GAIA: A Benchmark for General AI Assistants
- 前言
- Abstract
- 1 Introduction
- 2 Related work
- 3 GAIA
- 3.1 A convenient yet challenging benchmark for general AI assistants
- 3.2 Evaluation
- 3.3 Composition of GAIA
- 3.4 Building and extending GAIA
- 4 LLMs results on GAIA
- 5 Discussion
- 6 Limitations
- 7 Acknowledgements
- 阅读总结
前言
一篇来自Meta、HuggingFace、AutoGPT联合投稿的Agent Benchmark的工作,为当前百花齐放的Agent领域带来了评测的标准。这篇工作详细介绍了GAIA的设计理念,展望了GAIA的未来,讨论了当前GAIA的不足,细读下来可以看到这些大佬们对于这个当前火热领域的热切期待。
| Paper | https://arxiv.org/pdf/2311.12983.pdf |
|---|---|
| Code | https://huggingface.co/gaia-benchmark |
| From | arXiv 21 Nov 2023 |
Abstract
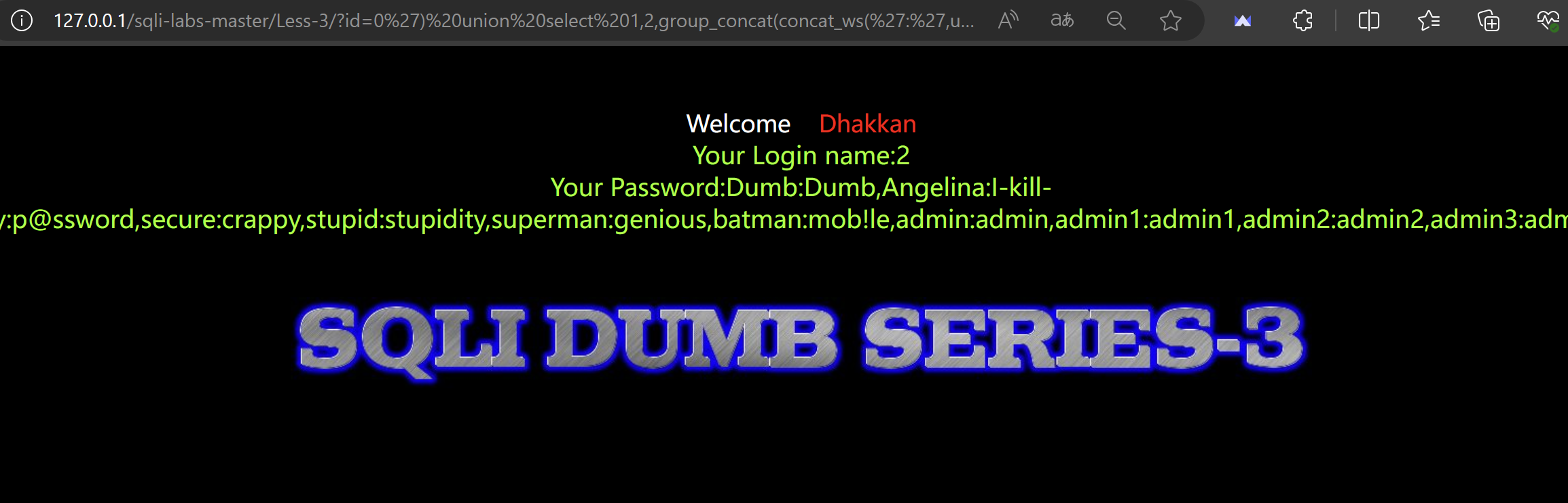
本文提出GAIA,一个通用AI助手的benchmark。GAIA提出真实世界的问题,需要一系列基本能力,如推理,多模态处理,网页浏览和一般工具使用等。GAIA的问题概念上对人类都很简单,但对于先进的AI模型却具有挑战,比如人类能够完成92%的任务而接入插件的GPT-4只能完成15%。GAIA的理念本质上背离了当前AI的发展趋势,即针对人类更加困难的任务。作者认为,AGI的出现取决于系统能否在此问题上表现出和人类相似的鲁棒性。作者在GAIA的方法下设计了466个问题及其答案,同时保留其中300个问题的答案,以便于之后的模型刷榜。
1 Introduction
现有的LLM知识丰富,与人类的喜好对齐,可以通过一些工具进行增强,然而评测这些系统是一个悬而未决的问题,LLM由于其不断涌现的新能力而常常刷榜。
为了研究更多挑战性的benchmarks,当前的趋势是寻找对人类更难的任务来挑战LLM,但是对于人类来说困难的任务对LLM来说不一定是困难的,可能的原因是数据污染。此外,开放式问题往往需要人工评估或者模型评估。随着任务越来越复杂,人工评估也变得困难,而模型评估又依赖于更强的模型,因此无法评估最先进的模型。
总而言之,需要新的benchmarks来评估现有的AI系统,除了对人类困难的任务外,也可以构建概念上简单的任务,但需要执行具有大组合空间的复杂动作序列,输出只有完成任务才能获得,并且易于验证。
