操作系统:centos7
软件环境:jdk8、hadoop-2.8.5
一、创建虚拟机
1.下载VMware,建议支持正版
2.安装到Widows目录下任意位置即可,安装目录自定义。打开VMware,界面如下:

3.创建虚拟机
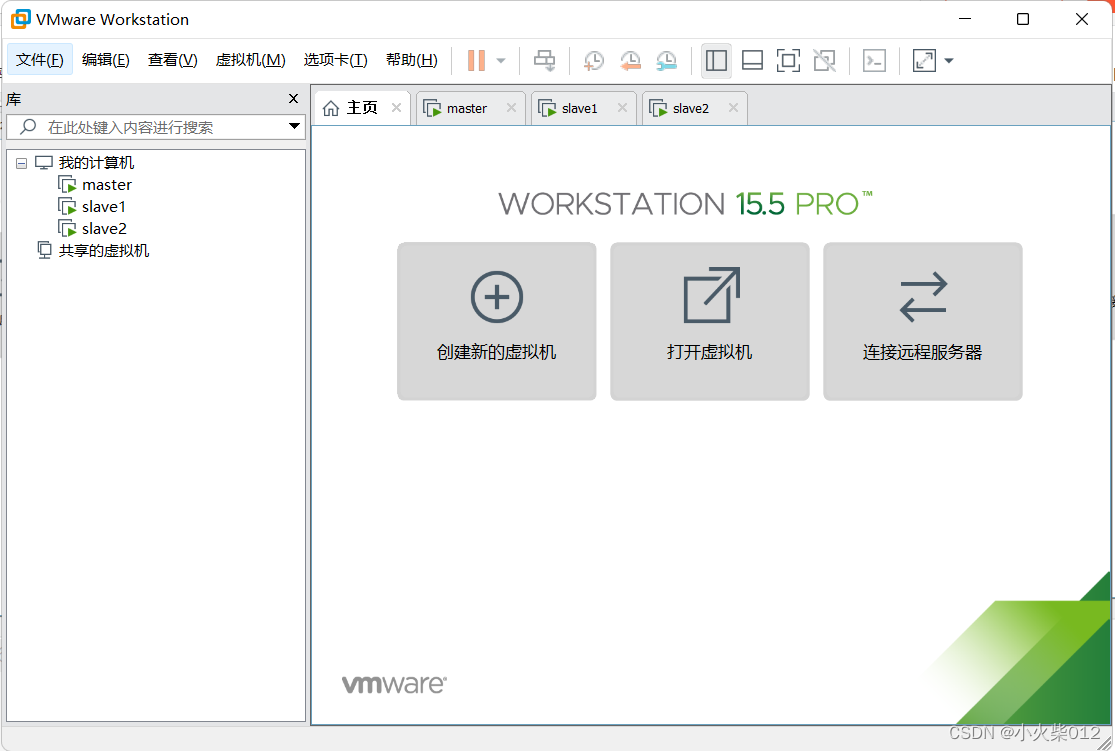
创建虚拟机—>选择自定义
这一步按照默认的配置就好

选择系统,安装程序光盘映像文件iso,这里需要下载cenos镜像文件
 给虚拟机命名,选择虚拟机安装位置
给虚拟机命名,选择虚拟机安装位置
 处理器配置
处理器配置

内存配置

配置虚拟机网络连接方式
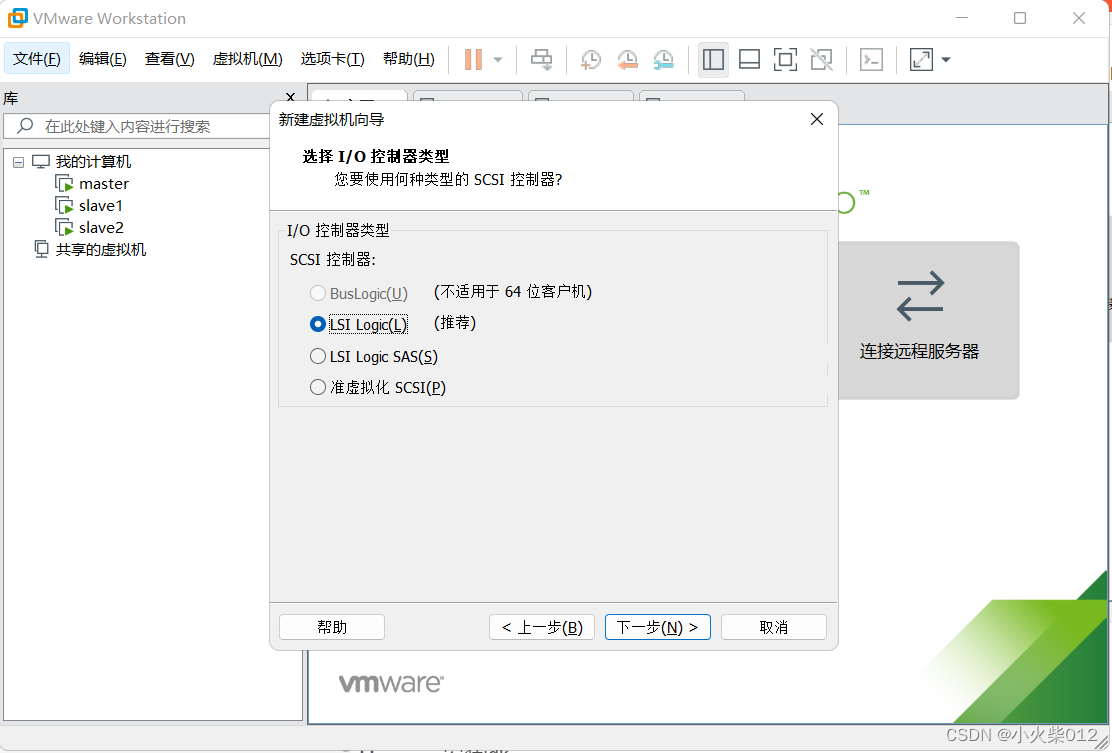
选择I/O控制器
创建磁盘


设置磁盘大小
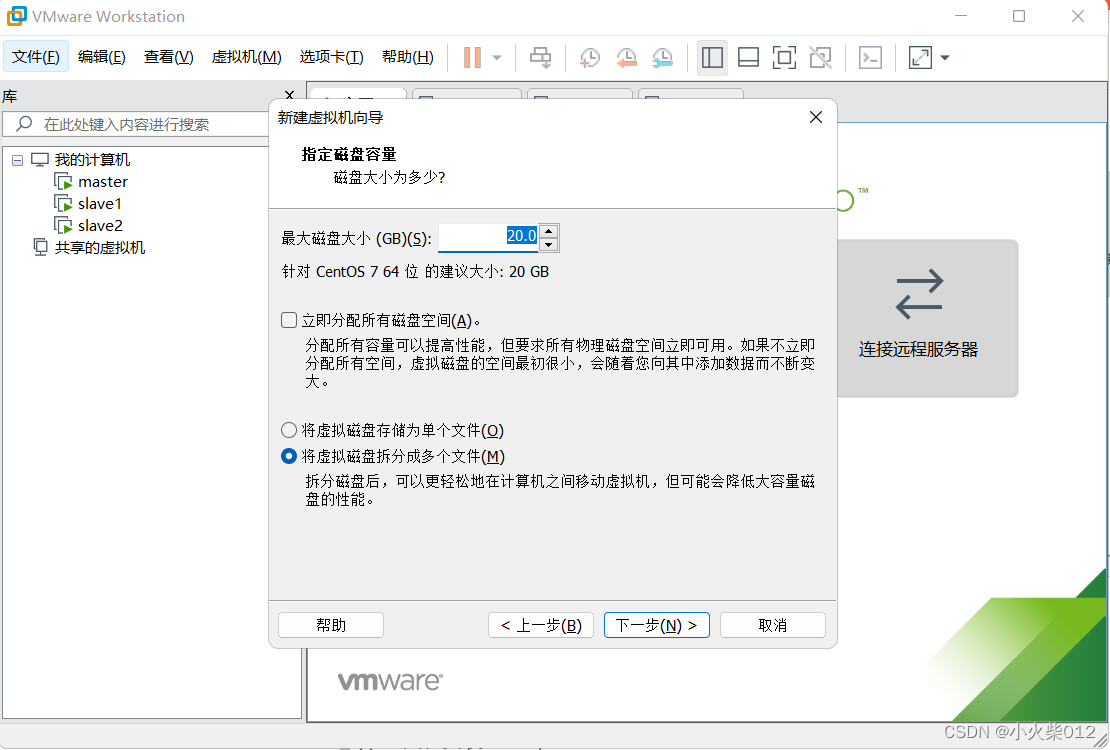
选择虚拟磁盘存放地址
检查虚拟机配置,如果没有什么问题,点击完成
启动虚拟机,鼠标点击虚拟机屏幕,使用键盘上下键移动光标位置,光标在Install CentOS 7处,按下enter键

等待系统进入CentOS安装界面,选择简体中文

