目录
13.p 和 q 分别为指向该二叉树中任意两个结点的指针,试编写算法 ANCESTOR(ROOT,P,q,r),找到P和q的最近公共祖先结点 r
14.假设二叉树采用二叉链表存储结构,设计一个算法,求非空二叉树 b的宽度(即具有结点数最多的那一层的结点个数)
15.设有一棵满二叉树(所有结点值均不同),已知其先序序列为 pre,设计一个算法求其后序序列post。
16.设计一个算法将二叉树的叶结点按从左到右的顺序连成一个单链表,表头指针为 head.二叉树按二叉链表方式存储,链接时用叶结点的右指针域来存放单链表指针。
17.试设计判断两棵二叉树是否相似的算法。
13.p 和 q 分别为指向该二叉树中任意两个结点的指针,试编写算法 ANCESTOR(ROOT,P,q,r),找到P和q的最近公共祖先结点 r
后序遍历最后访问根结点,即在递归算法中,根是压在栈底的。本题要找 p 和g 的最近公共祖先结点了,不失一般性,设p在 的左边。算法思想:采用后序非递归算法,栈中存放二又树结点的指针,当访问到某结点时,栈中所有元素均为该结点的祖先。后序遍历必然先遍历到结点p,栈中元素均为 p 的祖先。先将栈复制到另一辅助栈中。继续遍历到结点 时,将栈中元素从栈顶开始逐个到辅助栈中去匹配,第一个匹配(即相等)的元素就是结点p和的最近公共祖先。
本题代码如下
// 查找二叉树中两个节点的最近公共祖先的函数,输入为一个指向tree的指针,以及两个指向treenode的指针p和q
tree find(tree* t, treenode* p, treenode* q)
{// 定义两个stack数组s1和s2,以及两个栈顶指针top1和top2,用于深度优先搜索 stack s1[10], s2[10];int top1 = -1, top2 = -1;treenode* tt = *t;// 当tt不为NULL或者栈s1不为空时,循环执行以下操作 while (tt != NULL || top1 != -1){// 当tt不为NULL时,循环执行以下操作,将tt及其所有左子节点压入栈s1中,并标记tag为0 while (tt != NULL){s1[++top1].t = tt;s1[top1].tag = 0;tt = tt->lchild;}// 当栈s1不为空且栈顶元素的tag为1时,循环执行以下操作,检查栈顶元素是否为p或q,如果是,则将其压入栈s2中 while (top1 != -1 && s1[top1].tag == 1){if (s1[top1].t == p){for (int i = 0; i <= top1; i++){s2[i] = s1[i];}top2 = top1;}if (s1[top1].t == q){// 从栈s1和栈s2的顶部开始,逐一对比两个栈中的元素,如果找到相同的元素,则返回该元素的指针,这就是p和q的最近公共祖先 for (int i = top1; i >= 0; i--){for (int j = top2; j >= 0; j--){if (s2[j].t == s1[i].t)return s1[i].t;}}}top1--;}// 如果栈s1不为空,则将栈顶元素的tag设为1,并将tt设为栈顶元素的右子节点,开始遍历右子树 if (top1 != -1){s1[top1].tag = 1;tt = s1[top1].t->rchild;}}// 如果遍历完整棵树都没有找到公共祖先,则返回NULL return NULL;
}完整测试代码
#include<stdio.h>
#include<stdlib.h>
typedef struct treenode
{char data;struct treenode* lchild, * rchild;
} treenode, * tree;
typedef struct
{treenode* t;int tag;
} stack;
void buildtree(tree* t)
{char ch;ch = getchar();if (ch == '#')*t = NULL;else{*t = (treenode*)malloc(sizeof(treenode));(*t)->data = ch;(*t)->lchild = NULL;(*t)->rchild = NULL;buildtree(&(*t)->lchild);buildtree(&(*t)->rchild);}
}
// 查找二叉树中两个节点的最近公共祖先的函数,输入为一个指向tree的指针,以及两个指向treenode的指针p和q
tree find(tree* t, treenode* p, treenode* q)