本文提出通用AI助手benchmark GAIA,它包含466个精心设计的问题和答案,以及相关的设计方法。这些问题对LLM来说很有挑战性,大多数任务都需要复杂的生成。GAIA通过以下目标来避免LLMs评估的困难:
- 真实世界和富有挑战性的问题。
- 问题都是概念上对人类简单的任务,具有很好的解释性。
- 非游戏性。必须强制完成一系列步骤,无法走捷径。不用担心数据污染的问题。
- 易于使用。只接受zero-shot。
尽管LLM能够完成对人类来说困难的任务,但是在GAIA上表现不佳,即使可以外接工具,GPT-4对于最简单的任务成功率也不超过30%,对于最困难的任务一个也完成不了,而与此同时,人类的平均成功率是92%。本文介绍了GAIA的组成,设计以及如何提出问题和相关挑战,以便社区进行扩展。本文还分析了最新智能体的成功和不足,证明其潜力。作者公布了166个带注释的数据集,以及300个不带注释的问题集用于评测。作者希望这篇工作能够成为下一代AI系统的里程碑。
2 Related work
随着LLM能力的迅速提升,benchmark的测试以越来越快的速度变得饱和。几年前阅读理解还是一个具有挑战性的问题,2018年引入了通用语言理解评估benchmark GLUE,不到一年模型的能力在该数据集上就超过了人类。为了寻找更难的评估,一个方向是在各个领域专业水平知识的任务,比如MMLU,但是很快LLM就又超过了人类。更广泛的LLM对话能力上的评估包括:
