1 List 接口
java.util 中的集合类包含 Java 中某些最常用的类。最常用的集合类是 List 和 Map。
List是一种常用的集合类型,它可以存储任意类型的对象,也可以结合泛型来存储具体的类型对象,本质上就是一个容器。
1.1 List 类型介绍
- 有序性: List中的元素是按照添加顺序进行存放的。因为有序,所以有下标,下标从0开始
- 可重复性: List中可以存储重复的元素
List中主要有ArrayList、LinkedList两个实现类。
2 List 接口
2.1 List 初始化
// 创建集合
List list = new ArrayList<>();// 添加元素
list.add("hello");
list.add("world");
list.add("java");// public boolean remove(Object o):删除指定的元素,返回删除是否成功
list.remove("world");//true
// public E remove(int index):删除指定索引处的元素,返回被删除的元素
list.remove(1);//world
// public E set(int index,E element):修改指定索引处的元素,返回被修改的元素
list.set(1,"javaee");//world// IndexOutOfBoundsException
list.remove(3);
2.2 List 常用API
ArrayList和LinkedList通用方法。
方法名 说明
public boolean add(要添加的元素) 将指定的元素追加到此集合的末尾
public boolean remove(要删除的元素) 删除指定元素,返回值表示是否删除成功
public E remove(int index) 删除指定索引处的元素,返回被删除的元素
public E set(int index,E element) 修改指定索引处的元素,返回被修改的元素
public E get(int index) 返回指定索引处的元素
public int size() 返回集合中的元素的个数
boolean contains(Object o) 如果此列表包含指定的元素,则返回 true
boolean addAll(int index, Collection<? extends E> c) 将指定集合中的所有元素插入到此列表中,从指定的位置开始
void clear() 列表中删除所有元素
2.3 List 遍历方式
List<String> list = new ArrayList<String>();
list.add("aaa");
list.add("bbb");
list.add("ccc");//方法一:超级for循环遍历
for(String attribute : list) {System.out.println(attribute);
}
//方法二:对于ArrayList来说速度比较快, 用for循环, 以size为条件遍历:
for(int i = 0 ; i < list.size() ; i++) {system.out.println(list.get(i));
}
//方法三:集合类的通用遍历方式, 从很早的版本就有, 用迭代器迭代
Iterator it = list.iterator();
while(it.hasNext()) {System.ou.println(it.next);
}
3 ArrayList
ArrayList是Java中的实现List接口的类,底层使用数组来存储元素。但与数组相比,它具有更灵活的大小和动态的增加和删除元素。
注意: 由于 ArrayList 底层使用的是数组,因此一旦创建了 ArrayList,它的大小就是固定的。而当元素添加到 ArrayList 中时,如果底层数组已满,则需要创建一个更大的数组,并将原有元素复制到新数组中,这会带来一定的性能损耗。
因此,在实际开发中,建议在创建 ArrayList 时设置一个合适的初始化容量,避免在运行时频繁进行扩容操作,同时也可避免浪费过多空间资源。
