本文将比较Apache Kafka和Redpanda两种开源的数据流技术,在云原生实时处理能力上的不同,以及如何在项目中做出选择。
目前,Apache Kafka不但成为了数据流处理领域事实上的标准,而且带动了同类产品的出现。Redpanda就是其中之一。它是一种轻量级的且兼容C++的Kafka实现。下面,我将和您一起探讨Apache Kafka和Redpanda之间的差异,以及如何对Kafka生态系统、许可证和社区采用等方面产生的影响。
1、Apache Kafka的增长曲线
在Kafka的采用成熟度方面,大多数公司往往或多或少地经历了如下过程:
· 从一个或几个用例开始,快速证明其业务价值。
· 将第一个应用程序部署到生产环境中,并全天候(24/7)地运行。
· 充分利用来自各个领域、业务和技术部门的数据流。
· 迁移到分布式数据中心的中枢系统。
下图展示了使用Maven下载Kafka Java客户端库的用户月活数的增长曲线:
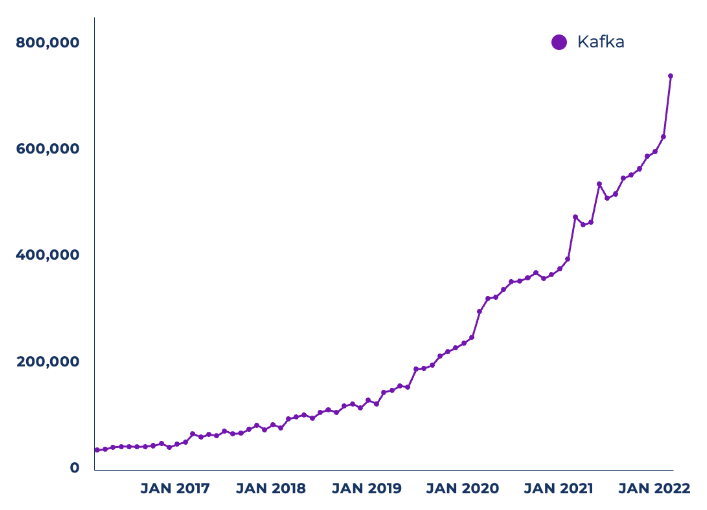
资料来源:Sonatype
显然,各种数据流的潜在用例和商业价值,是Kafka被采用的曲线能够持续增长的主要动因。而下图则展示了各个行业凭借着Kafka的低延迟、可扩展性、可靠性、以及真正的解耦性等特点,在不同的业务场景中创造的丰富数据价值。
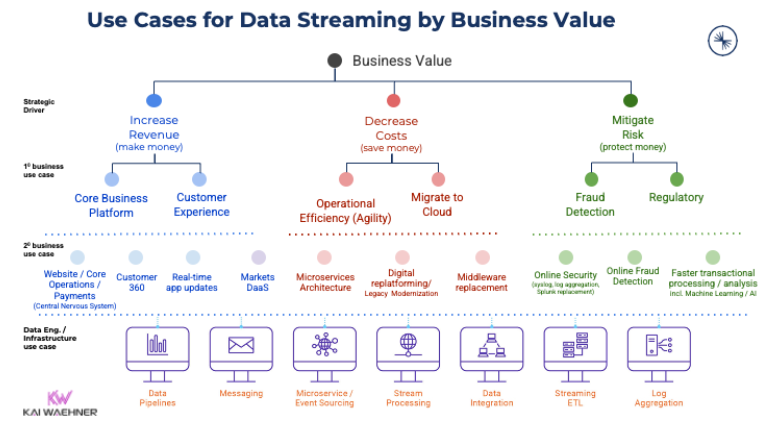
2、Redpanda:兼容Kafka的数据流
前面是对Kafka的现状介绍。下面,让我们来看看Kafka领域的新玩家:Redpanda。
作为一个数据流平台,Redpanda在其网站给出了如下市场定位和产品策略介绍:
- 去Java:它是一种既无需JVM,又摆脱了ZooKeeper的基础设施。
- 采用C++设计:此类设计旨在提供比Apache Kafka更好的性能。
- 单一的二进制架构:它并不依赖于其他任何库或节点。
- 自我管理和自我修复:它是一种可用于内部和云端部署的、简单且可扩展的架构。
- 与Kafka兼容:它针对现有应用程序、工具、以及集成的Kafka协议,提供了开箱即用的支持。
3、如何为您的项目选择合适的Kafka实现
我们往往需要从业务案例的需求出发,进行评估与定义。例如:正常运行时间、SLA、灾难恢复策略、企业支持、运营工具、托管式云服务、消息传递、数据获取、以及数据集成等功能与应用。下面,我们将对开源项目Apache Kafka和Redpanda(对Kafka协议的重新实现)进行比较,以便您根据实际需求,来予以评估和选择。
由于Redpanda和Apache Kafka的高级主张是相同的,因此我们首先来看两者的相同之处:
- 以数据流的方式持续、实时地处理大体量的数据。
- 使用分布式存储层去分离应用程序和域。
- 能够与各种数据源和数据接收器(data sink)相集成。
- 利用流式处理来关联数据,并能实时采取行动。
- 既能提供自我管理的操作,又可以使用完全托管的云产品。
下面,我们来深入了解Redpanda的各项特点。
4、部署选项:自我管理与云服务
如今,业务对于数据流的需求可谓比比皆是。虽然各行各业纷纷采用了云优先的战略,但是鉴于成本、延迟、以及安全要求,某些工作负载必须留在边缘处。对此,您除了自行配置Redpanda之外,还可以购买“Redpanda作为产品”,将其部署到自己的环境中。也就是说,您既可以使用Kubernetes(通常由供应商的外部控制层面提供支持),又可以利用云服务(由供应商完全实施管理)将其部署为环境中的数据层面,而非自行托管Redpanda。
Redpanda的这种不同部署选项,有点类似于Apache Kafka的Confluent部署选项。不过,其唯一缺陷是Redpanda并未提供关于云服务和企业级SLA的官方文档。