{// 定义两个stack数组s1和s2,以及两个栈顶指针top1和top2,用于深度优先搜索 stack s1[10], s2[10];int top1 = -1, top2 = -1;treenode* tt = *t;// 当tt不为NULL或者栈s1不为空时,循环执行以下操作 while (tt != NULL || top1 != -1){// 当tt不为NULL时,循环执行以下操作,将tt及其所有左子节点压入栈s1中,并标记tag为0 while (tt != NULL){s1[++top1].t = tt;s1[top1].tag = 0;tt = tt->lchild;}// 当栈s1不为空且栈顶元素的tag为1时,循环执行以下操作,检查栈顶元素是否为p或q,如果是,则将其压入栈s2中 while (top1 != -1 && s1[top1].tag == 1){if (s1[top1].t == p){for (int i = 0; i <= top1; i++){s2[i] = s1[i];}top2 = top1;}if (s1[top1].t == q){// 从栈s1和栈s2的顶部开始,逐一对比两个栈中的元素,如果找到相同的元素,则返回该元素的指针,这就是p和q的最近公共祖先 for (int i = top1; i >= 0; i--){for (int j = top2; j >= 0; j--){if (s2[j].t == s1[i].t)return s1[i].t;}}}top1--;}// 如果栈s1不为空,则将栈顶元素的tag设为1,并将tt设为栈顶元素的右子节点,开始遍历右子树 if (top1 != -1){s1[top1].tag = 1;tt = s1[top1].t->rchild;}}// 如果遍历完整棵树都没有找到公共祖先,则返回NULL return NULL;
}
int main()
{tree t;buildtree(&t);treenode* p = t->rchild->lchild, * q = t->rchild->rchild;treenode* result = find(&t, p, q);if (result)printf("%c与%c的最近公共祖先为:%c",p->data,q->data,result->data);elseprintf("没找到公共祖先");return 0;
}用ABD##E##CF##G##测试
/* A
B C
D E F G */

14.假设二叉树采用二叉链表存储结构,设计一个算法,求非空二叉树 b的宽度(即具有结点数最多的那一层的结点个数)
采用层次遍历的方法求出所有结点的层次,并将所有结点和对应的层次放在一个队列中。然后通过扫描队列求出各层的结点总数,最大的层结点总数即为二叉树的宽度。
/* A
B C
D E F G */
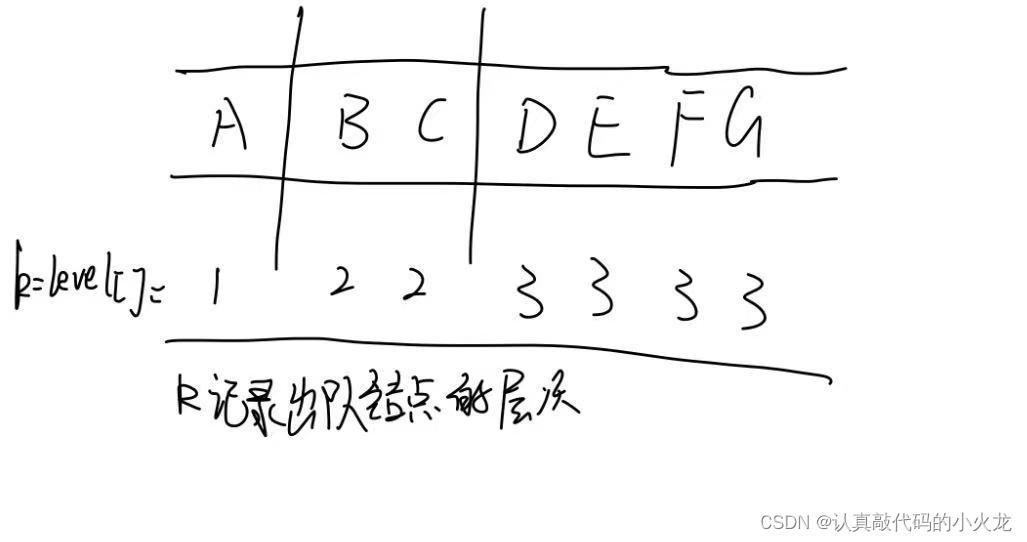
本题代码如下
int width(tree* t)
{quene q;tree p;int k;q.f = q.r = -1;//队列为空q.r++;q.data[q.r] = *t;//根结点进队q.level[q.r] = 1;//根结点层次为1while (q.f < q.r){q.f++;//出队p = q.data[q.f];//出队结点k = q.level[q.f];//出队结点的层次if (p->lchild != NULL)//左孩子进队{q.r++;q.data[q.r] = p->lchild;q.level[q.r] = k + 1;}if (p->rchild != NULL)//右孩子进队{q.r++;q.data[q.r] = p->rchild;q.level[q.r] = k + 1;}}int max = 0;//保留同一层最多的结点个数int i = 0;//i扫描队中的所有元素k = 1;//k表示从第一层开始查找int n;//n统计第k层中的结点个数while (i <=q.r){n = 0;while (i <=q.r && q.level[i] == k)//记录同一层有多少元素{n++;i++;}k = q.level[i];//将k等于下一层的层数if (n > max)//保留最大的nmax = n;}return max;
}完整测试代码
#include<stdio.h>
#include<stdlib.h>
typedef struct treenode
{char data;struct treenode* lchild, * rchild;
}treenode,*tree;
typedef struct
{tree data[10];int level[10];int f, r;
}quene;
void buildtree(tree* t)
{char ch;ch = getchar();if (ch =='#')*t = NULL;else{*t = (treenode*)malloc(sizeof(treenode));(*t)->data = ch;(*t)->lchild = NULL;(*t)->rchild = NULL;buildtree(&(*t)->lchild);buildtree(&(*t)->rchild);}
}
int width(tree* t)
