作者|Krishnadutt Panchagnula
翻译|Seal软件
链接|https://betterprogramming.pub/detecting-identifying-and-managing-terraform-state-drift-997366a74537
在理想的 IaC 世界中,我们所有的基础设施实现和更新都是通过将更新的代码推送到 GitHub 来编写和实现的,这将触发 Jenkins 或 Circle-Ci 中的 CI/CD 流水线,并且这些更改会反映在我们常用的公有云中。但现实并没有这么顺利,原因可能有很多,例如:
-
公司仍处于云自动化的初级阶段;
-
不同团队中的多个利益相关者正在通过控制台开发概念验证;
-
引入临时手动热修复以稳定当前生产;
-
用户并不知道 IaC 工具。
鉴于这些原因,系统中引入了不同类别的漂移,每种类别都有自己的补救措施。本文介绍了 Terraform 漂移、其类别、修复策略以及监测 Terraform 漂移的工具。为了更好地理解这些概念,我们将会带你探究什么是 Terraform 漂移以及在 Terraform 中如何检测这种漂移。
什么是 Terraform 漂移?
当我们使用 Terraform 创建资源(即 terraform apply)时,它会存储有关当前基础设施的信息,本地或远程支持在名为 terraform.tfstate 。随后 terraform apply 将根据基础设施的当前状态进行更新。但是,当我们通过控制台或 CLI 进行手动更改时,这些更改会应用到云环境中,但不会在状态文件中看到。
| Terraform 漂移可以理解为从 Terraform 中定义的基础设施的实际状态与云环境中存在的基础设施状态观察到的漂移/差异。 |
|---|
在上述几种情况下,在 Terraform 代码之外进行基础架构更改都会导致 Terraform 状态文件的状态与云环境的状态截然不同。因此,当我们下次应用 Terraform 代码时,我们会发现 Terraform 漂移,这可能会导致 Terraform 资源更改或销毁。因此,了解不同类型的漂移如何渗透到我们的基础设施中可以帮助我们有效减轻此类风险。
漂移类型
我们可以将 Terraform 配置漂移分为三类:
-
Emergent drift —— 在 Terraform 生态系统之外进行基础设施更改时观察到的漂移,该生态系统最初是通过 Terraform 应用的(因此它们的状态存在于 Terraform 状态文件中)。
-
Pseudo drift —— 由于列表中的订购项目和其他提供商的特性而在计划/应用周期中看到的“变化”。
-
Introduced drift —— 在 Terraform 之外创建的新基础设施。
不过关于引入漂移(Introduced drift)是否应当被考虑进来一直存在争议,因为基础设施完全是通过控制台设置的。但使用 Terraform 是通过代码完全自动化基础设施流程,因此任何包含手动创建的基础设施都被认为是配置漂移。
管理 Emergent Drift
如前所述,当 Terraform 应用和管理的基础设施在 Terraform 生态系统之外进行修改时,会观察到浮现漂移(Emergent Drift)。这时我们可以根据习惯的首选状态进行管理:
-
基础设施状态:如果我们的首选状态是云中的状态,那么可以更改 Terraform 配置图(通常是
main.tf文件)及其依赖模块,以便下次运行时terraform apply配置文件和 Terraform 状态文件同步。
-
配置状态:如果我们的首选状态是配置文件中的状态,我们只需使用配置文件运行
terraform apply即可。这将取消云中的所有更改并应用 Terraform 配置文件中的配置。
管理 Pseudo Drift
当配置文件中某些资源或资源的某些参数的顺序与状态文件中不同时,这就是伪漂移(Pseudo Drift)了。这种漂移并不常见。为了更好地理解这一点,我们以创建多可用区 RDS 为例。
resource "aws_db_instance" "default" {allocated_storage = 10engine = "mysql"engine_version = "5.7"instance_class = "db.t3.micro"availability_zone = ["us-east-1b","us-east-1c","us-east-1a"]# Us-east -1a was added latername = "mydb"username = "foo"password = "foobarbaz"parameter_group_name = "default.mysql5.7"skip_final_snapshot = true
}
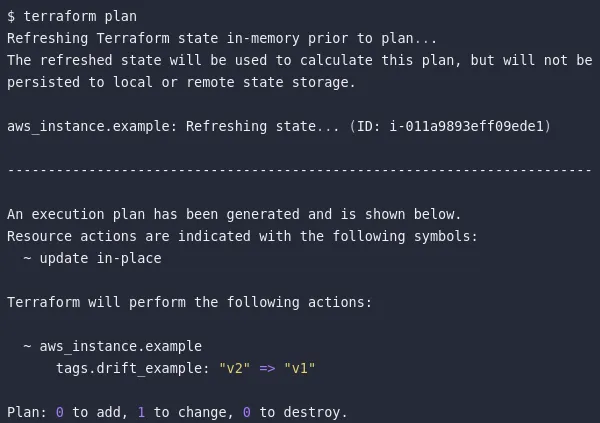
起初我们只需要 east-1b 和 1c,但后来添加了 1a。当我们应用此配置时,它运行成功。作为细心的 SRE 工程师,我们通过运行terraform plan来确认一切都是正常进行的。但惊讶的是,我们可能会看到它通过“availability zone”行的更改再次添加此资源。当我们再次应用此更改时,此更改日志可以在后续生命周期terraform apply中显示。
为了便于管理,我们应该运行terraform show来显示当前的状态文件。找到可用区参数并查看这些参数作为列表传递的顺序,将这些值复制到 Terraform 配置文件中。
管理 Introduced Drift