5、自带集群 (BYOC)
除了自行管理数据流集群和利用完全托管式的云服务之外,其实我们还有第三种选择:自带集群 (Bring Your Own Cluster,BYOC)。这种替代方案允许最终用户在自己的基础设施(如数据中心或云端的VPC)中,部署由供应商实施部分管理的解决方案。正如Redpanda的宣传口号说的那样:“Redpanda集群可以驻留在您的云服务处,并完全由Redpanda来打理。据此,您的数据将永远不会离开您的环境。”当然,这背后也潜藏着一些问题:
- 供应商如何访问您的数据中心或VPC?
- 谁来决定何时、以及如何扩展集群?
- 何时、以及如何部署集群,以修复错误或升级版本?
- 谁来保证SLA?是供应商吗?
- 对于受监管的行业,如何支持安全控制和合规性?
- 如何知晓供应商在您的环境中的各项行为?
- 如何定制第三方风险评估?
鉴于上述原因,用户要么将责任交给SaaS产品,要么自行控制。而云服务供应商往往仅能在自己的环境中提供托管服务。
6、既是社区产品也是商业产品
Redpanda的销售方式看起来与Confluent销售数据流的方式如出一辙。它既提供可用于生产环境的免费社区版,又在其企业版增加了分层存储、自动化数据平衡、以及24/7的企业支持等功能。
下面,我们来深入探讨Redpanda与Apache Kafka之间的技术差异。
7、Kafka协议的兼容性
为了提供API的兼容性,Redpanda重新实现了Kafka协议。不过它终究不是Kafka,无法保证来自Kafka生态系统的其他组件(如:Kafka Connect、Kafka Streams、REST Proxy和Schema Registry)在与仅使用Kafka协议、及其自我实现的非Kafka方案集成时,具有相同的表现。毕竟,即使其API能够100%地兼容,一些底层的行为也会有所差异。当然,这并不总是劣势。例如,Redpanda会专注于使用C++来进行性能上的优化,而在某些性能和内存情况下,C++所提供的性能会优于Java和JVM。
目前,Apache Kafka已经包含了用于数据集成的Kafka Connect,以及用于流处理的Kafka Streams。类似于大多数与Kafka相兼容的项目,Redpanda在其产品中也剔除了一些关键的、但“无用”的部分。因此,即使它号称具有100%的协议兼容性,也并不意味着该产品会重新实现Apache Kafka项目中的所有内容。
8、低延迟与基准化
在项目之初,我们需要考虑性能方面的需求。这往往离不开通过使用Apache Kafka、Apache Pulsar和Redpanda,进行概念验证(proof of concept,POC)。注意,不要随意采用有关性能和吞吐量的“基准”。这些基准通常只是针对某个特定问题提供的配置参考。我的同事Jack Vanlightly曾用如下图表,诠释了基准测试的相关概念。您可以参考一下:

资料来源:Jack Vanlightly
您可能会在Redpanda的基准测试中发现:Kafka并非为高吞吐量的生产者(producer)构建的。这正是Redpanda在吞吐量方面优于Kafka的地方。毕竟,在1 GB/s的用例中,谁又会仅创建4个生产者的吞吐量级呢?可见,基准化并不能说明一切,我们往往需要自行测试与尝试。
9、软实时与硬实时
当我们在谈论实时性时,通常是指数据处理管道至少需要几毫秒的时间,进行端到端的传输。这实际上是一种软实时,也是Apache Kafka、Apache Pulsar、Redpanda、Azure Event Hubs、Apache Flink、以及Amazon Kinesis等平台的实现方式。那么,什么是硬实时呢?
