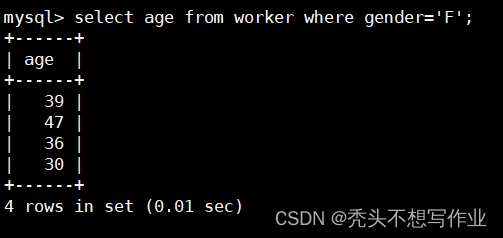
1.文件夹介绍(使用的是CWRU数据集)

0HP-3HP四个文件夹装载不同工况下的内圈故障、外圈故障、滚动体故障和正常轴承数据。
2.模型
按照1024的长度分割样本,构建内圈故障、外圈故障、滚动体故障和正常轴承样本集
2.1.计算11种时域特征值
# 计算时域特征
def calculate_time_domain_features(signal):features = []# 均值features.append(np.mean(signal))# 标准差features.append(np.std(signal))# 方根幅值features.append(np.sqrt(np.mean(np.square(signal))))# 均方根值features.append(np.sqrt(np.mean(np.square(signal))))# 峰值features.append(np.max(signal))# 波形指标features.append(np.mean(np.abs(signal)) / np.sqrt(np.mean(np.square(signal))))# 峰值指标features.append(np.max(np.abs(signal)) / np.mean(np.abs(signal)))# 脉冲指标features.append(np.max(np.abs(signal)))# 裕度指标features.append(np.max(np.abs(signal)) / np.sqrt(np.mean(np.square(signal))))# 偏斜度features.append(skew(signal))# 峭度features.append(kurtosis(signal))return features2.2.计算12种频域特征值
# 计算频域特征
def calculate_frequency_domain_features(signal, sample_rate):features = []# 快速傅里叶变换spectrum = fft(signal)spectrum = np.abs(spectrum)[:len(spectrum)//2] # 取一半频谱#频域指标1features.append(np.mean(spectrum))# 