目录
知识点
lsblk
grep
awk
tail
du
df
对新增存储设备的检测与分区
用lsblk查询块设备
用dmesg看内核打印信息
用ls查看新增设备
对rootfs空间使用情况的监控
知识点
首先想要用shell脚本解决一些问题肯定要熟悉linux的命令
lsblk
- -t或–tree:以树形结构展示设备的层次关系。
- -m或–list:显示挂载点的信息。
- -o或–output:指定要显示的列和顺序,例如-o NAME,SIZE,TYPE只显示名称、大小和类型。
- -a或–all:显示所有设备,包括空设备。
- -p或–paths:显示设备的完整路径。
grep
要用好grep这个工具,其实就是要写好正则表达式,所以这里不对grep的所有功能进行实例讲解,只列几个例子,讲解一个正则表达式的写法。
| 1 |
|
通过管道过滤ls -l输出的内容,只显示以a开头的行。
| 1 |
|
显示所有以d开头的文件中包含test的行。
| 1 |
|
显示在aa,bb,cc文件中匹配test的行。
| 1 |
|
显示所有包含每个字符串有5个连续小写字符的字符串的行。
| 1 |
|
如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着另外一个es(\1),找到就显示该行。如果用egrep或grep -E,就不用"\"号进行转义,直接写成'w(es)t.*\1'就可以了。
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 --count : 计算符合样式的列数。
- -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
- -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 --fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 --basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 --ignore-case : 忽略字符大小写的差别。
- -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -o 或 --only-matching : 只显示匹配PATTERN 部分。
- -q 或 --quiet或--silent : 不显示任何信息。
- -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
- -s 或 --no-messages : 不显示错误信息。
- -v 或 --invert-match : 显示不包含匹配文本的所有行。
- -V 或 --version : 显示版本信息。
- -w 或 --word-regexp : 只显示全字符合的列。
- -x --line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定"-i"参数相同。
awk
- -F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 - -v var=value or --asign var=value
赋值一个用户定义变量。 - -f scripfile or --file scriptfile
从脚本文件中读取awk命令。 - -mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。 - -W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。 - -W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息。 - -W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明。 - -W lint or --lint
打印不能向传统unix平台移植的结构的警告。 - -W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告。 - -W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。 - -W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 - -W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用。 - -W version or --version
