一、概述、定义
目的:
迁移学习的目的是将某个领域或任务上学习到的模式、知识应用到不同但相关的领域里,获取更多数据,而不必投入许多时间人力来进行数据的标注。
举例:
已经会下中国象棋,就可以类比着来学习国际象棋;已经会编写Java程序,就可以类比着来学习C#;已经学会英语,就可以类比着来学习法语;已经学会了骑自行车,就可以类比学习骑摩托车等等。
定义:
Transfer Learning Definition:
Ability of a system to recognize and apply knowledge and skills learned in previous domains/tasks to novel domains/tasks.
通俗地讲,迁移学习就是运用已有的知识、模型来学习新的知识,构建新模型。其核心是找到已有知识与新知识的相似性与关联性。
重要概念:
域:某个时刻的某个特定领域——例如书本评论、电影评论;
任务:所要完成的任务与实现的功能——例如情感分析、实体识别;
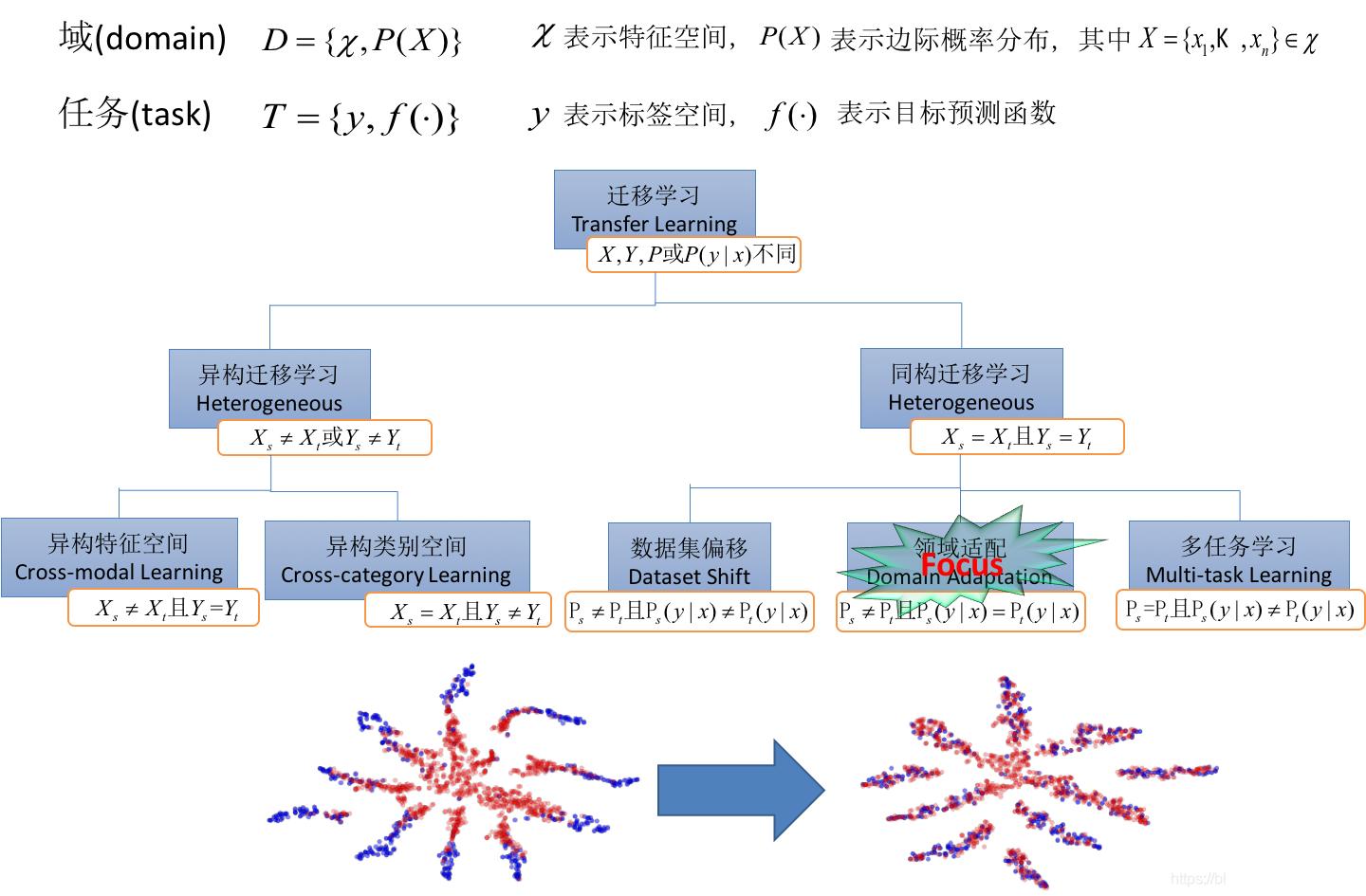
给定源域 和学习任务
、目标域
和学习任务
,迁移学习的目的是获取源域
和学习任务
中知识来帮助提升目标域
中预测函数
的学习。其中
或者
。
二、迁移学习的分类
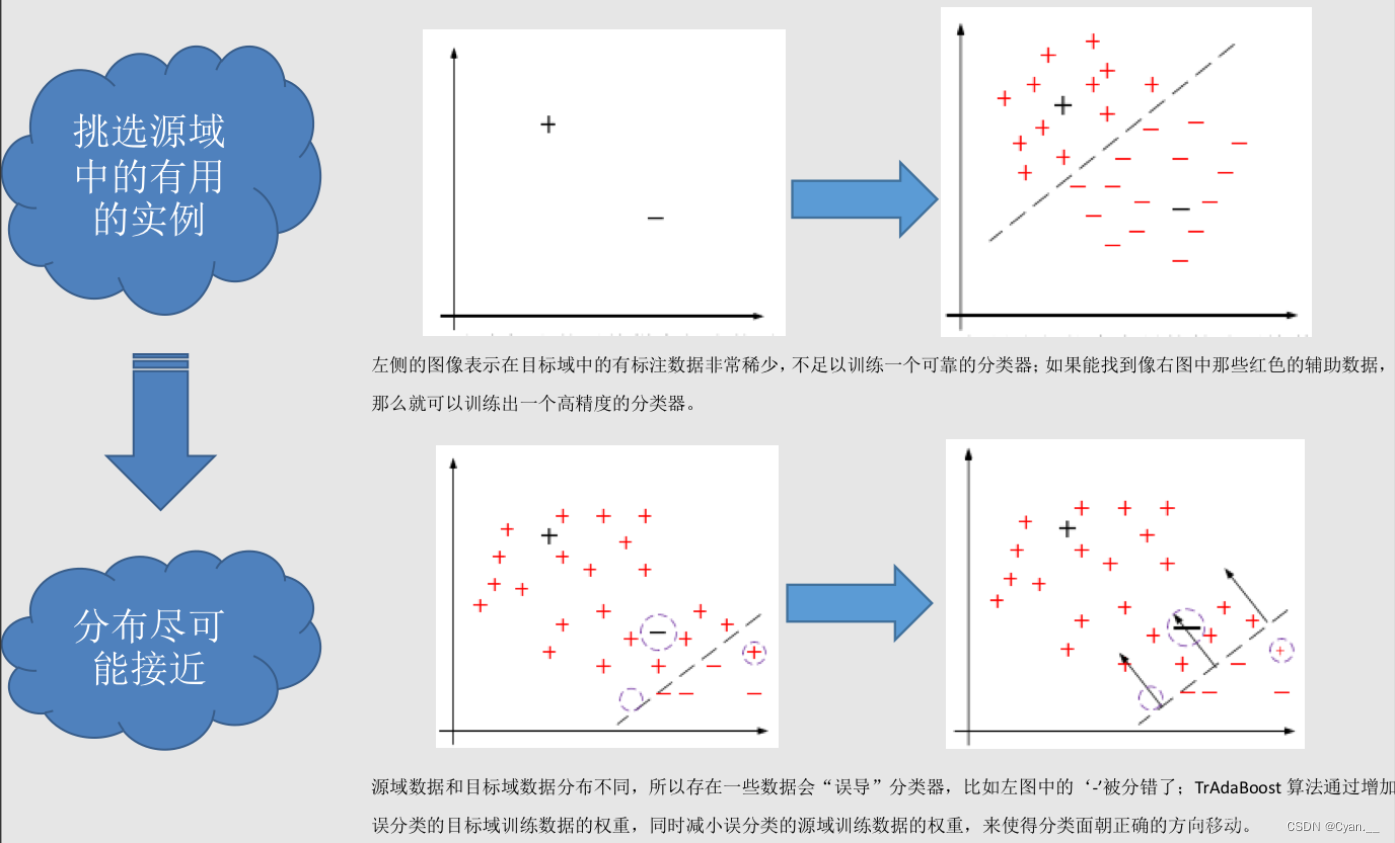
1. 基于实例的迁移
研究如何从源域中找出对目标领域训练有作用的实例。