硬实时需要的是零延迟且无峰值的确定性网络。其典型的场景包括:制造业、汽车、机器人、证券交易等领域的嵌入式系统、现场总线、以及PLC。您可以通过搜索关键词--时间敏感网络(Time-Sensitive Networking,TSN),了解更多相关内容。可见,Kafka和Redpanda并不适用于此类OT(Operational Technology,运营技术),而适用于IT(Information Technology,信息技术)。在OT领域,我们往往需要采用由纯C或Rust构建的嵌入式软件。
10、无需ZooKeeper
除了采用C++而非JVM来实现之外,Redpanda的第二项独特之处在于:它不需要ZooKeeper和两个复杂的分布式系统。当然,Kafka如今凭借着KIP-500,也可以在没有ZooKeeper的情况下,被投入生产环境。
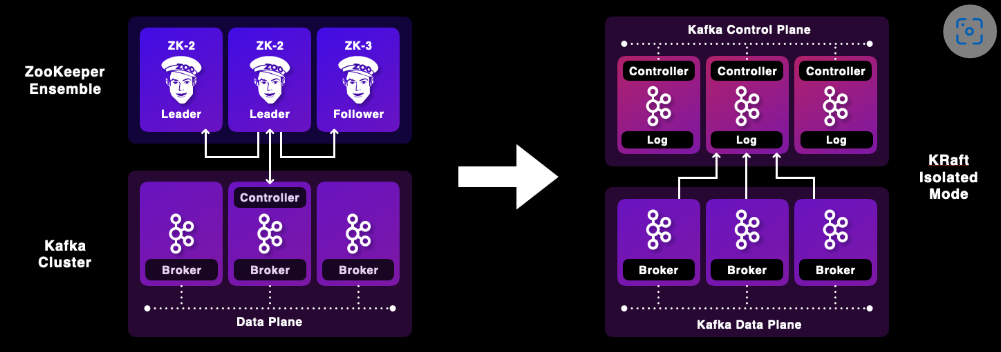
Redpanda的ZooKeeper-less数据流不仅对Kafka的可扩展性和可靠性有着巨大优势,而且操作十分简单。不过,新的ZooKeeper-less架构仍需要一些时间,才能投入生产环境,而且它仅受到新的Kafka集群的支持。虽然我们可以预见它会从今年开始,支持零停机和零数据丢失的迁移场景,但是作为成熟的软件产品,它有着严格的发布周期。
11、Redpanda的数据流
得益于C++的实现,Redpanda不但轻量级而且高效。这在有限的边缘硬件计算环境中非常实用。与基于JVM的Kafka引擎相比,您可以针对完整的端到端数据管道,使用Redpanda作为消息队列,以实现更高级的数据流用例。此外,Redpanda的延迟峰值比Apache Kafka更少。当然,在部署单个Kafka代理的边缘用例中,如果工业计算机 (IPC)在硬件上能够提供4到8 GB的内存,那么我们就可以围绕着Kafka和其他技术,去部署整个数据流平台。
12、跨集群的数据复制
如今,在各种应用中,拥有多个Kafka集群已是常态。针对不同国家、地区的灾难恢复、聚合、数据主权、以及从内部部署迁移到云端等用例,都需要多种类型的数据流集群。
通常,跨集群复制是Apache Kafka的一个组成部分。MirrorMaker 2(基于Kafka Connect)就能够支持此类用例。当然,来自Confluent Replicator或Cluster Linking等厂商的高级专有工具,会使得数据复制之类的用例更加便捷可靠,而不需要通过额外的基础设施,进行偏移同步等操作。
如下图所示,Kafka生态系统的数据流,非常适合作为去中心化数据网格的基础。此外,在数据复制方面,Redpanda同样可以使用Kafka的Mirrormaker。
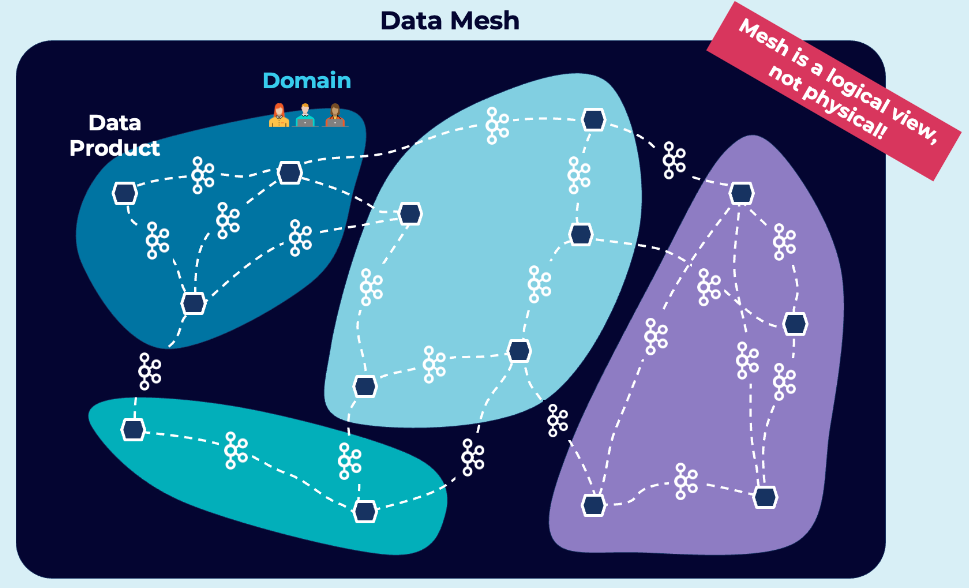
13、Apache Kafka和Redpanda之间的非功能性差异
我们在Redpanda与Apache Kafka之间进行选择时,技术性评估往往占有主导性地位。不过,许可证、采用曲线、以及总拥有成本(total cost of ownership,TCO)等非功能性因素,对于数据流平台的成功建立,有时候同样至关重要。
1)许可证