打印bug报告信息的版本。
tail
- -f 循环读取
- -q 不显示处理信息
- -v 显示详细的处理信息
- -c<数目> 显示的字节数
- -n<行数> 显示文件的尾部 n 行内容
- --pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
- -q, --quiet, --silent 从不输出给出文件名的首部
- -s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
du
- -a或-all 显示目录中个别文件的大小。
- -b或-bytes 显示目录或文件大小时,以byte为单位。
- -c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
- -D或--dereference-args 显示指定符号连接的源文件大小。
- -h或--human-readable 以K,M,G为单位,提高信息的可读性。
- -H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。
- -k或--kilobytes 以1024 bytes为单位。
- -l或--count-links 重复计算硬件连接的文件。
- -L<符号连接>或--dereference<符号连接> 显示选项中所指定符号连接的源文件大小。
- -m或--megabytes 以1MB为单位。
- -s或--summarize 仅显示总计。
- -S或--separate-dirs 显示个别目录的大小时,并不含其子目录的大小。
- -x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
- -X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
- --exclude=<目录或文件> 略过指定的目录或文件。
- --max-depth=<目录层数> 超过指定层数的目录后,予以忽略。
- --help 显示帮助。
- --version 显示版本信息。
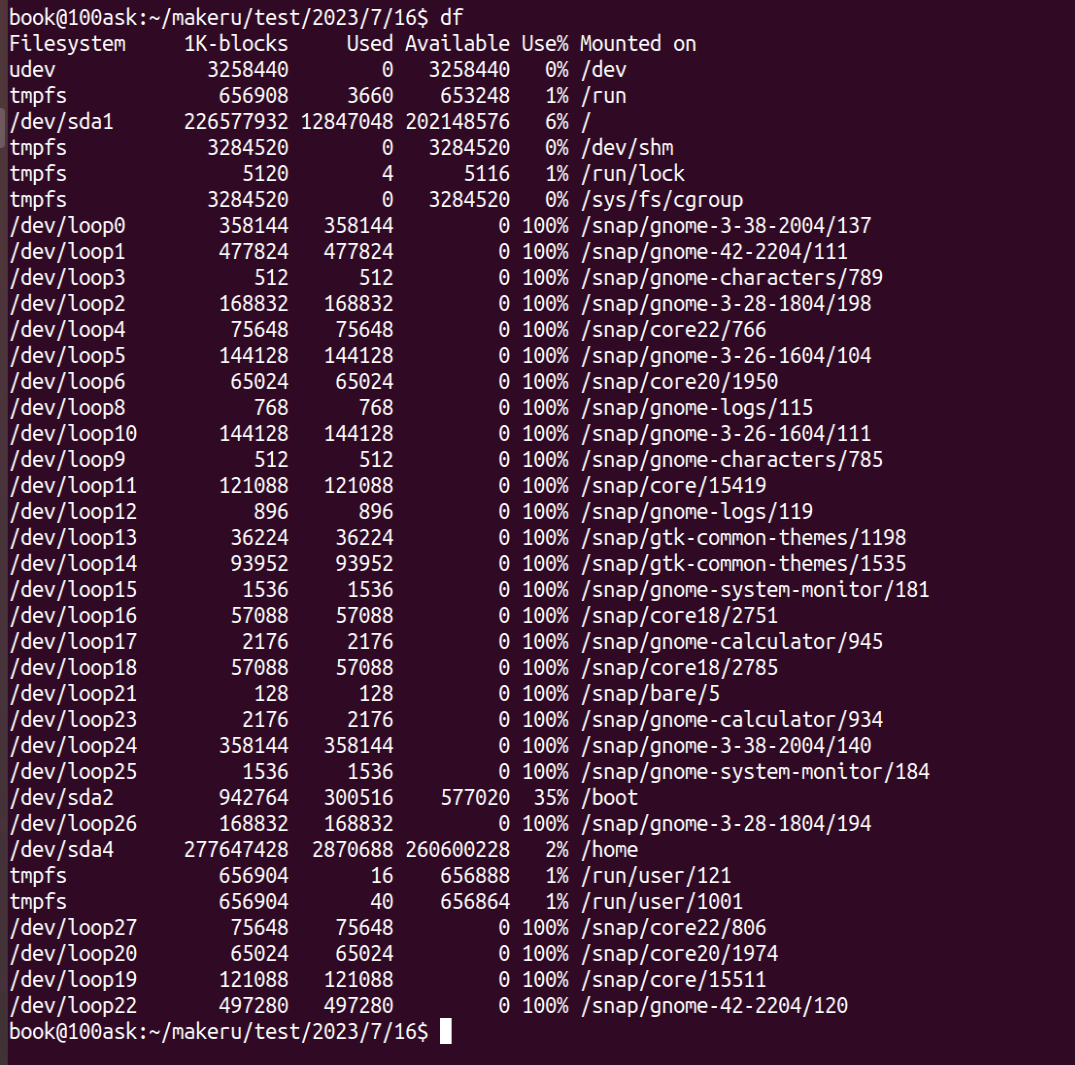
df
- 文件-a, --all 包含所有的具有 0 Blocks 的文件系统
- 文件--block-size={SIZE} 使用 {SIZE} 大小的 Blocks
- 文件-h, --human-readable 使用人类可读的格式(预设值是不加这个选项的...)
- 文件-H, --si 很像 -h, 但是用 1000 为单位而不是用 1024
- 文件-i, --inodes 列出 inode 资讯,不列出已使用 block
- 文件-k, --kilobytes 就像是 --block-size=1024
- 文件-l, --local 限制列出的文件结构
- 文件-m, --megabytes 就像 --block-size=1048576
- 文件--no-sync 取得资讯前不 sync (预设值)
- 文件-P, --portability 使用 POSIX 输出格式
- 文件--sync 在取得资讯前 sync
- 文件-t, --type=TYPE 限制列出文件系统的 TYPE
- 文件-T, --print-type 显示文件系统的形式
- 文件-x, --exclude-type=TYPE 限制列出文件系统不要显示 TYPE
- 文件-v (忽略)
- 文件--help 显示这个帮手并且离开
- 文件--version 输出版本资讯并且离开
对新增存储设备的检测与分区
检查新增块设备我想到了三个命令
用lsblk查询块设备
lsblk -o name,type,mountpoint | grep -i "disk" | grep -v "nvme" | grep -v "lvm" | awk '{print $1}' | tail -n 1lsblk的输出
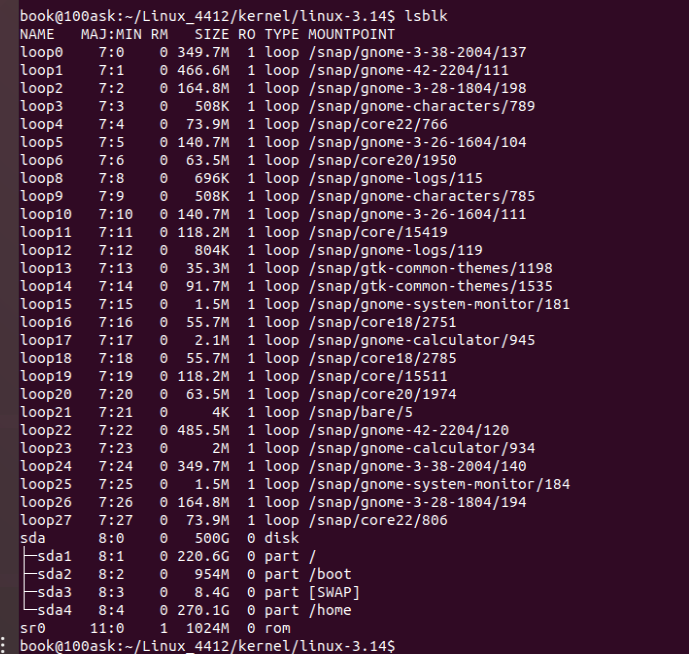
NAME:就是装置的文件名啰!会省略 /dev 等前导目录!
