以下主要介绍使用openpyxl模块操作excel及结合ddt实现数据驱动。
在此之前,我们已经实现了用unittest框架编写测试用例,实现了请求接口的封装,这样虽然已经可以完成接口的自动化测试,但是其复用性并不高。
我们看到每个方法(测试用例)的代码几乎是一模一样的,试想一下,在我们的测试场景中,
一个登录接口有可能会有十几条到几十条测试用例,如果每组数据都编写一个方法,
这样将会有更多的重复项代码,不仅执行效率不高,也不好维护。
接下来将会对框架进行优化,采用数据驱动方式:
- 把测试数据用excel表格管理起来,代码做封装;
- 用ddt来驱动测试,两部分相互独立。
一、openpyxl模块
openpyxl模块介绍
openpyxl是python第三方模块,运用openpyxl库可以进行excel的读和写。
在了解openpyxl模块之前,我们需要先熟悉excel的结构,才能更好理解openpyxl是如何操作excel。
从外到内,首先是一个excel文件(名),打开excel之后,会看到底部有一个或多个sheet(工作簿),每个sheet里有很多单元格,总体来说,主要分为三个层级。
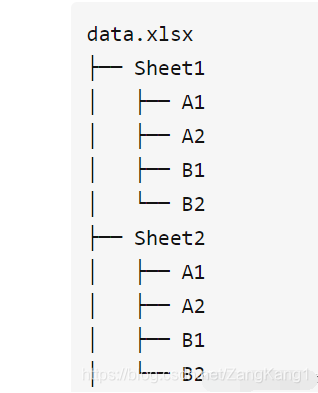
在opnepyxl里面,一个Excel文件对应着一个Workbook对象, 一个Sheet对应着一个Worksheet对象,而一个单元格对应着一个Cell对象。了解这些之后,对openpyxl是如何操作excel就比较清楚了。
openpyxl安装
pip install openpyxl
openpyxl简单使用
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
以上仅介绍openpyxl常用的语法,有兴趣了解更多内容可自行百度扩展。
二、Excel用例管理
在项目下,新建一个文件夹:data,文件夹下新建一个cases.xlsx文件,用来存放测试用例。
以下,是一个简单的登录测试用例设计模板:
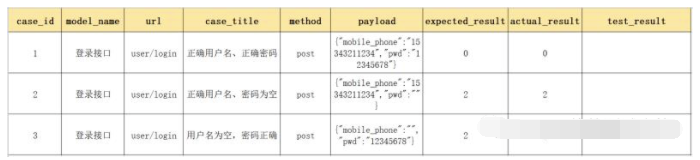
可以根据该表格生成实际结果,并将测试结果写入(Pass、Fail)表格。
公众号后台回复:接口测试用例模板,可以获取完整接口测试用例Excle模板。
既然有了用例模板,我们就开始从用openpyxl模块对excel读写数据。
如下,在common文件夹下,新建excel_handle.py,用于封装操作excel的类。
excel_handle.py
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
|
接下来结合ddt实现数据驱动,先简单来介绍下ddt。
三、ddt介绍及使用
ddt介绍
- 名称:Data-Driven Tests,数据驱动测试
- 作用:由外部数据集合来驱动测试用例的执行
- 核心的思想:数据和测试代码分离
- 应用场景:一组外部数据来执行相同的操作
- 优点:当测试数据发生大量变化的情况下,测试代码可以保持不变
- 实际项目:excel存储测试数据,ddt读取测试数据到单元测试框架(测试用例中)
补充:
所谓数据驱动,就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。说的直白些,就是参数化的应用。
ddt安装
pip install ddt
ddt使用
要想知道ddt到底怎么使用,我们从ddt模块源码中提取出三个重要的函数ddt、unpack、data。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
|
ddt:
装饰类,也就是继承自TestCase的类。
data:
装饰测试方法。参数是一系列的值。
unpack:
传递的是复杂的数据结构时使用。比如使用元组或者列表,添加unpack之后,ddt会自动把元组或者列表对应到多个参数上,字典也可以这样处理;当没有加unpack时,方法的参数只能填一个。
知道了具体应用后,简单来个小例子加深理解。
test_ddt.py
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
运行结果为:
Ran 2 tests in 0.001s
OK
15312344578 12345678
15387654321 12345678
上面的例子是为了加深理解,接下来介绍excel结合ddt实现数据驱动,优化之前的test_login.py模块。
test_login.py
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
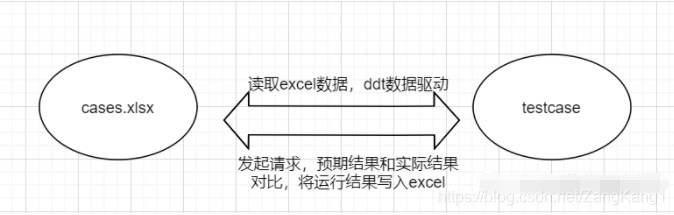
整体流程如下图:
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:485187702【暗号:csdn11】最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走! 希望能帮助到你!【100%无套路免费领取】



![源码泄露 [RoarCTF 2019]Easy Java1](https://img-blog.csdnimg.cn/direct/718101cb7af44fb9a4ded20b49d5ba7d.png)