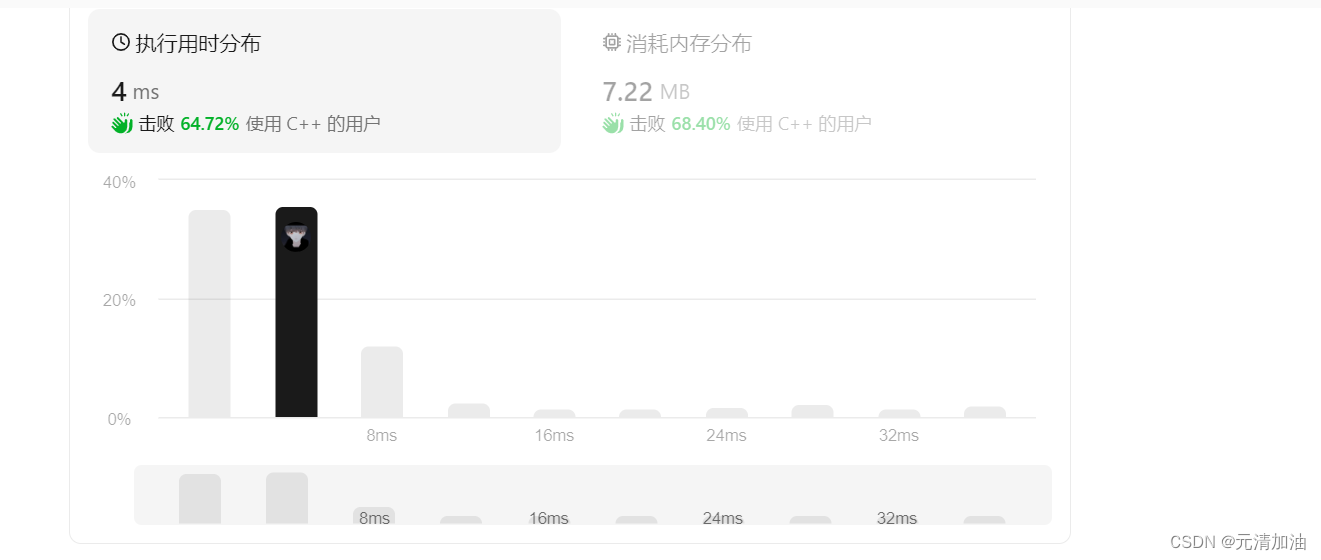
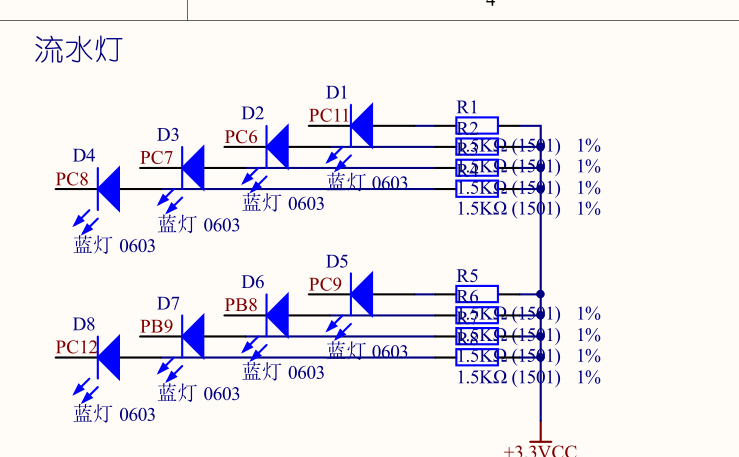
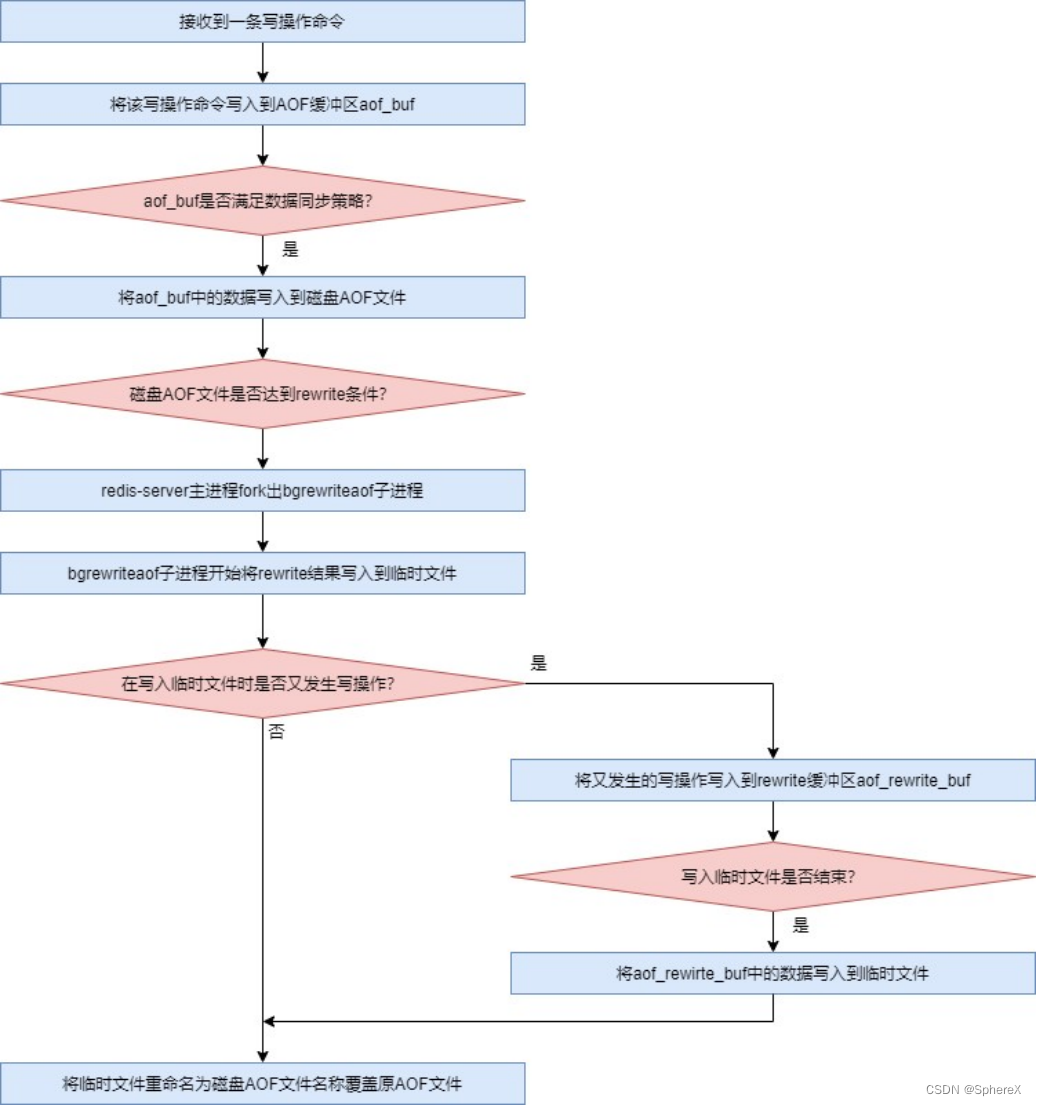
高斯分布我们都很熟悉,但在格密码中会用到一种特殊的高斯分布,将其取名离散高斯分布(discrete Gaussian)。
一. N维连续高斯分布
给定一个正整数n,代表维度。一个正实数,代表标准差(高斯分布的标准差决定着图像的胖瘦,所以这个参数有的时候也叫“宽度”)。N维连续高斯分布的输入是N维向量,输出是一个正实数,也就是
,概率密度函数如下:
可以想到,如果把看成一个整体的话,新的高斯分布的标准差则为1,如下:
写成N个维度的话,可得:
这个公式成立的前提是高斯分布不同维度上的标准差要求一样。这也就是所谓的在
上抗旋转(
is invariant under rotations of
)。
格密码偶尔会用到一个很有意思的现象:当选择合适的归一化因子时,高斯分布的傅里叶变换是其本身。
二. 离散高斯分布
先提一句,离散高斯是格密码中才会出现的概率。另外,补充一个重要的高斯积分结论,如下:
先引出一个新的高斯分布通常写作,概率密度函数与原始的
成正比,如下:
格陪集(lattice coset)(其实就是把格L进行平移c),如果将以上f(x)中的x改为格点的话,便得到了对应的离散高斯分布,如下:
这一段话可能有些官方,简单对这个概念谈谈自己的理解。离散高斯分布的输入是一个一个点,直观上就是把高斯分布的函数图像,抠成一个一个点,但是整体趋势还是高斯分布。这种离散的点,就可以直接套用格点,带进去所得到的函数值能直观反映取这个点对应的概率大小。
三. 光滑参数
谈格上高斯分布,不得不说光滑参数(smoothing parameter)。
我们知道,“格”是一个一个孤立的点,重点强调是离散的。那我们在想,能不能同时对这些格点加一个小小的扰动,神奇的化离散为连续呢?更进一步,如果加的扰动是一个高斯分布,那对这个高斯分布要啥要求呢?