设置时区,选择亚洲–上海
 软件选择,GNOME桌面
软件选择,GNOME桌面

选择自动配置分区

点击开始安装
设置root密码
创建用户
等待…安装完成,重启虚拟机
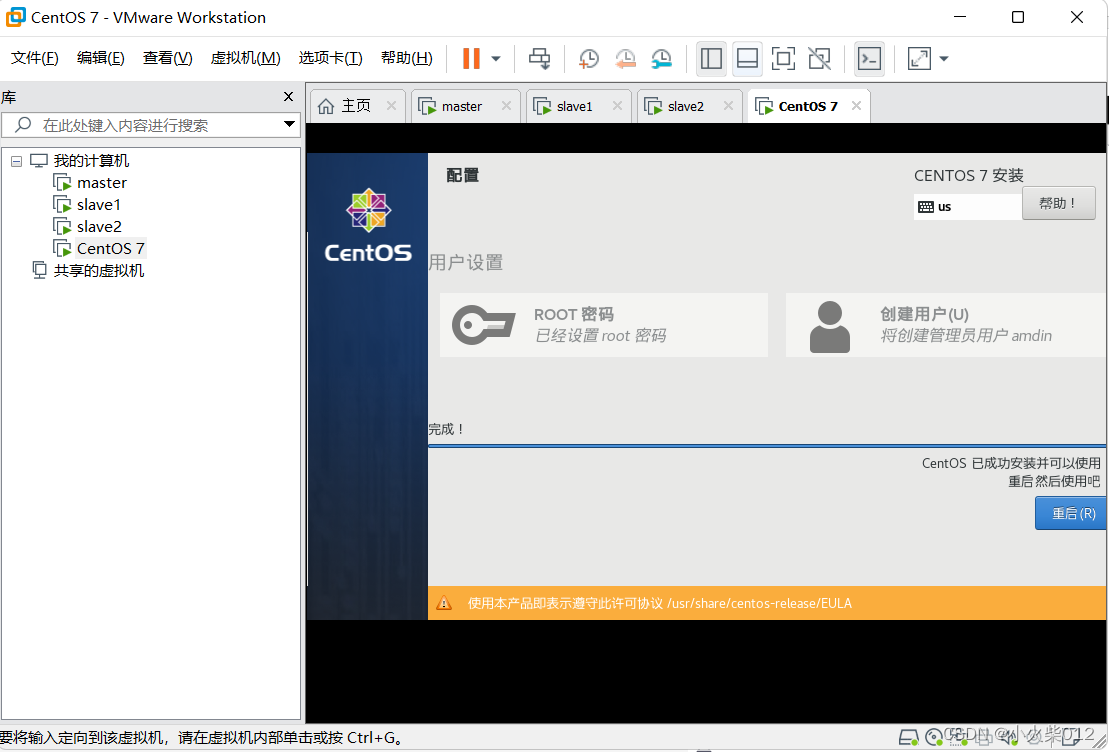
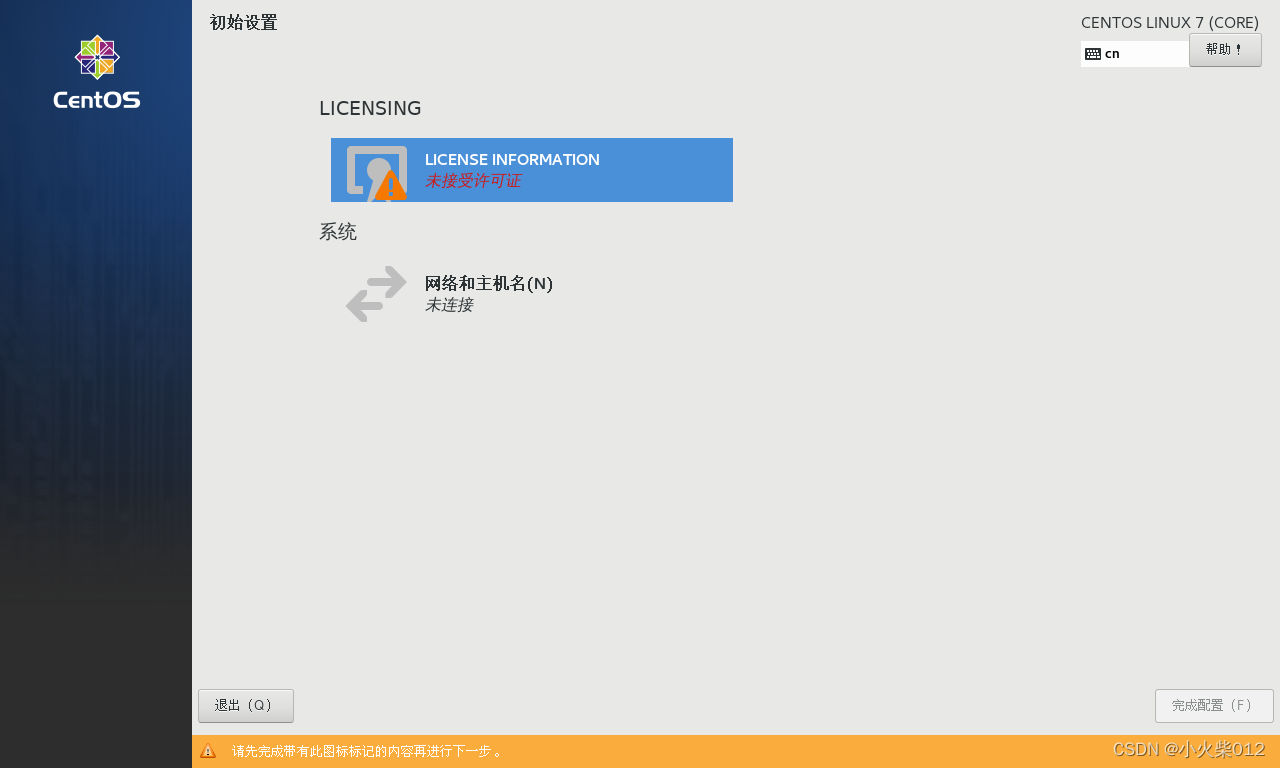
初始设置,完成授权
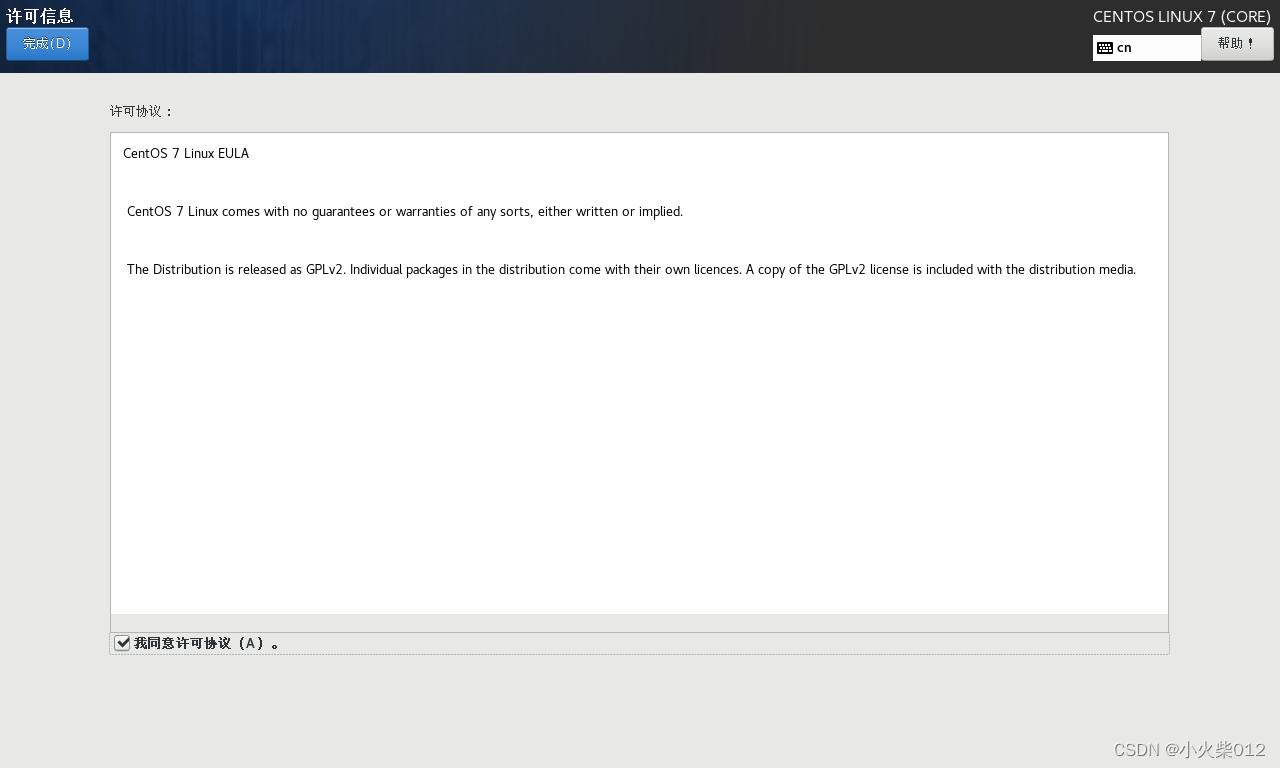
进入centos登录界面

二、配置虚拟机网络
编辑—>虚拟机网络编辑器–>NAT模式–>DHCP设置

查看网络信息

打开终端面板,进入root模式
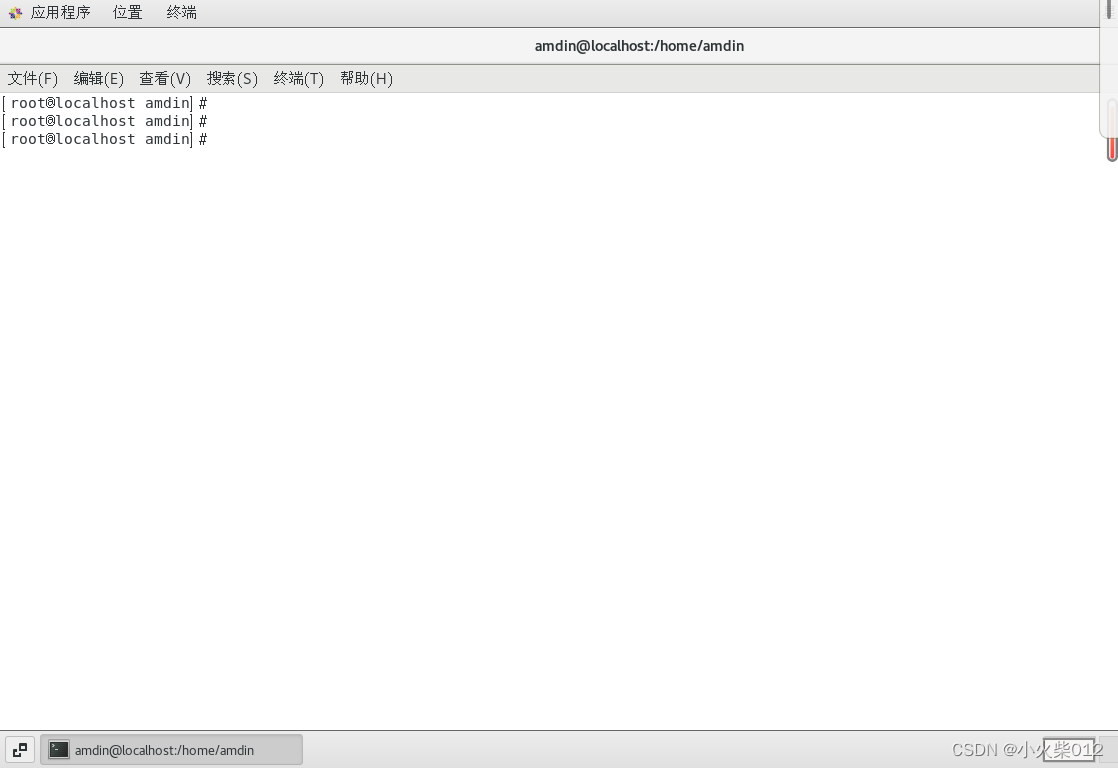
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改网络配置,配置如下:

使用wq命令保存,使用下面命令重启网络服务
service network restart
免密登录配置
修改主机名称
vi /etc/hostname
编辑映射文件hosts