由于Apache Kafka使用非常宽松的Apache许可证 2.0,因此每个人,包括云服务提供商在内,都可以使用该框架,来构建内部应用程序、商业产品和云服务。提交者(Committer)和贡献者(Contribution)可以来自不同的公司和个人。
而Redpanda是根据更严格的资源可用性许可证 (Source Available License,BSL) 发布的。其目的是阻止云服务提供商将Redpanda的成果作为服务随意向外提供。虽然其目的是好的,但是它限制了不同社区和供应商更广泛地采用。与Kafka等Apache项目相比,外部贡献者、提交者、以及其他供应商选择该技术的可能性要小得多。当然,这对于其采用曲线而言,也会造成重大的影响。
2)成熟度、社区和生态系统
Kafka有着完善的文档,庞大的专家社区,大量的工具支持。其操作也更为直接。目前,您可以选择包括:在线课程、书籍、聚会和研讨会等形式的本地和在线Kafka资源。
而Redpanda是一个全新的产品和实现,其引擎和操作行为有所不同。由于除了其供应商的基本内容,并无太多的文档,也尚无专家支持,因此请无比仔细检查Redpanda网站给出的功能列表。例如,Redpanda的RBAC(基于角色的访问控制)文档会说:“Redpanda控制台中的RBAC,仅管理控制台用户的访问,而不管理通过Kafka API交互的客户端。若要限制Kafka API的访问,您需要使用Kafka ACL。” 同时,请确保不要像若干年前使用Apache Pulsar的用户那样,陷入产品功能营销方面的误区。
3)总体拥有成本和商业价值
TCO不仅仅包括了产品或云服务的购置成本。众所周知,数据流平台既需要专职的工程师进行运维和集成,也需要昂贵的项目负责人、架构师、以及开发人员,去构建应用程序。
您可能经常听到Redpanda宣传:“C++可以更有效地利用CPU资源。”不过,问题在于Kafka其实很少受到CPU的限制,而更多地受限于I/O。可以说,由于Redpanda与Kafka具有相同的网络和磁盘要求,因此这意味着Redpanda在基础设施的TCO方面与Kafka的差异并不大。
14、何时该选择Redpanda
而非Apache Kafka?
在如下情况下,您可以优先评估和考虑Redpanda,而不是Apache Kafka。
由于您的运营团队无法处理和分析JVM日志,因此需要C++基础设施。不过,请注意,这只涉及消息传递的内核,而不是数据集成、数据处理或Kafka生态系统的其他功能。
细微的性能差异对您来说非常重要,当然您并不需要硬实时性。
在笔记本电脑和自动化测试环境中进行简单、轻量级的开发。
15、小结
本文从技术和非功能性两个角度,和您探讨了该如何在Apache Kafka和Redpanda之间做出选择。总的说来,如果您需要企业级的解决方案、完全托管的云服务、广泛的生态系统(如:各种连接器、以及数据处理能力),并且可以接受10毫秒的延迟、以及几个p99峰值的话,选择Apache Kafka可能要比Redpanda更稳妥一些。





![[AutoSar]一种ECU间CAN通信的优化方法](https://img-blog.csdnimg.cn/direct/1b0d9998b63d4850b87a183f0f017978.png)