当在云上的 Terraform 生态系统之外配置新基础设施时,就会出现引入漂移。这是最可怕的漂移类型,由于 Terraform 状态文件中没有跟踪这些变化,因此需要工程师们认真努力地进行检测和处理。引入漂移很难检测,需要通过控制台查看每个资源、读取云监视日志、检查计费控制台或向完成此更改的人询问确认。当我们运行terraform destroy时,某些资源无法销毁,也会发生这种情况。
如果我们可以识别手动配置的资源,则根据其所在的环境有两种方法进行处理:
-
重新配置:如果资源不在生产级环境中,建议销毁该资源,然后在 Terraform 配置文件中为其创建一个模块。这样,基础设施就可以通过 Terraform 状态文件进行记录、跟踪和监控,并且所有资源都是通过 Terraform 创建的。
-
Terraform 导入:如果资源存在于生产级环境中,则很难重新创建它。在本例中,我们使用“terraform import”导入资源。Terraform 导入帮助我们为相关资源创建 Terraform HCL 代码。获得此资源后,我们可以将此代码复制到 Terraform 配置文件中,应用该文件后,将使用与云中存在的状态相同的配置来更新状态文件。
漂移识别和监控
只有当我们能够检测到存在漂移时,才能完成所有这些漂移管理。在浮现漂移和伪漂移的情况下,我们可以使用terraform plan命令来识别它们,该命令会将当前状态文件与云中的资源(之前使用 Terraform 创建)进行比较。但在引入漂移的情况下会失败,因为在 Terraform 生态系统之外创建的资源没有状态。因此,如果我们可以提前检测到这种漂移并通过 IaC 工具实现自动化那就再好不过了。这里我们列出了以下两种工具来提前检测引入漂移。
CloudQuery
如果您喜欢使用以数据为中心的方法和可视化仪表板,那么此解决方案很适合您。CloudQuery 是一个开源工具,它将状态文件与我们所需的云提供商中的资源进行比较,然后格式化该数据并将其加载到 PostgreSQL 数据库中。由于漂移检测命令是在 PostgreSQL 之上创建的,并且具有托管或非托管列,因此我们可以使用此标志作为筛选器,在我们最喜欢的仪表板解决方案(例如 Tableau 或 Power BI)中进行可视化,以监控基础设施状态漂移。
有关更多信息,请参阅 https://www.cloudquery.io/docs/cli/commands/cloudquery。
providers:# provider configurations- name: awsconfiguration:accounts:- id: <UNIQUE ACCOUNT IDENTIFIER># Optional. Role ARN we want to assume when accessing this account# role_arn: < YOUR_ROLE_ARN ># Named profile in config or credential file from where CQ should grab credentialslocal_profile = default# By default assumes all regionsregions:- us-east-1- us-west-2# The maximum number of times that a request will be retried for failures.max_retries: 5# The maximum back off delay between attempts. The backoff delays exponentially with a jitter based on the number of attempts. Defaults to 30 seconds.max_backoff: 20## list of resources to fetchresources:- "*"
Driftctl
如果您偏向使用终端的 CLI,那么 DriftCtl 很适合您。该工具可以帮助我们跟踪和检测单个命令可能发生的托管和非托管漂移。
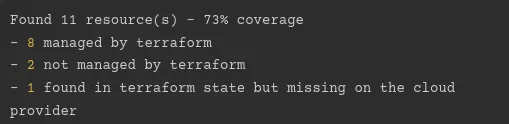
由于这是一个基于 CLI 的工具,因此可以轻松集成到 Jenkins 管道中编写的 CI/CD 流水线中,并且结果可以作为输出推送到 GitHub 中的 PR。如果你对这款工具不感兴趣,请将其作为系统中的 cron 作业运行。创建一个日志组来收集日志,然后使用日志监控解决方案(例如 Fleuentd 或 Prometheus/graphana 包)来进行可视化并创建警报解决方案。
了解更多工具相关信息,请阅读 https://docs.driftctl.com/0.35.0/installation
#to scan local file
driftctl scan
# To scan backend in AWS S3
driftctl scan --from tfstate+s3://my-bucket/path/to/state.tfstate
结 论
最后,我想就编写更好的代码和采用更优的编码实践总结几点我的思考:
- 始终尝试构建自动化基础设施。即使您执行手动步骤,也请尝试将它们导入 Terraform 脚本,然后进行应用。
- 渐进地、逐步地增加编写和应用的代码,避免一次性编写和应用超长代码。
- 实施带有自定义警报系统的漂移跟踪系统,确保该系统将向 SRE 发送有关观察到的基础漂移的信息。