- 汇编评估。容易因为数据泄露造成污染。
- 人工评估。耗时,难以扩展。
- 比当前LLM更强的模型评估。容易受到模型本身的限制。
因此,当前的评估方法仍然滞后,大多数评估依赖于封闭系统、特定的API调用或者给定的正确方法来评估。而GAIA依赖于现实世界的交互。
3 GAIA
3.1 A convenient yet challenging benchmark for general AI assistants
GAIA试图去规避LLMs的不足,它由466个人工标注的问题组成,基于文本,有时会有文件(图像、表格等),涉及各种需要助手的场景。这些问题的答案简短且唯一,易于验证。
在设计上,GAIA有四点原则:
- 针对概念上简单的问题。让LLM专注于基本能力(推理,多模态理解,工具使用),而不是专业技能。
- 可解释性。任务的概念简单,用户很容易理解模型的推理轨迹。
- 对记忆的鲁棒性。数据中不存在纯文本的结果答案,且不容易因为数据的泄露而污染评估(推理轨迹限制)。即使还是出现灾难性知识泄露问题,设计新的问题也是很容易的。
- 易用性。任务只是简单的提示,可能附带文件,问题的答案是真实的,并且简洁明确。
3.2 Evaluation
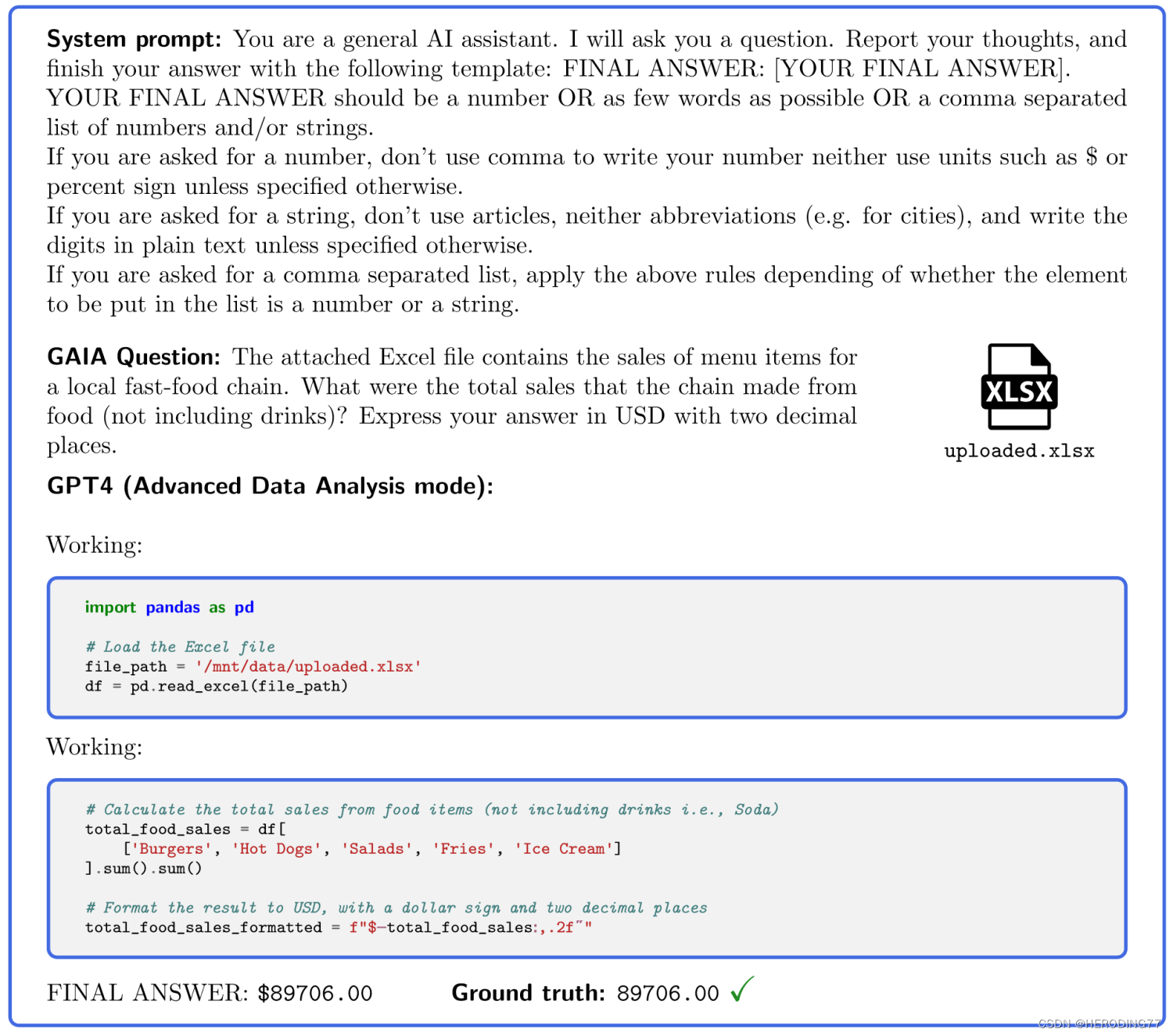