vi /etc/hosts
添加如下配置
192.168.245.200 master
192.168.245.201 slave1
192.168.245.202 slave2
# 生成公钥与私钥(三次回车)
ssh-keygen -t rsa
将~/.ssh/id_rsa.pub 分发到节点服务器的~/.ssh目录下,并重命名为 authorized_keys
for i in {1..2};do scp -r ~/.ssh/authorized_keys root@slave${i}:~/.ssh/;done
这样便可以实现不同节点服务器免密登录
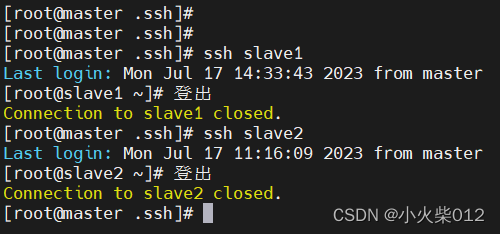
每台服务器都需要配置
三、安装jdk
上传jdk到linux系统,这里使用jdk1.8版本
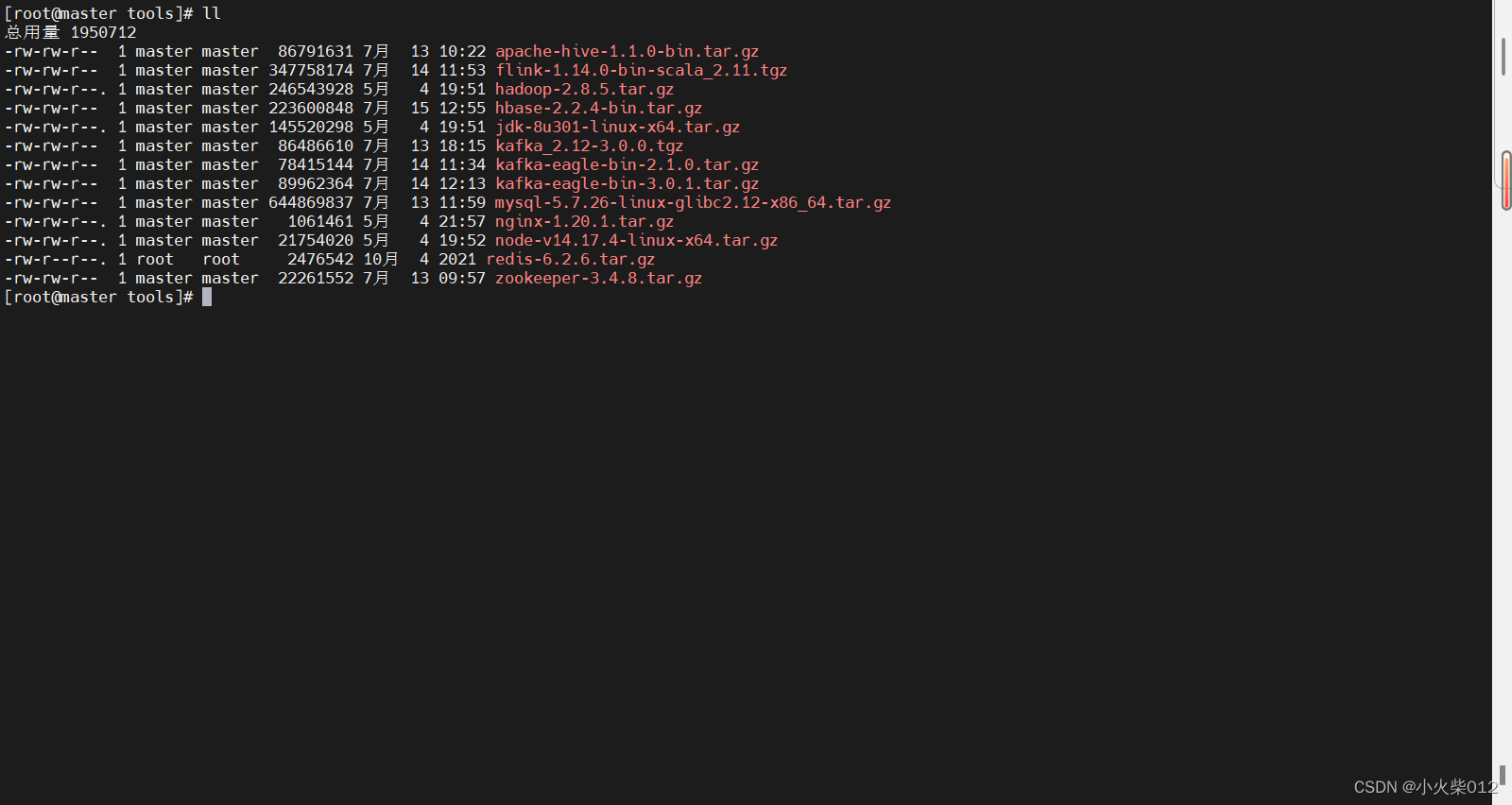
将其解压到指定目录下
tar -zxvf jdk-8u301-linux-x64.tar.gz -C /home/local/
移动至java目录
mv jdk1.8.0_301 java
配置环境
