什么是语义搜索?
语义搜索是一种使用自然语言处理算法来理解单词和短语的含义和上下文以提供更准确的搜索结果的搜索技术。 这种方法基于这样的想法:搜索引擎不仅应该匹配查询中的关键字,还应该尝试理解用户搜索的意图以及所使用的单词之间的关系。
语义搜索旨在超越传统的基于关键字的搜索算法,通过使用实体识别、概念匹配和语义分析等技术来识别单词、短语和概念之间的关系。 它还考虑同义词、相关术语和上下文,以提供更相关的搜索结果。
总体而言,语义搜索旨在提供更精确、更有意义的搜索结果,更好地反映用户的意图,而不仅仅是匹配关键字。 这使得它对于复杂的查询特别有用,例如与科学研究、医疗信息或法律文档相关的查询。
语义搜索的历史
语义搜索的概念可以追溯到计算机科学的早期,在 20 世纪 50 年代和 1960 年代就有人尝试开发自然语言处理系统。 然而,直到 20 世纪 90 年代和 2000 年代,语义搜索领域才取得了重大进展,这在一定程度上要归功于机器学习和人工智能的进步。
语义搜索最早的例子之一是 Douglas Lenat 在 1984 年创建的 Cyc 项目。 该项目旨在建立一个全面的常识知识本体或知识库,可用于理解自然语言查询。 虽然Cyc项目面临诸多挑战,最终没有实现其目标,但它为未来语义搜索的研究奠定了基础。
20 世纪 90 年代末,Ask Jeeves(现称为 Ask.com)等搜索引擎开始尝试自然语言查询和语义搜索技术。 这些早期的努力受到当时技术的限制,但它们展示了更复杂的搜索算法的潜力。
2000 年代初 Web 本体语言 (OWL) 的发展提供了一种以机器可读格式表示知识和关系的标准化方法,使得开发语义搜索算法变得更加容易。 2008 年被微软收购的 Powerset 和 2007 年推出的 Hakia 等公司开始使用语义搜索技术来提供更相关的搜索结果。
如今,许多搜索引擎和公司正在使用语义搜索来提高搜索结果的准确性和相关性。 其中包括于 2012 年推出知识图谱的谷歌,以及使用语义搜索为其 Alexa 虚拟助手提供支持的亚马逊。 随着人工智能领域的不断发展,语义搜索可能会变得更加复杂且适用于广泛的应用。
语义搜索的最新改进
语义搜索最近出现了一些改进,有助于进一步推动该领域的发展。 一些最值得注意的包括:
- 基于 Transformer 的模型:基于 Transformer 的模型,例如 BERT(来自 Transformers 的双向编码器表示),彻底改变了自然语言处理和语义搜索。 这些模型能够更好地理解单词和短语的上下文,从而更容易提供更相关的搜索结果。
- 多模态搜索:多模态搜索是指跨文本、图像、视频等多种模式搜索信息的能力。 机器学习的最新进展使得开发更准确、更复杂的多模态搜索算法成为可能。
- 对话式搜索:对话式搜索涉及使用自然语言处理和机器学习来为用户查询提供更准确、更人性化的响应。 这项技术已经被用于虚拟助手,例如亚马逊的 Alexa 和苹果的 Siri。
- 个性化:个性化是指根据用户的偏好和之前的搜索历史来定制搜索结果的能力。 随着在线可用数据量的不断增长,这一点变得越来越重要。
- 特定领域搜索:特定领域搜索涉及使用语义搜索技术在特定领域或行业(例如医疗保健或金融)内进行搜索。 这有助于为这些行业的用户提供更准确、更相关的搜索结果。
总体而言,语义搜索的最新进展使得在线查找信息变得更加容易,并为未来更复杂的搜索算法铺平了道路。
语义搜索和知识图谱有什么关系?
语义搜索和知识图(knowledge graph)密切相关,因为两者都涉及使用语义技术来改进搜索结果。