{quene q;tree p;int k;q.f = q.r = -1;//队列为空q.r++;q.data[q.r] = *t;//根结点进队q.level[q.r] = 1;//根结点层次为1while (q.f < q.r){q.f++;//出队p = q.data[q.f];//出队结点k = q.level[q.f];//出队结点的层次if (p->lchild != NULL)//左孩子进队{q.r++;q.data[q.r] = p->lchild;q.level[q.r] = k + 1;}if (p->rchild != NULL)//右孩子进队{q.r++;q.data[q.r] = p->rchild;q.level[q.r] = k + 1;}}int max = 0;//保留同一层最多的结点个数int i = 0;//i扫描队中的所有元素k = 1;//k表示从第一层开始查找int n;//n统计第k层中的结点个数while (i <=q.r){n = 0;while (i <=q.r && q.level[i] == k)//记录同一层有多少元素{n++;i++;}k = q.level[i];//将k等于下一层的层数if (n > max)//保留最大的nmax = n;}return max;
}
int main()
{tree t;buildtree(&t);int widthnum = width(&t);printf("二叉树的宽度为:%d", widthnum);return 0;
}用ABD##E##CF##G##测试
/* A
B C
D E F G */![]()
15.设有一棵满二叉树(所有结点值均不同),已知其先序序列为 pre,设计一个算法求其后序序列post。
对一般二叉树,仅根据先序或后序序列,不能确定另一个遍历序列。但对满二叉树,任意一个结点的左、右子树均含有相等的结点数,同时,先序序列的第一个结点作为后序序列的最后个结点。
本题代码如下
void pretopost(char *pre,int l1,int h1,char post[],int l2,int h2)
{int half = 0;if (h1 >= l1){post[h2] = pre[l1];//后序最右端等于先序最左端half = (h1 - l1) / 2;pretopost(pre, l1 + 1, l1 + half, post, l2, l2 + half - 1);//转换左子树pretopost(pre, l1 + half + 1, h1, post, l2 + half, h2 - 1);//转换右子树}
}完整测试代码
#include<stdio.h>
void pretopost(char *pre,int l1,int h1,char post[],int l2,int h2)
{int half = 0;if (h1 >= l1){post[h2] = pre[l1];//后序最右端等于先序最左端half = (h1 - l1) / 2;pretopost(pre, l1 + 1, l1 + half, post, l2, l2 + half - 1);//转换左子树pretopost(pre, l1 + half + 1, h1, post, l2 + half, h2 - 1);//转换右子树}
}
int main()
{char *pre = "ABDECFG";char post[10];pretopost(pre, 0, 6, post, 0, 6);printf("后序序列为:");for (int i = 0; i <= 6; i++)printf("%c", post[i]);return 0;
}![]()
16.设计一个算法将二叉树的叶结点按从左到右的顺序连成一个单链表,表头指针为 head.二叉树按二叉链表方式存储,链接时用叶结点的右指针域来存放单链表指针。
通常我们所用的先序、中序和后序遍历对于叶结点的访问顺序都是从左到右,这里我们选择中序递归遍历。
设置前驱结点指针 pre,初始为空。第一个叶结点由指针 head 指向,遍历到叶结点时,就将它前驱的 rchild 指针指向它,最后一个叶结点的 rchild 为空。
本题代码如下
tree head =NULL, pre = NULL;
tree inorder(tree* t)
{if (*t){inorder(&(*t)->lchild);//中序遍历左子树if ((*t)->lchild == NULL && (*t)->rchild == NULL)//处理叶结点if(pre==NULL){head = *t;pre = *t;//处理第一个叶结点}else{pre->lchild = *t;pre = *t;//将叶结点链入链表}inorder(&(*t)->rchild);//中序遍历右子树pre->rchild = NULL;//设置链表尾}return head;
}完整测试代码
#include<stdio.h>
#include<stdlib.h>
typedef struct treenode