MAJ:MIN:其实核心认识的装置都是透过这两个代码来熟悉的!分别是主要:次要装置代码!
RM:是否为可卸除装置 (removable device),如光盘、USB 磁盘等
SIZE:当然就是容量啰!
RO:是否为只读装置的意思
TYPE:是磁盘 (disk)、分区槽 (partition) 还是只读存储器 (rom) 等输出
MOUTPOINT:就是前一章谈到的挂载点
我们查找了这三列元素并输出第一列的最后一个

用dmesg看内核打印信息
dmesg | grep -ioE "sd[a-z]+|mmcblk[0-9]+" | tail -n 1忽略大小写以正则表达式的样式来查找内核打印信息中sd开头和mmcblk开头的设备并取最后一个
服务器上新插入的块设备是sd开头的除非是自带驱动的设备,而单板上开发插入块设备是mmcblk开头的

用ls查看新增设备
ls -lf /dev/sd* /dev/mmcblk* 2>/dev/null | awk -F '[/ ]' '{devices[NR]=$NF} END {print devices[NR-4]}'ls我没介绍这个太简单了经常用相信没人不会因为ls会连带分区一起显示出来,我当时的设备正好四个分区就显示倒数第五个数了,这个命令最不靠谱,dmesg那个也容易显示错误,因为可能有哪个程序使用了分区有时候也会在dmesg中打印出来就是可能会查错。第一个lsblk其实也不完善,因为插入的设备如果是第二次插入那检查到的就不是这个设备了,因为这个排序不少按照时间来的,是按照设备号,比如有sda sdb 两个设备,拔掉sda在插入这个命令找到的还是sdb
希望以后可以完善一下,暂时是为了单板启动初始化存储设备用的不存在二次插拔现象。
#检查平台
check_platform()
{if [ `uname -r` == "4.19.0" ]; thenecho "The platform is ARM"#由于arm平台设备分区名称自动以p1~pn为自增后缀,故此进行重命名partition_name=$dev_name"p"#是否为arm平台platform=1elseecho "The platform is X86"partition_name=$dev_name#平台为x86platform=0fi
}又写了个检测平台是ARM还是x86的函数
对rootfs空间使用情况的监控
#!/bin/bash# 存储初始rootfs的内容
INITIAL_CONTENTS="initial_contents.txt"# 存储当前rootfs的内容
CURRENT_CONTENTS="current_contents.txt"# 存储初始磁盘使用情况
INITIAL_DISK_USAGE="initial_disk_usage.txt"# 存储当前磁盘使用情况
CURRENT_DISK_USAGE="current_disk_usage.txt"# 检查初始rootfs内容文件是否存在
if [[ ! -f $INITIAL_CONTENTS ]]; then# 如果不存在,创建并保存初始rootfs的内容du -h -d 1 / > $INITIAL_CONTENTSdf -h / | tail -n 1 > $INITIAL_DISK_USAGEecho "保存初始rootfs内容和磁盘使用情况"
else# 如果存在,将当前rootfs的内容与初始内容进行对比du -h -d 1 / > $CURRENT_CONTENTSdf -h / | tail -n 1 > $CURRENT_DISK_USAGEecho "与初始rootfs内容进行对比"# 提取初始磁盘使用率和当前磁盘使用率initial_usage=$(awk '{print $5}' $INITIAL_DISK_USAGE)current_usage=$(awk '{print $5}' $CURRENT_DISK_USAGE)# 提取初始rootfs总空间、剩余空间和当前rootfs剩余空间total_space=$(awk '{print $2}' $INITIAL_DISK_USAGE)initial_free_space=$(awk '{print $4}' $INITIAL_DISK_USAGE)current_free_space=$(awk '{print $4}' $CURRENT_DISK_USAGE)# 生成初始内容文件、当前内容文件和它们之间的差异表格printf "%-11s | %-7s | %-6s | %-5s |\n" "文件/目录名称" "初始大小" "当前大小" "变化量"printf "*****************************************\n"paste <(cut -f 2 $INITIAL_CONTENTS) <(cut -f 1 $INITIAL_CONTENTS) <(cut -f 1 $CURRENT_CONTENTS) <(paste <(cut -f 1 $INITIAL_CONTENTS) <(cut -f 1 $CURRENT_CONTENTS) | awk '{printf "%.2f\n", ($2-$1)}') | while IFS=$'\t' read -r file initial_size current_size change initial_free current_free initial_usage current_usage; doprintf "%-11s | %-7s | %-6s | %-5sM |\n" "$file" "$initial_size" "$current_size" "$change"doneprintf "*****************************************\n"echo "总空间 $total_space"echo "初始剩余空间 $initial_free_space"echo "当前剩余空间 $current_free_space"echo "初始使用率 $initial_usage"echo "当前使用率 $current_usage"
fi# 每次执行后,删除临时文件
rm $CURRENT_CONTENTS $CURRENT_DISK_USAGE这里主要就是du和df查看然后paste和printf进行打印了比较简单