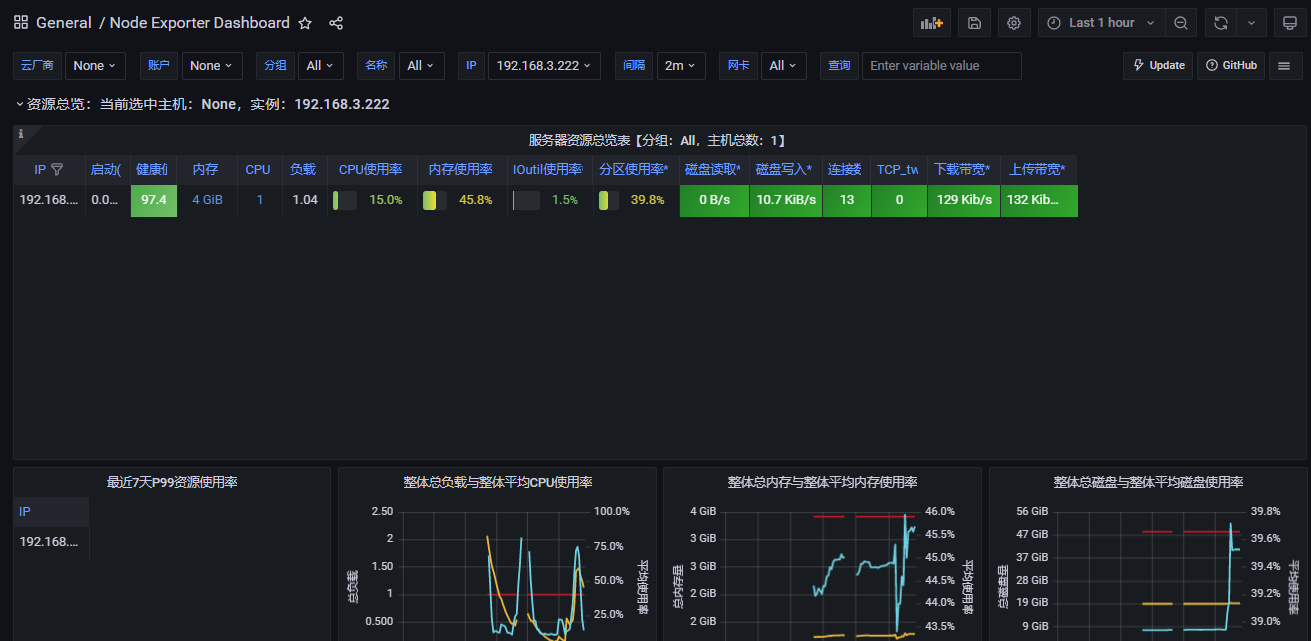
主机性能采集:Prometheus + Grafana
node_exporter
Prometheus 提供了各种监控 Agent,这里以主机性能监控【node_exporter】为例。
下载解压 node_exporter:
# 根据系统选择对应的下载包
[root@localhost prometheus]# wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz[root@localhost prometheus]# tar -zxvf node_exporter-1.3.1.linux-amd64.tar.gz
node_exporter-1.3.1.linux-amd64/
node_exporter-1.3.1.linux-amd64/LICENSE
node_exporter-1.3.1.linux-amd64/NOTICE
node_exporter-1.3.1.linux-amd64/node_exportergzip: stdin: unexpected end of file
tar: Unexpected EOF in archive