GAIA的设计使得评估自动化、快速且真实。每个问题都有一个正确答案,因此评估是通过模型的答案和ground truth之间的匹配完成的。系统的prompt模板如上图所示。
3.3 Composition of GAIA
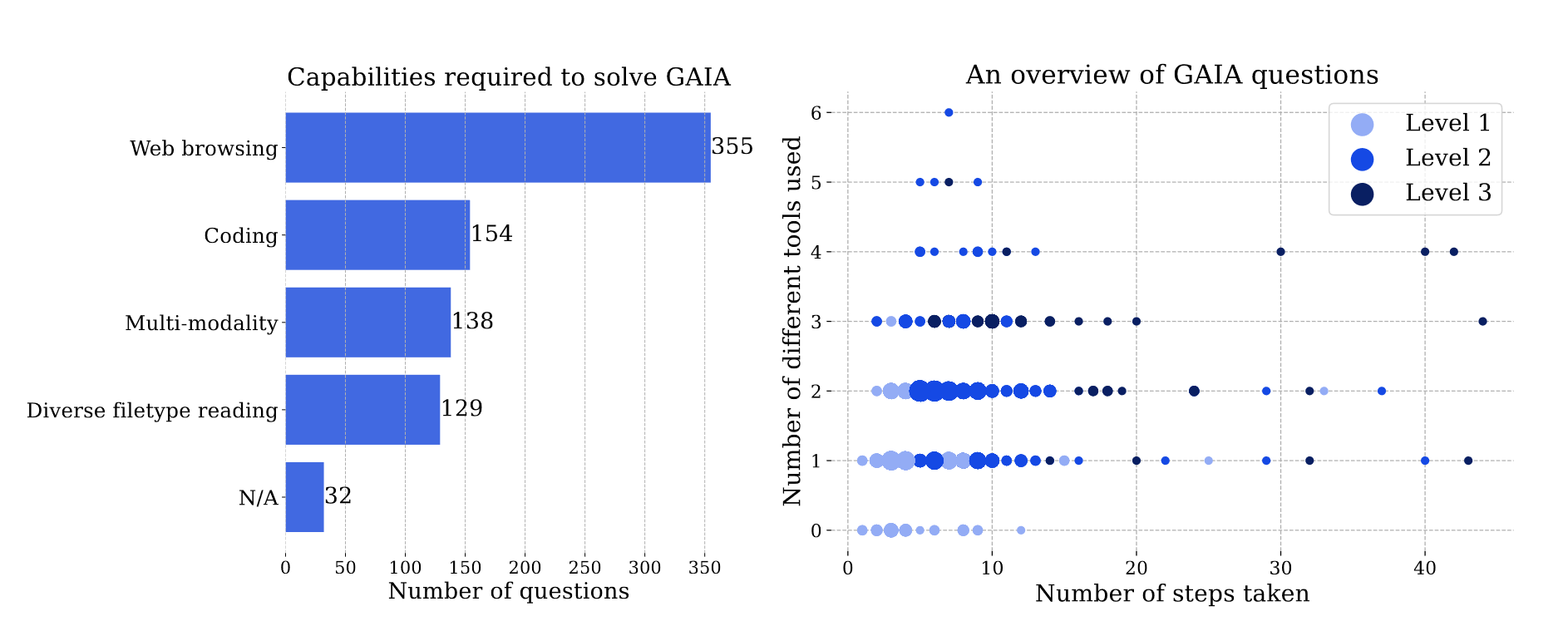
在GAIA上获得分数需要先进的推理、多模态的理解、编码能力以及一般工具的使用,比如网页浏览。尽管网页浏览是GAIA的关键部分,但是作者不需要这些智能体执行点击以外的操作,比如上传文件,发表评论等,这些考虑留给未来的工作。
所有的问题可以根据所需的步骤和回答问题所需的工具数量分类为难度递增的三个等级。上图展示了不同类型问题的分布情况,每个工具总是和一个或者多个能力相关。三个等级粗略的定义如下:
- Level 1。问题生成无需工具,或者至多一个工具,不超过5步。
- Level 2。问题包含更多步骤(5-10),需要借助不同的工具。
- Level 3。需要接近完美的助手才能解决,采取可能任意长度的步骤,使用任意数量的工具,并且接入真实世界。

不同等级的示例如上图所示,当然上面的定义并不绝对,有时候不到10步需要复杂互联网检索的任务也会被分到等级3。所有的任务尽可能涵盖各种主题领域和文化。
3.4 Building and extending GAIA