vim /etc/profile
添加如下配置
#java
export JAVA_HOME=/home/local/java
export JRE_HOME=/home/local/java/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
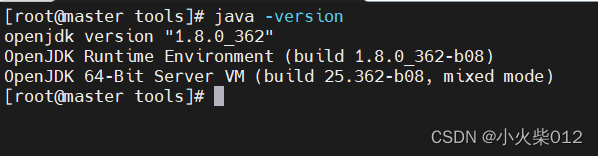
在终端输入java -version,出现下面信息,说明配置成功。
四、安装hadoop
上传hadoop安装包到linux系统,这里使用hadoop2.8.5版本
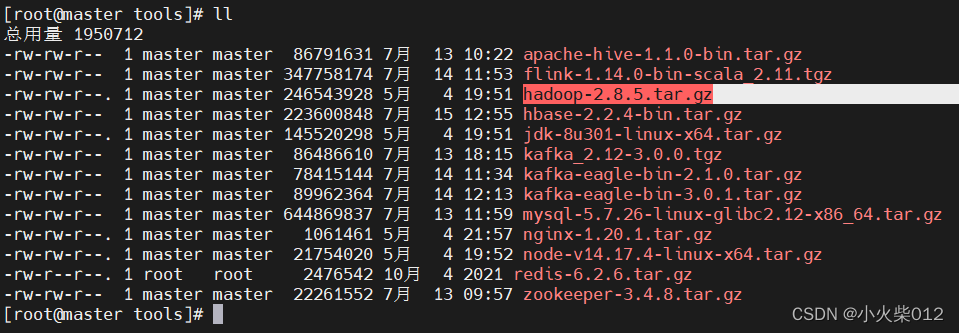
解压安装包
tar -zxvf hadoop-2.8.5.tar.gz -C /home/local/
移动至hadoop目录
mv hadoop-2.8.5/ hadoop
配置hadoop环境
vi /etc/profile
添加如下配置
#hadoop
export HADOOP_HOME=/home/local/hadoop