频域指标2features.append(np.var(spectrum))# 频域指标3features.append(np.sqrt(np.mean(np.square(spectrum))))# 频域指标4features.append(np.max(spectrum) / np.sqrt(np.mean(np.square(spectrum))))# 频域指标5features.append(kurtosis(spectrum))# 频域指标6features.append(skew(spectrum))# 频域指标7features.append(np.max(spectrum))# 频域指标8features.append(np.min(spectrum))# 频域指标9features.append(np.max(spectrum) - np.min(spectrum))# 频域指标10features.append(np.max(np.abs(spectrum)) / np.mean(np.abs(spectrum)))# 频域指标11features.append(np.max(np.abs(spectrum)) / np.sqrt(np.mean(np.square(spectrum))))# 频域指标12peak_index = np.argmax(spectrum)peak_frequency = peak_index * sample_rate / len(spectrum)features.append(peak_frequency)return features2.3.构建评价指标,从时域和频域一共23个指标中选出对故障特征最敏感的前4个特征,这里用的是方差评价指标,也可以选用其它的评价指标
# 数据
samples = data # 轴承振动信号样本数据列表
sample_rate = 12000 # 采样率# 构建特征集
feature_set = build_feature_set(samples, sample_rate)# 选择前4个敏感特征
import numpy as np
from sklearn.model_selection import train_test_split# 将特征集转换为NumPy数组
feature_set = np.array(feature_set)# 计算评价指标(这里以方差为例)