可以想到,如果高斯分布的方差越大,那么它就越接近一个均匀分布,这种效果就越好。
将刚才谈到的格陪集全部带入高斯分布,可以得到求和(gaussian mass),如:
光滑参数其实是定义在对偶格上的,满足下列不等式最小的s即为光滑参数的值:
可以看到右边有个参数,所以光滑参数通常记作
。这个
在格密码中通常是很小的值,也就是计算复杂性通常所说的可忽略函数,比如
,其中n可以看成格的维度。
光滑参数在格上,本质就是一个数,那这个数有多大呢?
光滑参数的上限与对偶格最短的向量长度相关,请看一个定理。
定理1
对任意的满秩格,都有
可以看到这个定理中的就是取
,这个值是很小的。
怎么老谈对偶格,弄得很玄幻。当然,其实也有直接定义在原始格上光滑参数的结论。
对任意格的格基可以进行高斯-斯密斯(Gram-Schmidt)正交化,来让格基更加“漂亮”。格基记为,正交化后记为
。格基正交化后的长度满足如下性质:
现在来看另一个定理
定理2
对任意的满秩格,以及
,格的光滑参数有上界结论:
回到主题,也就是光滑参数可以让离散的分布看起来像连续分布。也就是当高斯分布的标准差满足时,离散高斯分布
就跟连续高斯分布很像。这个很想指的是分布的矩(moments)和尾数(tails)很像(这两个概念是统计学的专有名词)。
另外,统计独立的离散高斯分布的和依旧为离散的高斯分布。
四. 子高斯分布
这个概念也经常出现在格密码中,尤其是在一些困难问题的规约证明中很常见。
先谈正式的定义。给定一个参数s,以及实数,满足如下不等式的变量X就可以称之为子高斯分布:
这个定义想说,一个变量大于一个数所得到的概率与高斯分布有关,英文一些文献可能会这样表达"a random variable is subgaussian if it is dominated by a Gaussian”。
注意这个地方的x也是一个n维的向量,实际上,对任意的单位向量,如果x为子高斯分布,那么
也为子高斯分布。
子高斯分布的理解还太粗糙,后期会补上的。