例:在对源域的有标记数据实例中进行有效的权重分配,让源域的实例分布接近目标域的实例分布,从而在目标领域中建立一个分类精度较高并且可靠的学习模型。
迁移学习中,源域与目标域的数据分布不一致,故源域中并非所有有标记的数据实例都对目标域有作用。基于实例的迁移有现有的一些迁移算法,来对源域的有效数据迁移到目标域中。
TrAdaBoost算法就是典型基于实例的迁移。
TrAdaBoost算法的工作机制如下:
-
初始化:算法开始时,对源域和目标域数据的权重进行初始化。通常,目标域数据的初始权重会高于源域数据。
-
迭代更新:在每一轮中,算法使用当前的权重来训练一个弱分类器。分类器首先在目标域上测试,然后在两个域上进行误差评估。
-
权重调整:算法根据分类器的表现来调整数据点的权重。对于源域数据,分类正确的数据点权重会增加(使得算法在后续迭代中更少地关注这些点),而分类错误的数据点权重会减少。这与传统的AdaBoost相反,其核心思想是减少源域中对目标域帮助不大或有害的数据点的权重。对于目标域数据,权重更新与传统AdaBoost相同,即增加被错误分类数据点的权重。
-
终止条件:算法会在达到预定的迭代次数后停止,或者当目标域上的误差不再显著减少时停止。
-
组合弱分类器:最后,算法结合所有的弱分类器,形成一个强分类器。每个弱分类器根据其在目标域上的性能加权,性能越好的分类器影响越大。
通过这种方式,能够有效利用源域数据来帮助构建在目标域上表现良好的分类器,即便源域和目标域的数据分布有所不同。
2. 基于特征的迁移
①特征选择
找出源域和目标域之间共同的特征表示,找出特征之间对应的不同相关性,利用这些特征进行知识迁移。