例如:new ArrayList(50);将ArrayList初始容量改为50
3.1 ArrayList 数据结构
ArrayList的数据结构本质上就是数组。区别在于,数组是一种静态的数据结构,需要在创建数组时就指定它的长度,并且创建后长度无法改变。而ArrayList是一种动态的数据结构,它可以自动进行扩容。
3.2 ArrayList 类定义
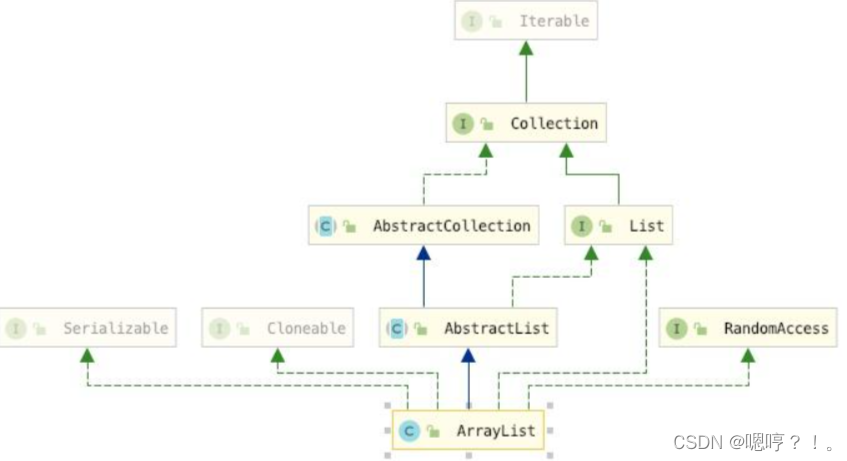
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
ArrayList是一个继承于AbstractList的线性数据结构。
AbstractList提供了List接口的默认实现(个别方法为抽象方法)
- ArrayList 实现 List 接口,能对它进行队列操作。
- ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
- ArrayList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
- ArrayList 实现RandomAccess接口,提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
3.3 ArrayList 特点
除了具备List有序性、可重复性特点外,ArrayList还具备以下的特点:
- 自动扩容 :当向ArrayList中加入的元素超过了其默认的长度时(由于ArrayList是数组的封装类,在创建ArrayList时不用给定长度,其默认长度为10),它会自动扩容以增加存储容量
- 随机访问:随机访问是指可以直接访问元素,而不需要从头部或者尾部遍历整个列表。由于ArrayList底层是用数组实现的,因此可以通过索引来快速访问元素。
- 慢速插入/删除::相比于链表(如LinkedList),ArrayList在中间插入或删除元素较慢,因为需要移动元素。
- 高效的遍历:由于ArrayList底层采用了数组来存储元素,所以对于ArrayList的遍历操作比较高效。
3.4 ArrayList 特定API
方法名 说明
ArrayList() ArrayList构造函数。默认容量是10
ArrayList(int initialCapacity) ArrayList带容量大小的构造函数
ArrayList(Collection<? extends E> c)创建一个包含collection的ArrayList
trimToSize() 将内部存储的数组大小调整为列表中元素的实际数量。
ensureCapacity(int minCapacity) 设置内部存储的数组大小,以容纳指定数量的元素。
toArray(T[] a) 将列表中的元素转换为指定类型的数组
4 LinkedList
LinkedList也是Java中实现List接口的常用集合类,底层使用的是双向链表数据结构。
与ArrayList不同,LinkedList在内部存储元素时,不是使用连续的内存空间,而是使用一个链表来存储元素。
4.1 LinkedList 数据结构
LinkedList底层采用的是双向链表(doubly linked list) 数据结构。链表中的每个节点(结点)都由两个部分组成,一部分是存储数据元素的值域,另一部分是指向前一个节点和后一个节点的指针(引用)。对于双向链表来说,除了一个指向前一个节点的指针外,还有一个指向后一个节点的指针
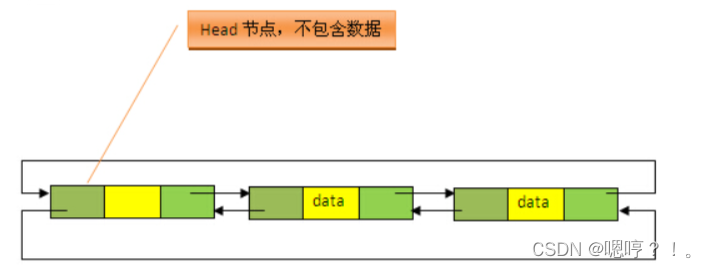
4.2 LinkedList 类定义
public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable
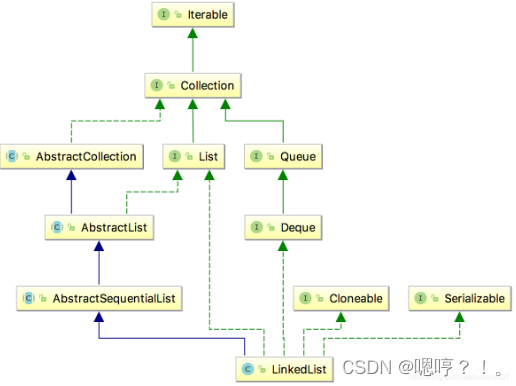
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
为什么要继承自AbstractSequentialList ?