scores = np.var(feature_set, axis=0)# 选出最敏感的4个特征
selected_indices = np.argsort(scores)[-4:]
selected_features = feature_set[:, selected_indices]最后选出 的敏感特征集
2.4.将每个样本的这4个特征输入CNN模型进行分类(也可以输入给SVM或KNN等分类器)
3.效果
0HP数据集
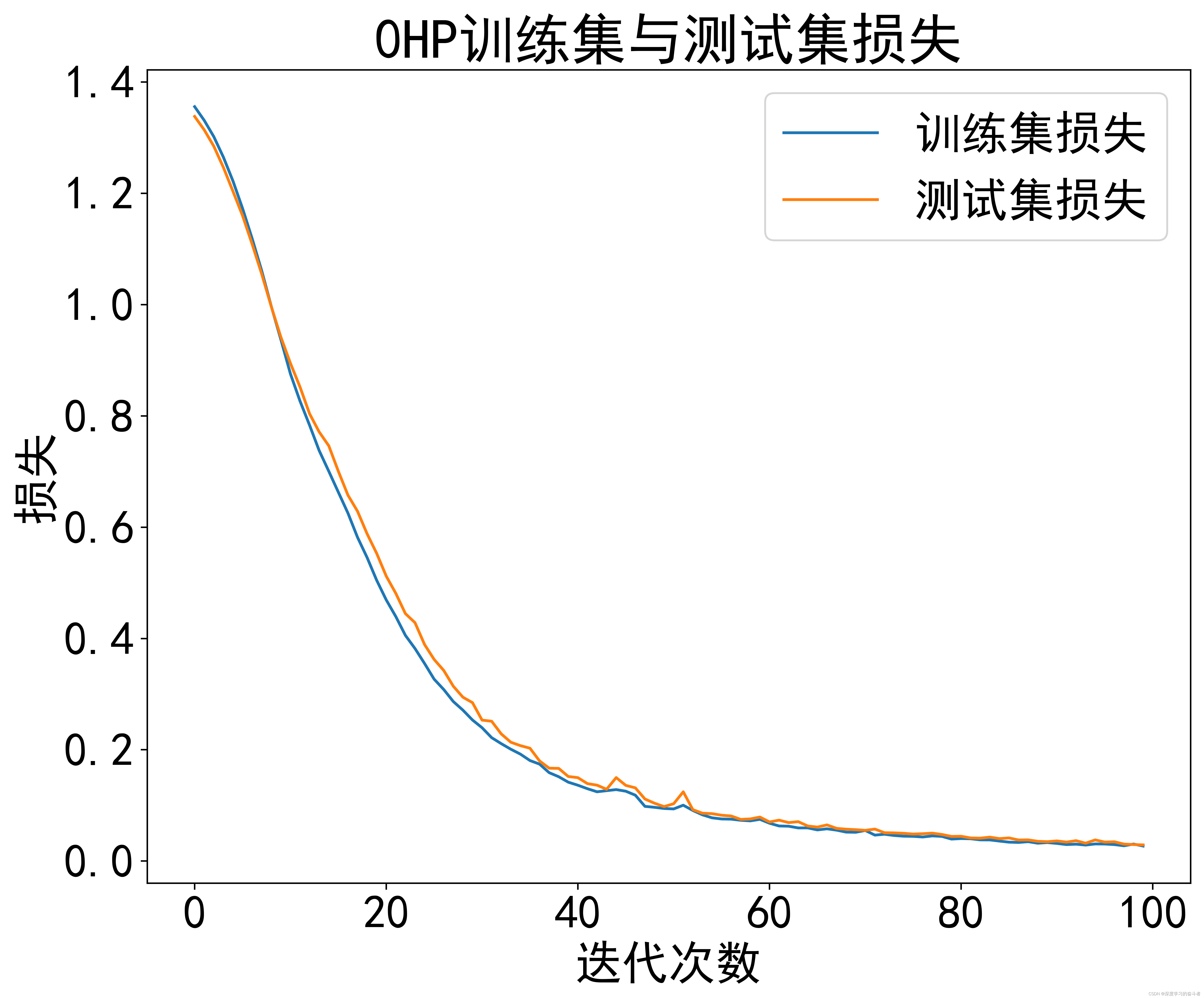
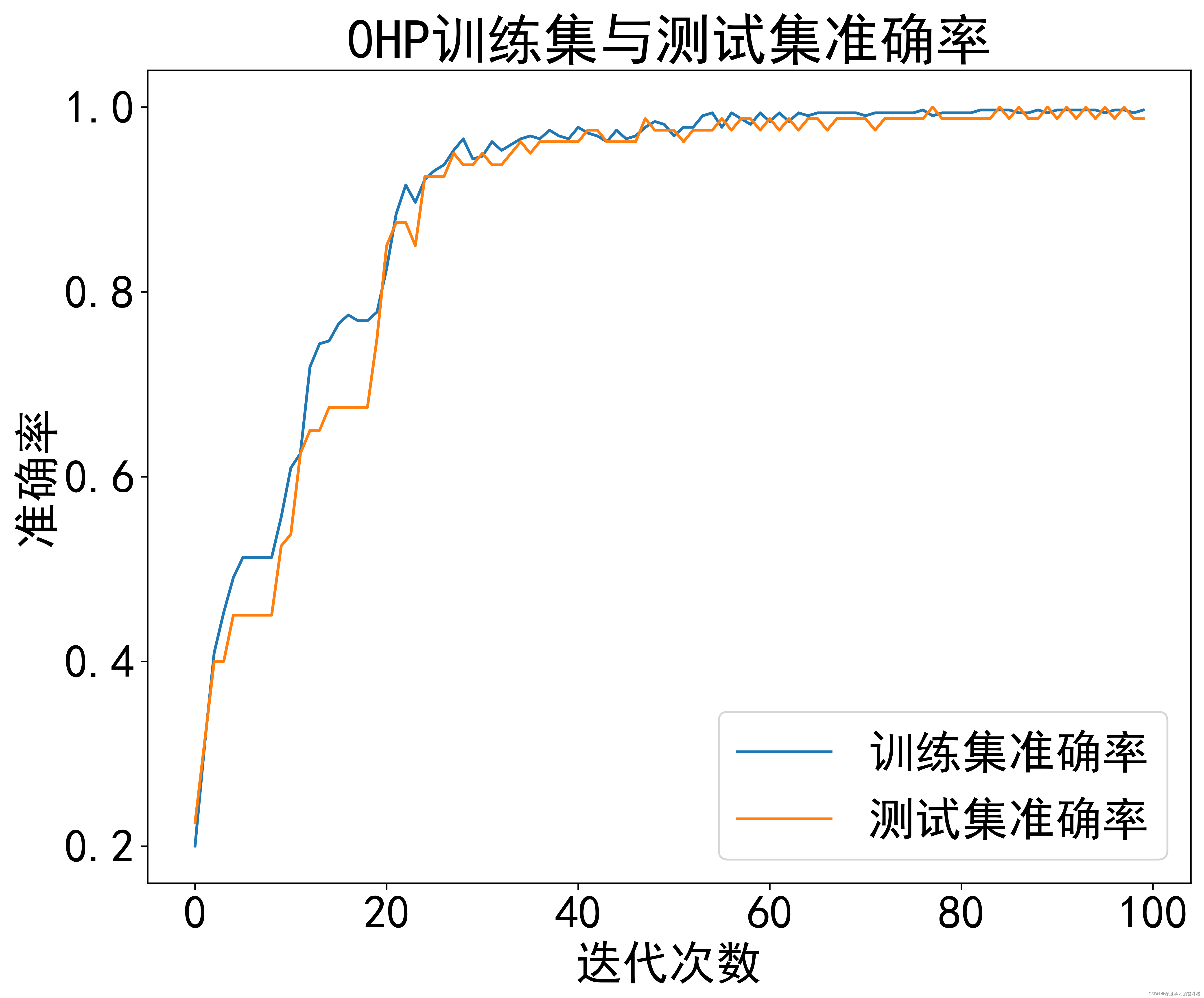
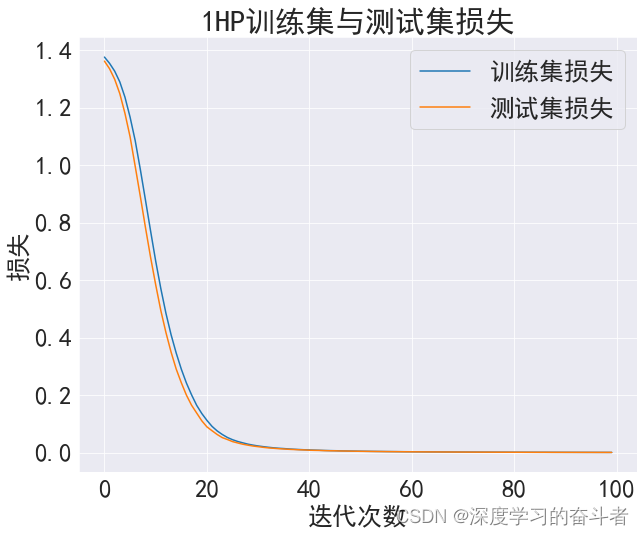
1HP数据集

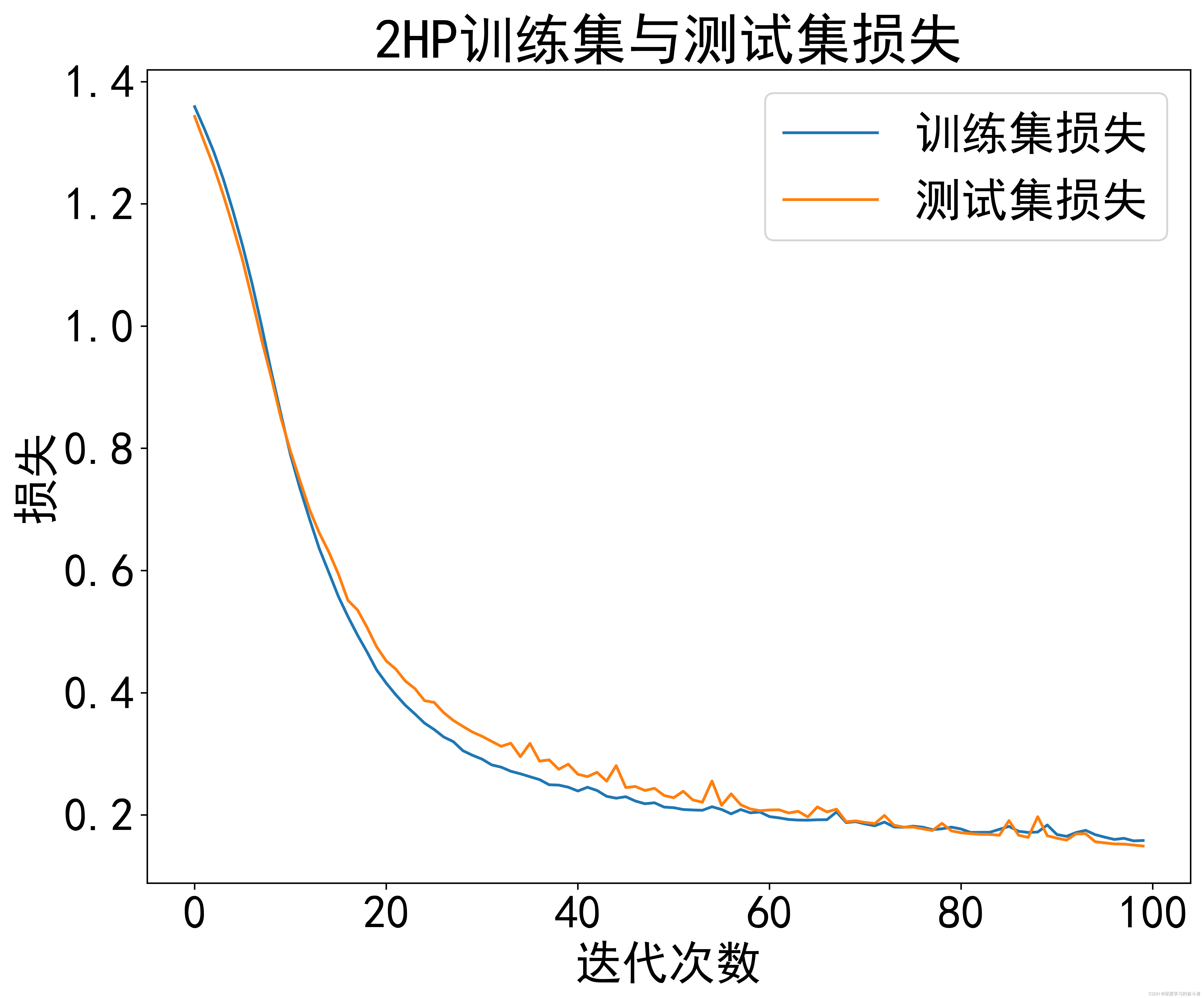
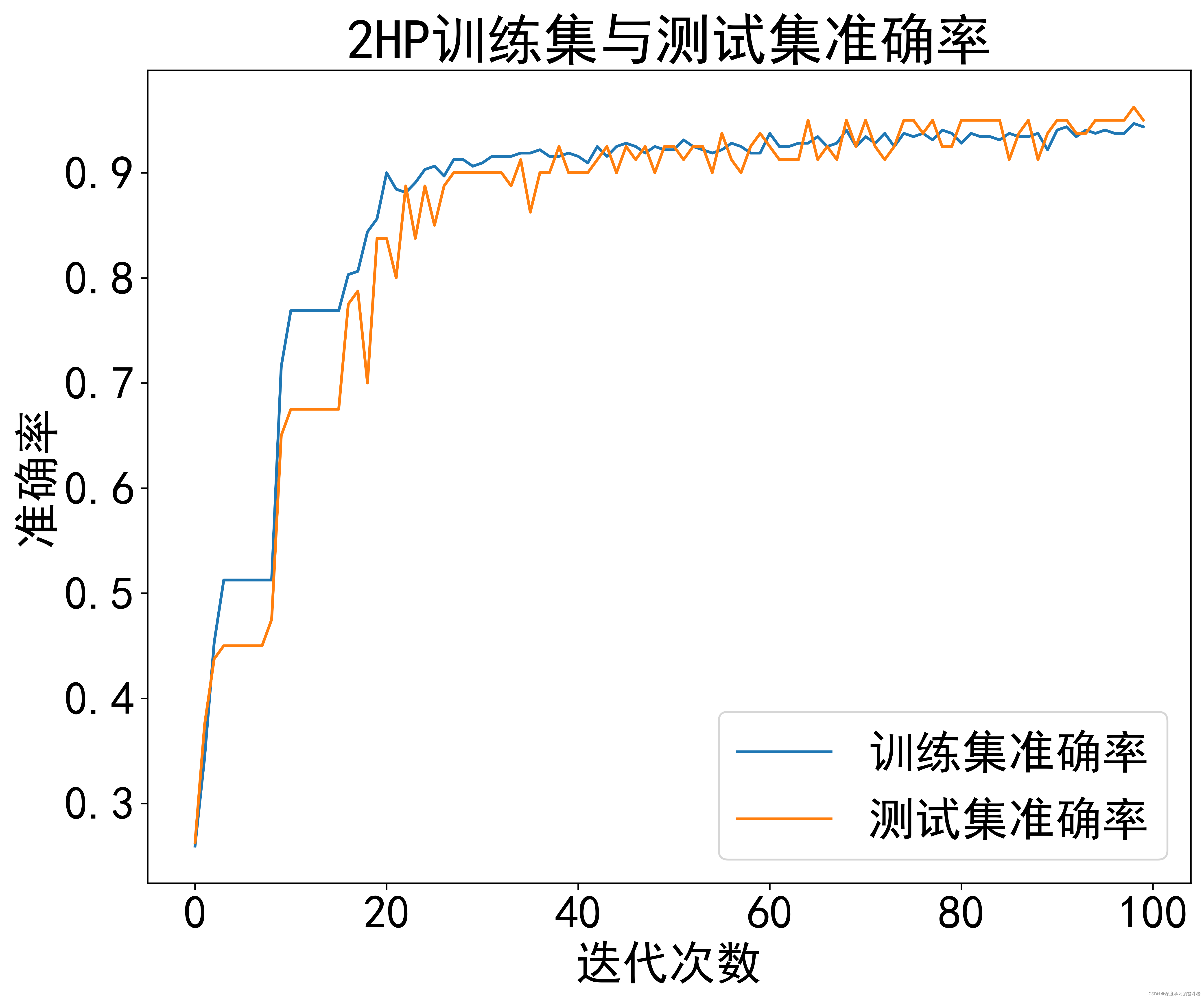
2HP数据集
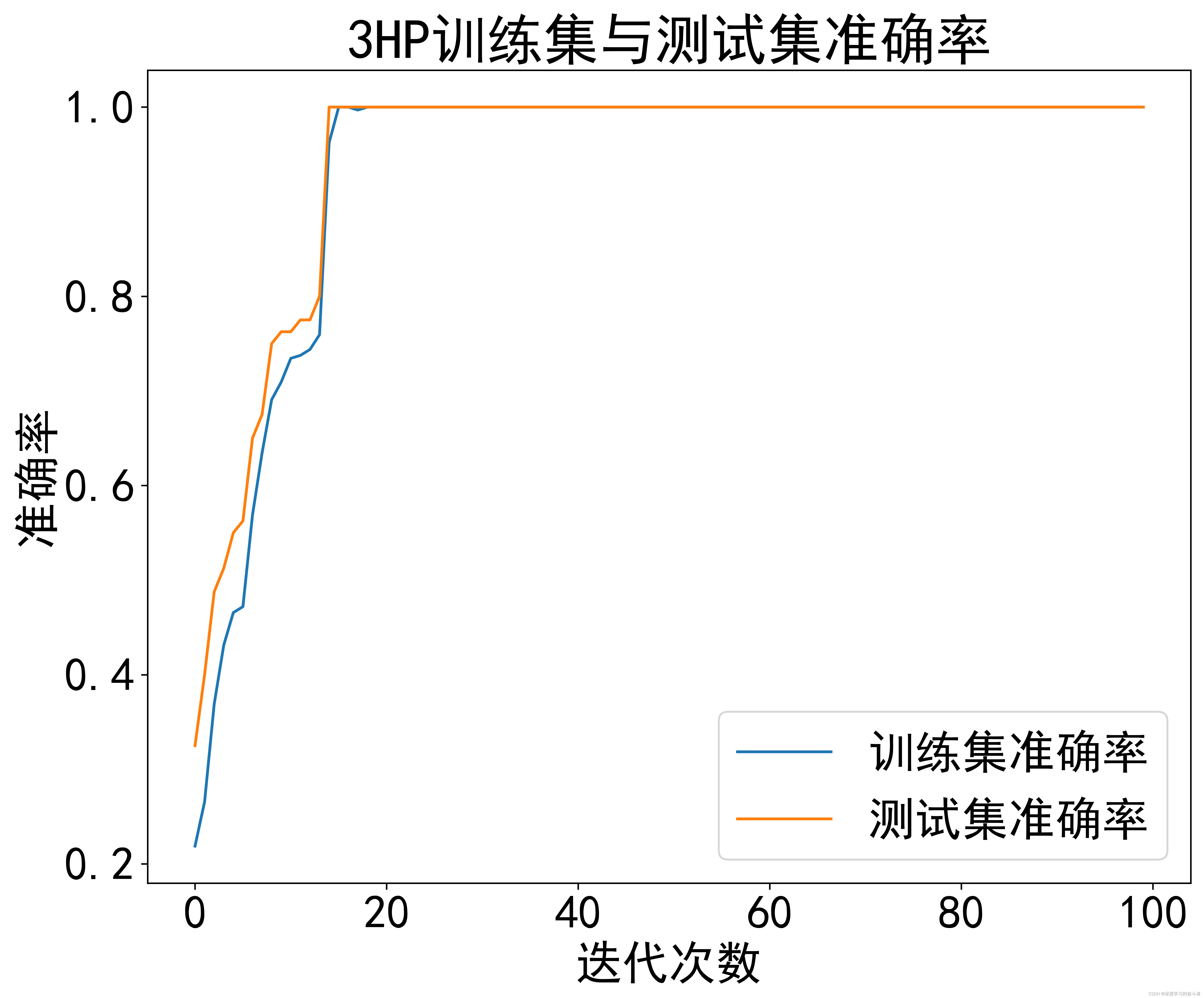
3HP数据集

总的代码和数据集放在了压缩包里
plt.rcParams['font.size'] = 25
# 绘制损失曲线
plt.figure(figsize=(10, 8))
plt.plot(train_loss, label='训练集损失')
plt.plot(test_loss, label='测试集损失')
plt.xlabel('迭代次数')
plt.ylabel('损失')
plt.title('1HP训练集与测试集损失')
plt.legend()
plt.savefig('0.png', dpi=600,bbox_inches = "tight")
plt.show()
# 绘制准确率曲线
plt.figure(figsize=(10, 8))
plt.plot(train_accuracy, label='训练集准确率')
plt.plot(test_accuracy, label='测试集准确率')
plt.xlabel('迭代次数')
plt.ylabel('准确率')
plt.title('1HP训练集与测试集准确率')
plt.legend()
plt.savefig('1.png', dpi=600,bbox_inches = "tight")
plt.show()
#可以关注:https://mbd.pub/o/bread/ZJuXmZtt