②特征映射
将源域和目标域的数据从原始特征空间映射到新的特征空间之中。
源域的特征值经过一系列变换,对应到目标域的特征值,经过一一映射,使得源域数据与目标域的数据分布相同,从而在新的空间中,更好地利用源域已有的标记数据样本进行分类训练。最终对目标域的数据进行分类测试。
3. 基于共享参数的迁移
找到源域与目标域空间模型之间的共同参数或先验分布。
前提:学习任务的每个相关模型都会共享一些相同的参数或者先验分布。
三、迁移学习使用场景
1. 有大量数据样本,但大部分样本无标注
要想继续增加更多数据标注,需要付出很多成本。利用迁移学习思想,可以寻找一些和目标数据相似而且已经有标注的数据,利用数据之间的相似性对知识进行迁移,提高对目标数据的预测效果或者标注精度。
2. 帮助解决算法的冷启动问题
在跨域推荐系统将用户偏好模型从现有域(如图书推荐领域)迁移到一个新域(如电影推荐领域)中。
3. 想要获取具有更强泛化能力,但是数据样本较少. 许多应用场景数据量小
高质量有标签数据总是供不应求。传统的机器学习算法常常因为数据量小而产生过拟合问题,因而无法很好地泛化到新的场景中。
4. 数据来自不同的分布时
数据分布不仅会随着时间和空间而变化,也会随着不同的情况而变化,我们可能无法使用相同的数据分布来对待新的训练数据。已经训练完成的模型需要在使用前进行调整,在不同于训练数据的新场景下。
四、迁移学习的示例
例:假设现在要构建一个对手写数字进行识别的模型,但目前已有的已标注数据较少,如何不花费大量时间精力标注数据也能获得一个效果较好的模型?