AbstractSequentialList 实现了get(int index)、set(int index, E element)、add(int index, E element) 和 remove(int index)这些骨干函数。降低了List接口的复杂度。LinkedList双向链表通过继承于AbstractSequentialList,就相当于已经实现了“get(int index)这些接口”。
此外,若需要通过AbstractSequentialList自己实现一个自定义列表,只需要扩展此类,并提供 listIterator() 和 size() 方法的实现即可。若要实现不可修改的列表,则需要实现列表迭代器的 hasNext、next、hasPrevious、previous 和 index 方法即可。
- LinkedList 实现 List 接口,能对它进行队列操作。
- LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
- LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
- LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
4.3 LinkedList 特点
- 随机访问性能较差:LinkedList的随机访问性能较差,因为在链表中要从头开始遍历链表,直到找到目标元素。所以如果在代码中需要频繁进行随机访问元素的操作,LinkedList可能不是一个最佳的选择。
- 添加/删除操作快:由于LinkedList底层使用双向链表,因此它的添加和删除操作非常快,因为只需要更改指针的指向即可,不需要像ArrayList一样重新分配数组空间,而且LinkedList还支持在指定位置插入和删除元素。
- 需要额外空间:链表中每个节点都需要额外存储到前一个和后一个节点的指针,因此比数组等其他数据结构需要更多的内存空间。
- 适用于队列和双端队列:LinkedList还可以支持队列和双端队列的功能,如在链表头部或尾部添加或删除元素,实现队列和双端队列的常见操作。
4.4 LinkList 特定API
方法名 说明
LinkedList() 构造方法
LinkedList(Collection<? extends E> c) 创建一个包含collection的LinkedList
addFirst(E element) 将元素添加到列表的开头
getFirst() 返回列表的第一个元素。
getLast() 返回列表的最后一个元素。
removeFirst() 删除并返回列表的第一个元素。
removeLast() 删除并返回列表的最后一个元素。
5 ArrayList与LinkedList的比较
- 由于ArrayList的数据结构为数组,所以查询修改快,新增删除慢;而LinkedList的数据结构为链表结构,所以查询修改慢,新增删除快
- ArrayList是基于数组实现的动态数组,在内存中有连续的空间,可以通过下标访问元素,由于数组需要提前分配一定大小的空间,因此当元素数量增多之后,可能会导致数组空间不足需要重新分配数组,这种情况下可能会出现内存空间浪费;相比之下,LinkedList是基于链表实现的,每个元素都有一个引用指向下一个元素,不需要提前分配空间,因此能够更加灵活地插入和删除元素。然而,链表在内存中是不连续的,每个元素的引用占用额外的内存空间。由于链表中每个元素都需要有一个指向下一个元素的引用,因此在存储同样数量的元素时,LinkedList通常会占用比ArrayList更大的内存空间。
转载链接
https://www.cnblogs.com/lzq198754/p/5780165.html
https://blog.csdn.net/TestXzing/article/details/131197073
https://blog.csdn.net/jianyuerensheng/article/details/51204598



![[架构之路-261]:目标系统 - 设计方法 - 软件工程 - 软件设计 - 架构设计 - 网络数据交换格式](https://img-blog.csdnimg.cn/direct/23d059d38f7640c0b740cfb2812143ec.png)