export PATH=$PATH:${HADOOP_HOME}/bin
使用配置的环境变量立即生效
source /etc/profile
配置 hadoop-env.sh 文件,指定java安装目录
cd $HADOOP_HOME/etc/hadoop
修改hadoop-env.sh文件
vi /hadoop-env.sh
配置如下
export JAVA_HOME=/home/local/java
配置Hadoop主要文件
核心配置文件 —— core-site.xml
HDFS 配置文件 —— hdfs-site.xml
YARN 配置文件 —— yarn-site.xml
MapReduce 配置文件 —— mapred-site.xml
1.core-site.xml
<configuration>
<!-- 指定 NameNode 的地址 --><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property>
<!-- 指定 Hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/hadoop/tmp</value></property>
<!-- 配置 HDFS 网页登录使用的静态用户为 master --><property><name>hadoop.http.staticuser.user</name><value>master</value></property>
</configuration>2.hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.name.dir</name><value>file:/opt/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/opt/hadoop/dfs/data</value></property><property><name>dfs.namenode.http-address</name><value>master:9870</value></property><property><name>dfs.namenode.secondary.http-address</name><value>slave2:9871</value></property>
</configuration>
3.yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties --><!-- 指定 MR 走 shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><!-- 指定 客户端web 的地址--><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- 如果要程序的运行日志信息上传到HDFS系统上,可配置日志聚集(选择配置) --><!-- 开启日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志聚集服务器地址 --><property><name>yarn.log.server.url</name><value>http://master:19888/jobhistory/logs</value></property><!-- 设置日志保留时间为7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