方法:借助迁移学习,利用其它模型来辅助实现该任务。
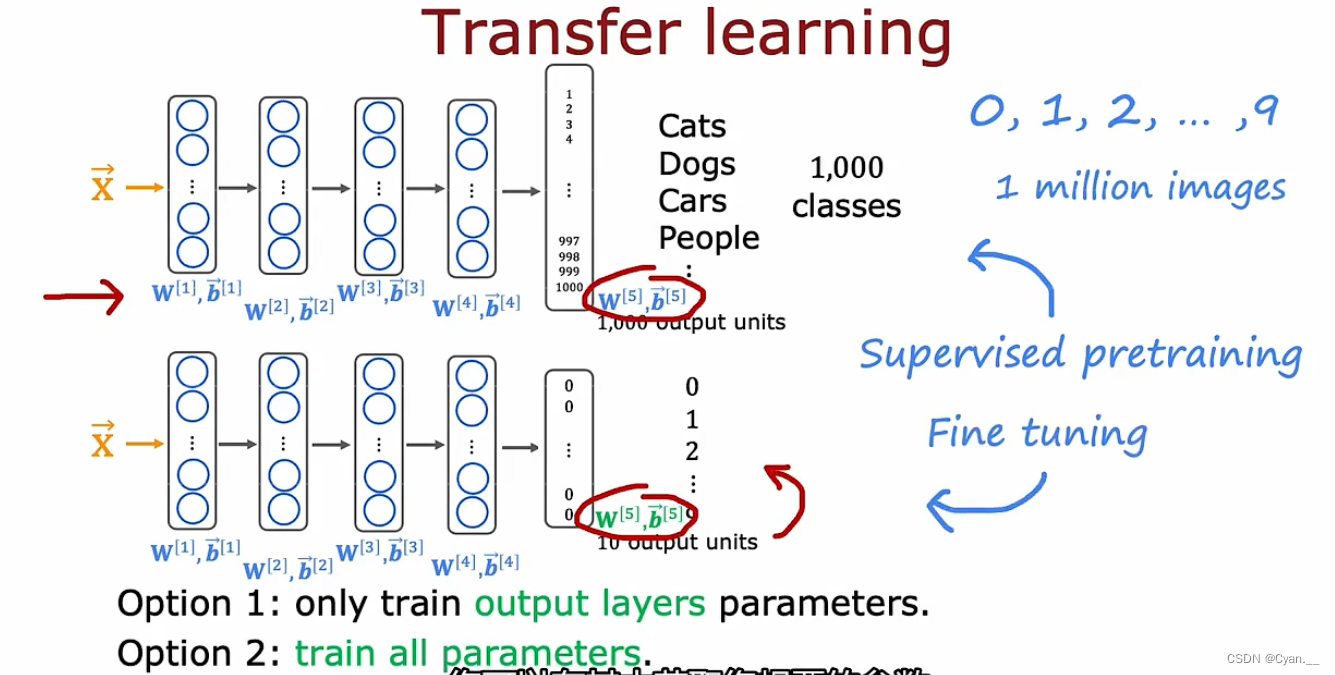
假设有一个已经训练好的可以识别猫、狗、汽车和人的图像识别模型。复制此神经网络,在其中插入新的参数,那么对于最后的输出层,可以消除输出层并用一个更小的输出层(10个)替换它。
可以做的是使用前几层隐藏层的参数(实际上是除输出层之外所有隐藏层),然后采用两种方法训练新的网络:
①将五个新的输出层参数作为顶部的值,固定它们然后使用随机梯度下降或Adam算法更新参数,来降低识别数字0到9的成本函数。
②更新并训练网络中的所有参数,但前几层参数可以借助之前的神经网络。
首先在大数据集上进行训练,然后再在较小的数据集上进一步调整参数,这就是监督预训练。
然后进行微调,在其中获取已初始化或从监督预训练中获得的参数,进一步运行梯度下降微调权重以适应对应新的学习任务的特定应用参数。
原理:如果同样是图像识别的神经网络,那么在前几层——检测图像边缘、检测角点、检测通用形状、基本曲线等等都是相同的步骤,因而可以通用进行。
故而,可以下载、借助他人预训练的神经网络来根据自己的数据进一步训练、微调神经网络以达成相应目的。