{char data;struct treenode* lchild, * rchild;
}treenode,*tree;
void buildtree(tree* t)
{char ch;ch = getchar();if (ch =='#')*t = NULL;else{*t = (treenode*)malloc(sizeof(treenode));(*t)->data = ch;(*t)->lchild = NULL;(*t)->rchild = NULL;buildtree(&(*t)->lchild);buildtree(&(*t)->rchild);}
}
tree head =NULL, pre = NULL;
tree inorder(tree* t)
{if (*t){inorder(&(*t)->lchild);//中序遍历左子树if ((*t)->lchild == NULL && (*t)->rchild == NULL)//处理叶结点if(pre==NULL){head = *t;pre = *t;//处理第一个叶结点}else{pre->lchild = *t;pre = *t;//将叶结点链入链表}inorder(&(*t)->rchild);//中序遍历右子树pre->rchild = NULL;//设置链表尾}return head;
}
int main()
{tree t;buildtree(&t);head=inorder(&t);while (head){printf("%c", head->data);head = head->lchild;}return 0;
}用ABD##E##CF##G##测试
/* A
B C
D E F G */![]()
17.试设计判断两棵二叉树是否相似的算法。
若T1和T2都是空树,则相似;若有一个为空另一个不空,则必然不相似:否则递归地比较它们的左、右子树是否相似。
本题代码如下
int similar(tree* t1, tree* t2)
{int lefts, rights;if (*t1 == NULL && *t2 == NULL)//两树皆空return 1;else if (*t1 == NULL || *t2 == NULL)//只有一树为空return 0;else//递归判断{lefts = similar(&(*t1)->lchild, &(*t2)->lchild);rights = similar(&(*t1)->rchild, &(*t2)->rchild);return (lefts && rights);}
}完整测试代码为
#include<stdio.h>
#include<stdlib.h>
typedef struct treenode
{char data;struct treenode* lchild, * rchild;
} treenode, * tree;
void buildtree(tree* t)
{char ch;ch = getchar();if (ch == '#')*t = NULL;else{*t = (treenode*)malloc(sizeof(treenode));(*t)->data = ch;(*t)->lchild = NULL;(*t)->rchild = NULL;buildtree(&(*t)->lchild);buildtree(&(*t)->rchild);}
}
int similar(tree* t1, tree* t2)
{int lefts, rights;if (*t1 == NULL && *t2 == NULL)//两树皆空return 1;else if (*t1 == NULL || *t2 == NULL)//只有一树为空return 0;else//递归判断{lefts = similar(&(*t1)->lchild, &(*t2)->lchild);rights = similar(&(*t1)->rchild, &(*t2)->rchild);return (lefts && rights);}
}
int main()
{tree t1, t2;buildtree(&t1);getchar();buildtree(&t2);int T = similar(&t1, &t2);if (T == 1)printf("相似");elseprintf("不相似");return 0;
}用下面的两棵树测试
/*
第一棵树
A
B
AB###
第二棵树
C
D
C#D##

换另外一种测试
/*
第一棵树
A
A##
第二棵树
C
C##





![Python自动化测试系列[v1.0.0][多种数据驱动实现附源码]](https://img-blog.csdnimg.cn/20200415142950316.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2Rhd2VpX3lhbmcwMDAwMDA=,size_16,color_FFFFFF,t_70)