所有的数据都是人工创建的,旨在反映AI助手的实际用例。作者设计了初始的问题,并将它们作为范例提供给标注者以创建更多的问题。这些问题基于一个或多个事实来源,并且通常避免了歧义。当一个问题创建时,还需要标注问题的答案和元数据:需要多少工具,采取哪些步骤,需要多久回答等。一个典型的注释问题如下: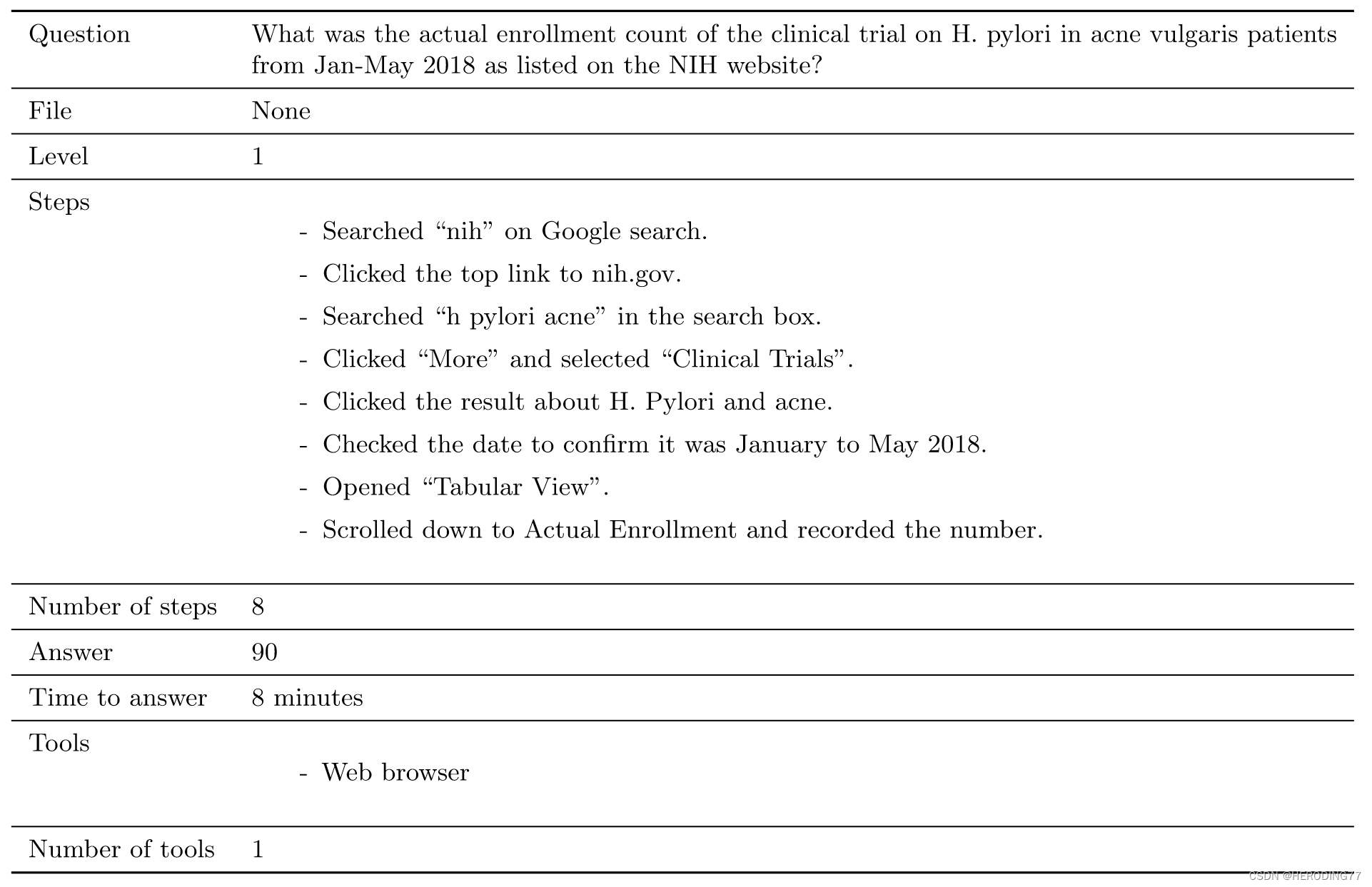
GAIA的验证集请了两个新的注释者独立回答,回答的准确度达到了92%,如下表所示,这表明GAIA对于人类来说是简单的。
当事实来源托管在网络时,涉及的问题可能会出现问题。首先该事实可能会随着时间而改变,因此指定事实的版本日期很重要。其次部分网站对内容的访问有所限制,本文的问题确保问题托管在互联网上不受限制。
4 LLMs results on GAIA
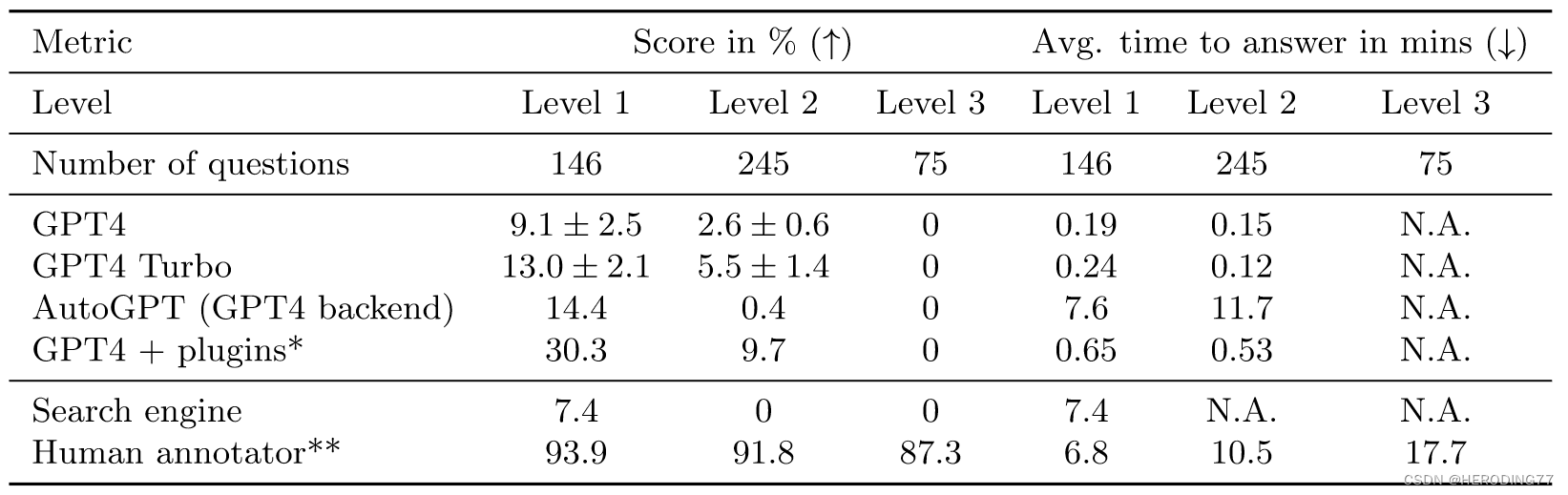
通过GAIA来测试LLMs的能力只需要对模型进行提示。作者在图2中展示了预先定义好的prompt。作者对GPT4、GPT4-Turbo、GPT4带插件、AutoGPT以GPT4为backend的四款模型进行了测试,baseline是人类的标注和网页搜索。
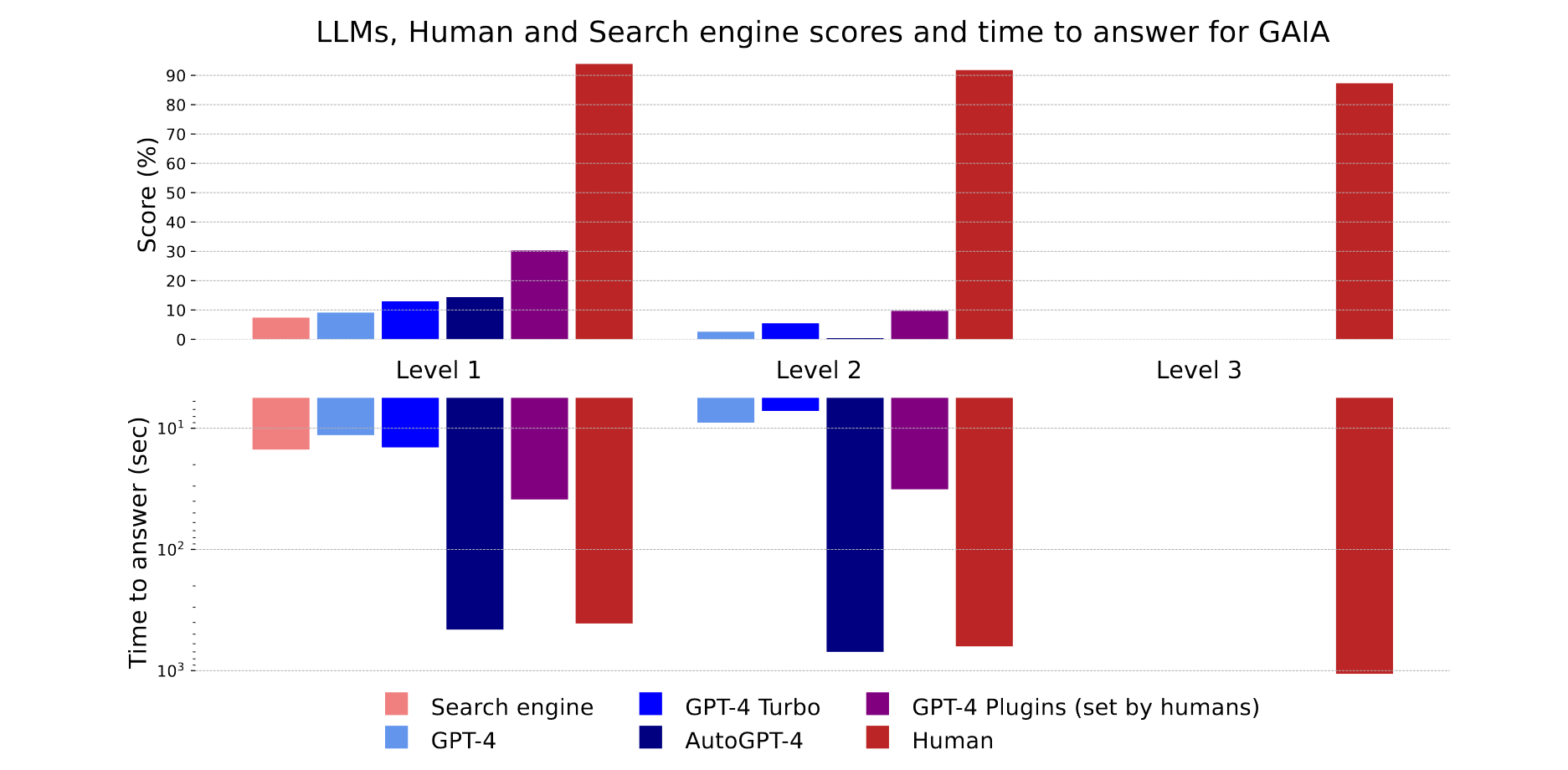
结果如上图所示,更多的内容见上表。本文提出的不同难度级别和模型的表现相关,证明其有效性。人类在三种任务上都表现出色,而LLMs却表现不佳。总的来说,GAIA可以对有能力的LLM进行清晰的排名。从时间上来看,人类的耗时要比LLM慢得多,这证实了LLM智能体作为Agent竞争对手的潜力。