知识图是一种结构化的信息数据库,它使用语义技术以机器可读的格式表示知识。 它通常由实体(例如人、地点和事物)以及它们之间的关系组成。 例如,知识图可能包含有关特定公司的信息,包括其位置、产品和员工以及这些实体之间的关系。
另一方面,语义搜索是一种使用自然语言处理和机器学习来更好地理解搜索查询中单词和短语的含义的搜索技术。 语义搜索算法使用知识图和其他语义技术来分析实体和概念之间的关系,并基于此分析提供更相关的搜索结果。
换句话说,知识图为语义搜索算法提供了底层结构和数据。 通过利用知识图提供的关系和上下文,语义搜索算法能够提供更准确、更有意义的搜索结果,更好地匹配用户的意图。
例如,谷歌的知识图使用庞大的结构化数据数据库来支持其搜索结果,并提供有关搜索结果中出现的实体(例如人物、地点和事物)的附加信息。 这使得用户更容易找到他们正在寻找的信息并探索相关的概念和实体。
矢量数据库、知识图谱和语义搜索
矢量数据库是另一种可以与语义搜索和知识图结合使用以改进搜索结果的技术。
矢量数据库使用机器学习算法将数据表示为矢量,矢量是数据的数学表示,可用于各种计算任务,例如相似性搜索、聚类和分类。 这些矢量可用于以允许更准确和高效处理的方式表示实体、概念和其他类型的数据。
在语义搜索和知识图的背景下,矢量数据库可以通过更好地理解实体和概念之间的关系来提高搜索结果的准确性。 例如,矢量可用于表示人、地点和事物等实体以及它们之间的关系。 通过比较这些矢量,搜索算法可以识别数据本身可能无法立即显现的关系和模式。
例如,当用户搜索 “Paris” 时,语义搜索算法可以使用知识图和矢量数据库来了解用户可能指的是法国巴黎市,而不是其他同名实体。 通过使用矢量数据库来表示和比较实体和概念,搜索算法可以提供更相关和更准确的搜索结果。
总体而言,矢量数据库、语义搜索和知识图谱都是共同提高搜索算法的准确性和效率的技术。 通过利用这些技术,搜索引擎和其他应用程序可以更好地理解实体和概念之间的关系,从而更轻松地找到用户正在寻找的信息。
如何对自己的私有数据进行语义搜索
在我之前的文章 “ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据(一)”,我详细描述了目前我们的 LLMs (Large Language Models)虽然能够实现语义搜索,但是由于它的局限性,不能针对私有数据进行语义搜索,因为私有数据对 LLMs 不可见。此外,由于 LLMs 的每次训练需要非常多的费用,它不能及时地针对新的数据进行训练,这也使得它的使用具有一定的局限性。正如我之前的文章中介绍的那样,我们可以使用 Elasticsearch 结合 LLMs 来共同完成语义搜索:
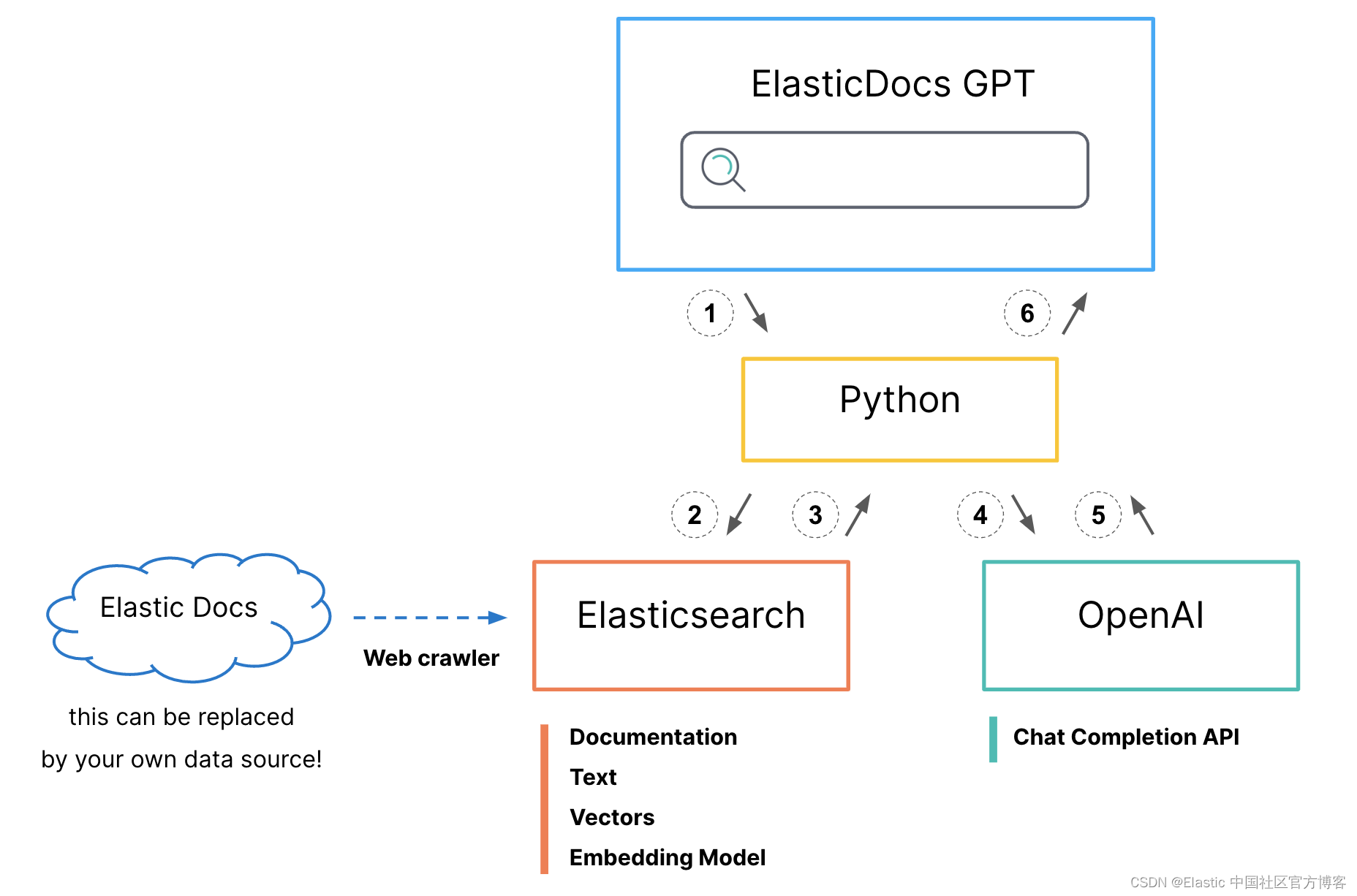
有关这个展示的详细步骤,请参阅文章 “ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据(二)”。
针对语义搜索,除了上面的方案之外,Elastic 也提供一个叫做 Elasticsearch Relevance Engine™ 的发布。我们可以使用 Elastic 的开箱即用的 Learned Sparse Encoder 模型实现基于 ML 的搜索,无需训练或维护模型,可在各种领域提供高度相关、语义化的搜索。详细阅读,请参考:
- Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR
-
Elasticsearch:使用 ELSER 进行语义搜索
如果你想了解更多关于 NLP,语义搜索方面的知识,请参阅 “Elastic:开发者上手指南” 中的 “NLP - 自然语言处理及矢量搜索” 章节。