</configuration>
4.mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property>
</configuration>
五、启动hadoop
将hadoop分发到每个节点,每个节点都要进行格式化,进入$HADOOP_HOME/bin目录下
$HADOOP_HOME/bin/hdfs namenode -format
进入$HADOOP_HOME的sbin目录下,分别启动hdfs和yarn
./start-dfs.sh && ./start-yarn.sh
使用jps命令查看进程
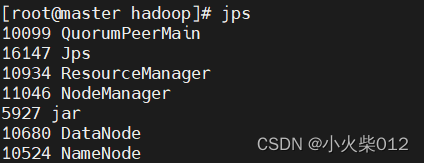
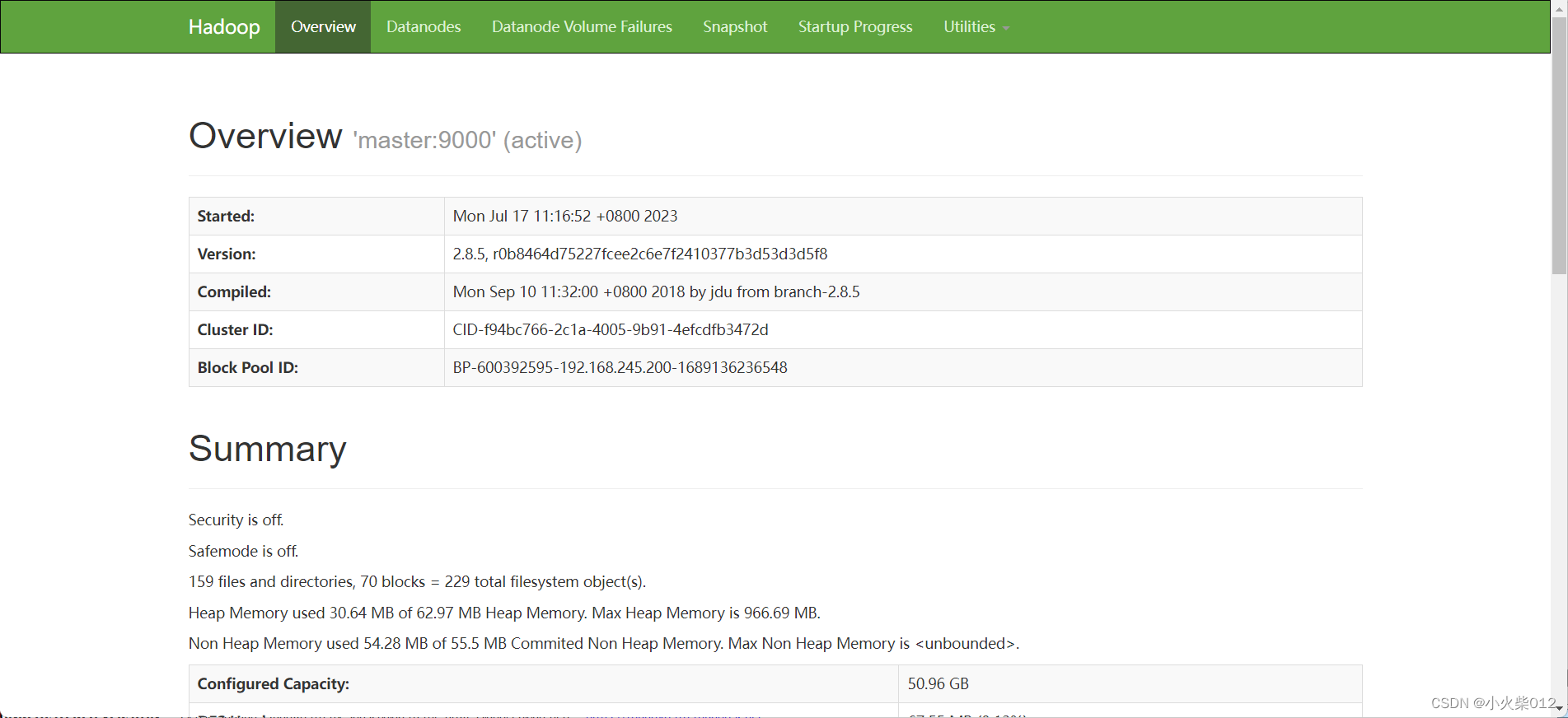
六、访问Web UI界面
客户端Web页面
http://192.168.245.200:8088/cluster/nodes
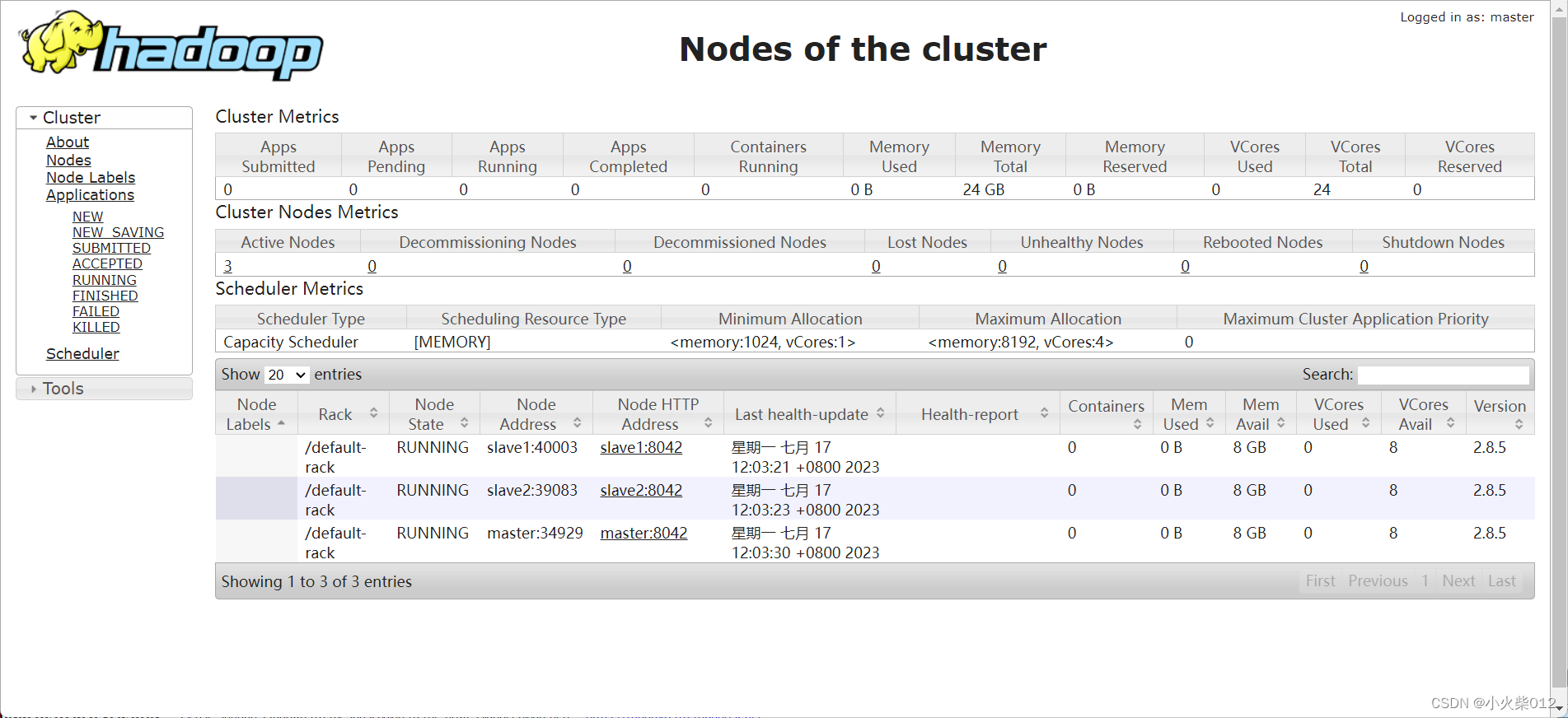
hdfs页面