没有插件的GPT4和其他结果的差异表明,通过工具API增强LLM可以提高答案的准确性,证明该方向的研究具有巨大潜力。
AutoGPT的结果令人失望, 这种落差可能来自于对GPT4 API的依赖,在之后要重新评估。总的来说,人类和带有插件的GPT4之间的协作似乎提供了迄今为止最佳的分数和所需时间的比率。
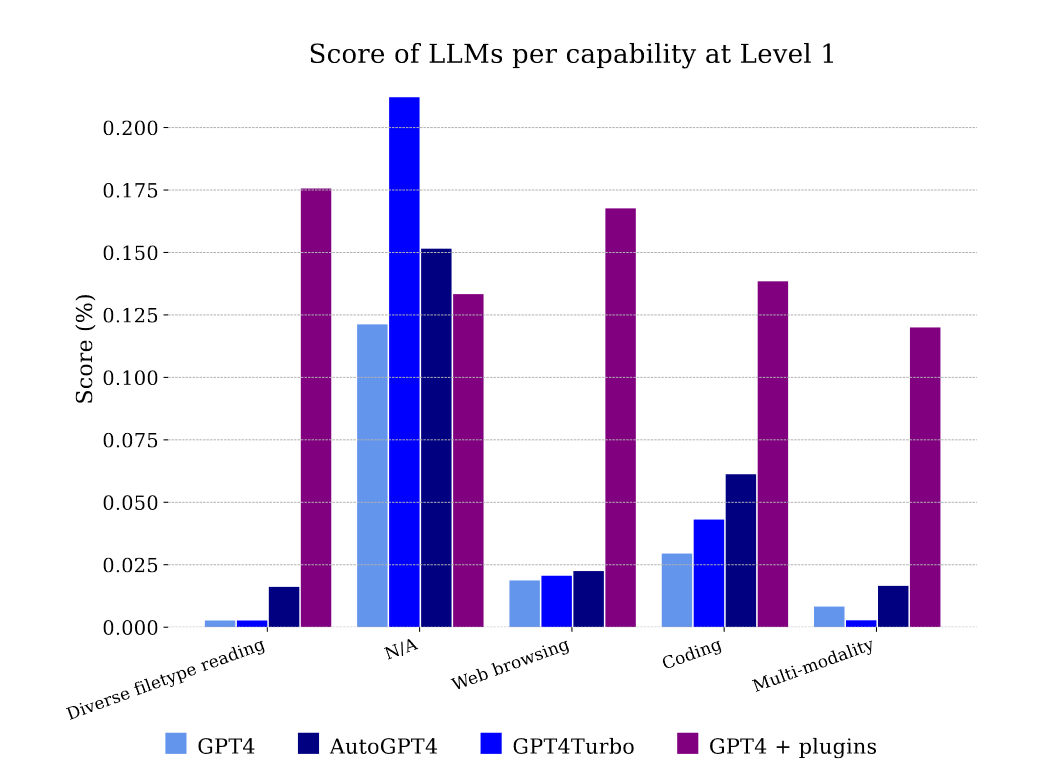
上图显示了在水平1下,LLMs在不同能力任务上的表现,GPT4无法处理文件和多模态任务,但可以解决网页浏览的问题,主要是因为它记住了答案的信息片段。
5 Discussion
通过对GAIA的设计,引导我们去思考当前和未来的AI模型评估的范式。有如下值得讨论的问题:
- 闭源模型的可重复性。闭源模型会定期更改,或者某些插件不可用。
- 静态基准和动态基准。问题质量很关键,此外,需要采取一定的措施缓解GAIA被污染。
- 走向生成模型的统一评估。未来的模型可能会倾向于与其他能力集成,即多模态模型,而不是继续调用外部工具。在未来,多模态模型与GAIA的结合会进一步改善生成模型的评估。
- 部分自动化与完全自动化。完全自动化是深度学习一直努力实现的目标,这将会重塑社会经济格局。
6 Limitations
GAIA现如今还存在如下的限制:
- 缺少评价。不同的路径可能会导致正确的答案,但是没有简单方法可以直接评估这些答案。
- 设计问题的成本较高。作者系统AI系统与人类的偏好一致,因此问题的多样性和是否有根据至关重要。实际中,用户会提出一个不明确的问题,有用的助手会通过通过引用或者保留最值得信赖的来源来回答,二者都很难评估。
- 缺乏语言和文化的多样性。GAIA的任务都是以英文提出。希望在未来能够填补这一空白。
7 Acknowledgements
略。
阅读总结
一篇很新的关于LLMs评测的benchmark工作,对于当前火热的智能体领域带来了久违的氮泵。在GAIA之前,很多Agent的工作虽然都很出色,但是在实验部分常常受到诟病,因为没有一个领域的数据集,很多工作只能构建新的数据集进行微调,有时候甚至偏离了工作本身,或者自己构建一个新的领域数据集,但往往缺乏有效的对比,只能自娱自乐。因此GAIA这一benchmark的出现如同给基于LLM的Agent领域带来了久违的甘露,许多用于规划来解决实际问题Agent工作都可以通过这一数据集进行测评。GAIA的出现也是当前研究人员思想的一个转变,与其让模型不断去卷相对于人类来说特别困难的任务,不如让模型来像人一样解决现实中的问题,这样的工作落地下来才能为更多人所用。当前的GAIA还是颇具有难度的,如果不是多模态模型很难解决一些看似很简单的任务,随着多模态模型的发展,相信这个benchmark会大有用处。