tar: Unexpected EOF in archive
tar: Error is not recoverable: exiting now
[root@localhost prometheus]# ls
node_exporter-1.3.1.linux-amd64 node_exporter-1.3.1.linux-amd64.tar.gz prometheus.yml
[root@localhost prometheus]# cd node_exporter-1.3.1.linux-amd64/
[root@localhost node_exporter-1.3.1.linux-amd64]# ls
LICENSE node_exporter NOTICE
启动 node_exporter:
# 查看启动参数
[root@localhost prometheus]# ./node_exporter --help
# 自定义启动端口,且限定访问IP
[root@localhost prometheus]# nohup ./node_exporter --web.listen-address="192.168.3.222:9102" &
# 不限定访问IP
[root@localhost prometheus]# nohup ./node_exporter --web.listen-address=":9102" &
修改 Prometheus 配置文件,添加 node_exporter 配置:
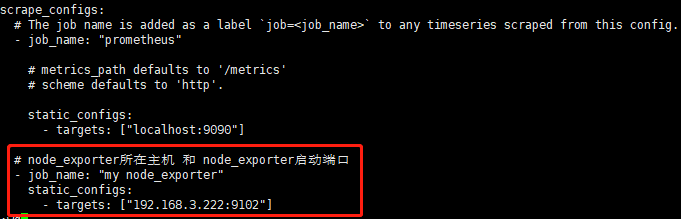
重启容器:
docker restart prometheus
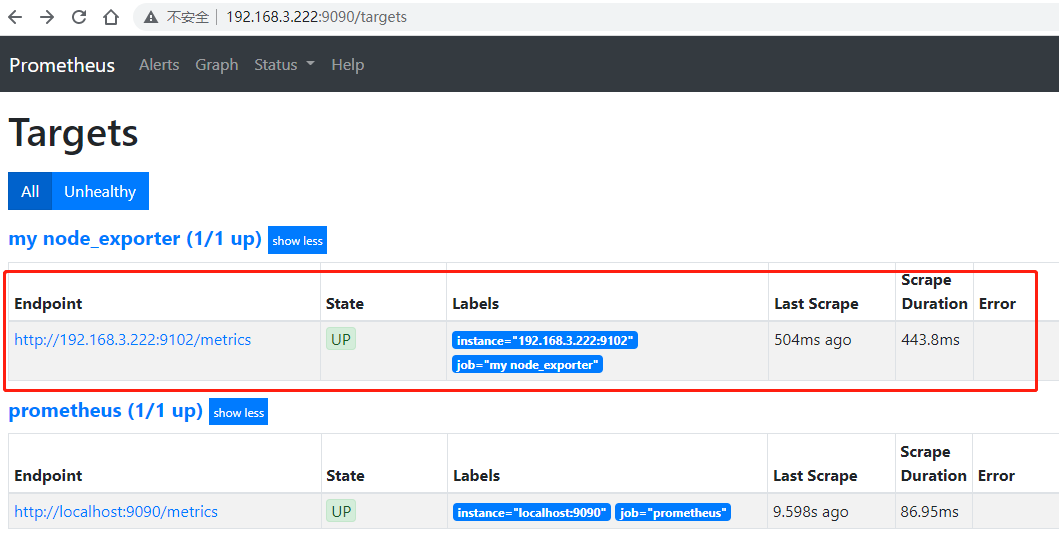
监控添加成功:
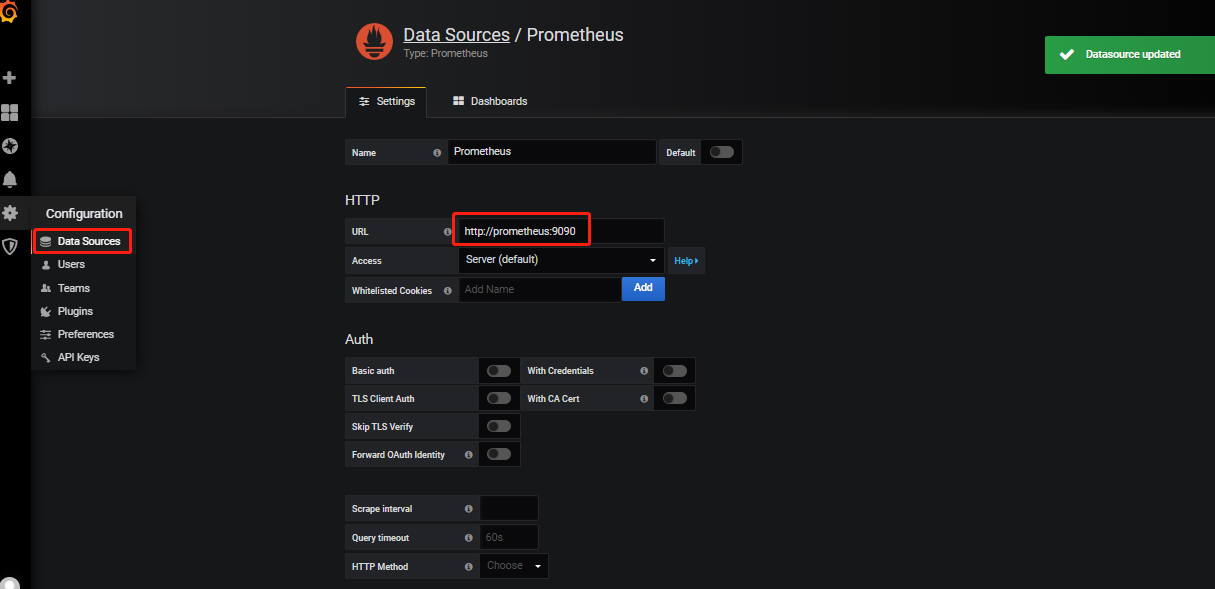
Grafana 添加 Prometheus 数据源
Grafana 导入 node_exporter 仪表盘
导入 Grafana 官方 node_exporter 仪表盘:Node Exporter Dashboard 220413 ConsulManager自动同步版 | Grafana Labs
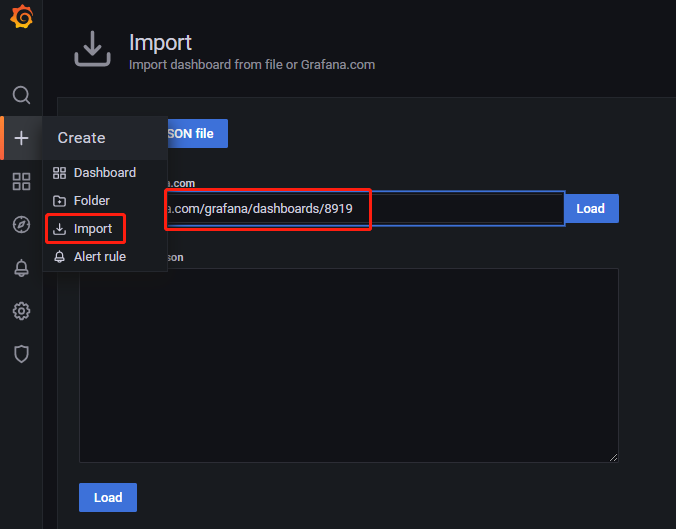
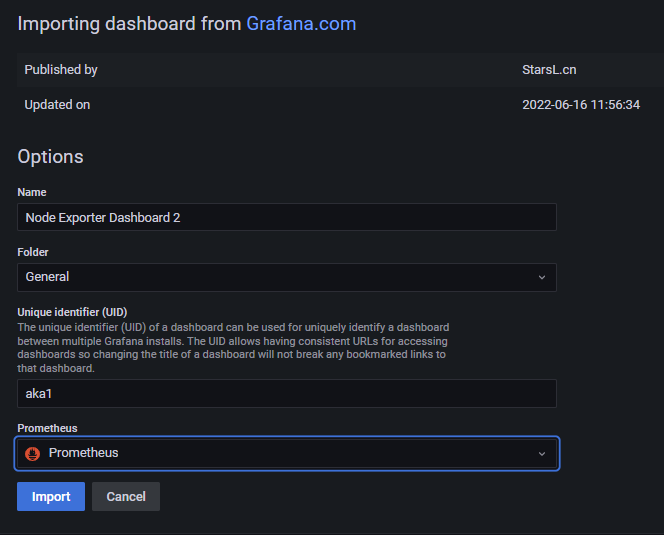
仪表盘导入成功: